


AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
-
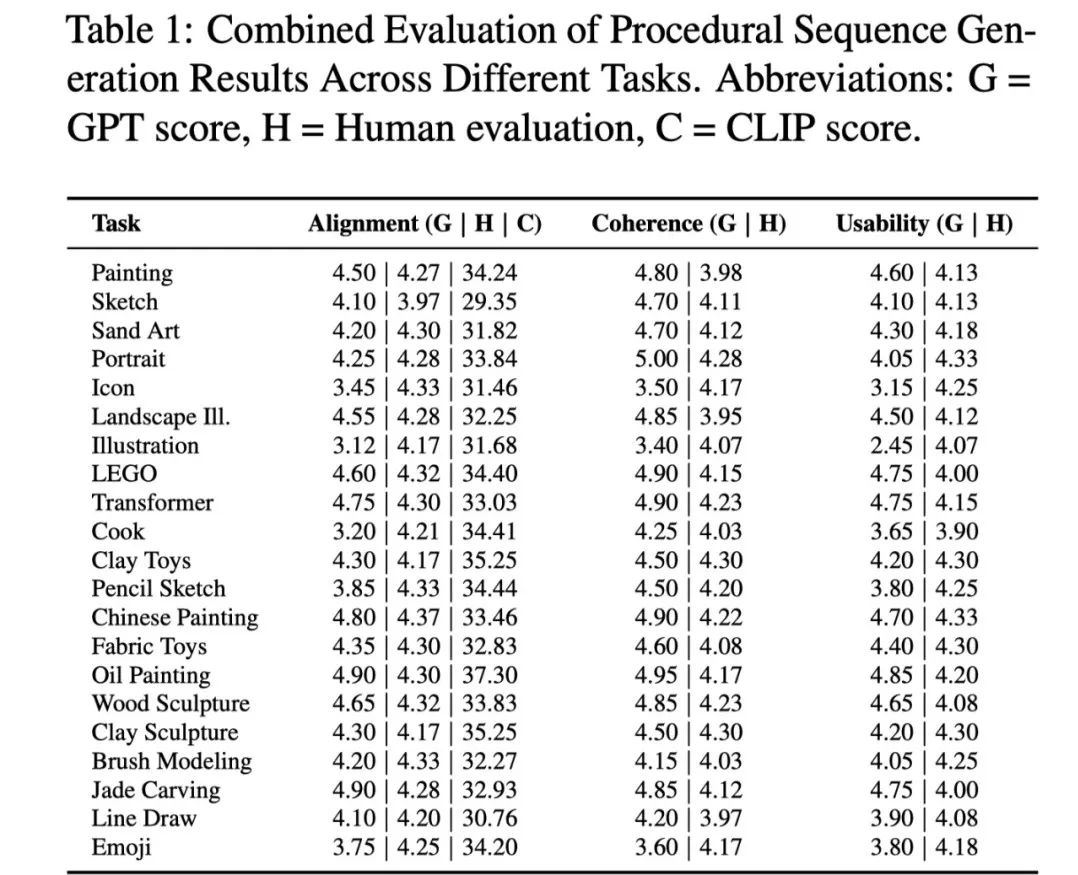
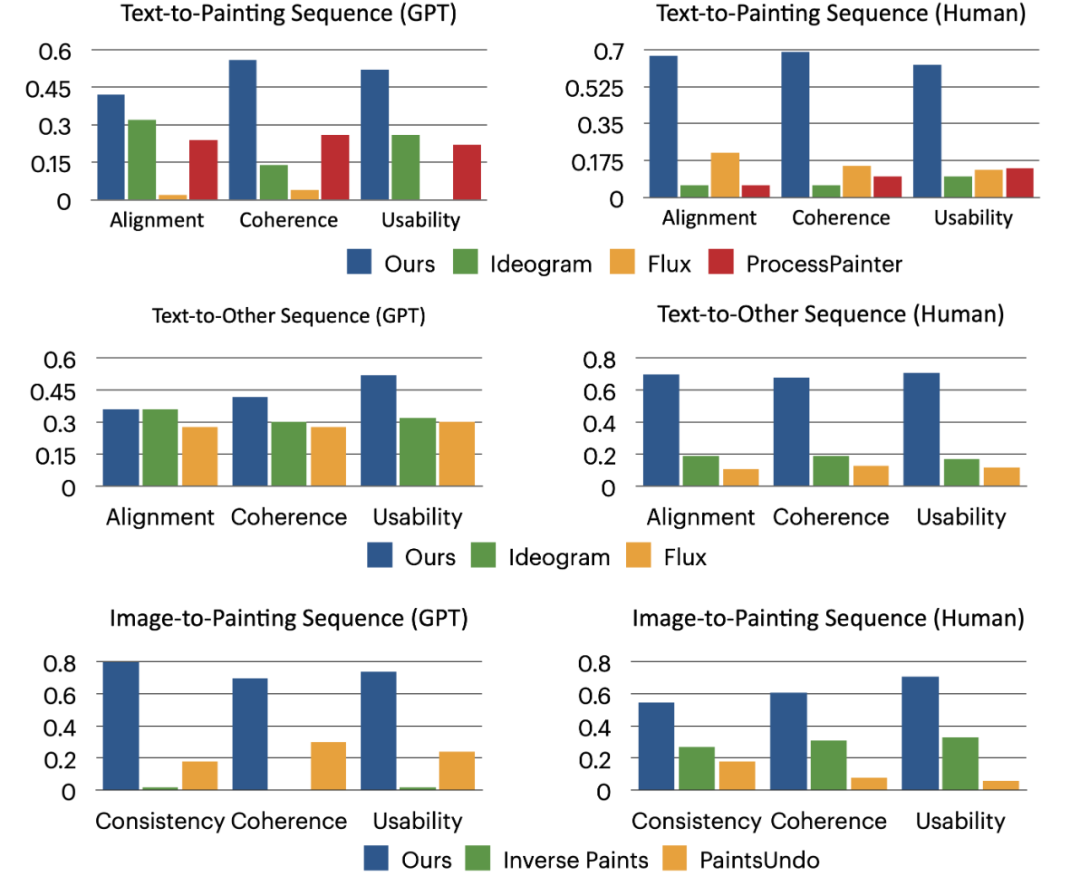
