

极市导读
首个专门用于评估多模态大模型(MLLMs)在真实世界场景中全模态理解能力的基准测试集。研究发现现有的开源多模态模型在真实场景中的理解能力有限,即使是表现最好的专有模型准确率也仅为48%,显示出在精确的全模态理解方面仍有巨大的提升空间。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

论文链接:https://arxiv.org/pdf/2502.04326
项目链接:https://jaaackhongggg.github.io/WorldSense/
🔥现有的Agents在现实世界的全模态理解方面存在重大局限性:
亮点直击
介绍了 WorldSense,第一个专门用于评估 MLLM 在真实世界场景中全模态理解能力的基准。WorldSense 的特点是全模态集成、多样化的视频类别以及高质量的问答对; 进行了广泛的实验来评估当前 MLLM 在真实世界全模态理解方面的能力。实验结果表明,开源的视频-音频 MLLM 仅略优于随机猜测,而即使是表现最好的专有模型也仅达到 48% 的准确率,显示出在精确的全模态理解方面仍有巨大提升空间; 通过详细分析,研究了影响真实世界全模态理解的关键因素。结果表明,声音信息、视觉线索和高密度的时间采样都对模型性能产生重大影响。这些发现为未来真实世界全模态理解的发展提供了有价值的指导。
总结速览
解决的问题
当前多模态大模型(MLLMs)主要关注视觉-语言信息,而忽略了音频等其他关键模态,导致对现实场景的理解能力不足。此外,现有的多模态评测基准(benchmark)存在以下局限:
-
主要侧重于图像而非完整的视频-音频分析(如 OmniBench、AV-Odyssey Bench)。 -
任务单一,主要是描述、分类等基础任务,而缺乏复杂推理和多样化评测。 -
题目质量较低,缺乏细粒度标注,导致评测结果的可靠性较低。
提出的方案
提出WorldSense,一个全面评估多模态视频理解能力的新基准测试集,具有以下特点:
-
全模态协作(Omni-Modality Collaboration):设计任务需要同时结合视频和音频信息,确保模型必须整合多个模态进行理解。 -
