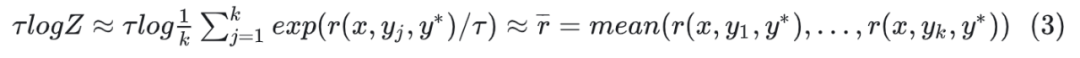©作者 | 姜富春
单位 | 百度
研究方向 | AI搜索
最近 Reasoning Model(推理模型)异常火爆,Kimi 和 DeepSeek 陆续推出自家的产品 K1.5 和 R1,效果追评甚至超过 o1,也引起了大家的关注,甚至 OpenAI 也慌了。 我也第一时间体验了下产品的效果,推理能力确实惊艳。也非常好奇到底用了什么技术。国内的 LLM 开源玩家算是比较良心的,模型开源的同时,一些技术细节也都发表出来,也能进一步解答大家的好奇心。 过年期间正好忙里偷闲,可以静下来好好整理下这块内容。我个人认为主要有三篇工作比较清晰的讲述了 Reasoning Model 的探索过程,分别是: 字节的 ReFT、Kimi 的 K1.5 和 DeepSeek 的 R1。 看完总结下来:大家方法趋同, 核心都是在 Post-Training 阶段通过 RL(Reinforcement learning)提升模型的推理能力。 这也不禁让人感叹,Reasoning Model 看似 o1 放出的杀手锏,”国产之光”的复现竟可以做到如此精巧、简洁。 在介绍三篇工作前,我也想按自己的理解先来介绍一些早期的 o1 的猜想。也方便与本文要介绍的工作做些对比,也好理解为什么说复现的工作是精巧、简洁的。
Reasoning Model的早期猜想
自从 OpenAI 发布 o1 模型后,让我们体验到 LLM 在复杂问题的推理能力上的进步。Reasoning Model(推理模型)的复现之路也成为各家大模型追捧的热点。在猜想和复现的过程中,试图从 OpenAI、Google、微软的近期的研究中找到一些蛛丝马迹,其中主流的一些猜测集中在使用 PRM 和 MCTS 方法,在 Post-training 和 Inference 阶段提升推理性能。 我们简单看下使用 PRM 和 MCTS 方法是如何提升推理性能的? PRM(Process-supervised Reward Model)是 OpenAI 在 Let’s Verify Step by Step [1] 一文中首次提出的概念。与之相对应的是ORM(Outcome-supervised Reward Model)。
PRM: 过程奖励模型,是在生成过程中,分步骤,对每一步进行打分,是更细粒度的奖励模型。
ORM: 结果奖励模型,是不管推理有多少步,对完整的生成结果进行一次打分,是一个反馈更稀疏的奖励模型。
使用 PRM 可以在 Post-Training 和 Inference 两阶段提升模型的推理性能。 Post-Training 阶段: 在偏好对齐阶段,通过在 RL 过程中增加 PRM,对采样的结果按步骤输出奖励值,为模型提供更精细的监督信号,来指导策略模型优化,提升模型按步推理的能力。 Inference 阶段: 对于一个训练好的 PRM,可以在 Inference 阶段来筛选优质生成结果。具体来说。对 generator 模型做 N 次采样(如 Beam Search 方法等),并通过 PRM 对每个采样的每步推理进行打分,最终拟合一个整体过程打分,并选取打分最高的结果作为最终的答案。
这里我们假设基础的 generator 模型在 pretrain 后做了指令微调(SFT),有基本的推理能力(能按步骤生成答案,但推理准确性可能较差)。
1.2 MCTS增强推理能力
MCTS(Monte Carlo Tree Search)是强化学习领域提出的方法,通过采样方式预估当前动作或状态的价值。具体操作步骤:使用已有的策略与环境做仿真交互,进行多次 rollout 采样,最终构成了一个从当前节点出发的一颗 Tree(每个 rollout 表示从当前节点到最终结束状态的多次与环境仿真交互的过程)。
这颗 Tree 的所有叶子节点都是结束状态,结束状态是能量化收益的(量化收益的方法:比如方法 1:答案错误收益-1,答案正确收益 +3;再比如方法 2:叶子节点的收益是 到达叶子节点路径数/总路径数 的概率,这是一种根据投票机制预估的价值,越多路径到达叶子节点,说明这个叶子节点越置信,那么这个叶子节点就有更高的奖励)。
