

Ziyu Guo 投稿
量子位 | 公众号 QbitAI
图像生成模型,也用上思维链(CoT)了!
来自港中文、北大和上海AI Lab的研究团队,将CoT与生成模型结合到了一起。
实验结果表明,他们的这种方法能有效提高自回归图像生成的质量,甚至超越扩散模型。

此外,作者还提出了两种专门针对该任务的新型奖励模型——潜力评估奖励模型(Potential Assessment Reward Model,PARM)及其增强版本PARM++。
其中PARM++引入了反思机制(Reflection Mechanism),进一步优化了图像生成质量。

将CoT用于图像生成
研究团队观察到,自回归图像生成与LLM/LMM具有类似的推理架构,即:
-
离散化的Token表示:无论是语言还是图像数据,自回归模型都将其量化为离散Token,并通过逐步预测的方式进行生成。
-
逐步解码(Step-by-Step Decoding):类似于CoT在数学问题上的逐步推理,自回归图像生成也可以逐步生成中间图像,并在生成过程中进行验证与优化。
于是,类比用CoT推理解决数学题的方案,研究团队设计了用CoT推理进行文生图的新方法。
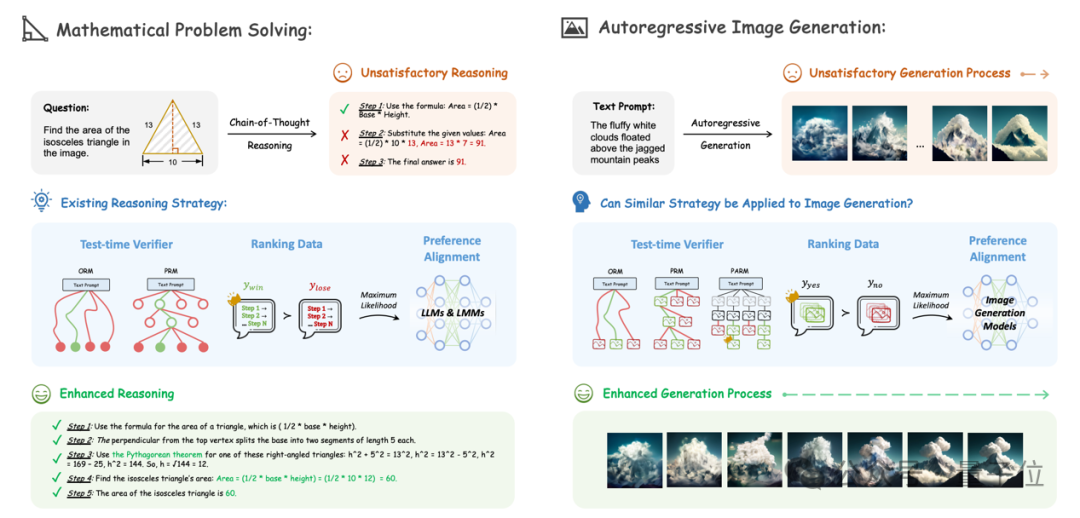