多样化的任务和数据(Diversity of Videos and Tasks):包含1,662 个音视频同步的视频,涵盖8 个主要领域、67 个细分类,并设计3,172 道多选题,涉及 26 种不同的认知任务,从基础感知到高级推理,确保评测的广度和深度。 -
高质量标注(High-Quality Annotations):所有题目由80 位专家人工标注,并经过多轮审核和自动模型校验,保证数据的准确性和可靠性。
应用的技术
-
多模态大模型评测:对开源视频-音频模型、视频大模型和商用模型(如 Gemini 1.5 Pro)进行实验评测。
-
模态消融实验(Ablation Studies):研究不同模态对模型性能的影响,例如:
-
仅使用视频 vs. 仅使用音频 vs. 同时使用视频+音频 -
原始音频 vs. 转录文本(分析音频的韵律、语调等对理解能力的影响) -
视频帧采样密度对推理能力的影响
达到的效果
-
现有开源视频-音频模型的表现接近随机猜测(约 25% 准确率),表明现有模型在真实场景中的多模态理解能力严重不足。 -
Gemini 1.5 Pro 在同时提供视频和音频的情况下达到了最高 48% 的准确率,但当缺少任意一个模态时,准确率下降 约 15%,凸显多模态协作的必要性。 -
原始音频数据比转录文本提供更多信息,例如语调、节奏、情感等,有助于提升模型理解能力。 -
增加视频帧采样密度(提供更丰富的时序信息)可以进一步提高模型表现,表明时间信息在多模态理解中的重要性。
WorldSense
本节将详细介绍 WorldSense 的构建过程,包括数据收集流程、标注流程和统计信息。与现有的基准测试不同,WorldSense 评估 MLLMs 在真实世界场景中通过整合全模态信息进行感知、理解和推理的能力。如下图 1 所示,所有的多项选择题都经过精心设计,确保问题只能通过对文本、视觉和音频的综合分析来回答。

设计原则
在多模态评估方面,基于音视频同步的视频,这些视频捕捉了时间事件、运动模式和音视频相关性。为了构建基准测试,遵循以下三个原则,以确保严格而全面的评估。
-
全面的领域覆盖。 为了确保对 MLLMs 真实世界理解能力的全面评估,我们制定了一套系统的分类方法,涵盖不同领域和场景。该过程从反映人类核心经验的主要类别开始,进一步细分为 67 个子类别,以捕捉具体的语境。该层次结构确保我们的视频集合涵盖广泛的真实世界体验,为多模态理解的评估提供了生态学有效的基础。 -
