
本文是 OpenAI 官方发布的关于推理模型(o 系列模型,如 o1 和 o3-mini)的最佳实践指南。文章对比了推理模型与 GPT 模型(如 GPT-4o)的特性与适用场景,详细介绍了推理模型的优势、适用场景,并提供了有效提示推理模型的实用技巧。

如何用好快思考和慢思考
OpenAI 提供两种类型的模型:推理模型(例如 o1 和 o3-mini)和 GPT 模型(如 GPT-4o)。这些模型家族的行为方式有所不同。
本指南涵盖以下内容:
-
1. OpenAI 推理模型和非推理 GPT 模型之间的区别 -
2. 何时应使用 OpenAI 推理模型 -
3. 如何有效地设计推理模型的提示词
推理模型与 GPT 模型对比
与 GPT 模型相比,OpenAI o 系列模型在不同任务上表现更优异,并且需要不同的提示词。两种模型系列并无优劣之分——它们只是各有侧重。
OpenAI 训练 o 系列模型(“规划者”)的目的是让其能够对复杂任务进行更深入持久的思考,使其能够有效地制定战略、规划复杂问题的解决方案,并基于大量模糊信息进行决策。这些模型还可以高精度和高准确性地执行任务,使其成为原本需要人类专家的领域的理想选择——如数学、科学、工程、金融服务和法律服务。
另一方面,OpenAI 的低延迟、更具成本效益的 GPT 模型(“工作负载模型”)专为直接执行任务而设计。应用程序可以使用 o 系列模型来规划解决问题的策略,并使用 GPT 模型来执行特定任务,特别是在速度和成本比完美精度更重要的情况下。
如何选择
对于您的用例,哪个方面最重要?
-
• 速度和成本 → GPT 模型速度更快,成本通常更低 -
• 执行定义明确的任务 → GPT 模型能很好地处理明确定义的任务 -
• 准确性和可靠性 → o 系列模型是可靠的决策者 -
• 复杂问题求解 → o 系列模型可以处理模糊性和复杂性
*如果速度和成本是完成任务时最重要的因素,并且您的用例由简单、定义明确的任务组成,那么 OpenAI 的 GPT 模型最适合您。但是,如果准确性和可靠性是最重要的因素,并且您有一个非常复杂的多步骤问题需要解决,那么 OpenAI 的 o 系列模型可能更适合您。*
大多数 AI 工作流将结合使用两种模型——o 系列用于基于智能体的规划和决策,GPT 系列用于任务执行。
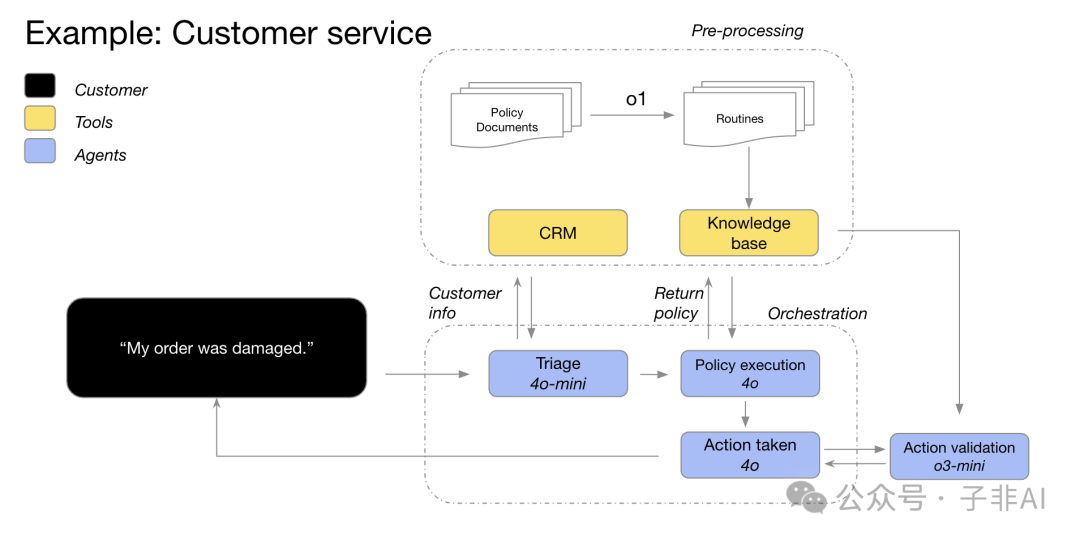
OpenAI 的 GPT-4o 和 GPT-4o mini 模型利用客户信息对订单详细信息进行分类,识别订单问题和退货政策,然后将所有这些数据点输入 o3-mini,以根据政策对退货的可行性做出最终决定。
何时使用 OpenAI 的推理模型
以下是 OpenAI 从客户和内部实践中观察到的一些成功使用模式。这并非对所有可能用例的全面概述,而是一些测试 o 系列模型的实用指南。
1. 处理模糊任务
推理模型特别擅长获取有限的信息或不同的信息片段,并通过简单的提示理解用户的意图,并处理指令中的任何空白。 事实上,推理模型通常会在进行未经训练的猜测或尝试填补信息空白之前,提出澄清问题。