一颗 Tree 的叶子节点有了奖励值,就可通过反向传播,计算每个中间节点的奖励值,最终计算出整个 Tree 所有节点的奖励值。MCTS 一次 rollout 包括:select,expand,simulate,backprop 四个步骤。我们展开描述下四个步骤的具体工作。
Sample(采样): 选择一个未被探索的节点,在 Reasoning Model 中节点表示一个打了特定 tag 的推理步骤(如:planning 节点,reflection 节点等)。初始情况,Tree 只有一个表示原始问题的节点(如下图 1 的 )。 expand(扩展): 从未被选择的节点出发(如初始从 ),展开所有可能的子节点(如下图 1 中的 )。当然对于文本生成模型不可能穷举所有的子节点,需要设置个最大生成次数,在有限生成次数内的所有的不同的输出,认为是子节点的集合。 simulate(模拟): 从展开的子节点里,再随机选择一个节点,再展开它的子节点,重复做 expand 过程。直到最终到达叶子节点(生成答案)。当然这里也会控制最大树深度,模拟会进行 N 次。 backprop(回传): 通过多次模拟我们得到了一个从根节点(原始问题 )到叶子节点(最终生成答案)的 Tree,如下图 1 所示。 我们通过计算(从当前节点出发到正确答案的路径数/从当前节点出发总路径数)的比值作为节点的奖励值。这个奖励值隐含表示的是从当前节点出发能得到正确答案的潜在的可能性。 比如以 节点为例,从 出发共有 4 条路径,分别是: 其中有 2 条路径都能走到正确答案。所以 的奖励值为 1/2。我们通过从后往前回溯,能计算出 Tree 中所有节点的奖励值。
▲ 图1. MCTS生成Search Tree过程 使用 MCTS 提升模型的推理能力,也可在 Post-Training 和 inference 两阶段来实现。 Post-Traing 阶段:对于每个 problem 通过上述方法构造一个搜索 Tree,然后进行 Tree 的游走遍历采样,再用采样的样本 SFT 或 RL 训练模型。 Inference阶段:在推理阶段,也是对一个 problem 探索多节点构造一颗搜索 Tree,对于到达正确答案的路径,根据节点路径的置信度打分,贪心选取最优路径作为最终的推理结果。 使用 PRM 和 MCTS 训练推理模型的大致框图,如图 2 所示,主要是在 Post Training 和 Inference 阶段使用来提升模型的推理能力。
▲ 图2. 基于PRM和MCTS的推理模型
注:这里对 PRM 和 MCTS 在 Reasoning Model 上的使用,是个人参考 paper 和网上的一些资料的总结,可能有不准确的地方。如有错误,欢迎指正
PRM 和 MCTS 的方法理论上都有自身的优势。对于复杂的推理过程,PRM 可以按步骤做细粒度的监督,MCTS 可以自动探索解空间。两者配合可以在探索(Exploration)和利用(Exploitation)上做平衡,以提升复杂问题的推理能力。 PRM 的局限: 对于一般的推理任务,很难定义一个精细的执行步骤。对于语言模型判断一个中间步骤是否正确是一项艰巨的任务。另外对于 PRM 训练样本的质量要求较高,使用模型进行自动标注可能无法取得令人满意的结果,而手动标注则不利于扩展规模。 一旦引入基于模型的 PRM,就不可避免地会导致 Reward Hacking 问题。此外从头训练奖励一个奖励模型需要额外的训练资源,也使得整个模型训练流程复杂化。 MCTS 的局限: MCTS 方法核心是需要建搜索 Tree,在生成模型任务中,需要提前定义好 Tree 的节点空间(如 Planning,Reflection 等类型节点)。 这个定义是非常难的:因为一方面生成模型面向的场景是多领域、多任务的,很难定义一个有限的节点集合来覆盖所有任务,而且就算提前定义好了一个集合,随着任务的新增,整个集合又要更新,模型要重新训练,这样就增加了维护和迭代的复杂性。 