多样化的音频信号。 在真实世界场景中,音频信号主要可分为三种基本类型:语音、事件和音乐。我们的基准测试涵盖了所有这三种类型,以确保全面覆盖,使 MLLMs 能够处理和理解从语义语音到抽象音乐及环境声音的广泛音频信息。 -
多层次评估。 为了评估 MLLMs 的感知和认知能力,我们设计了三级多尺度评估:识别(基本音视频元素检测)、理解(多模态关系的理解)和推理(高级认知任务,如因果推理和抽象思维)。我们开发了 26 个任务来评估多模态理解的不同方面,重点是在各个层次上整合音视频信息。
数据收集与整理
主要从 FineVideo 获取视频内容,这是一个涵盖多种真实世界场景的高质量 YouTube 视频数据集,具有强烈的音视频相关性。为了增强音乐内容的覆盖范围,额外引入了 MusicAVQA 中的视频。
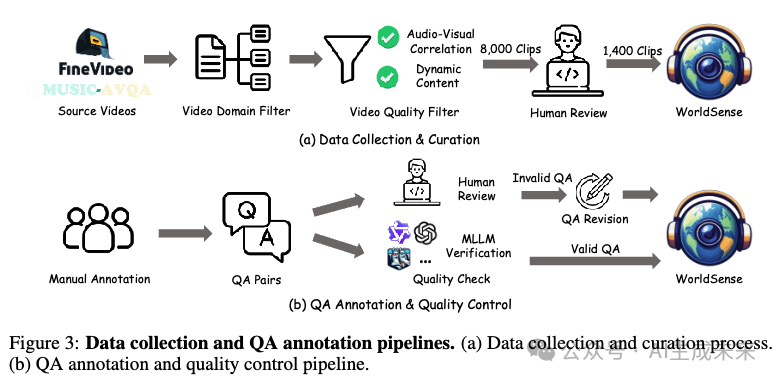
采用系统化的筛选流程,以确保视频具有丰富的音视频语义和时间动态,如下图 3(a) 所示。该流程包含三个关键步骤:(i) 根据预定义分类筛选视频,以确保全面覆盖;(ii) 使用预计算指标(包括音视频相关性和动态内容评分)从最初约 8,000 个视频中筛选出重要片段;(iii) 由人工专家评审视频质量和真实世界相关性。最终,该严格的流程筛选出 1,662 个高质量的视频片段,这些视频在各种真实世界场景中展现了强烈的音视频相关性。
标注协议
QA 标注。 由 80 名专业标注员组成的团队负责创建高质量的多项选择题。对于每个视频片段,标注员会对视觉和听觉内容进行全面审查,以确保充分理解。然后,他们生成问题及对应选项,这些选项必须要求整合视觉和音频信息才能得出正确答案,从而有效评估 MLLMs 的多模态理解能力。
质量控制。 为了保证问答对的质量,我们实施了一套严格的质量控制流程,结合了人工评审和自动验证,如上图 3(b) 所示。专业质量控制专家根据三个关键标准评估每个 QA 对:(i) 语言清晰度和连贯性;(ii) 是否需要同时利用视觉和音频信息才能回答正确;(iii) 问题难度的适当性。不符合标准的问题将被退回修改。
