

极市导读
深入探讨DeepSeek的技术突破及其对AI行业的影响。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
Ben Thompson 是科技领域最具洞察力的分析师之一,他的博客 Stratechery 以其对科技行业的深度分析和前瞻性预测而闻名。
Q:为什么你还没写关于DeepSeek的文章?
Ben Thompson:我写了!我上周二就写了关于R1的内容。我依然认可那篇文章的观点,包括我强调的两个关键点(通过纯强化学习实现的涌现链式思维,以及知识蒸馏的强大威力)。我也提到了低训练成本以及芯片禁令的影响。但我当时的观察过于局限于当前AI技术的发展,而我完全没有预见到这条新闻在更宏观的讨论层面,特别是在美中关系方面,会引发如此广泛的影响。
Q:有过类似的误判吗?
Ben Thompson:确实有过。2023年9月,华为发布了Mate 60 Pro,搭载由中芯国际制造的7nm芯片。这颗芯片的存在并没有让密切关注该领域的人感到意外:中芯国际早在一年前就生产了7nm芯片(而我在更早的时候就指出了它的存在),而台积电也曾在不依赖EUV光刻的情况下批量生产7nm芯片(后来的一些7nm制程才开始引入EUV)。英特尔更早之前也曾使用DUV光刻技术生产10nm(相当于台积电的7nm)芯片,只是良率太低,无法盈利。因此,中芯国际用现有设备生产7nm芯片并不让人意外——至少对我来说是这样。
但我完全没预料到的是,华盛顿的反应会如此激烈。美国政府对芯片禁令的急剧升级最终导致拜登政府将芯片销售转变为“许可制”。这背后的原因,是许多人不理解芯片制造的复杂性,被华为Mate 60 Pro突如其来的发布打了个措手不及。我感觉过去72小时里,类似的事情正在发生:DeepSeek取得的具体技术突破——以及它尚未实现的部分——本身并不重要,关键在于人们的反应,以及这种反应揭示了他们原本的假设。
Q:那么DeepSeek具体发布了什么?
Ben Thompson:本周末引发广泛讨论的最直接原因是R1——一个推理能力与OpenAI的o1相当的模型。然而,真正导致市场震动的信息——比如DeepSeek的训练成本——其实早在圣诞节发布的V3版本中就已披露。而支撑V3的关键技术突破,最早可以追溯到去年1月发布的V2版本。
Q:DeepSeek的模型命名规则是不是OpenAI犯下的“最大罪行”?
Ben Thompson:第二大罪行,我们稍后再聊最大的那个。让我们从头开始:V2模型是什么?为什么它很重要?
DeepSeek-V2带来了两个关键突破:DeepSeekMoE和DeepSeekMLA。
DeepSeekMoE中的“MoE”指的是“Mixture of Experts(专家混合)”。像GPT-3.5这样的模型,在训练和推理时会激活整个模型,但实际上,并非所有部分都对特定任务有贡献。MoE通过将模型划分为多个“专家”,只在需要时激活相关专家,从而提升效率。据推测,GPT-4也是一个MoE模型,可能包含16个专家,每个专家约有1100亿参数。
DeepSeekMoE在V2版本中对这一概念进行了创新,包括颗粒度更细的专家划分,以及具备更强泛化能力的共享专家。此外,DeepSeek还优化了训练过程中的负载均衡和路由机制。传统的MoE模型在训练时计算开销较大,但DeepSeek的方法在保持推理高效的同时,也让训练变得更高效。
DeepSeekMLA(Multi-head Latent Attention,多头潜在注意力)则是更大的突破。推理的最大瓶颈之一在于内存占用:不仅需要加载整个模型,还要加载整个上下文窗口(context window)。而上下文窗口在内存中非常昂贵,因为每个token都需要存储一个Key-Value。DeepSeekMLA让Key-Value存储得以压缩,从而大幅降低推理时的内存使用。
这些突破的真正意义——也是你需要关注的重点——在V3版本中才真正显现。V3进一步优化了负载均衡(进一步减少通信开销),并在训练中引入了多token预测(提升每一步训练的密度,再次减少开销)。最终,V3版本的训练成本低得惊人。
DeepSeek宣称,该模型的训练共消耗278.8万H800 GPU小时,按照每GPU小时2美元计算,总成本仅557.6万美元。这个成本低得难以置信。DeepSeek明确表示,这个成本仅指最终的训练运行,不包括所有其他开销。以下是V3论文中的相关内容:
