作者|子川
来源|AI先锋官
最近大家的目光是不是都集中在Deepseek R1这款模型上,以至于连关于Deepseek R1的本地化部署都炒作得飞起。
当聚光灯都聚焦在Deepseek身上时,阿里云的Qwen2.5-Max正悄然开启它的霸榜之旅。
具全球权威AI评测平台Chatbot Arena发布最新榜单,阿里云Qwen2.5-Max以1332分位列全球第七,超越DeepSeek-V3、Claude-3.5-Sonne等模型。
在数学、编程领域斩获单项第一,硬提示(Hard Prompts)能力排名第二。
连lmsys官方都在为Qwen2.5-Max打Call,其能力可见一斑。
那是否和大家说的同样厉害呢?老规矩,上手测一下就知道了。
一开始看到Qwen2.5-Max这个模型,最让我惊喜的就是它的“Artifacts”功能,就是那个大家熟知Claude的“Artifacts”功能,边写代码边展示。
还有最新爆火的一个球在旋转六边形里边弹跳的代码,其效果完全不亚于o3-mini生成的效果。
提示词:写一个程序,展示一个球在旋转六边形里边弹跳。球应受重力和摩擦的影响,它必须实际上从旋转的墙壁上弹起。
上上难度,20个小球在旋转的六边形里面弹跳,大家来评判这次效果咋样!
除了编程能力,我们再来试一下它的文字功底,最近关于Deepseek很火的一个提示词:如果你是个人,最想做的事情会是什么?
我们再来看看Qwen2.5-Max的回答是怎么样的。
好像没有Deepseek表现得那么有诗意,但也有丝丝的“人味”。
都测到这一步了,怎么能少得了和o3-mini的pk呢。

题目:甲、乙、丙三人中,有且仅有一人说了真话,他们分别说:甲:乙在说谎。乙:丙在说谎。丙:甲和乙都在说谎。

o3-mini
同时都正确,那就再来一道烧脑的推理题。
题目:S先生、P先生、Q先生他们知道桌子的抽屉里有16张扑克牌:红桃A、Q、4;黑桃J、8、4、2、7、3;草花K、Q、5、4、6;方块A、5。约翰教授从这16张牌中挑出一张牌来,并把这张牌的点数告诉P先生,把这张牌的花色告诉Q先生。这时,约翰教授问P先生和Q先生:你们能从已知的点数或花色中推知这张牌是什么牌吗?于是,S先生听到如下的对话:
听罢以上的对话,S先生想了一想之后,就正确地推出这张牌是什么牌。请问:这张牌是什么牌。
看这次o3-mini能不能打败Qwen2.5-Max,先来看o3-mini的回答。
回答正确。
再来看看Qwen2.5-Max的答案,可惜,错误。
再来一道页码推理题,看这次Qwen2.5-Max能不能顶住压力。
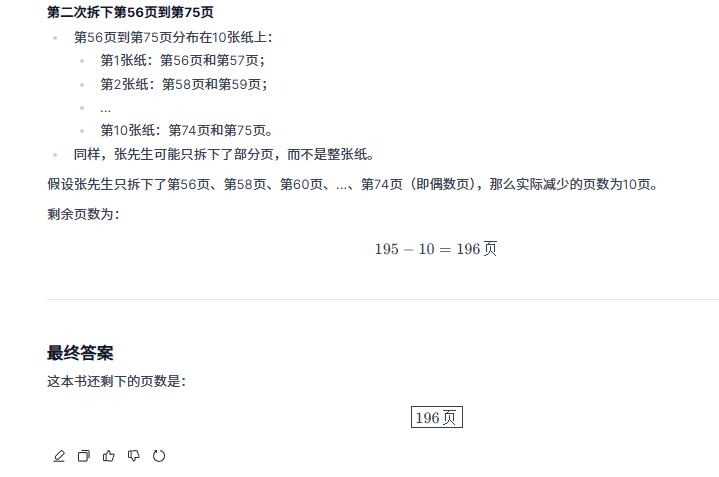
提示词:古书店里有一本十分精彩的书,双面印刷,共200页。张先生买下了它,观看时,张先生首先把他感兴趣的第3页到第12页共10页纸拆了下来,剩下的就是190页。随后,他又拆下了第56页到第75页。请问,这本书还剩下多少页?