此外,使用 MLLMs 进行自动化验证。视觉-语言模型(如 Qwen2-VL)用于检查问题是否确实需要多种模态的信息才能得出正确答案。同时,能够处理视频、音频和文本的多模态 MLLMs(如 Video-LLaMA2 和 OneLLM)被用于评估问题难度,所有模型都能正确回答的问题将被标记为过于简单,并由人工进行修订。
这种结合专家审查和自动测试的双重验证系统确保了基准测试中的所有问题质量高、结构合理,并真正需要多模态理解,且对模型提出了显著挑战。
数据集统计
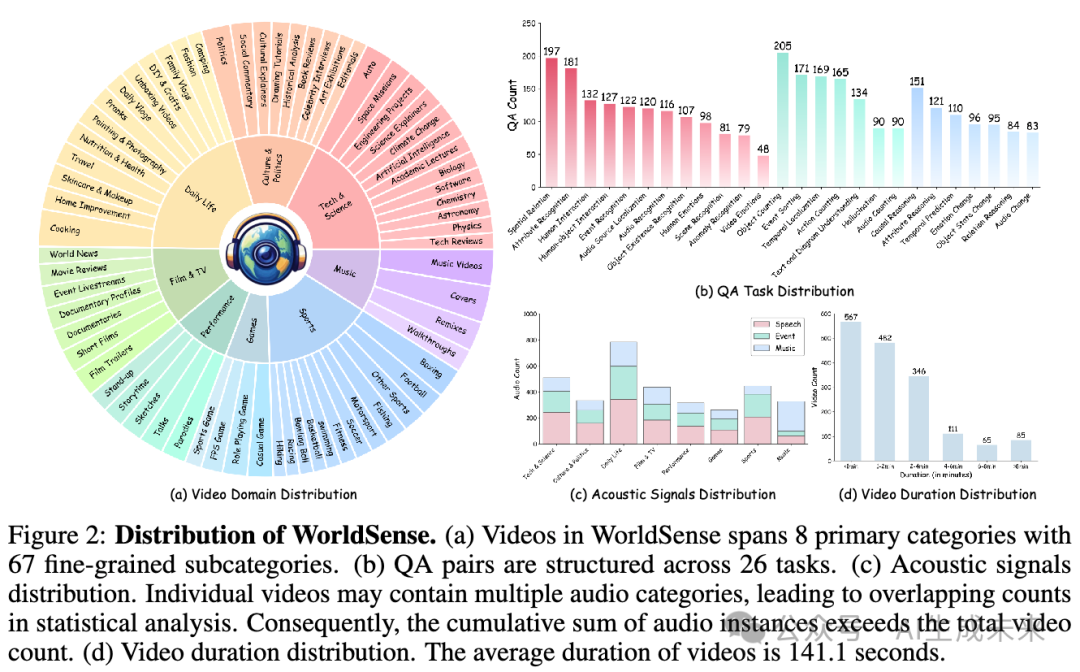
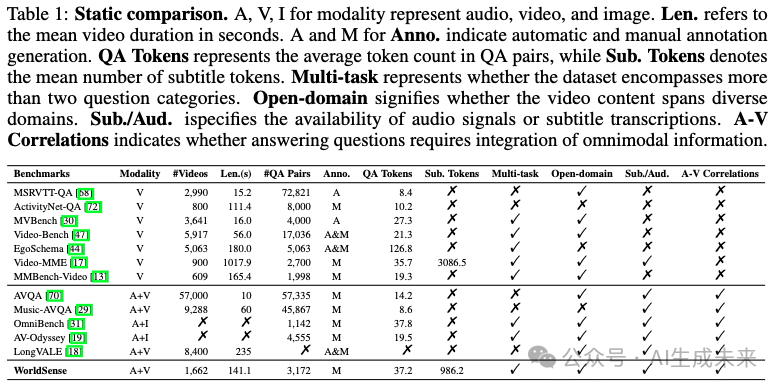
如下表 1 所示,WorldSense 数据集包含 1,662 个带有同步音频的视频片段,分布在 8 个主要类别和 67 个子类别中。平均时长为 141.1 秒,长度范围从 30 秒到 10 分钟以上,涵盖了各种事件和活动。总计包含 3,173 道多项选择题,涉及三个评估层次。
WorldSense 涵盖多种音频成分,包括语音、环境声音和音乐。与现有基准测试不同,例如使用静态图像的 AV-Odyssey Bench 和 OmniBench,或音视频相关性较弱的 Video-MME ,WorldSense 是首个专为评估 MLLMs 真实世界多模态理解能力而设计的基准测试。其特点包括:(i) 开放领域视频与多任务评估;(ii) 原始音视频内容及完整转录;(iii) 精心设计的问题,要求真正的音视频融合,从而构建一个更全面的真实世界多模态理解评估基准。
评估范式
在评估框架中,每个测试实例包括一个带有同步音频的视频片段和一道多项选择题。模型必须处理这些多模态输入,并从多个选项中选择正确答案。性能以准确率衡量,即模型的选择与标准答案匹配的程度。模型的成功取决于其准确对齐正确答案的能力。为了严格评估多模态整合在真实世界理解中的必要性,我们针对不同的模态配置进行了消融研究。这种方法不仅评估了模型的整体表现,还量化了模型对单一模态的依赖程度,突出多模态协作在真实世界理解任务中的关键作用。
实验与发现
WorldSense 基准测试上的开源和专有 MLLMs 进行了全面评估。我们首先介绍实验方法和评估协议,然后对定量结果进行详细分析。此外,我们深入探讨影响模型性能的重要因素,并提供见解,以指明未来多模态理解的发展方向。