具体来说,作者以“文生图”为任务场景,并使用了Show-o来作为baseline模型,研究主要分为测试时验证(Test-time Verification)、直接偏好优化(DPO)对齐以及二者的结合3个部分。
测试时验证
首先,论文探索如何使用奖励模型来进行测试时验证,实现了结果奖励模型(ORM)和过程奖励模型(PRM)方案。
在两者的基础上,作者又提出了两种全新的针对于图像生成任务的潜力评估奖励模型(PARM)和PARM++。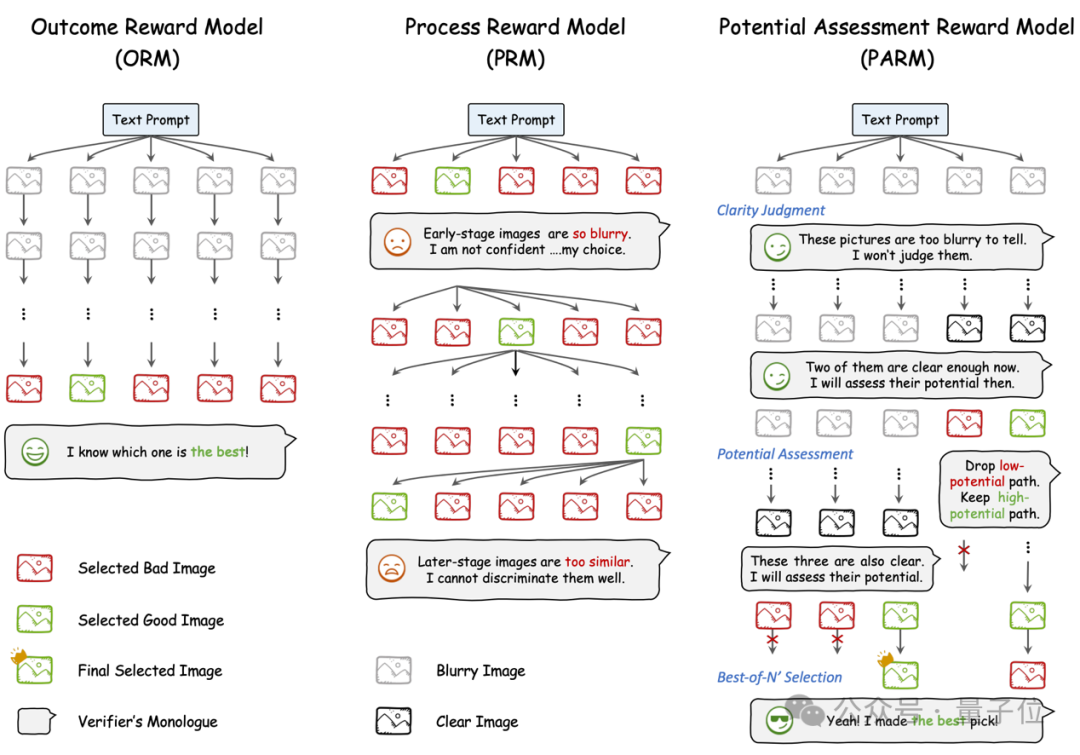
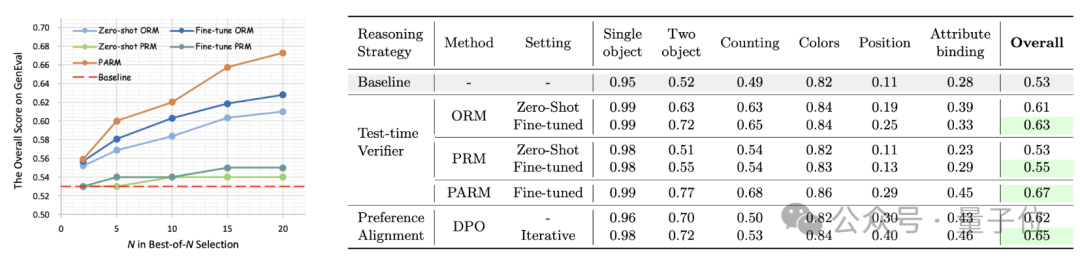
针对结果奖励模型,论文提出了零样本和微调2种方案,均使用Best-of-N的方式进行验证,即进行多次完整路径的生成,并从中选择出质量最高的最终图片。
零样本ORM基于LLaVA-OneVision的7B版本,通过下面的prompt来激发其作为文生图质量评估的能力:

同时作者也构建了大规模的图文奖励数据来得到微调ORM,数据形式如下图所示:

而对于过程奖励模型,作者使用了类似ORM的方案,同样尝试了零样本和微调两种方式,并对每个步骤进行Best-of-N的方案,即逐步选择出质量最高的中间阶段的生成图片。
然而,作者发现这种PRM无法对图像生成有显著的提升。
通过可视化,作者发现:PRM在早期生成阶段由于图像模糊而难以评估,而在后期生成阶段不同路径的图片趋于相似,导致辨别能力受限。

