

AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
-
内部慢思考:通过额外的训练,使模型在专门的推理任务上优化参数,提升自身的推理深度和输出质量。
-
外部慢思考:不改变模型本身,而是增加计算开销,例如通过多次采样、重新生成答案等方式延长推理过程,从而提高推理的准确性和可靠性。
-
缺乏理论支撑:目前,我们对这些方法为何有效的理解仍然有限,这阻碍了更先进策略的设计。
-
计算资源需求高:复杂的慢思考技术往往需要大量计算资源,且优化设计参数的难度较大,导致实际应用中的表现不尽如人意。

-
论文标题:Rethinking External Slow-Thinking: From Snowball Errors to Probability of Correct Reasoning
-
论文链接:http://arxiv.org/abs/2501.15602
-
分析了 LLM 推理过程中的雪球误差效应,并证明该效应会导致推理错误概率随推理路径的增长而上升,强调了慢思考策略在减少错误中的关键作用。
-
提出了一种基于信息论的系统性框架,建立外部慢思考方法与推理正确概率之间的数学联系,为理解慢思考策略的有效性提供理论支撑。
-
对比了不同的外部慢思考方法,包括 BoN 和 MCTS 等,揭示它们在推理能力提升方面的差异与内在联系。
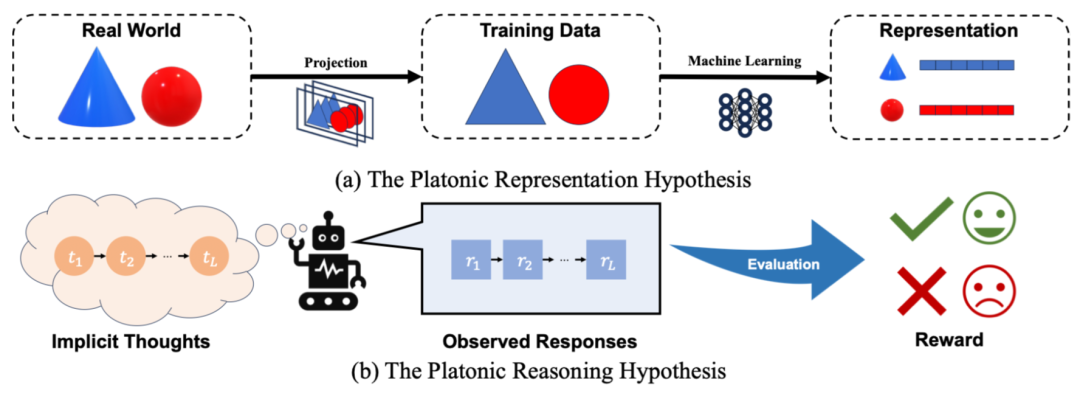
例如:在 LLM 执行数学推理任务时,例如解答「计算 3x + 2y」,模型并不是直接给出答案,而是隐式地执行一系列推理步骤: t₁: 计算 3x → t₂: 计算 2y → t₃: 将 3x 和 2y 相加。 然而,这些推理步骤是抽象的、不可直接观察的,模型的最终输出是这些推理过程的不同表达方式。例如,输出序列 r₁ → r₂ → r₃ 可能有多种不同的表达形式,但它们并不一定能完全还原对应的推理步骤 t₁ → t₂ → t₃。





-
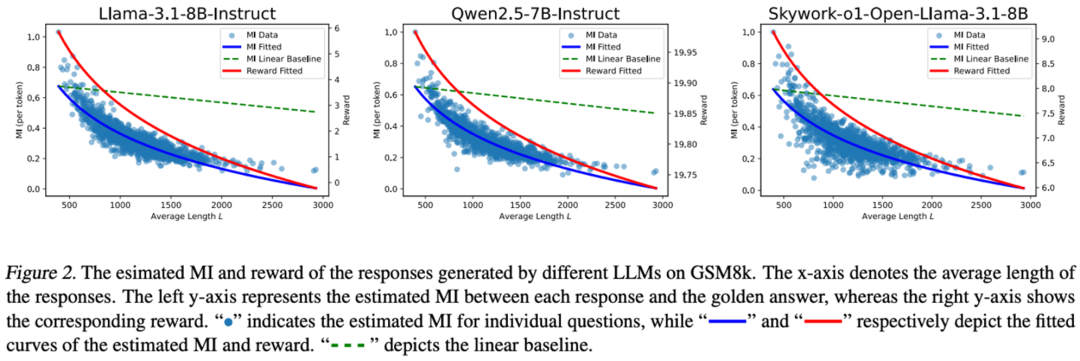
互信息呈负指数级下降,比线性衰减更快,随着推理步数 L 的增长,信息损失迅速累积;
-
由于计算的是平均互信息,推理链条靠后的 token 可能损失更多关键信息;
-
奖励分数随推理长度增加而下降,进一步验证了雪球误差对 LLM 生成质量的影响。



-
宽度扩展(Width-Expansion):
-
对于长度一定的推理序列,大多数外部慢思考方法都试图扩展推理空间的宽度。
-
这可以通过简单的重新生成(BoN、CoT-SC)或更复杂的树搜索方法(ToT、MCTS) 来实现。
-
生成 & 选择(Generation & Selection):
-
扩展推理空间后,还需要从多个候选推理路径中选出最优解。
-
设 Pr (τ_generate) 为生成正确推理的概率,Pr (τ_select) 为从候选路径中选出正确推理的概率,则最终获得正确推理结果的概率可表示为:Pr [ψ(R)≤τ ]= Pr (τ_generate )× Pr (τ_select )。
-
在每一层推理,生成 k 个子节点以扩展搜索树的宽度;
-
仅保留 b 个最优候选解,以减少计算复杂度。