另一方面 token 生成的搜索空间是指数级增长,在全空间做搜索是不可行的。为了解决搜索空间爆炸的问题,通常会做节点扩展限制的搜索,这样可能导致陷入局部最优解。另外 MCTS 方法一般依赖一个价值度量模型(如上述的 PRM)来衡量节点的价值,引入价值模型也进一步增加了模型训练的复杂度。 PRM 和 MCTS 方法,都会引入模型训练和推理的复杂性。在实际的复现 Reasoning Model 工作中,大家并没有应用这些技术,而是不约而同的选择了更轻量、更直接的方案。下面我们来看看国内三篇有价值的 Reasoning Model 的技术报告。
Reasoning Model三篇有价值的工作
三篇工作附原文链接,如下:
字节ReFT:
https://arxiv.org/pdf/2401.08967
KIMI K1.5:
https://arxiv.org/pdf/2501.12599
DeepSeek-R 1:
https://arxiv.org/pdf/2501.12948
注1:这三篇 Paper 的核心的工作都是卷 RL 阶段来提升模型的推理能力。所以要更好的理解上述工作,要具备基本的 RL 的基础知识,本人之前整理过 RL 核心算法(PPO 训练的源码阶段),如需要提前了解,可以适当参考:
https://zhuanlan.zhihu.com/p/13043187674
https://zhuanlan.zhihu.com/p/14569025663
https://zhuanlan.zhihu.com/p/14813158239
注2:本文并不是对三篇工作做从头到尾的翻译,二是 主要讲解核心的实现思路 ,不会对效果、实验等细节展开讲解。如需要了解更多细节,请参考原文阅读。
下面我们来看看 ReFT、K1.5,R1 的核心实现。
ReFT
ReFT (Reinforced Fine-Turning) 是字节 24 年初的一篇工作,ReFT 方法包括两个阶段:SFT 冷启阶段和强化学习训练阶段。 3.1 ReFT SFT冷启阶段(warm-up stage) SFT 阶段通过构造一批带推理过程的数据,来精调 Base LLM 模型,这个阶段主要是让模型有基本的 CoT 推理能力。ReFT 的做法也非常简单,就是用一批开源的数据,通过 Prompt 工程来发压 GPT-3.5t 来收集样本,再 SFT 微调自己的小模型。 具体实现细节上, 样本数据 主要来源于 GSM8K,SVAMP 和 MathQA 三个数据集,通过 GPT-3.5-turbo few-shot prompting 的方法收集的训练数据。数据集有两种推理格式:N-CoT,P-CoT。
作者在实验中并没有人工标注训练数据,而是完全通过 self-instruct 方式,基于 GPT-3.5dump 的训练样本。
▲ 图3. ReFT的SFT阶段样本样例数据
通过上述方法,收集了 SFT 数据集: 62K 的指令集样本,分布如下:
▲ 图4. ReFT的SFT阶段样本分布
模型训练: 这个阶段模型训练就是常规的 SFT,训练了 40 个 Epoch(作者说这个训练步数是保证模型收敛的一个比较大的设置了)。 ReFT 使用 PPO 的方法做强化学习,我们先回顾下 PPO 的具体方法,如下图 5 所示,参考:
https://zhuanlan.zhihu.com/p/13043187674
阶段1: 先基于Pretrain model,训练一个 精调模型(SFT Model) 和一个 奖励模型(Reward Model) 。Reward model 一般可以基于SFT model 热启或基于 Pretrain model 热启训练。 阶段2: 模型初始化,PPO 过程,在线同时有 四个模型 ,分别为:
Actor Model: 是我们要优化学习的策略模型,同时用于做数据采样,用 SFT Model 热启;
