
OpenAI 刚刚发布了一份研究报告,主题是关于人工智能在竞技编程领域的进展。他们展示了自家的大模型是如何一步步从“编程小白”成长为可以和顶尖程序员 PK 的“高手”

竞技编程,可能有些朋友不太熟悉,简单来说就是比拼编程能力和算法技巧的比赛,像 ACM、ICPC、Codeforces 这些平台就聚集了很多编程高手
报告里提到,最初的模型表现平平,在编程方面显得比较吃力。但关键的转折点是 大型推理模型 的出现,特别是结合了 强化学习 (Reinforcement Learning) 进行训练之后,o1到o3模型变强的“心路历程”,但是方法依然是个迷,问就是四个字:强化学习
故事的开端:强化学习赋能 “推理” 大脑
OpenAI 这次报告的核心,其实还是他们一直强调的 强化学习 (Reinforcement Learning, RL) 。报告一开始就明确指出,RL 是提升大型语言模型 (LLMs) 在复杂编程和推理任务上性能的 关键驱动力
为了验证 RL 的效果,OpenAI 首先推出了 通用推理模型 OpenAI o1。这个模型在训练时,特别注重提升 链式思考 (chain-of-thought reasoning) 能力。简单来说,就是让 AI 学会像人类一样,一步一步地分析问题、拆解难题,最终找到解决方案
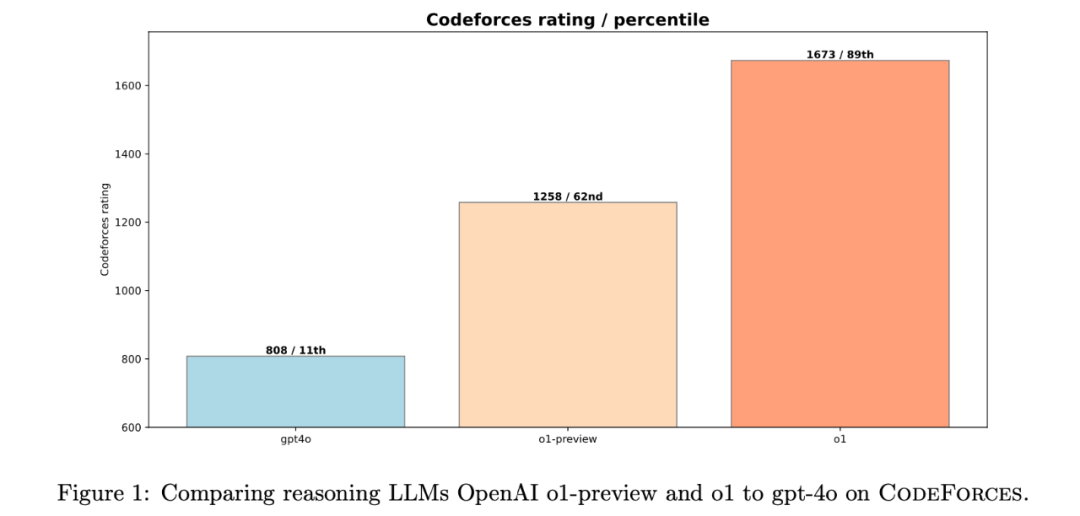
图:OpenAI 推理模型 o1-preview, o1 与 gpt-4o 在 Codeforces 上的性能对比图
数据说话,效果惊人! 在模拟的 Codeforces 竞赛环境中,o1 模型的表现相比之前的模型 大幅提升。 它的 Elo 评分从 1258 分 (62nd percentile) 直接跃升到 1673 分 (89th percentile)!