我们再次强调DeepSeek-V3的经济训练成本,如表1所示,这是通过优化算法、框架和硬件协同设计实现的。在预训练阶段,每处理1万亿个token仅需180K H800 GPU小时,即在我们配备2048 H800 GPU的集群上训练3.7天。因此,我们在不到两个月内完成了预训练,总计耗费2664K GPU小时。再加上用于上下文长度扩展的119K GPU小时和后训练的5K GPU小时,DeepSeek-V3的完整训练仅耗费2.788M GPU小时。假设H800 GPU的租赁价格为557.6万。需要注意的是,上述成本仅包括DeepSeek-V3的正式训练,不包含在架构、算法或数据上的前期研究和消融实验成本。
你不能用557.6万美元复制DeepSeek这家公司。
Q:我还是不相信这个数字。
Ben Thompson:实际上,质疑者需要提供证据来反驳这个数字,特别是在你理解了V3的架构之后。还记得我们之前提到的DeepSeekMoE吗?V3具有6710亿参数,但每个token仅计算370亿参数的活跃专家部分,这相当于3333亿FLOPs(浮点运算)。
这里还需要提到DeepSeek的另一个创新点:虽然参数存储时使用BF16或FP32精度,但在计算时会降低到FP8精度。此外,2048张H800 GPU的计算能力为3.97exaFLOPS(即3.97×10¹⁸FLOPS)。训练集包含14.8万亿tokens,当你计算所有数据后,会发现278.8万H800小时确实足以训练V3。再次强调,这只是最终训练的计算量,而不是所有成本,但它是一个合理的数字。
Q:Scale AI的CEO Alexandr Wang说他们有50,000张H100。
Ben Thompson:我不确定Wang的数据来源,但我猜他指的是2024年11月Dylan Patel的一条推文,其中提到DeepSeek拥有超过5万张Hopper GPU。然而,H800也是Hopper GPU,只是由于美国的出口管制,其内存带宽比H100受限得多。
关键在于,DeepSeek的许多创新,都是为了克服H800内存带宽的限制。 如果你仔细计算过前面的内容,就会发现DeepSeek其实是有充足算力的。原因在于:DeepSeek专门将H800的132个计算单元中的20个用于管理跨芯片通信。
这在CUDA(Nvidia的标准编程框架)中是无法实现的,DeepSeek的工程师必须使用PTX(Nvidia GPU的低级指令集,相当于汇编语言)进行编程。这种优化级别极高,只有在使用H800而不是H100时才有意义。与此同时,DeepSeek还需要为模型推理提供算力,这意味着他们的GPU远不止用于训练。
Q:那么,这是否违反了美国的芯片禁令?
Ben Thompson:没有。H100是被禁的,但H800没有被禁。许多人原本以为训练顶级模型必须依赖高内存带宽,但DeepSeek正是围绕这个限制进行了优化,调整了模型架构和基础设施,最终成功解决了这个问题。
再次强调,DeepSeek设计V3的所有决策,只有在受限于H800时才有意义。 如果他们能获得H100,可能会使用更大的训练集群,而不会做那么多专门针对低带宽的优化。
Q:那么,V3是一个顶级模型吗?
Ben Thompson:V3的确能与OpenAI的GPT-4o和Anthropic的Sonnet-3.5竞争,并且似乎比Llama系列的最大模型更强。更值得注意的是,DeepSeek可能通过蒸馏(distillation)从这些模型中提取了高质量token作为训练数据。
Q:什么是蒸馏?
蒸馏是一种从更强的模型中提取知识的方法:你可以给教师模型(teacher model)输入数据,记录它的输出,并用这些数据训练学生模型(student model)。这就是GPT-4 Turbo从GPT-4演化而来的方式。
一般来说,公司只能对自己的模型进行蒸馏,因为他们有完整的访问权限。但如果愿意,仍然可以通过API访问,甚至通过对话界面(chat clients)进行非正式蒸馏。
当然,蒸馏通常违反OpenAI等公司的服务条款,唯一的防范方法是直接封禁IP或者限制API访问。但这仍然是一种普遍存在的训练策略,也正因如此,我们才看到越来越多的模型在逼近GPT-4o的质量。 我们无法100%确定DeepSeek是否对GPT-4o或Claude进行了蒸馏,但老实说,如果他们没有这么做,那才奇怪。
Q:蒸馏对顶级模型来说是个坏消息吧?