为了同时结合ORM的简洁和有效性,以及PRM细粒度逐个步骤验证的思想,作者提出了PARM。
PARM通过以下三步提升图像生成质量:
-
清晰度判断(Clarity Judgment):识别哪些中间步骤的图像已经足够清晰,可用于后续评估。
-
潜力性评估(Potential Assessment):分析当前步骤是否有潜力生成高质量的最终图像。
-
最佳选择(Best-of-N’ Selection):在高潜力路径中选择最佳的最终图像。
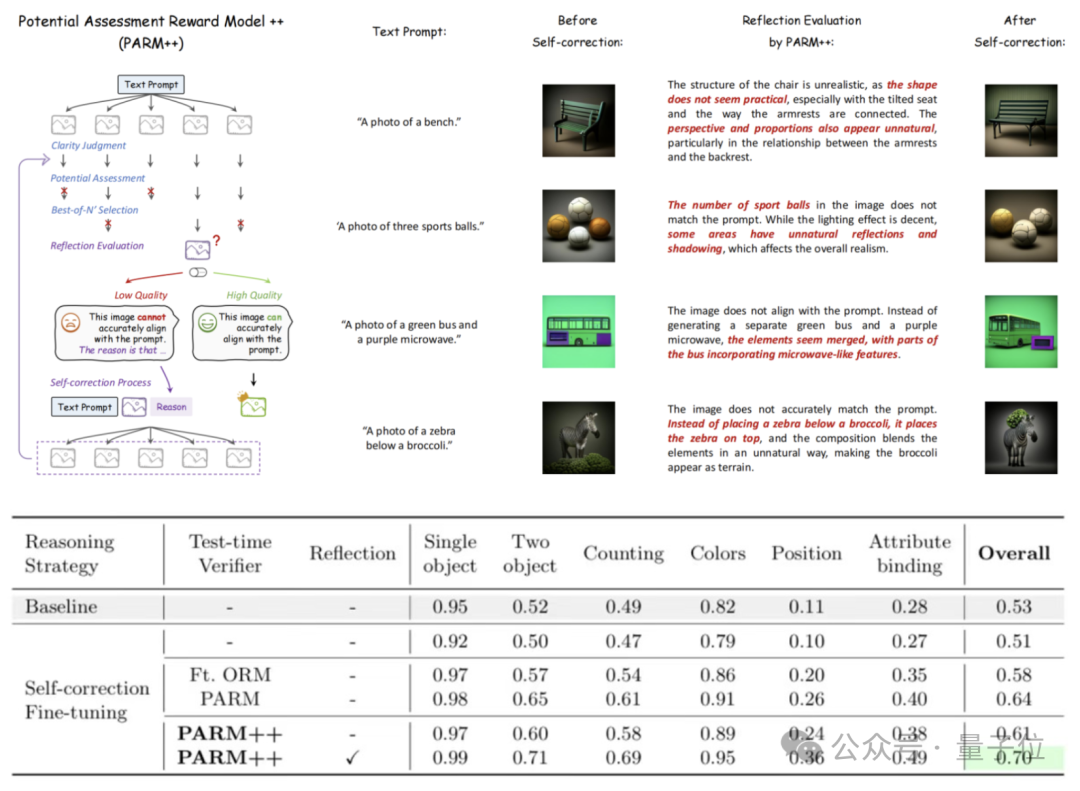
在PARM的基础上,作者进一步提出了PARM++,使模型能够在生成错误时进行自我修正。
具体来说,基于PARM选出的最终图片,作者首先使用PARM++ 评估生成图片是否符合文本描述。
若图片不符合要求,会要求RM提供详细的错误描述,并根据该描述,要求生成模型进行自我修正(Self-correction),即模型接收反馈,并参考错误信息重新生成结果。
结果表明,PARM++进一步将GenEval成绩提升了10%,生成结果在物体数量、颜色、空间关系等方面更加准确。
直接偏好优化对齐
作者进一步了引入DPO偏好对齐,即使用大规模排名数据训练模型,使其生成结果更符合人类偏好。
研究团队构建了288K条图文排名数据用于训练。
具体来说,训练过程是采用最大似然优化,调整模型输出,使其更偏向人类偏好。
同时,论文也进一步使用迭代DPO,在模型优化后重新生成新数据进行再次训练。