Reference Model: 是为了控制 Actor 模型学习的分布与原始模型的分布相差不会太远的参考模型,通过 loss 中增加 KL 项,来达到这个效果。训练过程中该模型不更新;
Critic Model: 是对每个状态做打分的价值模型,衡量当前 token 到生成结束的整体价值打分,一般可用 Reward Model 热启;
Reward Model: 这里是 ORM(Outcome Reward Model),对整个生成的结果打分,是事先训练好的 Reward Model。训练过程中该模型不更新。
阶段3: 采样 Experience 数据,流程为:
阶段4: 用 Experience 样本,训练 Actor Model 和 Critic Model。 重复 3-4 阶段,循环采样 Experience 数据-> 模型训练,直到 loss 收敛。 由上述过程可知,做 PPO 训练,我们需要预先准备两个训练好的模型:Base LLM Generator 和 Reward Model。 ReFT 是如何准备这两个模型的?首先 Base LLM Generator 就是 warm-up 阶段 SFT 的模型,对于 Reward Model 本文作者并没有训练一个模型,而是通过定义一个规则函数,设置了一个 Rule-Base RM,下面我们来看看细节。 3.2.2 Reward Model的设计:Rule-Base RM ReFT 主要是针对数学场景富集样本来训练 Reasoning Model,数学计算的问题是可简单判断答案正确与否的。所以作者设置了一个判别函数作为奖励。具体如下:
这里的 Reward Model 是个 ORM,对于模型生成的中间状态,奖励都为 0; 对于终止状态判别有 3 种情况:
1. 如果通过规则能抽取出正确答案则奖励为 1;
2. 如果抽取不出正确答案,但能解析出一个结果,奖励值设置为 0.1;
3. 如果最终结果无法解析,奖励制设置为 0。
这里对错误答案的推理路径,设置了一个弱奖励的机制(赋值 0.1),主要是为了减少奖励反馈稀疏的问题。如果能解析出一个答案,证明生成过程是在做一个推理的过程,虽然答案错了,但推理的执行过程对模型是有帮助的,所以设置个小的奖励值,激励模型按推理逻辑输出结果。
Critic Model 是对每个状态做打分的价值模型,衡量当前 token 到生成结束的整体价值打分,模型的结构一般跟 Reward Model 一致,通常也会用 Reward 热启。但本文中,并没有 Reward Model,那么 Critic Model 如何设计的呢? 作者对 Critic Model 的设计还是遵从 Reward Model 的设计方式,在 Base Model 之上,增加一个回归头(regresion head)对每个生成的状态进行打分。ReFT 也做了些优化,为了减少训练时模型的计算量和显存占用,Critic Model 的参数与 Actor Model (Policy Model) 的参数共享。如下图所示: 为了证明 ReFT 的有效性,作者也实现两个 self-training 的方法。这两个方法虽然被证明没有 ReFT 效果好,但这两种方法实际工作,是经常被使用的方法。所以也详细展开介绍下。有助于在实际工作中,根据自己的业务特点,选择合适的优化方案。 所谓 self-training 就是不采用额外的人工标注的数据集,而是通过模型自己产出的数据再来迭代优化模型的方法。作者设置的两个 self-training 的实验如下: 1. Offline Self-Training (Offline- ST):用初始的 SFT 的模型作为 generator,对于训练集的每个问题通过生成多次来采集多个样本。然后将采集的样本的答案跟 ground Truth 对比,筛选答案正确的样本,然后跟原始样本混合,再训练初始模型。 这就是我们通常使用的拒绝采样训练模型的方法。 