构建最大规模多领域数据集:涵盖各类绘画、手工艺、乐高组装、Zbrush 建模、变形金刚变形、烹饪等 21 类任务,包含超过 24,000 条标注序列,首次实现从 “单一生成” 到 “步骤逻辑” 的数据支撑; -
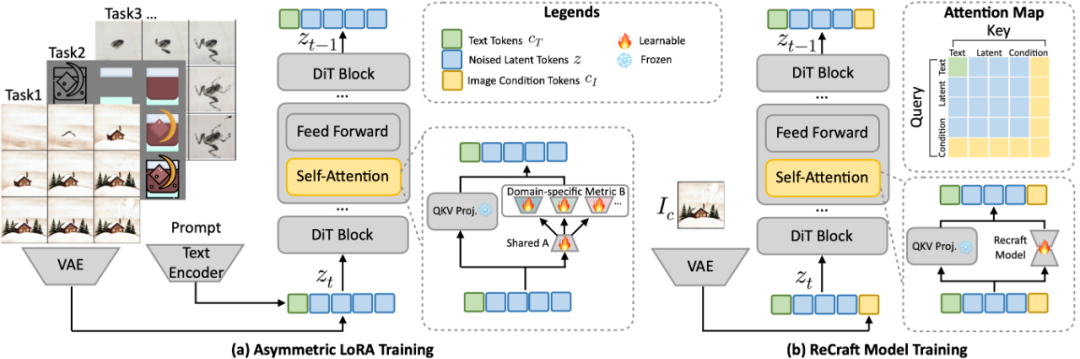
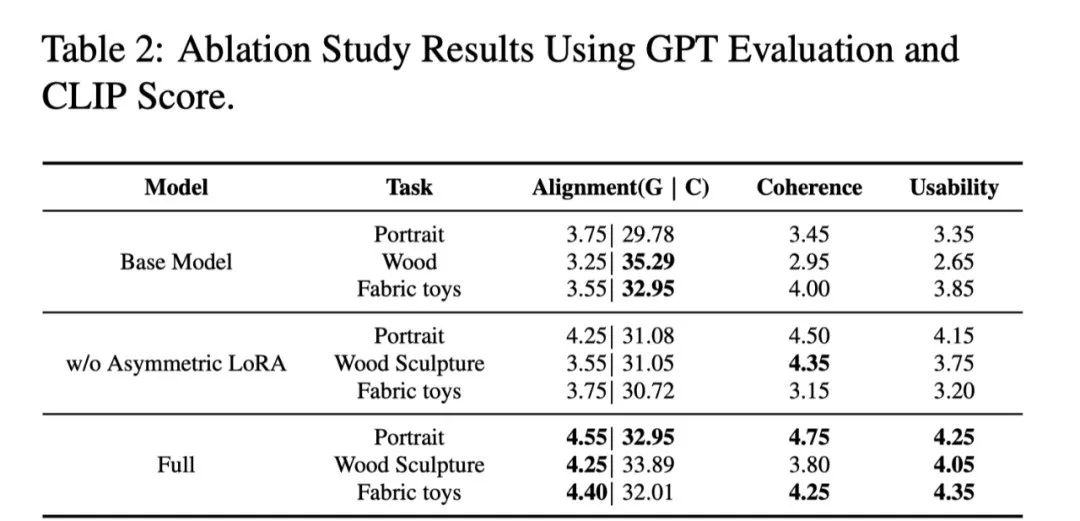