Ben Thompson:没错!从好的方面来看,OpenAI、Anthropic和Google也在用蒸馏优化推理模型,以便在面向消费者的应用中运行得更高效。但从坏的方面来看,他们承担了所有顶级模型的训练成本,而其他公司则“白嫖”这些成果。
实际上,这可能是微软与OpenAI渐行渐远的核心经济原因。微软对提供推理服务感兴趣,但不太愿意为1000亿美元的数据中心买单,因为这些模型在商业化之前就可能已经被蒸馏、复制,变得廉价。
Q:这就是为什么所有科技股股价都在下跌吗?
Ben Thompson:从长期来看,模型的普及和推理成本下降(DeepSeek也证明了这一点)对大科技公司来说是好事。
微软:推理成本大幅降低意味着数据中心和GPU需求减少,或者用户量暴增。
亚马逊(AWS):AWS自己的AI模型竞争力较弱,但他们可以用超低成本部署高质量的开源模型,照样赚推理的钱。
苹果:推理的内存需求大幅减少,使边缘推理(edge inference)更加可行,而苹果拥有最强的硬件。苹果芯片的统一内存架构(Unified Memory)比Nvidia游戏GPU更适合AI推理。
Meta(脸书):最大的赢家!Meta所有的AI计划都受益于更低的推理成本,这让他们的AI生态更容易实现。
Google:可能会受损。因为硬件要求下降,削弱了Google TPU的竞争力。而且推理成本降低会催生取代搜索的AI产品,这对Google的核心业务构成威胁。
你问股价为什么跌,我给你的是长期趋势;市场今天反应的只是短期冲击。
Q:等一下,你还没谈R1呢?
Ben Thompson:R1是一个推理模型,类似OpenAI的o1。它可以进行复杂的思考,提高代码、数学和逻辑推理能力。
Q:R1比V3更惊人吗?
Ben Thompson:其实,我花了这么多时间讲V3,是因为V3证明了让市场震惊的技术趋势。R1之所以特别,主要有两个原因:第一,它的存在本身就说明OpenAI并不具备“不可复制的独特优势”。第二,R1是开源的(虽然没有数据集),所以你可以在任何服务器甚至本地运行它,而不需要付费给OpenAI。
Q:DeepSeek是如何训练R1的?
DeepSeek其实训练了两个模型:R1和R1-Zero。R1-Zero才是更值得关注的模型——正如我在上周二的更新中所提到的:
R1-Zero在我看来才是真正的大事。他们的论文中写道:
在本文中,我们迈出了利用纯强化学习(RL)提升语言模型推理能力的第一步。我们的目标是探索大型语言模型(LLM)在没有任何监督数据的情况下,通过纯强化学习过程实现自我进化的潜力。具体而言,我们以DeepSeek-V3-Base作为基础模型,并采用GRPO作为强化学习框架,以提升模型在推理方面的表现。在训练过程中,DeepSeek-R1-Zero自然涌现出了许多强大且有趣的推理行为。经过数千步的强化学习,DeepSeek-R1-Zero在推理基准测试上展现出了超凡的表现。例如,在AIME 2024竞赛上的pass@1分数从15.6%提升到了71.0%,并且在使用多数投票的情况下,该分数进一步提升至86.7%,达到了OpenAI-o1-0912的水平。
强化学习是一种机器学习技术,其中模型被提供一组数据和一个奖励函数。一个经典的例子是AlphaGo,DeepMind给该模型提供了围棋的规则,并设定了“赢得比赛”作为奖励函数,随后让模型自行摸索其它一切策略。这种方法最终被证明比其他更具人为指导的技术更有效。
然而,迄今为止,大型语言模型主要依赖“带有人类反馈的强化学习”(RLHF);在该过程中,人类会参与其中,以帮助引导模型,解决奖励不够明确的难题等。RLHF是GPT-3进化为ChatGPT的关键创新,使得模型可以生成结构良好的段落,提供简明扼要的回答,而不会跑题或产生无意义的内容。