-
每层生成的候选数 k :决定了推理空间的扩展宽度;
-
每层筛选的最优候选数 b :影响正确推理路径的选择精度;
-
正确性阈值 τ :衡量推理结果的质量要求。
-
Pr (τ_select) (选择正确推理的概率)依赖于价值函数的可靠性,即 ϵ_b 相关的参数。
-
Pr (τ_generate) (生成正确推理的概率)受 推理路径长度 L 和扩展宽度 k 影响。
-
通过增加推理步骤,可以提升生成正确推理的概率,但同时会引入额外的选择代价,增加错误概率。
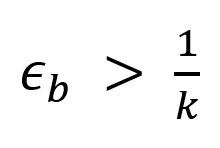 。
。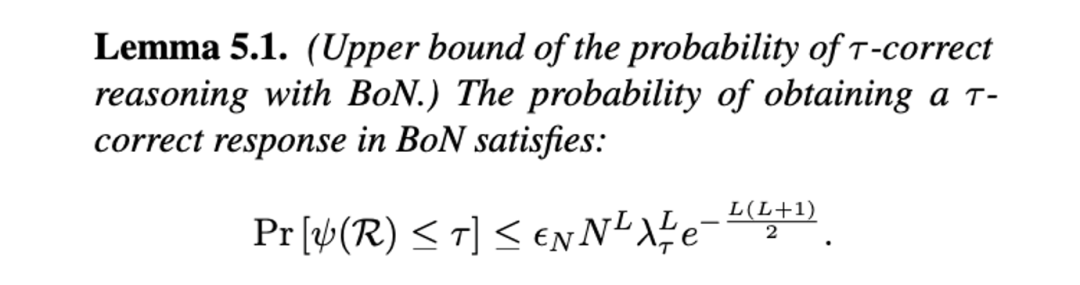



-
最优情况下:BoN 与 MCTS 的推理成本趋近相等;
-
最差情况下:当推理步数 L 较小时,BoN 的成本可能略高于 MCTS,但仍保持在合理范围内。当 L 增加,BoN 的推理成本甚至可能低于 MCTS。
-
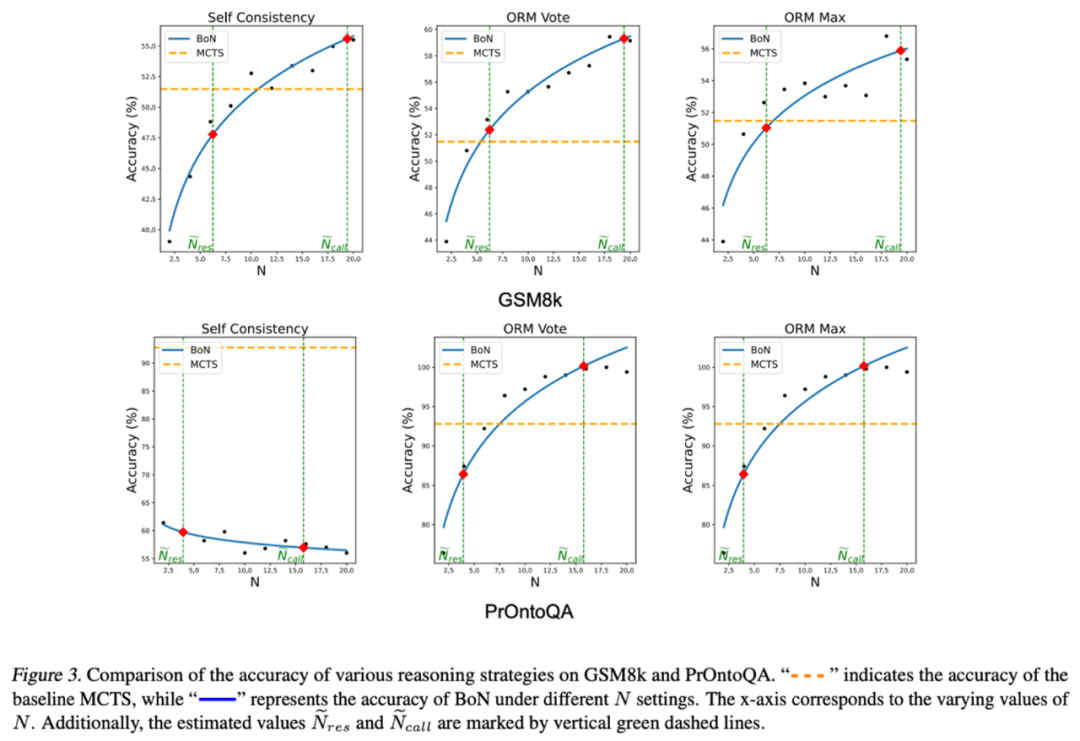
N ̃_res :对齐推理步数的 N 值
-
N ̃_call :对齐 LLM 调用次数的 N 值
-
Self-Consistency(自洽性选择)
-
ORM Vote(基于奖励模型的投票选择)
-
ORM Max(基于奖励模型的最大值选择)
-
PrOntoQA(二分类任务:True/False):
-
由于答案固定,增加 N 并不会提升 Self-Consistency 策略下的 BoN 性能,除非引入奖励模型。
-
GSM8k(多步推理任务):
-
由于答案多样,增加 N 即使在没有奖励模型的情况下,也能提升 BoN 的性能。
-
ORM Vote & ORM Max 策略(结合奖励模型):当 N 在 N ̃_res 和 N ̃_call 之间时,BoN 能够达到与 MCTS 相当的推理性能;
-
N 接近 N ̃_res 时,BoN 略低于 MCTS,但差距不大;
-
N 取更大值时,BoN 能够匹敌甚至超越 MCTS,进一步验证了 MCTS 在 LLM 推理中的局限性,并支持研究者的理论分析。
(文:机器之心)