激活 DiT 的上下文能力:通过低秩微调激活 Flux 的上下文能力, 确保生成结果逻辑连贯性和外观一致性; -
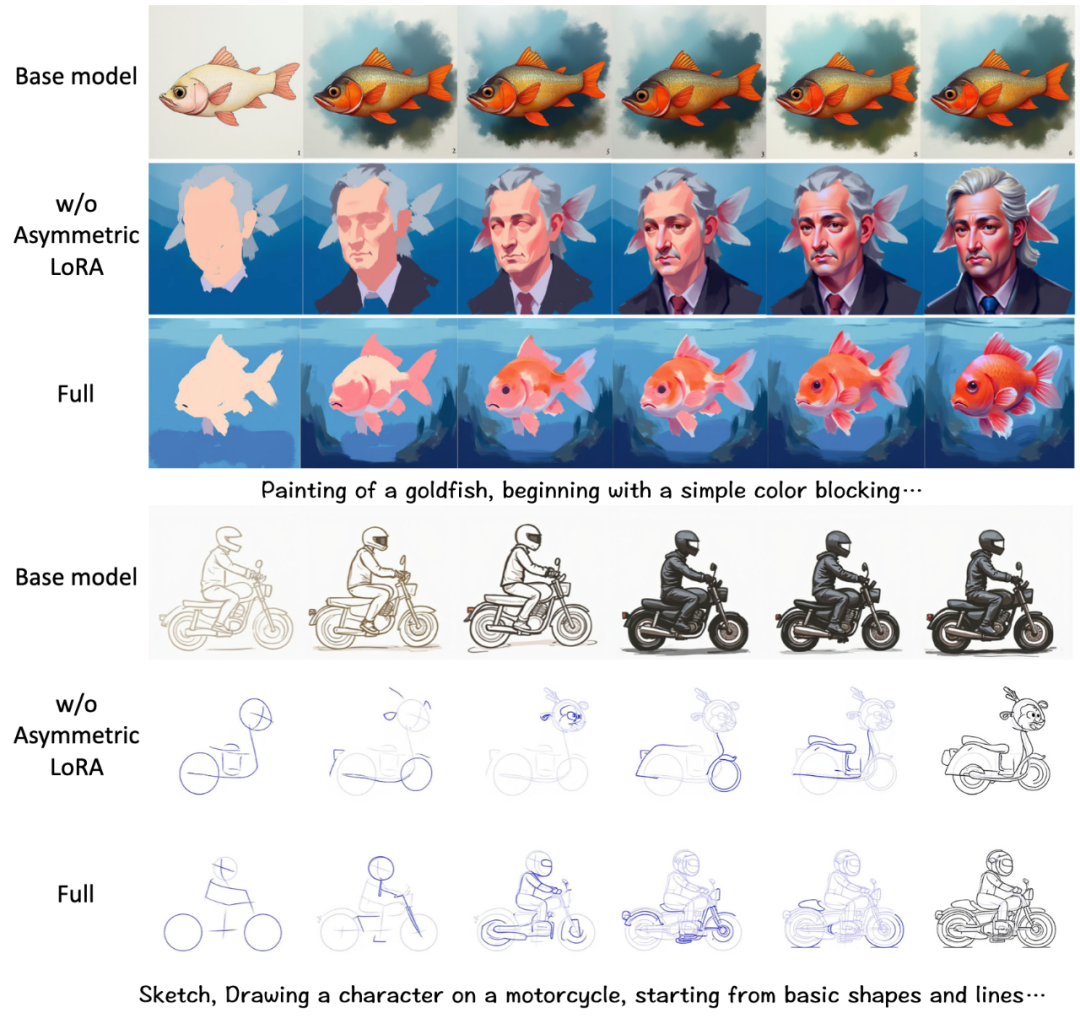
非对称 LoRA 设计:平衡通用知识与领域特性,显著提升跨任务泛化能力。






©
(文:机器之心)