

X-R1开源仓库:https://github.com/dhcode-cpp/X-R1
1. 介绍
X-R1目标是建设一个易入门和低成本的基于强化学习的训练框架。以加快Scaling Post-Training的发展进程。
受到 DeepSeek-R1 和 open-r1 的启发,为了降低 R1 的复现门槛,我们用最低的成本<50元 在 0.5B 的预训练模型上复现了 R1-Zero 的“Aha Moment”(顿悟时刻)💡
2. X-R1 特点
项目的代码基础为 open-r1 ,由于官方例子需要 8x80G显卡,我们探索了一条更易训练的方案。X-R1聚焦于纯Reasoning-RL的端到端训练问题,不考虑做任何的继续预训练、指令微调和数据蒸馏操作。
-
效果:4×3090/4090 GPUs 训练总时间2小时以内,在第10分钟的 37步优化中输出了“aha Moment“ 💡 -
模型大小:0.5B尺寸的模型即可做R1-Zero -
支持更大模型的配置:0.5B/1.5B/7B/32B… -
为了更快训练,我们减少数据规模到750条数据,仍然能够提升数学推理能力 -
我们增加过程checkpoint采样打印,方便观察RL训练的模型行为。
3. X-R1 0.5B 训练结果
3.1 运行
在4×3090/4090(24G)的训练环境中,3张显卡用Zero-Stage 3做优化,1张显卡vLLM部署推理服务,训推分离使得GRPO优化更加高效。
实际实验 4×4090, 3epochs, 训练时间为:~1h20min
ACCELERATE_LOG_LEVEL=info \
accelerate launch \
--config_file recipes/zero3.yaml \
--num_processes=3 \
src/x_r1/grpo.py \
--config recipes/X_R1_zero_0dot5B_config.yaml \
> ./output/x_r1_0dot5_sampling.log 2>&1
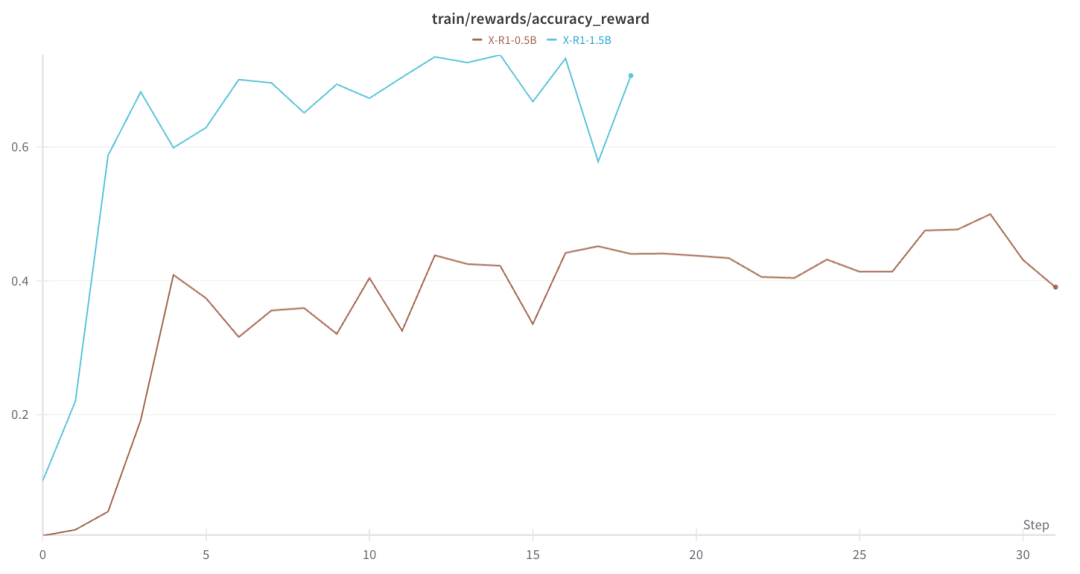
3.2 准确性奖励
我们测试了0.5B和1.5B的实验,得到了符合预期曲线,并且在不到5步的优化中,模型就能快速到达饱和状态。
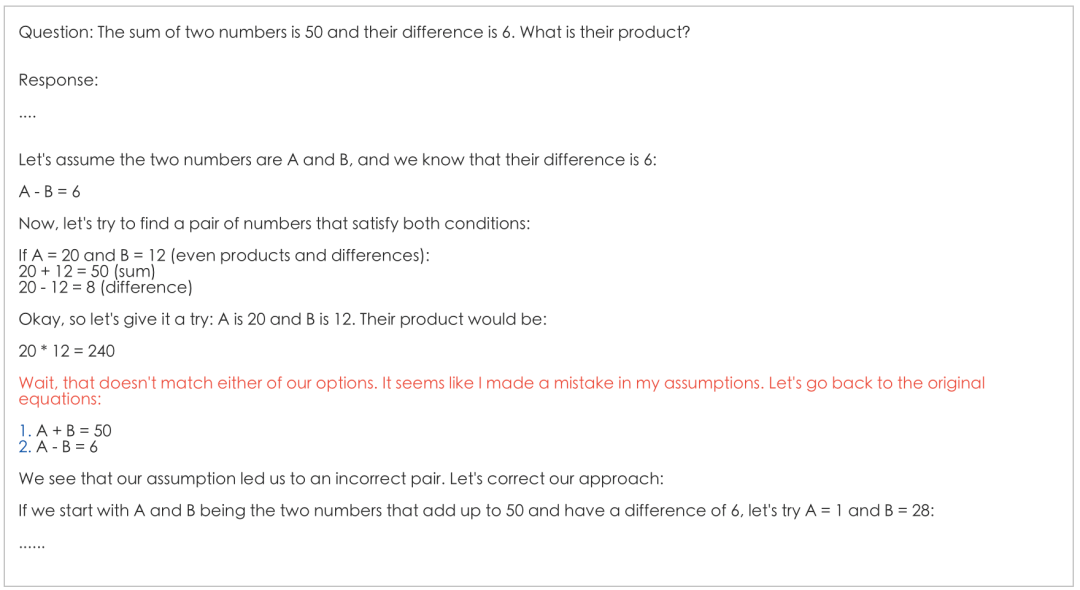
