


极市导读
这篇文章发现了并非所有扩散噪声生成质量相同这一问题,并设计了反演稳定度这一衡量噪声质量的指标。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
自从 ChatGPT o1 在 2024 年 9 月发布后,人们逐渐把研究重点放在了推理时扩展 (Inference-time scaling) 上。对于扩散模型而言,除了在推理时增加步数外,谷歌今年 1 月的研究 Inference-Time Scaling for Diffusion Models beyond Scaling Denoising Steps 表明,搜索更好的扩散模型噪声也能提升图像质量。但实际上,选取更好的噪声这一想法早在 2024 年 6 月的论文 Not All Noises Are Created Equally:Diffusion Noise Selection and Optimization 中就已提出。可惜的是,这篇论文最后在 ICLR 上被主动撤稿了,详情可参考 OpenReview:https://openreview.net/forum?id=R5xozf2ZoP 。
在这篇博文中,我会简单介绍「并非所有噪声本质相同」这篇论文。之后,我们来尝试批判性分析这篇论文及其审稿意见,并反思该如何做出高质量的工作。
知识准备
想读懂这篇论文,只需了解 DDPM 和 DDIM 这两篇扩散模型经典论文。
DDPM 定义了加噪过程和去噪过程:加噪过程中,训练图像 会加噪 次,最后变成纯噪声 ;去噪过程中,纯噪声 会被去噪 次,最后变成生成图像 。
DDIM 修改了 DDPM 中的部分假设,让扩散模型在去噪时不再有随机性,而唯一的随机性来自于随机噪声 的采样。保证了去噪过程不再有随机性后,我们就可以通过公式反演 (inversion),找出某个真实图像 对应的 。当然,这个反演过程存在误差。
核心思想:更好的噪声带来更高的图像质量
作者认为,过去的工作仅通过优化网络结构或参数来提升扩散模型生成质量,却忽视了噪声的重要性。作者从两个方向探索了噪声空间(即所有可能的噪声构成的集合):能否用某种定量指标选取更好的噪声?能否优化某一现有噪声?这两个方向的应用如下所示。噪声选取能够提升模型在同一个文本提示下的随机生成质量,而噪声优化能够提升现有某噪声对应图像的质量。

用反演稳定度反映噪声质量
根据以上设计思想,这个工作的重点就落在了噪声质量的评估指标上。只要有了一个这样的指标,我们就能用简单的算法实现噪声选取和噪声优化:
-
噪声选取:随机采样大量噪声,然后根据指标选出最好的那一个。 -
噪声优化:把指标变成损失函数,用损失函数优化给定噪声。
作者认为,函数不动点具有某些良好性质。因此,如果一个噪声在做完一轮生成-反演(去噪-加噪)后变化越小,那么这个噪声的质量越好。
所谓不动点,就是令函数 满足 的输入 。这里作者把函数 定义成先生成再反演这一整个过程,把 定义成某个高斯噪声。
具体来说,作者用 相似度来反映噪声的「变化幅度小」,即对于噪声 和其生成-反演结果 ,反演过程的稳定度,或者说噪声的质量,等于 。
有了这样一个指标后,我们可以用下面伪代码所示算法实现噪声选取和噪声采样:
input number of samples K, denoising model M
eps_list = sample_noise(K)
stability_list = []
for i in range(K):
eps = eps_list[i]
img = generate(M, eps)
eps_inversion = inversion(M, img)
stability = cos(eps, eps_inversion)
stability_list.append(stability)
best_idx = argmax(stability_list)