挑战 IOI:特训模型 + 人工策略 “双剑合璧”
OpenAI 的目标远不止于此。为了挑战更具含金量的 国际信息学奥林匹克竞赛 (IOI),他们对 o1 模型进行了 专项强化训练,并打造了 o1-ioi 模型。同时,为了确保在 IOI 这种高强度竞赛中取得好成绩,研究团队还 “祭出” 了 手工打造的测试时策略 (hand-crafted test-time strategies)
这些策略,可以理解为人类专家为 AI 模型 “量身定制” 的一套竞赛技巧 “组合拳”,包括:
-
• 子任务分解 (Subtask Decomposition): 将 IOI 复杂问题拆解成更小的、更易于解决的子任务。IOI 竞赛评分也是基于子任务的,这个策略非常契合竞赛特点
-
• 大规模采样 (Large-Scale Sampling): 针对每个子任务,模型生成 10,000 个候选解决方案,通过 “广撒网” 的方式,提高找到正确答案的概率
-
• 聚类与重排序 (Clustering and Reranking): 对生成的候选方案进行聚类,然后根据预设的评分标准进行重排序,选出最优的方案进行提交
-
• 模型生成测试用例与验证 (Model-Generated Test Inputs & Validators): 利用模型自身生成测试用例和验证器,用于评估和筛选候选方案的正确性。
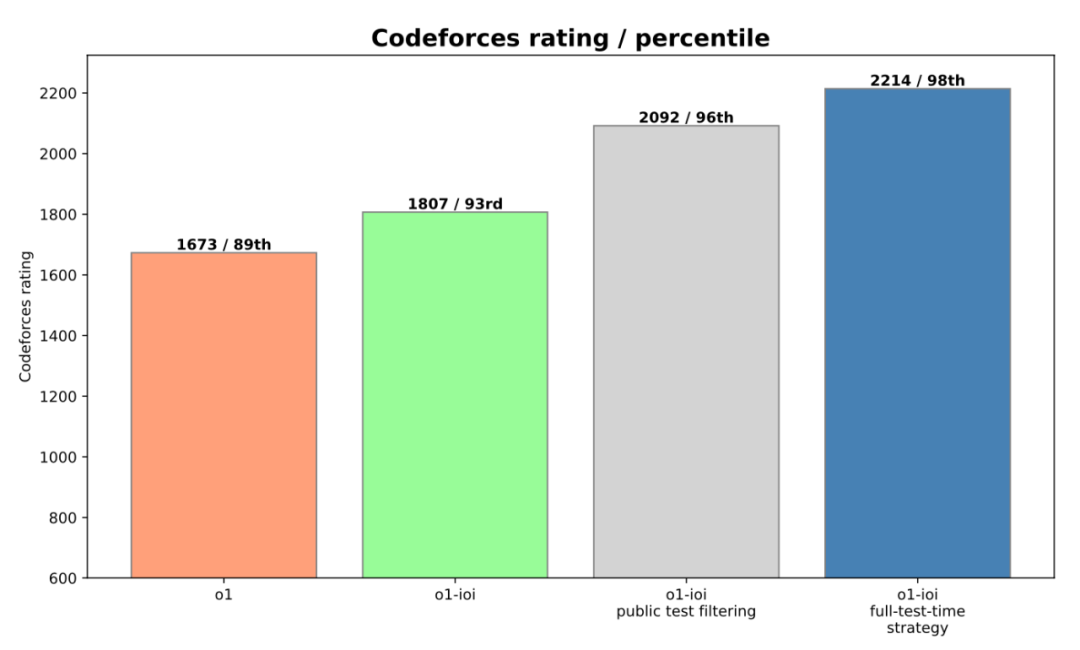
图:进一步训练 OpenAI o1 模型并加入测试时策略后,模型性能的提升
“人机协作” 威力显现! 在 手工策略 的加持下,o1-ioi 模型在 IOI 竞赛中获得了 49% 的排名,得分 213 分。更令人振奋的是,当 OpenAI 放宽提交次数限制 (从官方的每题 50 次放宽到 10,000 次) 后,o1-ioi 模型竟然 一举夺得金牌!得分高达 362.14 分

报告中还提到,这些 手工策略 非常有效,为 o1-ioi 的 IOI 成绩 提升了约 60 分,在 Codeforces 上的 percentile 排名也 提升了 5% (从 93% 提升到 98%, Elo 评分达到 2214 分)。
纯粹 RL 的力量:o3 模型 “无招胜有招” 的自主进化
虽然 o1-ioi 模型取得了亮眼的成绩,但 OpenAI 并没有满足于 “人机结合” 的模式。他们更进一步,推出了 新一代模型 o3。这次,他们想要探索 纯粹强化学习 的极限—— 完全不依赖任何人工策略,只通过 RL 训练,AI 能否在竞技编程领域达到顶峰?
