


随着deepseek的爆火,蒸馏推理模型的热度又被推向新高度,年前李飞飞团队的的一篇《s1: Simple test-time scaling》也火了起来。
paper: https://arxiv.org/abs/2501.19393
data: https://huggingface.co/datasets/simplescaling/s1K
这里要给大家先说几点,避免其他文章被带入到误区。
-
s1超过的是o1-preview,没有超过o1甚至o1-mini,有很大区别
-
s1的效果不敌deepseek-r1 800k数据蒸馏的32B模型,差了不少,不是媲美
-
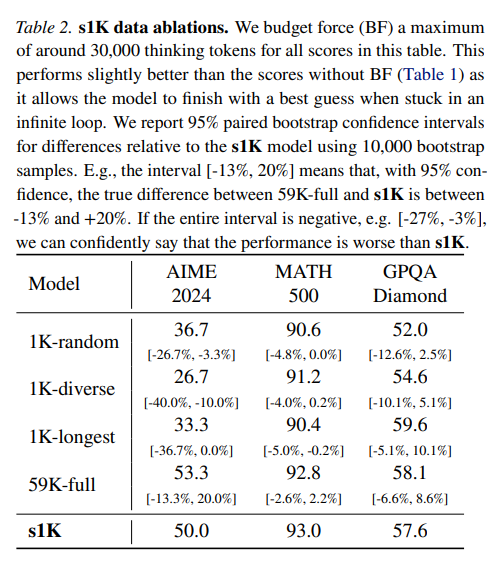
s1即使使用全量59k数据的效果也没有提高很多,甚至在math上还有下降,所以核心是数据质量
-
1k数据是从59K数据中筛选出来的,不是直接蒸馏1K数据就可以效果很好
-
s1使用1k数据是节省了训练时间,但蒸馏的难点在蒸馏数据的构造上
好了,下面开始介绍s1。
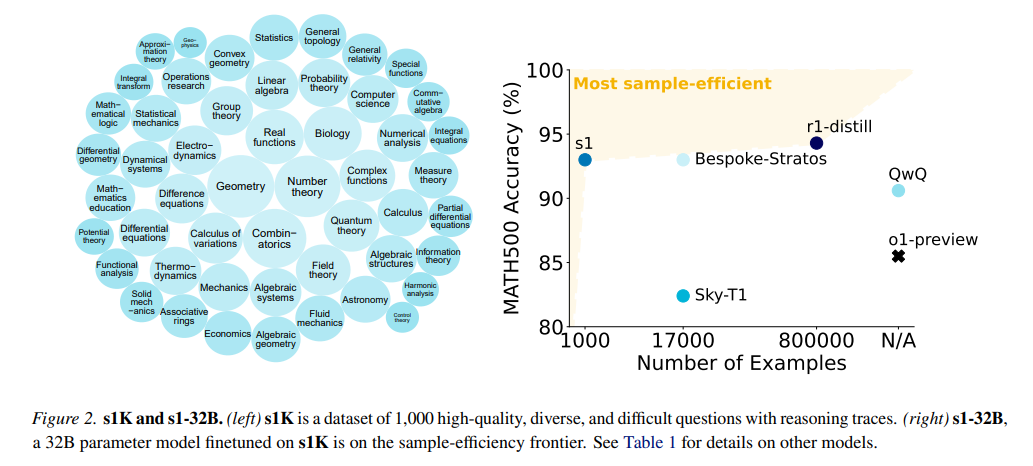
s1的本质是数据筛选+推理预算强制。
有了deepseek-r1-distill之后,我们知道,在不使用RL的情况下,纯SFT也能获得效果较好的推理模型。
而deepseek-r1-distill是使用了80k 数据SFT训练得来,做了这么久的SFT,我们都知道,数据质量、复杂度、多样性直接影响最后微调效果。我之前也分享过一些数据筛选的分享:
-
指令微调数据的高效筛选方法-CaR(排序&聚类)
-
DEITA-大模型指令微调的数据高效筛选方法
-
高质量指令数据筛选方法-MoDS
-
如何从数据集中自动识别高质量的指令数据-IFD指标的使用
s1d的数据筛选也是大同小异,对从16个不同的来源收集的59,029个样本进行数据筛选,
-
质量筛选:删除API错误的问题、删除存在任何格式问题的数据
-
难度筛选:删除Qwen2.5-7B-Instruct或Qwen2.5-32B-Instruct能够正确解答的问题
-
多样性筛选:将所有问题按MSC系统分类,随机选择一个领域的更长推理链条的数据。
除了筛选SFT数据外,s1还提出一种预算强制方法,在推理过程中,强制结束或延长思考时间来控制推理计算时间,从而干预推理效果。
-
强制结束:简单地添加“思考结束标记符”和““Final Answer:””
-
强制思考:抑制生成“思考结束标记符”,并选择性添加“wait”字符到当前推理路径中,鼓励模型持续反思、生成。

注意:s1的核心贡献还有开源了对应的训练数据。
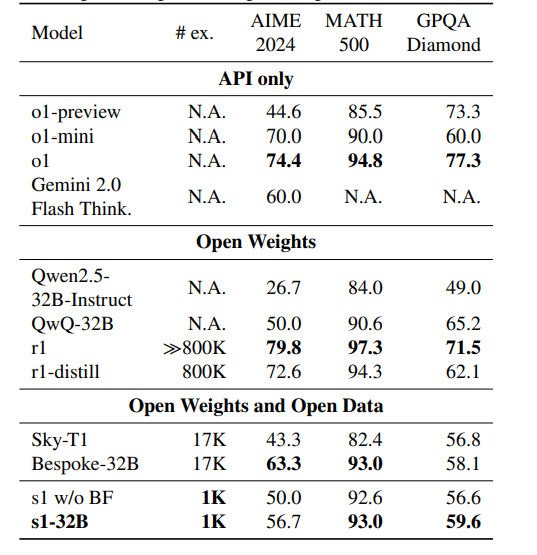
s1的整体效果,如下图所示,比o1-preview、Sky-T1要好,AIME和MATH超过了QWQ,MATH和GPQA超过了Bespoke-32B。
同时,使用预算强制方法的效果十分有效,在三个数据集上均有不错的提高,甚至AIME上提高6.7%。
数据筛选效果,1K数据的训练结果媲美全量数据训练结果,而并且远由于,随机选择数据、取最长数据等方法。
最后,s1还有有点意思的,但是大家一定要理性看待技术,我太怕哪个甲方跟我说,1k数据训练出r1了,想想就难受!
(文:机器学习算法与自然语言处理)