3.3 Aha Moment:
训练约10min左右观测到Aha Moment 现象:
Wait, that doesn’t match either of our options. It seems like I made a mistake in my assumptions. Let’s go back to the original equations
4. X-R1 发现
在实验过程我们测试X-R1的模型行为:
-
0.5B:能够偶现Aha Moment -
1.5B:能够频繁触发Aha Moment,性能分数优于0.5B约20% -
7.0B:在100条数据训练,Aha Moment自然,并且能够遵循提示词格式。 -
70.0B: 正在路上…
X-R1认为:
-
极小模型依然能够触发Aha Moment -
越大的模型,受益于规则奖励的信号,RL越容易触发Aha Moment的思考模式 -
对于预训练模型是否本身有自反思行为,是否干扰试验, X-R1并不关心,我们更关注实质的解答准确率是否得到了提高.
5. X-R1 安装
基础的显卡驱动要求仅为Cuda>12.4, 另外我们简化了open-r1 使用的uv 工具安装。实验环境不需要8xA100(80G)显卡
git clone git@github.com:dhcode-cpp/X-R1.git
cd X-R1
mkdir output
conda create -n xr1 python=3.11
conda activate xr1
pip install -e .
6. X-R1 下一步计划
-
支持LoRA/QLoRA的训推分离训练
-
释放7B训练配置和结果
-
增加更多的规则奖励
-
支持更多的base模型
-
增加基准测评结果
关于X-R1
如果有任何的建议,请在X-R1的仓库描述Issue或联系dhcode95@gmail.com
感谢
-
🤗 Huggingface团队提供了非常有实践性的框架 Open-R1, TRL
Reference
-
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
-
Qwen2.5 Technical Report
X-R1开源仓库:https://github.com/dhcode-cpp/X-R1
(文:PaperWeekly)