o3 模型在 Codeforces 上的 Elo 评分更是达到了 2724 分 (99.8th percentile), 全球排名 Top 0.2%, 接近 全球 Top 175 名 的水平!
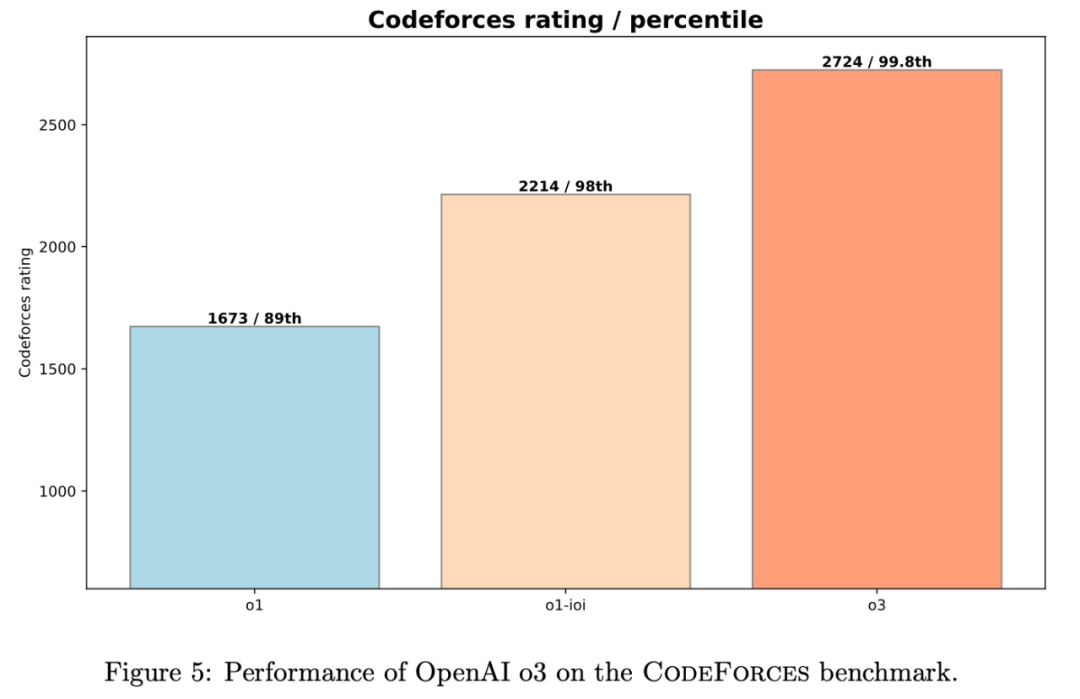
图:OpenAI o3 模型在 Codeforces 上的性能表现
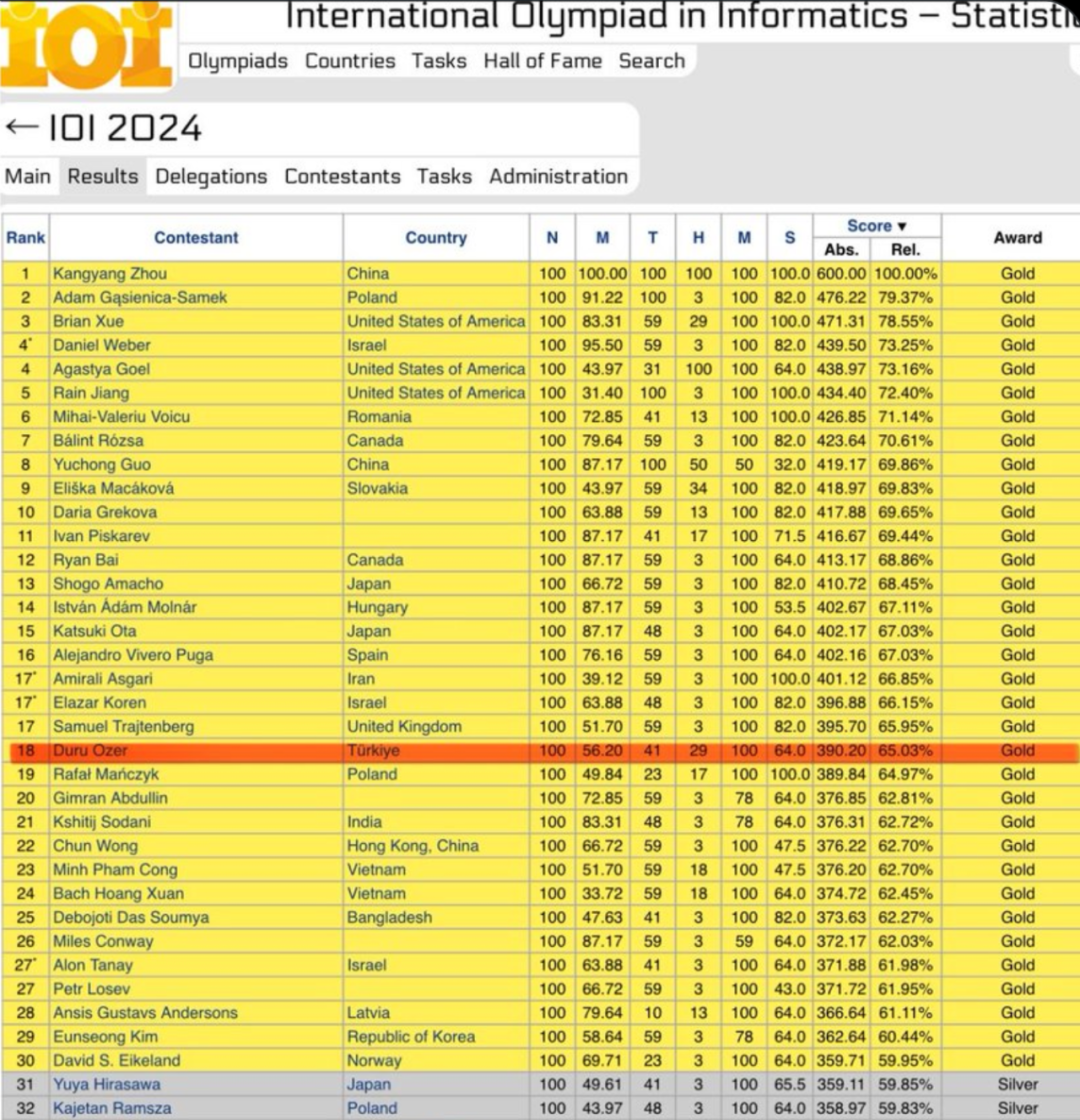
o3 模型在没有任何人工策略辅助的情况下,竟然在官方 IOI 竞赛的严格约束下,也成功斩获金牌! 🏆 得分高达 395.64 分,进一步超越金牌线

OpenAI o3 在 2024 年国际信息学奥林匹克竞赛(IOI)中获得 395.64分(满分 600 分),获得金牌,世界排名第 18 位。该模型没有受到这些数据的污染,并且使用了 50 次提交限制。这也印证了奥特曼的说法今年我们很可能会看到超人的编码模型
“自主进化” 的解题策略:暴力验证,殊途同归
更深入地分析 o3 模型的 解题过程 (chain of thought),研究人员发现,o3 模型竟然 自主领悟 并发展出了一套 测试时策略!其中一个策略,与人类程序员的常用技巧 不谋而合:
-
1. 先编写一个简单粗暴的 “暴力解法” (brute-force solution),确保程序的基本功能正确
-
2. 再利用这个 “暴力解法”,去验证更复杂、更优化的算法,确保优化后的算法在逻辑上也是正确的
图6:o3 模型自主测试解决方案的流程示意
这种先 “保底” 再 “优化” 的思路,是不是和我们人类程序员在竞赛中常用的策略 如出一辙?AI 不仅学会了编程,还学会了 人类的思考方式, 这才是 o3 模型最令人震撼的地方!