结果表明,初次DPO训练使模型在GenEval性能提升9%,而迭代DPO的提升比例可以达到12%,超越微调ORM。
测试时验证与DPO结合
在前述两种方法的基础上,作者探索了将测试时验证与DPO对齐相结合的策略,以实现端到端的优化。
在DPO训练的模型基础上,作者进一步应用测试时验证进行筛选,使生成图像质量更高,文本一致性更强。
实验结果表明,结合DPO和测试时验证后,模型在GenEval指标上的整体提升达27%,超越了单独使用DPO或测试时验证的方案。
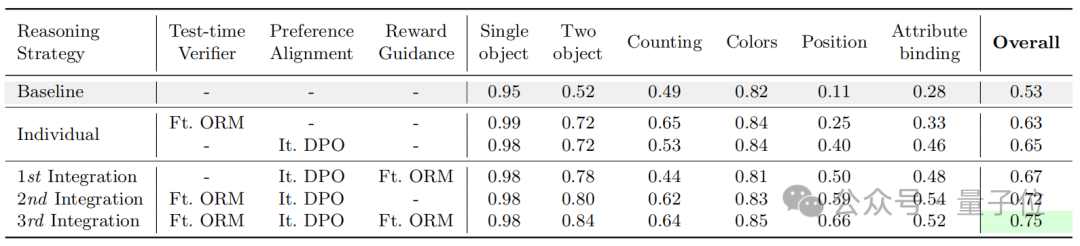
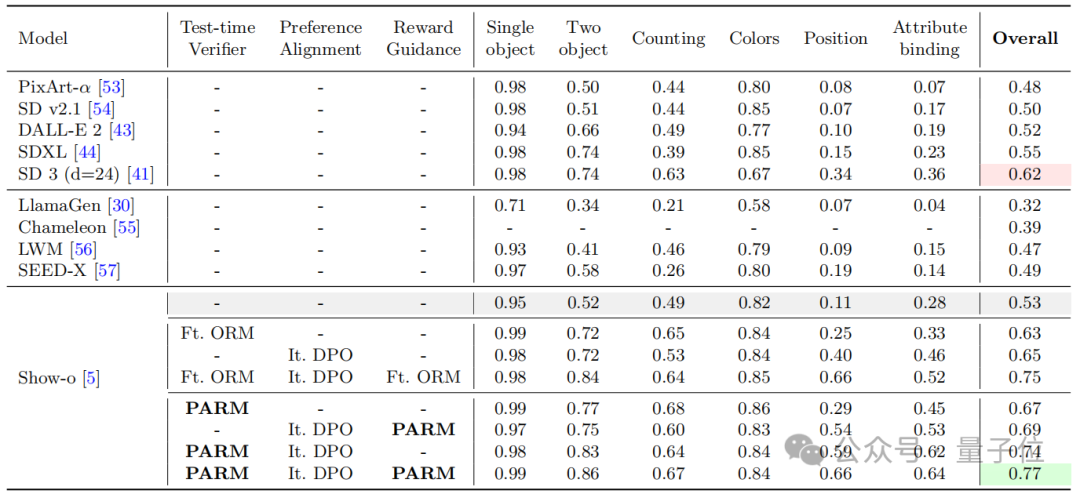
整体上看,相比于现有的扩散模型和自回归模型,使用CoT推理有效提升了文本生成图像任务质量。
论文地址:
https://arxiv.org/abs/2501.13926
项目地址:
https://github.com/ZiyuGuo99/Image-Generation-CoT
投稿请工作日发邮件到:
ai@qbitai.com
标题注明【投稿】,告诉我们:
你是谁,从哪来,投稿内容
附上论文/项目主页链接,以及联系方式哦
我们会(尽量)及时回复你

一键关注 👇 点亮星标
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
(文:量子位)