然而,R1-Zero舍弃了“人类反馈”(HF)部分,仅仅使用强化学习。DeepSeek研究团队向模型提供了一系列数学、代码和逻辑问题,并设置了两个奖励函数:一个用于奖励正确答案,另一个用于奖励符合推理过程的正确格式。此外,该方法相对简单:研究人员没有采用“逐步评估”(过程监督)或像AlphaGo那样搜索所有可能答案,而是鼓励模型同时尝试多个答案,并根据这两个奖励函数进行评分。
由此涌现出了一种能够自主发展推理能力和“思维链”(chain-of-thought)的模型,其中甚至出现了DeepSeek研究团队称之为Aha Moments的现象:
在DeepSeek-R1-Zero的训练过程中,我们观察到了一个特别有趣的现象,即Aha Moments。正如表3所示,这一现象出现在模型的中间训练阶段。在这一阶段,DeepSeek-R1-Zero学会了为某个问题分配更多的思考时间,并重新评估其最初的解题方法。这种行为不仅展现了模型日益增强的推理能力,同时也是强化学习如何催生意想不到且复杂结果的一个引人注目的例子。
这种Aha moment不仅对模型而言是一次突破性的发现,对观察它的研究人员而言也是如此。这一现象凸显了强化学习的强大和魅力:相比于直接教授模型如何解题,我们仅仅为它提供正确的激励,它便能自主发展出高级的问题解决策略。 这个Aha Moments是强化学习能够解锁人工智能新智能水平的一个有力证明,为未来更加自主和适应性的模型铺平了道路。
这可能是迄今为止对“痛苦的教训”(The Bitter Lesson)最有力的肯定之一:你无需教AI如何推理,只需给予它足够的计算能力和数据,它就能自学成才!
不过,还差一点:R1-Zero确实具备推理能力,但它的推理方式让人类难以理解。回到论文的介绍部分:
然而,DeepSeek-R1-Zero仍然面临诸如可读性差、语言混杂等挑战。为了解决这些问题并进一步提升推理能力,我们引入了DeepSeek-R1,它结合了一小部分“冷启动数据”(cold-start data)以及多阶段训练流程。具体来说,我们首先收集了数千条冷启动数据,对DeepSeek-V3-Base进行微调。随后,我们像训练DeepSeek-R1-Zero一样执行基于推理的强化学习。当强化学习过程接近收敛时,我们通过拒绝采样(rejection sampling)在RL训练的检查点上创建新的监督微调数据,并结合来自DeepSeek-V3的监督数据(涉及写作、事实问答和自我认知等领域),对DeepSeek-V3-Base进行再训练。在新数据微调后,模型检查点会经历额外的强化学习过程,并纳入所有场景下的提示语。经过这些步骤,我们最终得到了DeepSeek-R1,其性能已达到OpenAI-o1-1217的水平。
这听起来与OpenAI在o1训练过程中采用的方法非常相似:DeepSeek研究团队先用一组“思维链”示例来引导模型学习适合人类理解的格式,然后再利用强化学习增强推理能力,并进行一系列编辑和优化步骤。最终产出的模型在推理能力和可读性方面都足以与OpenAI-o1竞争。
DeepSeek可能确实受益于蒸馏,尤其是在训练R1方面。不过,这本身就是一个重要的结论:我们正处于AI模型教AI模型、AI模型自我训练的时代,眼前正是AI起飞情境的实时展开。
Q:那么,我们接近AGI了吗?
Ben Thompson:看起来确实如此。这也解释了为什么Softbank(以及孙正义能聚集的投资者)愿意为OpenAI提供微软不愿提供的资金:他们相信我们正处于一个临界点,抢先一步确实会带来真正的回报。
Q:但R1现在不是领先了吗?
Ben Thompson:我认为并不是,这个说法被夸大了。R1与o1旗鼓相当,尽管它在某些能力上存在漏洞,暗示其部分能力可能源自o1-Pro的蒸馏。而与此同时,OpenAI已经展示了o3——一个更强大的推理模型。DeepSeek无疑是效率方面的领导者,但这与整体领先是两个概念。
Q:那为什么大家都在恐慌?