设置
为了全面评估多模态理解能力,评估了三类 MLLM:(1)开源音视频模型,如 Unified-IO-2、OneLLM 和 VideoLLaMA2;(2)开源 MLLM,如 Qwen2-VL、LLaVA-OneVision、InternVL2.5、LLaVA-Video 等;(3)专有 MLLM,如 Claude 3.5 Sonnet、GPT-4o 和 Gemini 1.5 Pro。在所有评估中,严格遵循每个模型的官方实现指南和推荐的预处理流程。视频帧提取遵循相应 MLLM 指定的官方配置,而专有模型的评估则依据其 API 规范和推荐的输入格式。模型性能通过模型输出与标准答案的直接比较进行评估。
WorldSense 结果
主要结果
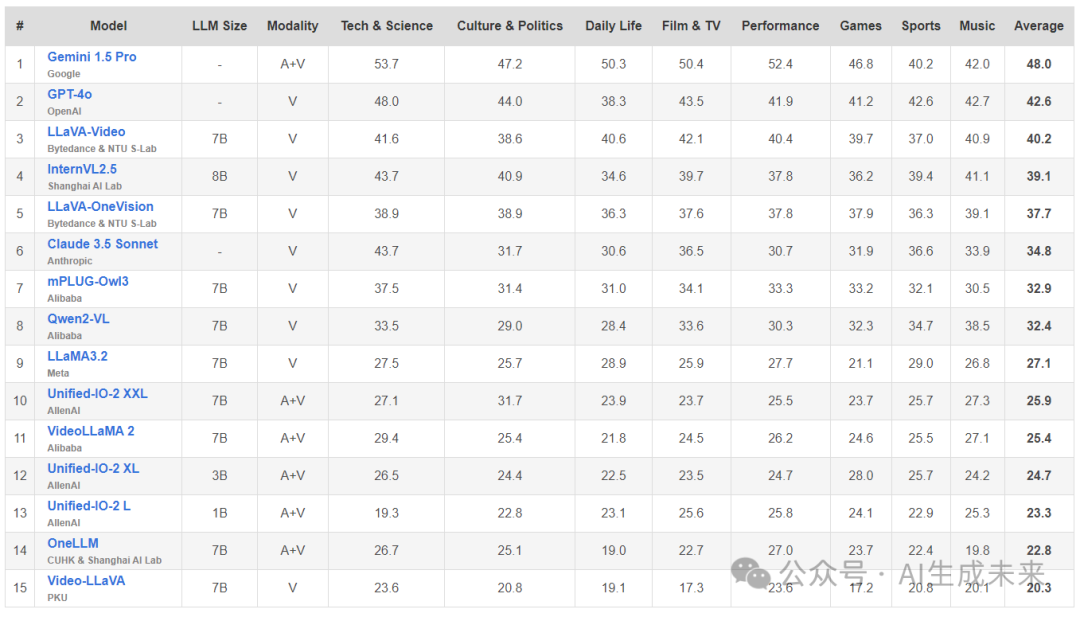
下表 2 中展示了 WorldSense 的综合评估结果。研究发现了一些关于当前多模态模型在真实世界理解方面的重要见解。
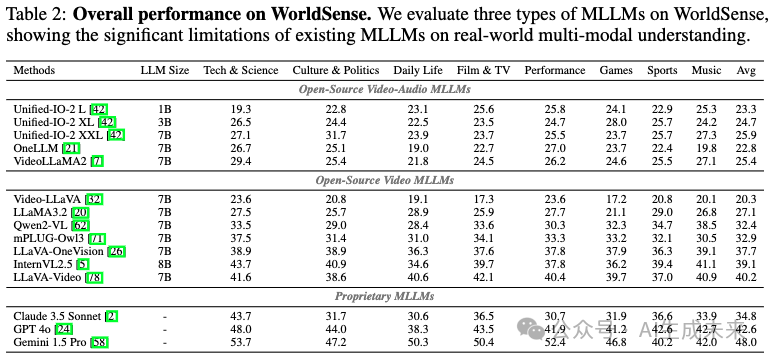
首先,当前的开源视频模型性能有限,因为它们仅处理视觉信息。这一限制凸显了它们在执行复杂多模态理解任务方面的明显不足,其最高性能得分仅为 40.2%。结果表明,仅依赖视觉处理是不够的,强调了在实际应用中集成音频输入的重要性,以实现更全面和准确的理解。
其次,令人惊讶的是,现有的开源音视频 MLLM 甚至表现更差,其准确率与随机猜测相当,并显著低于仅基于视频的 MLLM。这一反直觉的发现表明,尽管这些模型可以访问多种模态,但它们在有效的音视频融合方面仍然存在困难,表明仅具备多模态处理能力并不能保证更好的性能,除非具备更先进的融合机制。
第三,在专有 MLLM 中,仅基于视觉的 GPT-4o 和 Claude 3.5 Sonnet 的表现与最佳的开源视频 MLLM 相当。而能够同时处理音视频信息的 Gemini 1.5 Pro 取得了最高 48.0% 的准确率。然而,这一性能仍然远低于可靠的真实世界应用需求,表明还有很大的改进空间。
这些综合结果揭示了几个关键见解:(1)音视频协同理解在真实世界场景中的基本重要性;(2)当前模型在有效多模态集成方面存在的显著能力差距;(3)需要更复杂的方法来组合和推理多个模态信息。这些发现指明了未来 MLLM 研究和发展的重要方向。