“o1 的推理能力使OpenAI的多智能体平台 Matrix 能够在处理复杂文档时产生详尽、格式规范且详细的响应。例如,o1 使 Matrix 能够通过一个基本提示,轻松识别信贷协议中受限制支付能力下的可用篮子。没有之前的模型能达到如此性能。与其他模型相比,o1 在 52% 的关于密集信贷协议的复杂提示上产生了更优异的结果。”
——Hebbia,一家面向法律和金融领域的 AI 知识平台公司
2. 大海捞针
当您输入大量非结构化信息时,推理模型非常擅长理解并仅提取最相关的信息来回答问题。
“为了分析一家公司的收购,o1 审查了数十份公司文件——如合同和租约——以找出可能影响交易的任何棘手条件。该模型的任务是标记关键条款,并在此过程中,在脚注中发现了一个关键的“控制权变更”条款:如果公司被出售,它将不得不立即偿还 7500 万美元的贷款。o1 对细节的高度关注使OpenAI的 AI 智能体能够通过识别关键任务信息来支持金融专业人士。”
——Endex,AI 金融情报平台
3. 在大型数据集中发现关系和细微差别
OpenAI 发现推理模型特别擅长对具有数百页密集、非结构化信息的复杂文档进行推理——例如法律合同、财务报表和保险索赔。 这些模型尤其擅长在文档之间建立联系,并根据数据中未言明的真相做出决策。
“税务研究需要综合多个文档才能得出最终的、令人信服的答案。OpenAI 将 GPT-4o 换成了 o1,发现 o1 在推理文档之间的相互作用方面表现更出色,能够得出任何单个文档中都不明显的逻辑结论。因此,通过切换到 o1,OpenAI 实现了端到端性能 4 倍的提升——令人难以置信。”
——Blue J,一个用于税务研究的 AI 平台
推理模型还擅长对细致的政策和规则进行推理,并将它们应用于当前任务,以得出合理的结论。
“在财务分析中,分析师经常处理围绕股东权益的复杂场景,并且需要理解相关的法律细节。OpenAI 测试了来自不同提供商的约 10 个模型,提出了一个具有挑战性但常见的问题:融资如何影响现有股东,尤其是当他们行使反稀释特权时?这需要对投前和投后估值进行推理,并处理循环稀释——顶级财务分析师需要花费 20-30 分钟才能弄清楚。OpenAI 发现 o1 和 o3-mini 可以完美地做到这一点!这些模型甚至生成了一个清晰的计算表格,展示了对一个 10 万美元股东的影响。”
–BlueFlame AI,一个用于投资管理的 AI 平台
4. 多步骤的基于智能体的规划
推理模型对于基于智能体的规划和战略制定至关重要。 当推理模型被用作“规划者”时,OpenAI 已经看到了成功案例,它可以为一个问题生成详细的多步骤解决方案,然后根据高智能还是低延迟更重要,为每个步骤选择并分配合适的 GPT 模型(“执行者”)。
“OpenAI 在智能体基础设施中使用 o1 作为规划者,让它协调工作流中的其他模型来完成多步骤任务。OpenAI 发现 o1 非常擅长选择数据类型,并将大问题分解成更小的部分,使其他模型能够专注于执行。”
——Argon AI,一个面向制药行业的 AI 知识平台
“o1 为 OpenAI 在 Lindy(OpenAI 的工作 AI 助手)的许多智能体工作流提供支持。该模型使用函数调用从您的日历或电子邮件中提取信息,然后可以自动帮助您安排会议、发送电子邮件,以及管理您日常任务的其他部分。OpenAI 将所有以前会导致问题的智能体步骤都切换到了 o1,并观察到OpenAI的智能体在一夜之间变得几乎完美无瑕!”