Ben Thompson:我认为有几个原因。首先,中国赶上了美国顶级实验室,这让人震惊,毕竟很多人都认为中国在软件方面不如美国。这可能是我之前低估市场反应的关键原因。 实际上,中国的软件产业整体上非常强大,在AI模型构建方面也有很好的成绩。
其次,V3的低训练成本以及DeepSeek的低推理成本。 这对我来说也是个意外,但数据是合理的。这也让市场对Nvidia感到紧张,毕竟这对其市场地位有很大影响。
第三,DeepSeek在芯片禁令的背景下仍然取得了这一成就。 尽管芯片禁令有漏洞,但DeepSeek很可能是用合法芯片完成的。
Q:我持有Nvidia股票!完蛋了吗?
Ben Thompson:这确实对Nvidia的故事构成了真正的挑战。Nvidia有两大护法:CUDA是开发者的首选语言,而CUDA只能在Nvidia芯片上运行。Nvidia在多芯片互联成大型虚拟GPU方面拥有巨大领先优势。
这两大护法是相辅相成的。我之前提到,如果DeepSeek能获得H100,他们可能会用更大的集群来训练模型,因为这会更省事。但他们没有,带宽受限,这影响了他们的模型架构和训练基础设施决策。而看看美国实验室,它们在优化方面并未投入太多精力,因为Nvidia一直在提供更强大的系统,满足它们的需求。最简单的路径就是付钱给Nvidia。然而,DeepSeek刚刚证明了另一条路径的可行性:通过深度优化,即使在较弱的硬件上,仍然可以取得惊人的结果。这表明,仅仅砸钱给Nvidia,并不是改进模型的唯一方式。
不过,Nvidia仍然有三个优势。第一,DeepSeek的方法如果应用到H100或即将推出的GB100上,会有多强?他们找到了更高效的计算方式,并不意味着更多计算资源就没用了。第二,长期来看,较低的推理成本应该会推动更广泛的使用。微软CEO Satya Nadella在深夜发推,显然就是为了向市场传递这个信息。第三,像R1和o1这样的推理模型,其卓越性能依赖于更多计算资源。如果AI的进步仍然依赖于更多算力,那Nvidia就仍然是受益者。
微软CEO Satya Nadella在深夜发布了一条推文,几乎可以肯定是针对市场的,他明确表示了这一点:
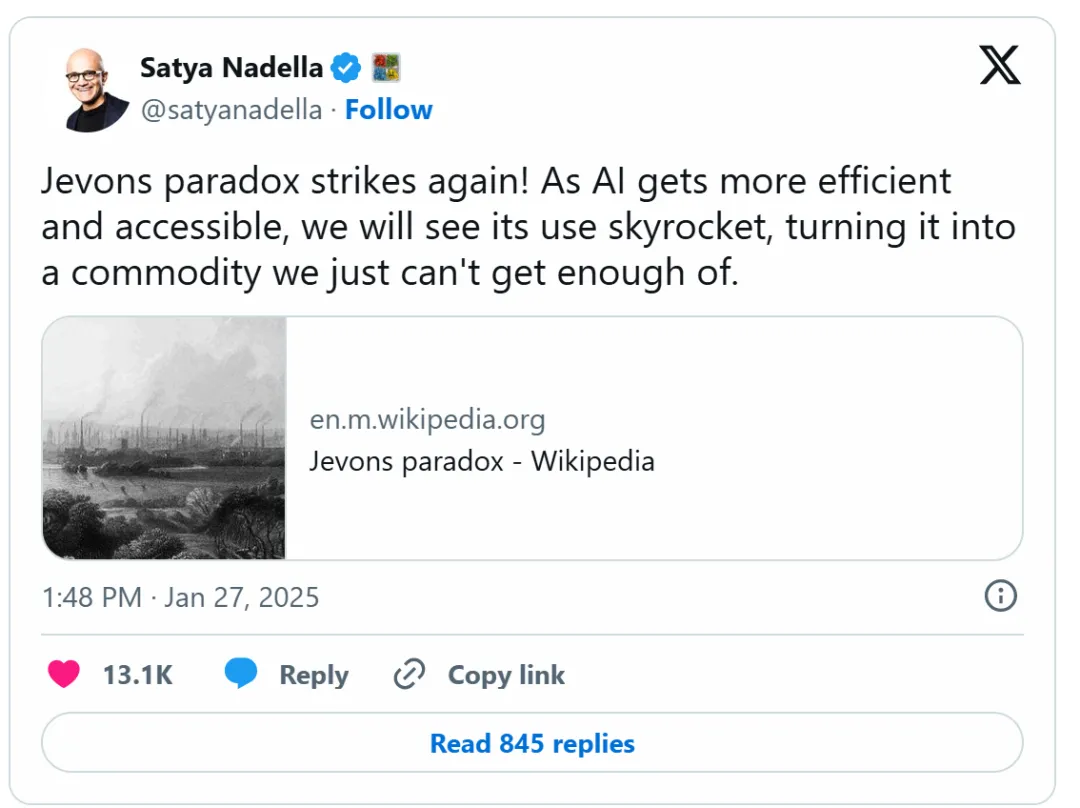
尽管如此,情况并非一片光明。至少,DeepSeek的高效性和广泛可用性让Nvidia最乐观的增长预期受到了质疑,至少在短期内是这样。此外,模型和基础设施优化的成功也表明,探索推理方面的替代方案可能带来重大收益。例如,在独立的AMD GPU上运行推理可能比使用AMD较弱的芯片间通信能力更具可行性。而推理模型的进步,也让比Nvidia GPU更专业化的推理专用芯片的价值大幅提升。
简而言之,Nvidia不会消失,但Nvidia的股价却突然面临更多尚未被市场定价的不确定性。这反过来会拖累整个市场。
Q:那么,芯片禁令呢?