2. Onlline Self-Training (Online-ST):跟 ReFT 类似,用 SFT 的模型 warm-up,之后在每个训练步,我们通过当前版本的模型做即时采样,然后保留答案正确的 Sample,再通过 SFT 训练当前版本模型,得到下一个版本的模型。重复上面的迭代过程,直到达到预期的训练步数。 为了清晰对比 Offline-ST,Online-ST 和 ReFT,如下图所示: 相较于上面两种 Self-Training, ReFT 优势主要有如下两方面: 样本充分利用: 在 ReST 中是基于 RL 的优化过程,对于采样的正负样本都参与模型训练。而上述两种 Offline-ST 和 Online-ST 两种方法都是基于 SFT 训练模型,SFT 是只能使用正样本做模型训练的,样本使用上是不够充分的。 模型训练稳定: Offline-ST 采样模型直接使用初始模型,而 Online-ST 采样模型是随着 Policy 模型的更新实时更新的,导致 Online 的方式可能使模型的分布大大偏离原始模型的分布。导致模型在采样的数据集上 overfitting,最终实际应用中效果达不到预期。而 ReST 采用 PPO 的方法训练,模型更新过程通过 KL 限制 Policy 模型与初始 Model 分布不会偏离太远。保证了模型的效果稳定。
上述的 Self-Training 方法,在实际的工作中,都是值得借鉴的,虽然 ReFT 理论上效果更好,但基于 PPO 的训练更复杂。可以结合自己业务的特点,考虑合适的方法驱动提升模型效果。
3.3 总结ReFT
ReFT 核心使用 PPO 算法来提升 Reasoning 的能力,相对于传统的 PPO 算法,主要做了两方面优化: 1)简化 Reward Model,使用的是 Rule-Base Reward 而非训练一个模型。 2)Critic Model 参数与 Policy Model 共享,压缩训练阶段模型的参数的存储空间,也进一步降低模型训练的复杂度。
Kimi-K1.5
Kimi K1.5 是个多模态的 Reasoning Model,论文中对模型训练过程描述的比较详细。主要包括:预训练、监督微调和强化学习(RL)三个阶段,其中 RL 阶段仍然是 Kimi 重点优化的阶段。我们先来快速看看预训练和 SFT 阶段的一些细节,之后再重点看下 RL 阶段。 4.1 预训练&监督微调
预训练阶段比较常规,数据集包括文本和图像多领域多模态高质量数据集,训练包括三个阶段: 1. Vision-language 预训练阶段:首先基于文本语料训练语言模型,然后进行多模态融合训练; 2. 退火阶段:筛选公开的和合成的高质量数据来进一步提升模型的基础能力,特别富集了针对推理和知识型任务的高质量数据集,做模型训练; 3. Long-context 训练阶段:这也是当前模型扩展长文能力的主要方法,在预训练的最后阶段,通过 feed 长文数据集提升长文理解和生成能力,Kimi 最终将长文能力扩展到 128K。 对于 SFT 精调阶段,Kimi 做了两个阶段,分别是 覆盖通用能力的基础监督微调 和 强化推理能力的 long-CoT 的监督微调 。 4.1.2 基础监督微调(SFT)
Kimi 富集了 200 万的监督微调数据集,其中包括 100 万的文本任务数据集(包括问答,编程,写作等)和 100 万的文本-视觉数据集(包括 OCR,视觉推理等),样本数据主要通过人工标注和拒绝采样的方式富集。模型训练阶段首先以 32K 的序列长度训练一个 epoch,然后又扩展到 128K 继续训练一个 epoch。 这一阶段重点通过 Prompt 方式生成长思维链的推理路径的小规模数据集,来做 SFT 训练。目的是让模型能够先内置一些推理的知识,学会基本的 long-CoT 的生成模式,能对推理过程的必要动作如:planning,evaluation,reflection,exploration 等步骤做正确的、连贯的响应。
注:该步骤的数据集是基于 RL 阶段的数据集做后处理得到的,后面 RL 阶段会详细讲述数据集的富集过程。