output eps_list[best_idx]
input denoising model M, optimization steps n, noise eps
for i in range(n):
img = generate(M, eps)
eps_inversion = inversion(M, img)
loss = 1 - cos(eps, eps_inversion)
eps = gradient_descent(loss, eps)
output eps
实验结果
实验配置
本工作用 SDXL 和 SDXL-turbo 模型做实验。去噪步数分别为 10, 4。
本工作在测试时只需要设置提示词。提示词来自于 Pick-a-pic, DrawBench, GenEval 这三个数据集。
-
Pick-a-Pic 收集了真实文生图应用中用户的输入提示词及相同提示词下不同输出的偏好程度。每项数据包含提示词、一对图像、一个表示用户偏好哪个图像的标签。 -
Drawbench 的每项数据包含提示词、一对图像、一个反映图像质量的偏好标签、一个反映提示词对齐度的偏好标签。这些提示词能从颜色、物体数量等多个角度测试模型生成属性。 -
GenEval 提供了能从单个物体、两个物体、物体数量、颜色、位置等多个角度测试模型的提示词。
为了对比生成图像质量,本工作用了 HPS v2, AES,PickScore, ImageReward 指标。除 AES 只考虑美学分数外,其他几个指标都是通过训练一个匹配人类偏好的模型来评估图像质量。除了给出这些指标的值外,论文还展示了方法的胜率——在同样的提示词下,比较使用/不使用新方法的定量结果,统计使用新方法胜利的频率。
定性定量结果
以下是噪声选取的实验结果。
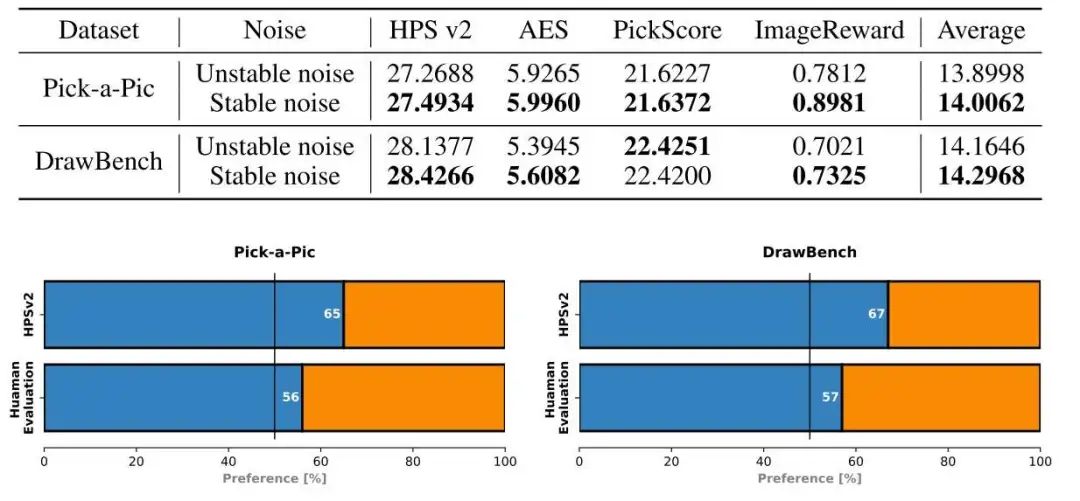
以下是噪声优化的实验结果。
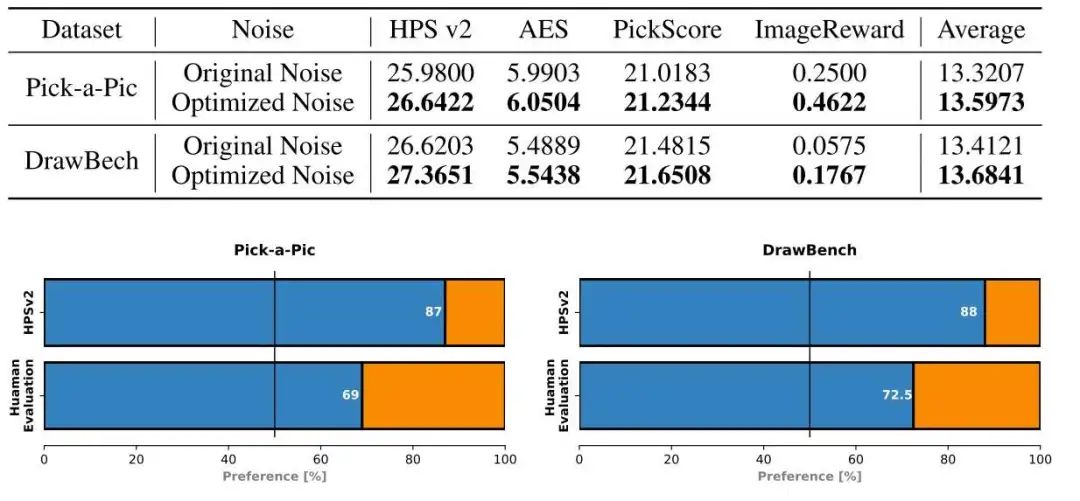
从定量结果中可以看出,本文的方法一定程度上确实是有效的。但是,这些数值上的提升真的总能反映在视觉效果上吗?这些数值上的提升足够大吗?由于缺乏同类方法的比较,这些实验还是欠缺说服力。
博文开头已经展示了本文的定性结果,这里就不再重复展示了。值得一提的是,本文的方法可以拓展到其他模型上,比如生成 3D 模型的 SV3D。以下是 3D 模型上的可视化结果。

审稿意见分析
在看 ICLR 2025 官方审稿人意见之前,我先给出我的一份简单审稿意见。我把本文的主要内容都在这篇博文里写出来了,读者也可以在阅读下面内容之前尝试给该论文打分。如果读者想着重提升审稿能力,可以先去把这篇论文细读一遍,再去 OpenReview 上审视其他审稿人的意见。
这篇文章发现了并非所有扩散噪声生成质量相同这一问题,并设计了反演稳定度这一衡量噪声质量的指标。定性和定量实验表明该方法确实能提升图像质量。
本文的优点在于新问题的发现:确实之前多数研究者只考虑如何优化模型,而忽视了噪声也是影响图像的重要因素。
本文在叙述和论证上均存在缺陷:
-
在为何要使用反演稳定性这件事上,作者说是受到了不动点理论的启发。但作者完全没有深入分析反演稳定性的原理,本质上是通过实验来直接验证假设的合理性。哪怕不好从数学原理上解释,作者也应该通过列出相关工作,并补充部分探究原理的实验,来巩固该指标的合理性。 -
本文的技术贡献并不多:优化噪声是一个非常常见的策略。 -
在实验中,作者没有和其他方法对比,完全看不出这个方法是否具有优越性。找出一个基准方法其实并不难:将 CFG (classifier-free guidance) 分别设置成 1 和 7.5 就是一个非常容易实现的基准方法。
如果是现在已经知道了优化噪声是一个有潜力的方向,我可能会给这篇论文一个位于接收临界线上的分数。但如果是去年的话,很可能给的是低于临界线的分数。