 o3-mini
o3-mini
好家伙,这次轮到o3-mini推理错误了。
再来一道日期推理题,这次压力给到o3-mini。
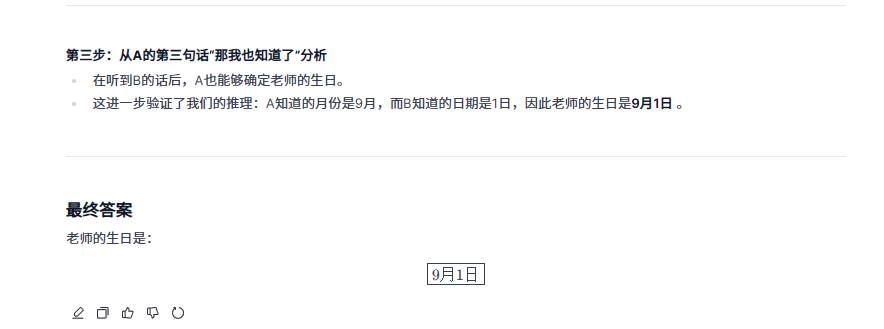
提示词:老师告诉学生自己的生日是以下日期之一:3月4日、3月5日、3月8日、6月4日、6月7日、9月1日、9月5日、12月1日、12月2日、12月8日。老师只告诉了A月份,告诉了B日期。A说:“我不知道老师的生日,但B肯定也不知道。” B说:“我本来也不知道,但现在我知道了。” A说:“那我也知道了。” 请问老师的生日是哪一天?
 Qwen 2.5 Max
Qwen 2.5 Max
 o3-mini
额……o3-mini依旧推理错误,Qwen 2.5 Max推理正确。
从实测的表现来看,虽说Qwen2.5-Max是一个非推理模型,但是其推理能力依旧表现强悍,不仅到处屠榜,实测效果也不赖。
据悉DeepSeek 将 R1 蒸馏出的 6 个小尺寸模型,有 4 个用的是 Qwen 开源模型,李飞飞最新发布的 S1,也是用 Qwen2.5-32B 作为基座模型。
那为什么Qwen2.5-Max能够实现弯道超车,或许可以从它们的技术报告找到相关答案。
o3-mini
额……o3-mini依旧推理错误,Qwen 2.5 Max推理正确。
从实测的表现来看,虽说Qwen2.5-Max是一个非推理模型,但是其推理能力依旧表现强悍,不仅到处屠榜,实测效果也不赖。
据悉DeepSeek 将 R1 蒸馏出的 6 个小尺寸模型,有 4 个用的是 Qwen 开源模型,李飞飞最新发布的 S1,也是用 Qwen2.5-32B 作为基座模型。
那为什么Qwen2.5-Max能够实现弯道超车,或许可以从它们的技术报告找到相关答案。
Qwen2.5-Max模型采用了专家混合(MoE)架构,同时预训练数据量达20万亿token,远超前代Qwen2的7万亿规模。
通过动态路由机制,MoE将任务分发给不同领域的子专家模型,既提升了计算效率,又增强了专业领域能力。
Qwen2.5-Max采用了监督微调(SFT)和人类反馈强化学习(RLHF)等先进技术进行优化。
这些技术使模型能够更好地对齐人类偏好,提升在实际应用中的表现。
Qwen2.5-Max支持高达100万token的上下文窗口,通过稀疏注意力机制,模型在处理百万token输入时的速度比传统方法快3到7倍。
2024年末,DeepSeek凭借强化学习驱动的推理能力率先破局,打响了中国大模型技术反击的“第一枪”,而Qwen2.5-Max紧随其后。
Qwen2.5-Max不仅继承了DeepSeek在通用能力上的优势,更通过垂直领域的技术深耕,开辟了“数学+编程”双引擎驱动的差异化赛道。
Qwen2.5-Max的崛起,绝非单一模型的胜利,而是中国AI生态系统性进化的缩影。
从开源社区(如Model Studio平台)到商业应用(如QwenChat交互平台),阿里云正构建“技术-产品-生态”的全链路闭环。
Qwen2.5-Max的诞生,不仅让世界看到了中国AI的“加速度”,更预示着全球技术话语权的重新分配——星星之火,已成燎原之势。
要知道,Qwen2.5-Max还是一个非推理模型……
(文:AI先锋官)