

DeepSeek 正在颠覆 AI 领域!通过推出一系列先进的推理模型,它挑战了 OpenAI 长期占据的主导地位。
最令人兴奋的是,这些革命性的模型完全免费使用,没有任何限制,任何人都可以随时访问并利用它们。是不是听起来像是科幻小说中的情节?但它已然成为现实!
在本教程中,我们将带你深入探讨如何在 Hugging Face 的 Medical Chain-of-Thought 数据集 上微调 DeepSeek-R1-Distill-Llama-8B 模型。

这个经过精心提炼的 DeepSeek-R1 模型,是通过对 DeepSeek-R1 生成的数据微调 Llama 3.1 8B 模型创建的,展示了与原始模型相似的卓越推理能力。这不仅是一次技术突破,也是你进一步掌握 AI 推理能力的最佳时机!
中国 AI 公司 DeepSeek AI 正式开源了其第一代推理模型 DeepSeek-R1 和 DeepSeek-R1-Zero,它们在数学、编码、逻辑等推理任务上的表现,已可与 OpenAI 的 GPT-4(o1)相媲美。
更值得关注的是,DeepSeek-R1-Zero 采用了一种全新的训练方法——大规模强化学习(RL),而非传统的 监督微调(SFT)。这种创新的训练方式使得模型能够独立探索思维链(CoT)推理,能够在面对复杂问题时,进行自我迭代优化输出。

然而,尽管 DeepSeek-R1-Zero 展示了强大的推理能力,但也带来了不容忽视的挑战。由于模型在强化学习中自主进行推理,它可能会产生重复的推理步骤、可读性较差,甚至出现语言混合等问题,这些都可能影响最终输出的清晰度和可用性。
因此,尽管其能力令人震惊,但在实际应用中,如何优化其推理流程,提升输出质量,仍然是一个值得关注的技术难题。
这场AI领域的创新革命正在悄然进行,DeepSeek 正在引领新一轮的推理技术变革。
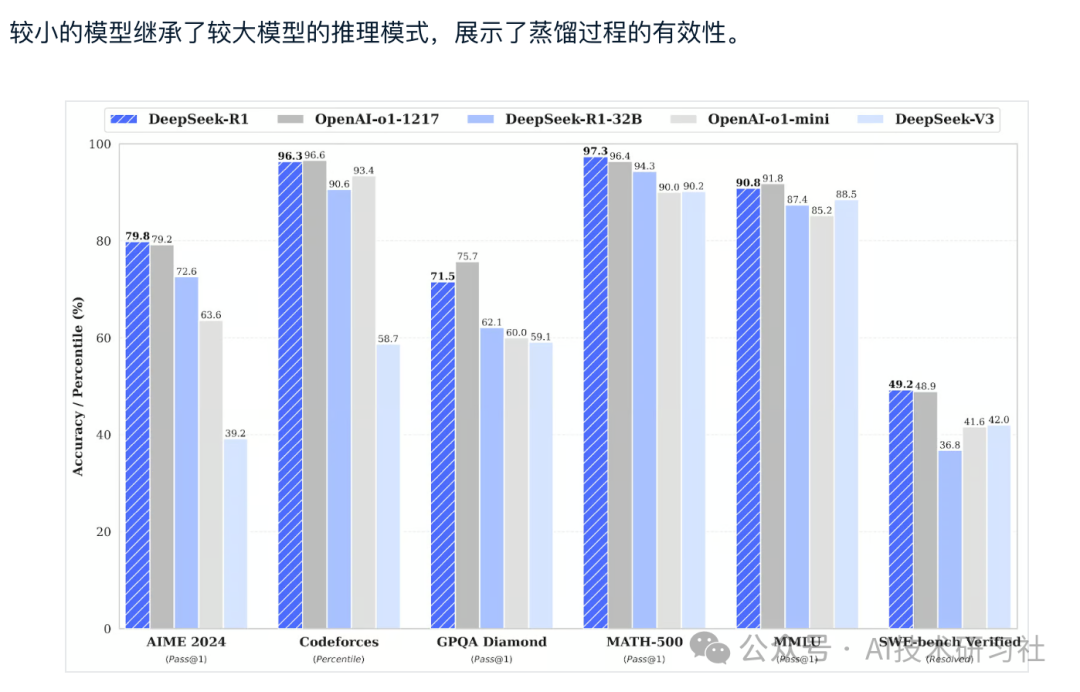
除了需要大量计算能力和内存才能运行的大型语言模型外,DeepSeek 还引入了蒸馏模型。这些更小、更高效的模型已经证明,它们仍然可以实现卓越的推理性能。
这些模型从 1.5B 到 70B 参数不等,保留了强大的推理能力,DeepSeek-R1-Distill-Qwen-32B 在多个基准测试中都优于 OpenAI-o1-mini。
安装 unsloth Python 包。Unsloth 是一个开源框架,旨在使微调大型语言模型的速度提高 2LLMs 倍,内存效率更高。
%%capture!pip install unsloth!pip install --force-reinstall --no-cache-dir --no-deps git+https://github.com/unslothai/unsloth.git
使用我们从 Kaggle Secrets 中安全提取的 Hugging Face API 登录到 Hugging Face CLI。
from huggingface_hub import loginfrom kaggle_secrets import UserSecretsClientuser_secrets = UserSecretsClient()hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")login(hf_token)
使用您的API密钥登录Weights & Biases (wandb),并创建一个新项目来跟踪实验和微调进度。
import wandbwb_token = user_secrets.get_secret("wandb")wandb.login(key=wb_token)run = wandb.init(project='Fine-tune-DeepSeek-R1-Distill-Llama-8B on Medical COT Dataset',job_type="training",anonymous="allow")
对于此项目,我们将加载 DeepSeek-R1-Distill-Llama-8B 的 Unsloth 版本。 此外,我们将以 4 位量化加载模型,以优化内存使用和性能。
from unsloth import FastLanguageModelmax_seq_length = 2048dtype = Noneload_in_4bit = Truetokenizer = FastLanguageModel.from_pretrained(model_name = "unsloth/DeepSeek-R1-Distill-Llama-8B",max_seq_length = max_seq_length,dtype = dtype,load_in_4bit = load_in_4bit,token = hf_token,)
要为模型创建提示样式,我们将定义系统提示并包含用于问题和响应生成的占位符。该提示将指导模型逐步思考并提供合乎逻辑、准确的响应。
prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.Write a response that appropriately completes the request.Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.### Instruction:You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.Please answer the following medical question.### Question:{}### Response:<think>{}"""
在此示例中,我们将向 prompt_style 提供一个医学问题,将其转换为标记,然后将标记传递给模型以生成响应。
question = "A 61-year-old woman with a long history of involuntary urine loss during activities like coughing or sneezing but no leakage at night undergoes a gynecological exam and Q-tip test. Based on these findings, what would cystometry most likely reveal about her residual volume and detrusor contractions?"FastLanguageModel.for_inference(model)inputs = tokenizer([prompt_style.format(question, "")], return_tensors="pt").to("cuda")outputs = model.generate(input_ids=inputs.input_ids,attention_mask=inputs.attention_mask,max_new_tokens=1200,use_cache=True,)response = tokenizer.batch_decode(outputs)print(response[0].split("### Response:")[1])
我们将通过为 complex chain of thought 列添加第三个占位符来略微更改处理数据集的提示样式。
train_prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.Write a response that appropriately completes the request.Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.### Instruction:You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.Please answer the following medical question.### Question:{}### Response:<think>{}</think>{}"""
编写 Python 函数,该函数将在数据集中创建一个 “text” 列,该列由训练提示样式组成。在占位符中填写问题、文本链和答案。
EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKENdef formatting_prompts_func(examples):inputs = examples["Question"]cots = examples["Complex_CoT"]outputs = examples["Response"]texts = []for input, cot, output in zip(inputs, cots, outputs):text = train_prompt_style.format(input, cot, output) + EOS_TOKENtexts.append(text)return {"text": texts,}
我们将从 FreedomIntelligence/medical-o1-reasoning-SFT 数据集加载前 500 个样本,该数据集可在 Hugging Face 中心获得。之后,我们将使用 formatting_prompts_func 函数映射文本列。
from datasets import load_datasetdataset = load_dataset("FreedomIntelligence/medical-o1-reasoning-SFT","en", split = "train[0:500]",trust_remote_code=True)dataset = dataset.map(formatting_prompts_func, batched = True,)dataset["text"][0]
使用目标模块,我们将通过将低排名的采用者添加到模型来设置模型。