不止于竞赛:RL 提升 AI 的 “通用” 编程能力
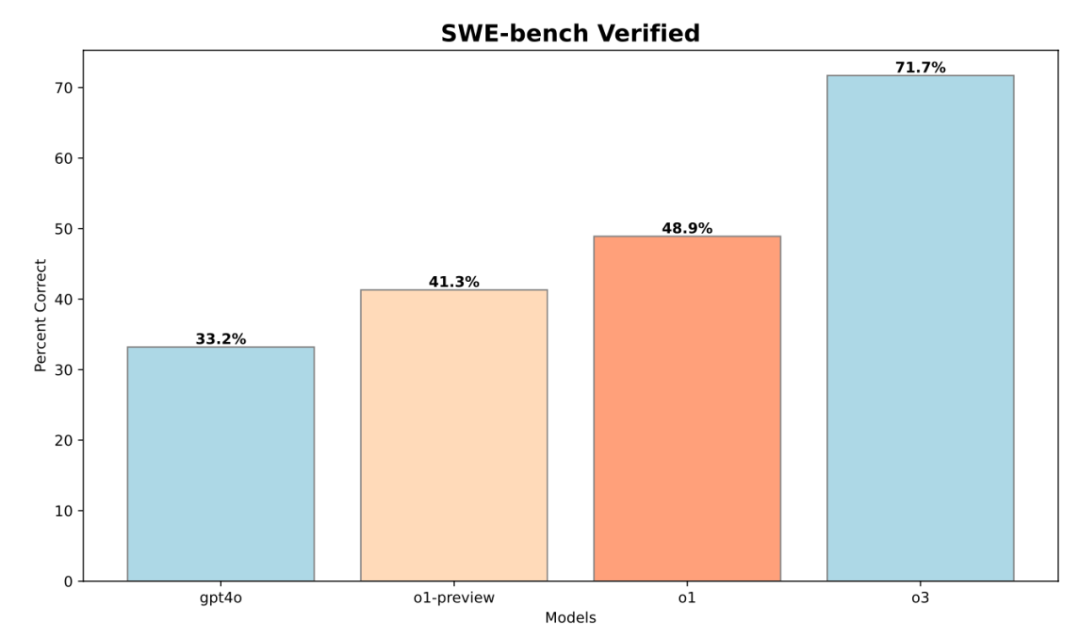
竞技编程的成功,只是 OpenAI 这次研究的一个侧面。他们还评估了这些模型在 软件工程 (Software Engineering, SWE) 任务中的表现,使用了 HackerRank Astra 和 SWE-bench Verified 两个行业benchmark 数据集
结果显示,经过强化学习训练的模型,在软件工程任务上的 Pass@1 (首次尝试成功率) 和 Avg Score (平均得分) 都得到了显著提升
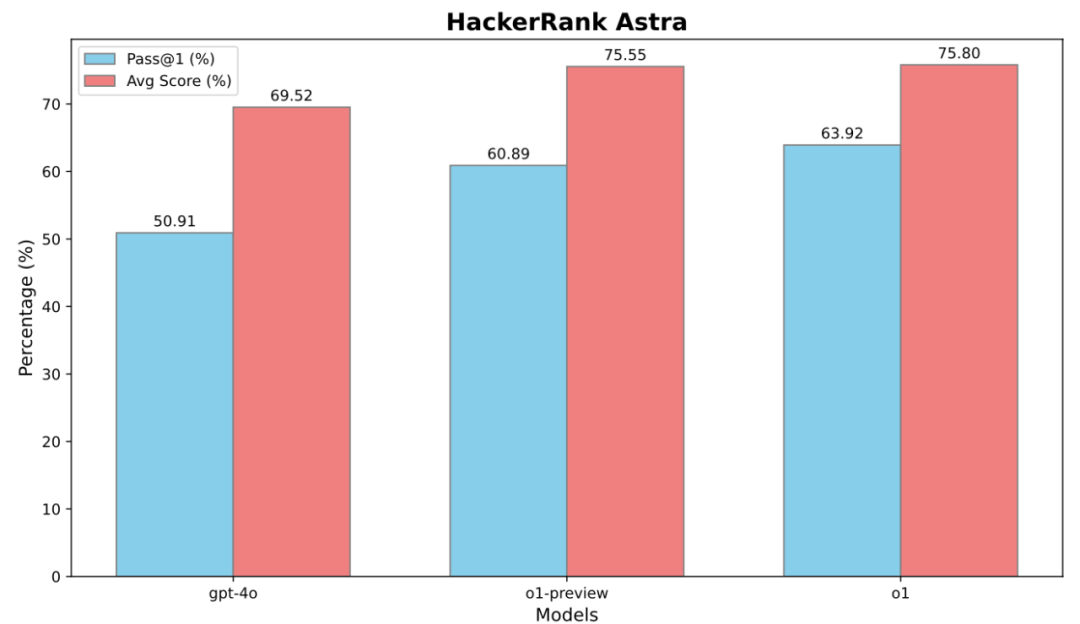
o3 模型在 SWE-bench Verified 数据集上,相比 o1 模型,Pass@1 提升了 22.8%! 这表明,强化学习不仅能提升 AI 的竞赛编程能力,也能有效提升其在更广泛的软件开发领域的应用能力
报告中关键数据回顾:
Codeforces Elo 评分: o1-preview: 1258 (62nd percentile), o1: 1673 (89th percentile), o1-ioi: 2214 (98th percentile), o3: 2724 (99.8th percentile, Top 0.2%, 全球 Top 175 左右)