细分结果
对模型在不同音频类型和任务类别上的性能进行了细粒度分析,如下图 4 所示,揭示了现有多模态模型的局限性。
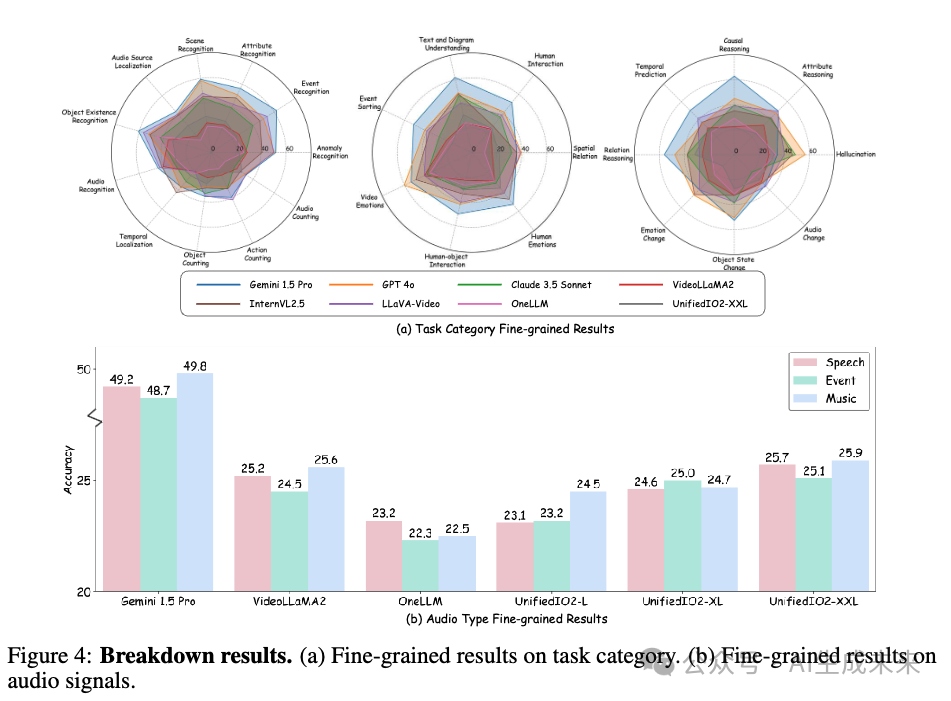
首先,模型在与音频相关的任务(如音频识别、音频计数)上的表现普遍较差,相较于其他任务类别,表现出显著的音频理解挑战。
其次,空间推理和计数任务对当前模型构成了显著困难,这种模式在多个基准测试中都得到了验证。
第三,涉及情感相关的任务表现尤其不佳,可能是因为这些任务需要整合微妙而复杂的多模态线索,包括面部表情、语音语调和语境语音内容。情感理解能力的不足表明当前 MLLM 在训练数据和能力方面存在显著缺陷,突出了未来发展的一个重要方向。
此外,不同音频类型的表现存在差异。虽然 Gemini 1.5 Pro 整体表现最佳,但在事件相关问题上的准确率明显低于语音或音乐任务,可能是由于环境声音的复杂性所致。其他模型在不同音频类型上的表现也存在不一致性,进一步突出了现有模型在音频理解方面的普遍局限性。
面向真实世界理解的路线图
鉴于上述评估揭示的显著性能差距,深入研究了提升 MLLM 性能的潜在方法。
视觉信息
我们通过不同的输入配置来研究视觉信息的影响:仅音频、音频加视频字幕和音频加视频帧。如下表 3 所示,视觉信息通常能提高性能,Gemini 1.5 Pro 的准确率从 34.6%(仅音频)提高到 48.0%(+视频)。然而,不同模型的影响有所不同,Unified-IO2 在使用字幕时表现出不一致的提升,甚至出现性能下降。
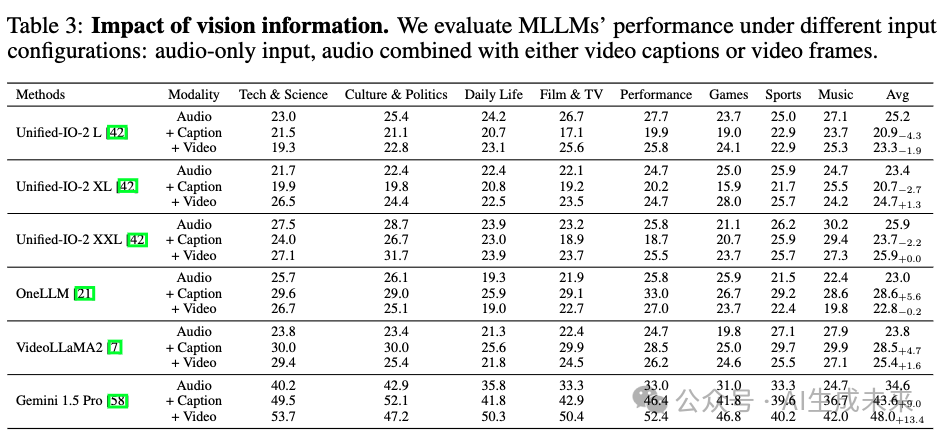
这些发现提供了两个重要见解:(1)当视觉信息得当地整合时,对提升多模态理解至关重要;(2)当前模型有效利用视觉信息的能力仍然有限。
音频信息
通过三种配置来研究音频信息的影响:仅视频、视频加字幕和视频加原始音频。
下表 4 的结果揭示了不同形式的音频信息如何影响模型性能的有趣模式。对于 Gemini 1.5 Pro,准确率从 34.4%(仅视频)提高到 39.3%(加字幕),再提高到 48.0%(加原始音频)。OneLLM 也显示了类似的改进。