经过上述几步,模型除了具备了通用的能力,同时也有了基础的推理能力,下面就是 KIMI 重点优化的 RL 阶段,进一步提升模型的推理性能。
Kimi 的 RL 训练过程,并没有采用 PPO 的方法,而是采用了一种更轻量的类 Policy Gradient 的方法。具体方法如下:
首先定义一个初始的目标:找到最优的 ,使得输出的结果让 Reward Model 获得最大期望奖励,如下公式:
是针对问题
接着,作者为了模型训练更加稳定,类似 PPO,在公式(1)基础上,增加了 KL 的正则项,来限制优化的模型与初始模型分布相差不要太远。 对于公式(2),可以进一步做推导,当取最大值时,可以推导出一个解析解+ 有了上面的转换,进一步我们通过最小二乘法 最终我们用
这是一个 Policy Gradient 方法的变体版本,该方法移除了 Critic 网络计算 Advantage 的过程。减少的策略优化的复杂度。
注:上述公式省略了严谨的数学推导过程,只是从直观上给出了必要的公式结果。其实这里我们重点要理解的并不是数学上的证明,而是重点要 get 到 Kimi 做 RL 过程用的是一个类 Policy Gradient 的简化版本,在计算 loss 的时候没有依赖 Critic Model。对公式感兴趣同学,可以自行推导。
K1.5 中对于 reward 的设计还是比较精细的。对可直接规则判别对错的问题,用 Rule-Base Reward 简化打分过程。对于开放问答类问题,用 Model-Base Reward。同时对于超长的 CoT 过程做了惩罚处理。 Rule-Base Reward:对于能简单判断对错的数学问题,直接通过规则函数来计算 Reward,对于编程问题通过评估是否通过测试用例来直接判断 Reward 打分。 Model-Base Reward:对于开放的问答类问题,训练一个 Reward Model,通过模型打分。 Length Penalty Reward:Kimi 做了一个 warmup 的设置,在训练初始阶段不增加这个惩罚因子,让模型能学习生成 long CoT,在训练后面阶段,为了防止生成过长的 CoT,增加了生成长度的惩罚因子,鼓励模型进行适当思考,而不是生成过于冗长的内容。 4.2.3 RL Prompt和采样策略的精心设计 kimi 通过实验表明 ,强化学习的 Prompt 的质量和多样性对 RL 学习是至关重要的,精心设计的 Prompt 不仅能引导模型稳健推理,还能降低模型 Reward hacking 和过拟合。 好的数据集特点:领域分布多样,难度分布多样,可准确评估性。 为了确保收集到好的数据集,作者做了一系列数据筛选策略: 多样性筛选策略:通过开发一些过滤器和分类器,选择有丰富推理路径且易于评估的问题。同时通过分类器,平衡不同领域的数据分布。 难度分级筛选策略:使用一个相对较高的采样温度,让 SFT 模型生成十次答案,然后计算通过率,并将其作为 Prompt 难度的指标。通过率越低,表示 Prompt 的难度越高。利用这种方法,可以预先过滤掉大多数简单样本,并在强化学习训练期间根据问题难度探索不同的采样策略。 筛选可准确评估的问题:为了避免 Reward Hacking,确保每个 Prompt 的推理过程和答案都能被准确验证,需要排除一些容易作弊的问题。作者过滤掉了一些依赖复杂推理且容易作弊的问题,包括选择题,判断题和基于证明的问题。同时对于通过简单的 Prompt 多次采样能有概率回答正确问题做了过滤。 Kimi 也对 RL 训练过程的采样策略做了精心设计,主要通过两个方法来提高训练效率: 课程采样(Curriculum Sampling):作者设计先从训练较简单的任务开始,逐渐过渡到更具挑战性的任务。主要考虑是初始阶段,强化学习模型性能有限,将有限的计算预算花在非常困难的问题上往往只能产生很少的正确样本,从而导致训练效率降低。 优先采样(Prioritized Sampling):关注模型表现不佳的问题。跟踪每个问题的成功率,对成功率低的问题进行更大概率采样,引导模型将精力集中在最薄弱的环节,从而实现更快的学习和更好的整体性能。 Kimi 打磨 K1.5 的过程非常精细,从报告中可详细了解从 PreTrain,到 SFT 精调,再到 RL 阶段的每一步的细节。 核心工作还是集中在 RL 阶段。对于 RL Kimi 采用了一种类 Policy Gradient 的方法,模型训练裁剪掉了 Critic Model 以减少训练的复杂度;对于 Reward 设计比较精细,对于不同问题,不同训练阶段都有细致调整 Reward 策略。同时对于采样做了课程采样和优先采样的精心设计,来提升训练效率。