IOI 竞赛得分: o1-ioi (官方约束): 213 分 (49th percentile), o1-ioi (放宽约束): 362.14 分 (金牌), o3 (官方约束): 395.64 分 (金牌). 手工策略为 o1-ioi IOI 提升 60 分, Codeforces percentile 提升 5%
-
• SWE-bench 性能提升: o3 相比 o1, Pass@1 提升 22.8%. HackerRank Astra 数据也显示类似提升
Codeforces 模拟竞赛评估方法 (Appendix B):
-
• 使用 Division 1 级别 竞赛题目 (2023 年底至 2024 年后)。
-
• 采用 完整测试集 (full test suite), 模拟官方 Codeforces 评分环境。
-
• 严格遵守 时间/内存限制
-
• 进行 污染检查 (contamination check),确保测试题目未在模型训练数据中出现
-
• 使用 Elo 评分系统 评估模型在 Codeforces 上的等级和 percentile 排名。
IOI 代码示例 (Appendix C):
写在最后:
这份报告就是在讲强化学习的威力,只不过OpenAI只告诉了结果,现在大家都知道了,因为DeepSeek R1已经证明了同样的事情,但是DeepSeek附送了详细的技术报告,告诉了强化学习实施的方法和过程
参考:
https://arxiv.org/pdf/2502.06807
⭐
(文:AI寒武纪)