Ben Thompson:最简单的说法是,考虑到美国在软件上的领先优势正迅速消失,芯片禁令的重要性反而被凸显了。软件和技术知识无法被封锁——关于这一点,我们早已讨论并得出结论。但芯片是实物,美国有理由让中国无法获得。
与此同时,我们也需要保持谦逊,因为早期的芯片禁令似乎直接促成了DeepSeek的创新。而这些创新不仅适用于走私的Nvidia芯片或被削弱的H800,也适用于华为的Ascend芯片。事实上,可以说芯片禁令的主要后果,就是今天Nvidia股价的暴跌。
我更担忧的是,芯片禁令背后的思维方式:美国不是通过未来的创新来竞争,而是通过封锁过去的创新来竞争。 短期来看,这或许有帮助——毕竟,如果DeepSeek有更多算力,他们的效果可能会更好。但从长远来看,这只会在芯片和半导体设备这两个美国占据主导地位的行业中,播下新的竞争种子。
Q:就像AI模型一样?
Ben Thompson:AI模型正是一个很好的例子。我之前提到会谈OpenAI最严重的错误,我认为那就是2023年拜登的AI行政命令。我在《Attenuating Innovation》中写道:
这段话的核心观点是:如果你接受“监管会巩固现有巨头”的前提,那么就很值得注意,为什么那些最早赢得AI竞赛的公司,反而是最积极在华盛顿制造AI恐慌的群体。他们的关切似乎并没有严重到让他们停止自己的AI研究,相反,他们自诩为负责任的一方,主动呼吁监管——而如果这种监管最终能扼杀未来的竞争者,那当然更好了。
这一段主要谈的是OpenAI,以及更广泛的旧金山AI社区。多年来,正是那些致力于构建并控制AI的人,在大肆渲染AI的危险。 这些所谓的危险,正是OpenAI在2019年发布GPT-2时转向封闭模式的理由:
“由于担忧大型语言模型可能被用来大规模生成欺骗性、带有偏见或滥用性质的语言,我们仅发布一个更小版本的GPT-2及其采样代码(opens in a new window)。我们不会发布数据集、训练代码或GPT-2模型权重……我们意识到,一些研究人员具备复现并开源我们成果的技术能力。我们认为我们的发布策略限制了最初可能这样做的组织,并为AI社区提供了更多时间来讨论此类系统的影响。”
“我们还认为,各国政府应考虑扩大或启动更多系统性举措,以监测AI技术的社会影响及其传播情况,并衡量这些系统能力的进展。如果推进,这些努力可能会为AI实验室和政府在发布决策及AI政策方面提供更坚实的证据基础。”
这段话的傲慢程度让人发指:六年过去了,全世界都能获取比当年的GPT-2强大得多的模型权重。OpenAI试图通过美国政府来维持控制权的策略彻底失败了。在这期间,由于顶尖模型没有开源,我们错失了多少创新机会?更广泛地说,我们又浪费了多少时间和精力在游说政府建立一个护城河,而DeepSeek刚刚摧毁了它?这些时间和精力原本可以用来推进真正的创新。
Q:所以,你不担心AI末日论吗?