model = FastLanguageModel.get_peft_model(model,r=16,target_modules=["q_proj","k_proj","v_proj","o_proj","gate_proj","up_proj","down_proj",],lora_alpha=16,lora_dropout=0,bias="none",use_gradient_checkpointing="unsloth", # True or "unsloth" for very long contextrandom_state=3407,use_rslora=False,loftq_config=None,)
接下来,我们将通过提供模型、分词器、数据集和其他重要的训练参数来设置训练参数和训练器,这些参数将优化我们的微调过程。
from trl import SFTTrainerfrom transformers import TrainingArgumentsfrom unsloth import is_bfloat16_supportedtrainer = SFTTrainer(model=model,tokenizer=tokenizer,train_dataset=dataset,dataset_text_field="text",max_seq_length=max_seq_length,dataset_num_proc=2,args=TrainingArguments(per_device_train_batch_size=2,gradient_accumulation_steps=4,# Use num_train_epochs = 1, warmup_ratio for full training runs!warmup_steps=5,max_steps=60,learning_rate=2e-4,fp16=not is_bfloat16_supported(),bf16=is_bfloat16_supported(),logging_steps=10,optim="adamw_8bit",weight_decay=0.01,lr_scheduler_type="linear",seed=3407,output_dir="outputs",),)
trainer_stats = trainer.train()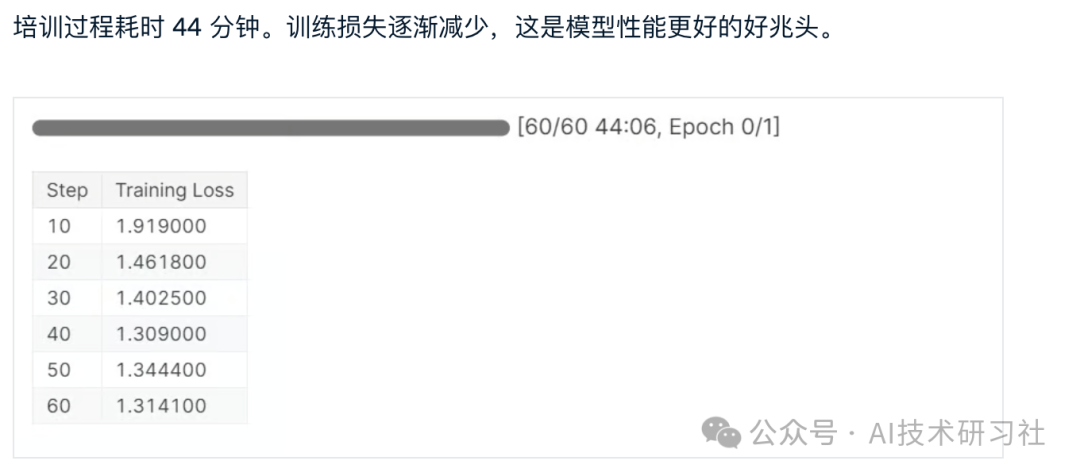
为了比较结果,我们将向微调模型提出与之前相同的问题,以查看发生了什么变化。
question = "A 61-year-old woman with a long history of involuntary urine loss during activities like coughing or sneezing but no leakage at night undergoes a gynecological exam and Q-tip test. Based on these findings, what would cystometry most likely reveal about her residual volume and detrusor contractions?"FastLanguageModel.for_inference(model) # Unsloth has 2x faster inference!inputs = tokenizer([prompt_style.format(question, "")], return_tensors="pt").to("cuda")outputs = model.generate(input_ids=inputs.input_ids,attention_mask=inputs.attention_mask,max_new_tokens=1200,use_cache=True,)response = tokenizer.batch_decode(outputs)print(response[0].split("### Response:")[1])
现在,让我们在本地保存 adopter、full model 和 tokenizer,以便我们可以在其他项目中使用它们。
new_model_local = "DeepSeek-R1-Medical-COT"model.save_pretrained(new_model_local)tokenizer.save_pretrained(new_model_local)model.save_pretrained_merged(new_model_local, tokenizer, save_method = "merged_16bit",)


AI 领域正在迅速变化。开源社区现在正在接管,挑战过去三年来统治 AI 领域的专有模型的主导地位。
开源大型语言模型 LLMs 变得越来越好、更快、更高效,这使得在较低的计算和内存资源上对其进行微调变得比以往任何时候都更容易。
参考:https://www.datacamp.com/tutorial/unsloth-guide-optimize-and-speed-up-llm-fine-tuning
(文:AI技术研习社)