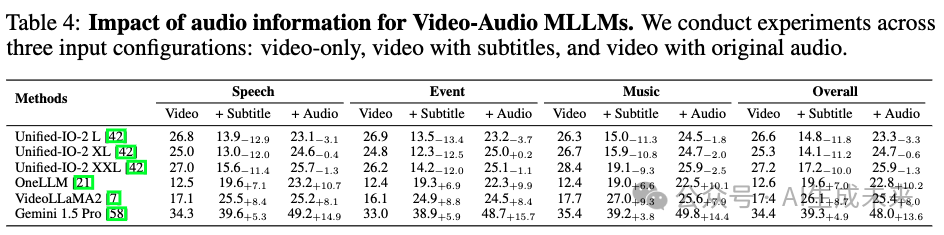
这些结果表明,字幕和音频特征(包括语调、情感和环境声音)为多模态理解提供了有价值的信息,超出了字幕本身的捕捉范围,强调了完整音频线索对多模态理解的重要性。
有趣的是,Unified-IO2 在整合字幕或音频时表现下降,特别是字幕导致准确率显著下降,表明其在多模态处理上存在困难。相反,Video-LLaMA2 在使用两种模态时表现有所提升,但在使用字幕时比原始音频表现更好,表明它对文本信息的依赖大于对复杂音频信息的依赖。我们进一步通过提供转录字幕来评估仅视频的 MLLM,如下表 5 所示。几乎所有模型在整合字幕后都表现出了显著的提升,强化了音频信息的重要性。然而,在与音乐相关的问题上,性能提升不明显,因为字幕无法有效捕捉旋律、节奏和和声等固有的音频特征。

这些评估揭示了几个关键发现:(1)原始音频包含丰富的信息,超出了字幕所能捕捉的内容,尤其是在音乐方面;(2)当前模型在多模态处理方面存在显著限制。这些见解为改善 MLLM 在整合音频和文本信息、实现全面场景理解的能力指明了重要的研究方向。
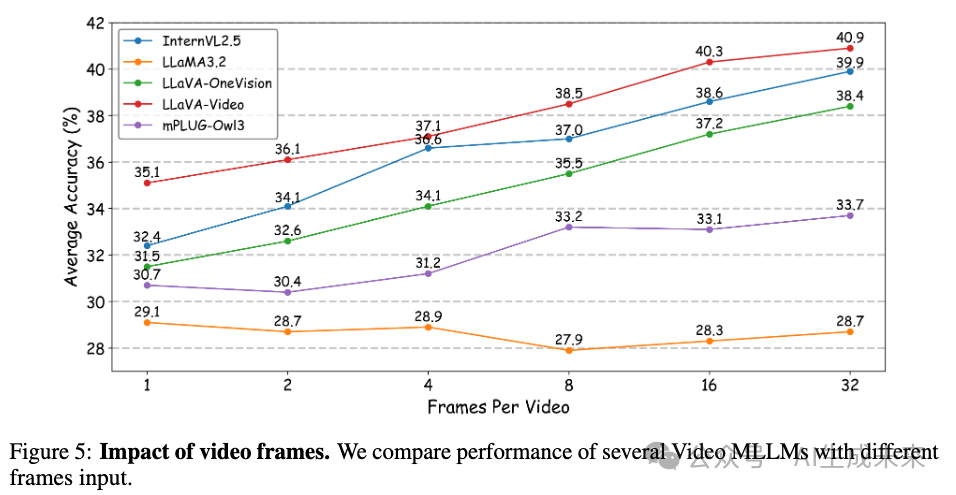
视频帧
通过改变输入帧数来研究时间采样密度对仅视频 MLLM 的影响。如下图 5 所示,大多数模型在增加帧密度后表现出显著的性能提升,LLaMA-3.2 是一个显著的例外。这些提升可能是由于更好地捕捉到细粒度的时间动态和微妙的视觉变化,强调了密集时间采样的重要性。
结论
WorldSense ,这是第一个旨在评估 MLLM 在真实世界场景中全模态理解的基准。WorldSense 的特点在于强调在多种真实世界情境中的联合全模态理解,涵盖了丰富的视频类别和精心策划的问答对,要求整合视觉和音频信息。通过广泛的实验,揭示了当前 MLLM 在处理和一致性地整合全模态信息方面的显著局限性。通过分析表明,全模态协作在真实世界理解中的重要性。希望 WorldSense 能成为推动类人全模态理解能力发展的基础性基准。
参考文献
[1] WorldSense: Evaluating Real-world Omnimodal Understanding for Multimodal LLMs

(文:极市干货)