Ben Thompson:我完全理解这种担忧,毕竟我们已经进入AI训练AI、AI自学推理能力的阶段。但我也清楚,这趟列车无法停止。更重要的是,这正是开放性至关重要的原因:我们需要世界上有更多AI,而不是让一个不受监督的董事会来统治所有人。
Q:等等,为什么是中国在开源他们的模型?
Ben Thompson:准确来说,是DeepSeek在开源。其CEO梁文峰在一次采访中表示,开源是吸引人才的关键:
“面对颠覆性技术,封闭只是暂时的。即便是OpenAI的封闭策略,也无法阻止他人赶上。 因此,我们的核心价值在于团队——同事们在这一过程中成长,积累技术知识,形成一个有创新能力的组织和文化,这才是我们的护城河。开源、发表论文,对我们而言实际上没有成本。对于技术人才来说,看到他人跟随自己的创新,会有极大的成就感。事实上,开源更多是一种文化行为,而非商业行为,参与其中能赢得尊重。 对于一家公司而言,这种文化也具有吸引力。”
那篇采访中,采访者接着问梁文峰,这种策略未来会改变吗?DeepSeek目前带有一种理想主义色彩,类似于OpenAI的早期阶段,而且它是开源的。未来你们会转向封闭吗?OpenAI和Mistral都从开源转向了封闭。
梁文峰回答:“我们不会转向封闭。我们认为,首先建立一个强大的技术生态系统比什么都重要。这不仅仅是理想主义,而是符合商业逻辑的。如果模型是商品化的——目前看来确实如此——那么长期的竞争优势来自于更优的成本结构,而DeepSeek正是实现了这一点。这也呼应了中国如何在其他行业取得主导地位的方式。 这种思维方式与大多数美国公司的差异很大,美国公司通常依赖差异化产品来维持更高的利润率。”
Q:那么,OpenAI完了吗?
Ben Thompson:未必。ChatGPT让OpenAI意外地成为了一家消费级科技公司,也就是说,它成为了一家产品公司。OpenAI仍然可以通过订阅和广告的组合,在可商品化的模型基础上建立一个可持续的消费业务。而且,它仍在赌AI起飞竞赛的胜利。
相反,Anthropic可能是这次最大的输家。 DeepSeek的App登顶了App Store,而Claude在旧金山之外几乎没有获得关注。API业务表现更好,但API公司普遍最容易受到商品化趋势的冲击(值得注意的是,OpenAI和Anthropic的推理成本看起来比DeepSeek高得多,因为它们原本是在获取高额利润,但这部分利润正在消失)。
Q:所以,这一切都很令人沮丧吗?
Ben Thompson:其实不然。我认为DeepSeek给几乎所有人带来了巨大的礼物。最大的赢家是消费者和企业,他们可以期待一个几乎免费AI产品和服务的未来。长远来看,朱庇特悖论(Jevons Paradox)将主导局势,AI的使用者最终都会是最大的受益者。
另一批赢家是大型消费科技公司。在一个免费AI的世界里,产品和渠道最重要,而这些公司早已在这场竞争中获胜。中国也是一个大赢家,这一点可能需要时间才能完全显现。中国不仅可以直接使用DeepSeek的技术,而且DeepSeek相对于美国顶尖AI实验室的成功,可能会进一步激发中国的创新热情,让他们意识到自己可以竞争。
剩下的是美国,以及我们必须做出的选择。从逻辑上讲,我们可以选择加倍采取防御措施,比如大幅扩大芯片禁令,并对芯片和半导体设备实施类似欧盟技术监管的许可制度。或者,我们可以认识到自己面临真正的竞争,并给自己“竞争的许可”。别再杞人忧天,别再游说监管——相反,我们应该走向另一极端,砍掉公司内部所有与胜利无关的冗余。如果我们选择竞争,我们仍然可以赢。而如果我们赢了,我们将要感谢这家中国公司。

(文:极市干货)