

这个项目还是新鲜出炉的。
2月12号刚刚发布。
能明显感觉到AI类模型在年后突然又涌现出一大批。
可能去年年底都在憋大招吧。
给大家简单介绍下这个项目,因为刚发布,重点看看DEMO,跟之前推荐的类似项目对比下。
扫码加入AI交流群
获得更多技术支持和交流
(请注明自己的职业)

项目简介
AnyCharV 是一个可控角色视频生成框架,能够将任意角色图像与目标驱动视频结合,生成高质量的角色视频。该方法通过“细到粗”的引导策略和两阶段训练机制,实现了角色细节的高保真度和复杂场景的自然融合。在第一阶段,模型利用细粒度分割掩码和姿态信息完成角色与场景的初步合成;第二阶段通过自增强训练,借助粗略的边界框掩码进一步优化角色细节。具有非常强的灵活性和高保真度。
DEMO
技术特点
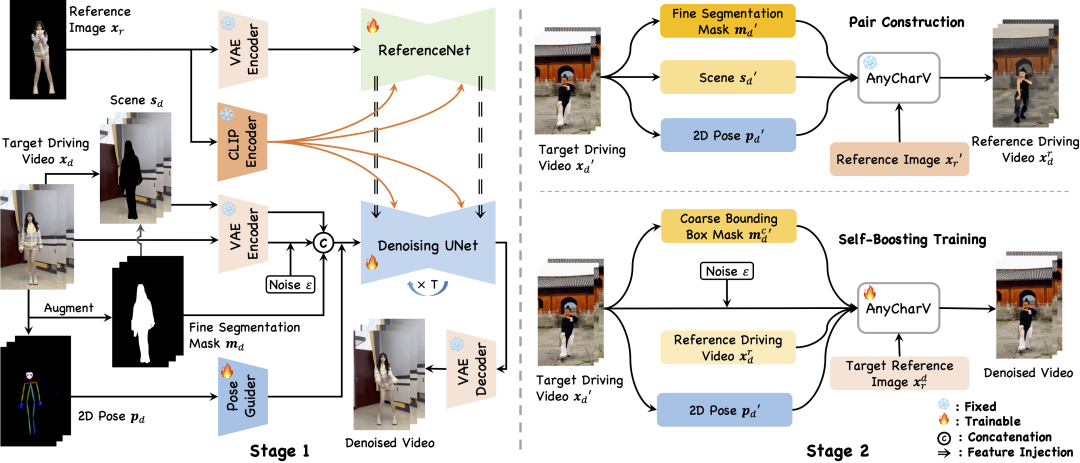
1.细到粗的引导策略
-
在第一阶段,通过细粒度分割掩码和姿态信息实现角色与目标场景的精准合成,确保运动和场景的正确性。
-
在第二阶段,采用粗略的边界框掩码进行自增强训练,减少细粒度掩码对角色形状的干扰,更好地保留角色细节。
2.两阶段训练机制
-
第一阶段:自监督学习,利用细粒度掩码和姿态信息完成角色与场景的初步融合。
-
第二阶段:自增强训练,通过生成的视频对进行训练,进一步提升角色细节的保真度和自然度。
3.高保真角色细节保留
-
引入参考图像的多路径特征注入(如 CLIP 编码器和 ReferenceNet),确保角色外观和身份的高保真度。
-
通过自增强训练和粗掩码引导,显著减少生成视频中的模糊和伪影。
4.灵活的场景与角色融合
-
能够将任意角色图像与任意目标视频场景结合,支持复杂的背景和人-物交互。
-
适用于多种应用场景,如艺术创作、影视制作和虚拟角色生成。
5.高效生成与广泛兼容性
-
生成效率高,仅需 5 分钟即可生成 5 秒的 24FPS 视频。
-
支持与文本到图像(T2I)、文本到视频(T2V)模型生成的内容结合,展现出强大的泛化能力。
项目链接
https://anycharv.github.io/
关注「开源AI项目落地」公众号
(文:开源AI项目落地)