
看我文章的老朋友应该还记得,之前写过一篇《字节跳动大模型研究院》推文。字节跳动成立大模型研究院已经快有半年时间,也该拿出一点成绩了。
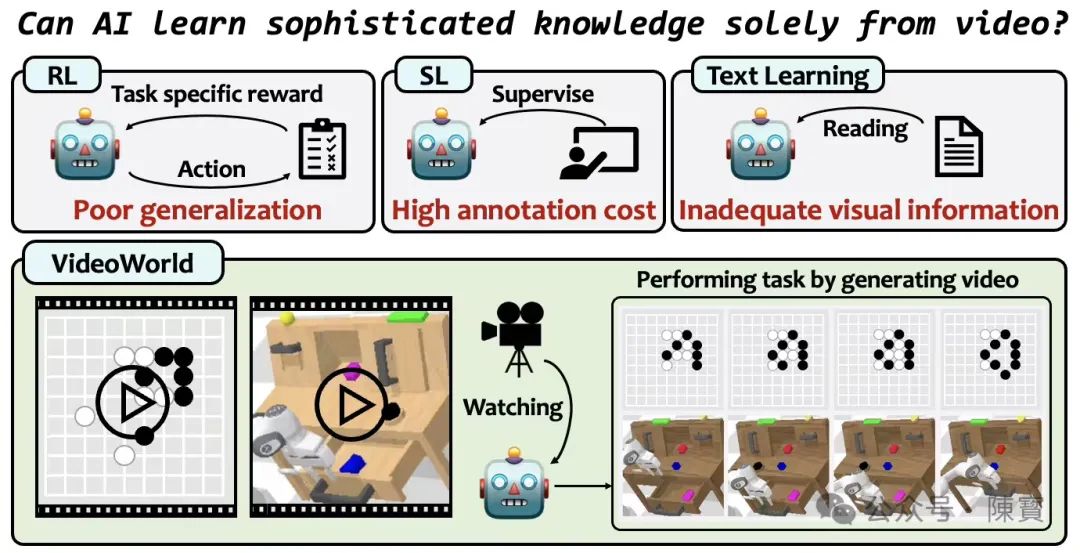
就在刚刚,豆包开源视频生成模型VideoWorld发布了。它是多模态AI领域一次重要技术突破,核心创新在于“无需依赖语言模型。仅通过视觉数据完成对世界的认知与生成”,个人觉得这一设计理念与当前主流模型(如Sora、DALL-E等)形成显著差异。
技术特点与创新突破
VideoWorld通过自回归模型架构,直接从未标注的视频数据中学习时空动态规律,无需借助文本标签或跨模态对齐。
模型能够通过预测视频帧序列或重建缺失片段,自主提取场景中的物理规律(如物体运动轨迹、光影变化等),从而实现“视觉即语言”的认知路径。
这种设计突破了传统多模态模型对语言模型的强依赖,减少了文本-视觉对齐的误差累积。
模型采用分层式时空注意力机制,分别捕捉局部运动细节与全局场景连贯性。
据开源资料推测,它能够通过多尺度特征融合技术,实现长视频生成中时间一致性的优化。
生成10秒以上的视频时,模型需确保物体位置、形态在时间轴上的合理演变,避免传统模型中常见的“闪烁”或逻辑断裂问题。
VideoWorld的开源策略(Apache 2.0协议)降低了技术门槛,允许研究者基于其框架探索更多应用场景,如视频编辑、虚拟现实内容生成等。
模型支持输入视频片段作为生成引导,为个性化创作提供了灵活接口。
创新价值与行业意义
传统视频生成模型(如Sora)高度依赖文本提示词,而VideoWorld证明纯视觉数据足以支持复杂场景的理解与生成。
豆包 VideoWorld 挑战了“语言为认知核心”的AI设计范式,为开发更接近人类直觉感知的AI系统提供了新思路。
无需文本标注的特性,使得模型可利用海量无标签视频数据(如监控录像、影视素材等),大幅降低训练成本。
减少对用户生成文本的依赖,一定程度上缓解数据隐私争议。
医疗影像分析、工业质检等文本描述匮乏但视觉信息丰富的领域,VideoWorld的技术路径更具适用性。例如,生成手术模拟视频时,模型可直接从真实手术录像中学习操作流程,无需依赖人工编写的文本指导。
潜在挑战与争议点
完全脱离语言模型,一定程度上会导致抽象概念(如情感、隐喻)的建模困难。
例如,生成“庆祝节日”的视频时,模型会仅能复现常见视觉元素(烟花、人群),但难以捕捉文化语境下的深层含义。
这种情况下,限制了其在需高语义理解场景中的应用。

视频生成本身对算力需求极高,而纯视觉模型需处理更密集的时空信息,我认为会加剧硬件负担。
如何平衡模型效率与生成质量,是未来优化的关键。
免费的就是最贵的,用在这里是合适的。开源模型会被滥用生成深度伪造内容,尽管团队未提及具体防范措施,但社区需建立配套监管机制。
VideoWorld的推出,为多模态AI提供了“视觉优先”的新范式。其技术路径若与语言模型适度结合(如后期引入轻量级文本引导),或可兼顾生成自由度与语义精确性。
探索小样本学习、增量训练等方向,有望进一步提升模型实用性。短期来看,该模型将加速短视频创作、游戏开发等领域的自动化进程;长期而言,其“纯视觉认知”理念会重塑AI基础架构的设计逻辑。
(文:陳寳)