DeepSeek-R1
DeepSeek 做了两阶段探索: DeepSeek-R1-Zero 和 DeepSeek-R1 。 DeepSeek-R1-Zero: 是个纯做 RL 的阶段,验证 RL 对推理性能的提升的有效性。 DeepSeek-R1: 由于 DeepSeek-R1-Zero 训练的模型可读性是比较差的,通常有多语言混合输出的问题,通用能力也较差。为了解决这些问题,并产出一个实际可用的模型。DeepSeek 在 R1 阶段,做了多阶段的模型训练,并通过混合多任务数据,同时提升模型的通用能力和复杂问题推理能力。 我们先看看看硬卷 RL 的 R1-Zero 的一些核心细节: 这是一个纯 RL 来探索模型推理能力的过程,具体 RL 优化过程和奖励模型设置如下: DeepSeek 一如既往地使用自研的 GRPO (Group Relative Policy Optimization) 来做 RL 阶段的训练。GRPO 原理比较简单,相对于 PPO 同时在线四个模型,GRPO 做了简化,裁剪掉了 Critic Model。GRPO 中计算Advantage 的过程,是一种基于组内相对优势的计算方式。
具体来说,对于每个问题 GRPO 计算每个采样
GRPO 与 PPO 的对比如下图所示。在 GRPO 训练过程中在线会有三个模型,其中 Reference Model 和 Reward Model 是 Frozen 的,最终只有 Policy Model 迭代更新的。
5.1.2 Reward Model的设计:Rule-Base RM
R1-Zero 阶段只关注数学、程序类推理问题,都是能简单通过规则判别答案对错的,所以奖励模型采用的是纯 Rule-Base 的设计,主要包括 2 类 Reward: 正确性校验 Reward(Accuracy rewards): 数学问题通过简单的规则抽取答案与 ground truth 对比校验。对于程序题,通过编译生成的程序,校验是否能通过测试用例,产生一致的答案。 格式校验 Reward(Format rewards): 校验是否 thought 内容是包含在 ‘<think>’ 和 ‘</think>’tags 之间。 DeepSeek 训练 Reasoning 的指令模板相当简单,如下图,除了做些角色和格式描述,对于 Reasoning 的能力描述没有做过多限制,主要也是希望能激发模型的自主能力,防止过多人为设计引入 Bias,干扰 RL 阶段模型的推理路径。(这种简单的指令集设计,确实也需要有 DeepSeek-V3 这样强大的基模能力才行)。
DeepSeek-R1-Zero 的核心过程就是如此,论文中着实没有暴露更多细节。 DeepSeek-R1-Zero 是个纯 RL 驱动模型训练过程,问题推理能力显著提升,但模型的通用能力有很多瑕疵,比如会输出可读性非常差的混合语言的结果。 为了进一步提升模型的可用性,在 R1-Zero 基础上,DeepSeek 又做了多阶段细致的优化过程,即 DeepSeek-R1。主要的优化包括四个阶段: SFT -> RL -> 增强 SFT -> 增强 RL (有点左脚踩右脚,然后直接起飞的架势)。 SFT 的样本通过两种方式获取:1)拒绝采样:通过 few-shot prompt 方式,基于已有的生成模型直接生成,来富集 long-CoT 的样本;2)人工标注:获取 R1-Zero 可读的样本,然后通过人工方式精编样本。 在冷启阶段,对样本也设计了可读性更好的 pattern,通过 |special_token| 将推理过程圈定起来,为了让人更便捷阅读,对样本做了 summary 处理。如下:
|special_token|<reasoning_process>|special_token|<summary>
最终产出数千条样本,然后训练 DeepSeek-V3-Base,作为 RL 阶段的初始 Policy Model。 阶段 2:Reasoning-oriented RL 阶段 这个阶段基本就是 R1-Zero 的过程,为了解决多语言混合输出的问题,在训练 R1 过程,对 Reward Model 增加了语言一致性的奖励设置。 具体来说,增加了 Language Consistency Reward,它通过计算推理 CoT 过程的字符与目标语言一致的字符比例,来作为奖励打分,一致率越高奖励越高。这个奖励对模型性能有轻微的影响,但趋向于更便于人可读性的优化,是一个有用的偏好奖励的设置。 阶段 3:增强 SFT 阶段(Rejection Sampling and Supervised Fine-Tuning)
这个阶段主要是提升模型的通用能力,包括:创作,角色扮演和其他一些通用任务。对于 Reasoning 和 Non-Reasoning 的样本通过不同方式富集: Reasoning data:通过拒绝采样获取。这个阶段引入了一批新的 Prompt 数据,基于上一步得到的模型,生成多结果,最终通过 Rule-Base Reward 和强大的 DeepSeek-V3 作为裁判模型,精选样本。同时根据一些规则,对于混合语言的,冗长的推理 CoT 样本做规则过滤。最终筛选了 600K 的 Reasoning 样本。 Non-Reasoning data:引入训练 DeepSeek-V3 的通用高质量 SFT 数据,包括: 创作、事实问答、自我认知和翻译。样本处理上,通过 prompt 方式调用 DeepSeek-V3,在回答问题前,先生成一个思维链,保证与 Reasoning Data 的样本格式一致。最后收集了 200K 的 Non-Reasoning 样本。 最终用这 800K 样本 SFT DeepSeek-V3-base 模型,产出了 Reasoning 和非 Reasoning 能力兼顾的新的模型(注:这里并没有基于上个阶段的模型继续微调,而是在基模上微调的,主要是为了保证更好的通用能力,然后进一步通过过滤后的样本继续微调,保留refine后的推理能力)。 阶段 4:增强 RL 阶段(Reinforcement Learning for all Scenarios)
这阶段其实跟 K1.5 的工作差不多,对于多样的数据,采用多种奖励方式来做精细化的奖励反馈。复用了 R1-Zero 和 DeepSeek-V3 的 Reward Model 的设置。其他并没有太多可关注的地方。 R1-Zero 采用了非常激进的纯 RL 方式来提升模型的问题推理能力,虽然模型有瑕疵,但 R1-Zero 的做法把 Reasoning Model 的探索推向了一个极简方式,我个人觉得是非常有价值的尝试。 但话又说回来,之所以 DeepSeek 能这么玩,还是要依赖于他自己有较强大的 DeepSeek-V3 支撑,换做其他玩家,未必可行。 如果我们再详细对比 R1 和 K1.5 训练过程,都是 SFT 冷启,在做 RL 或 SFT 增强训练,基本的做法是趋同的。而显然 Kimi 的报告要更详细,DeepSeek 的报告感觉是有所保留的。 总结
本文主要介绍了「国产之光」的三篇做 Reasoning Model 的工作,对于复杂问题的推理能力的探索,大家都不约而同的采用了精巧、简洁的复现方案。通过设定清晰的目标,减少过多的人为设定,基于 RL 端到端的自驱探索能力上限。我觉得本文最终可以用一句话总结:Reasoning Model,RL is all your need!
(文:PaperWeekly)