我们来简单看看官方审稿人的评价。
审稿人 A 给了明确的差评。文章的主要缺陷有:
-
虽然作者宣称这是首次研究噪声空间的论文,但实际上之前已经至少有三篇工作做过类似研究。因此,文章的创新性是有限的。 -
DDIM 反演稳定性差一部分是因为反演算法不够好导致的,而和扩散模型无关。最好能够展示更好反演算法下的结果。 -
评估不充分:这篇文章没有展示任何和其他方法的比较。另外,最好能展示诸如 FID,IS 等其他指标。文中的指标提升看起来微不足道,仅有约 1%,感觉不到明显的进步。 -
每次评估都需要执行一次加噪-去噪过程,方法性能较低。
审稿人 A 是这个方向的专家,他用已有的噪声空间优化工作来质疑本文的创新性。我简单看了一下该审稿人引用的工作,确实已经有不少往期工作做了类似的事,但实现方法还是比本文的方法更复杂一点。所以,不能说这篇论文一点创新也没有,作者必须严谨地比较这篇论文和之前的论文,并强调出创新点在哪。
审稿人 B 给了一份评价略低于临界线的短评。他认为这篇论文提出的「反演稳定性」及其实验结果还是非常合理的。他认为论文的主要缺陷是方法质量受到反演算法的影响,并希望作者给出不同反演策略下的结果。
审稿人 C 也给出了略低于临界线的评价。他认为这种使用反演稳定性来评估噪声质量的想法有新颖性,且实验的设置比较合理。在 3D 上的应用或许很有潜力。但他也列出了几条主要缺陷:
-
作者认为反演质量与生成质量强相关。但这个假设只是通过一个具体示例来验证,而缺少理论分析或者系统性的研究。一个可能的分析方法是:测试10万个样本,计算图像质量和反演稳定性的相关性。 -
和上面两个审稿人一样,审稿人 C 也提到了 DDIM 反演本身就不够好的问题。 -
噪声选取和噪声优化都需要大量计算资源。
审稿人 D 也给出了略低于临界线的评价。他同样认为反演稳定性是一种新颖的指标,作者对于方法设计动机阐述得十分清晰。他提到的主要缺陷有:
-
研究反演中的不同点并不是一个新颖的想法,之前至少有三篇工作从迭代优化来寻找反演不动点的文章。这篇文章没有与这些工作做对比。 -
从 K=100 个样本里选取噪声的方法太简单直接了。之前有类似工作用一种更深入的方式选取噪声。 -
缺乏和其他噪声优化论文的比较。 -
计算效率太低。
总结与反思
本工作明确指出了扩散模型不同初始噪声质量不同这一设计动机。为了找出更好的噪声,本工作用一种听起来比较有趣的「反演稳定性」来评估噪声质量。基于这个指标,本工作设计了噪声选取和噪声优化两个算法,用于两类生成任务。
多数审稿人都认可该工作的方法有一定的新颖性,但其论文有着诸多缺陷:
-
没有深入分析反演稳定性的原理,且没有考虑是否应该用更好的反演算法。 -
噪声优化是一种常见的策略。没有与相关工作做对比。 -
指标提升的说服力不足。 -
每次评估反演稳定性都需要执行去噪和加噪过程,运算效率过低。
当然,在目前的眼光看来,如果生成质量足够高,增加推理时间也是可以接受的。但是,论文的前几个缺陷是实实在在的,被评价为低于接收临界线合情合理。作者最后也没有 rebuttal,直接撤稿了。我感觉这篇论文还是比较可惜的,毕竟它的研究方向比较有潜力。
从这篇论文以及最近做推理时扩展的论文可以看出,哪怕对于同一项技术,改变看待问题的角度也算创新。比如同样是更换扩散模型噪声,如果是从推理时扩展的角度来看,那么运算时间长就不是缺陷了;但与之相对,我们需要证明随着运算时间的增加,生成质量会按某种规律逐渐变好,表明花更多的时间是有意义的。
从这篇论文投稿失败的教训中,我们也可以总结出顶会论文应该满足哪些最基本的要求。当论文的方法和之前方法非常相似时,一定要与之前的方法对比,并明确写出本文的创新点在哪。另外,虽然很多时候我们是先有了实验结果再去补充说明方法中的假设,但我们依然可以在论文里尝试解释我们这样做的原因。这种解释可以是通过原理上的推导,也可以是通过解释性实验。

(文:极市干货)