——Lindy.AI,一个用于工作的 AI 助手
5. 视觉推理
截至目前,o1 是唯一支持视觉功能的推理模型。它与 GPT-4o 的不同之处在于,o1 可以掌握最具挑战性的视觉内容,例如结构模糊的图表和表格,或者图像质量较差的照片。
“OpenAI 为数百万在线产品自动执行风险和合规性审查,包括奢侈珠宝仿冒品、濒危物种和受管制物质。GPT-4o 在OpenAI最困难的图像分类任务上达到了 50% 的准确率。o1 在没有任何修改OpenAI流程的情况下,实现了令人印象深刻的 88% 的准确率。”
——SafetyKit,一个 AI 驱动的风险与合规平台
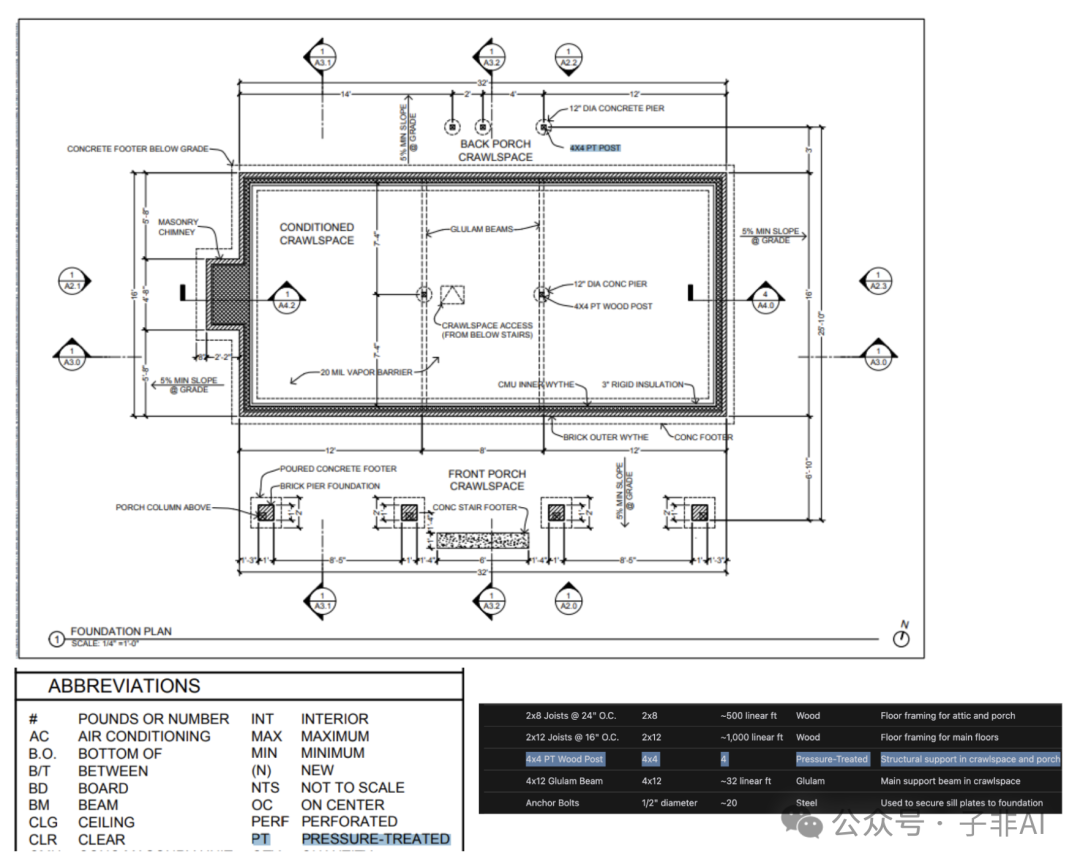
从 OpenAI 自己的内部测试中,OpenAI 看到 o1 可以从高度详细的建筑图纸中识别固定装置和材料,从而生成全面的材料清单。OpenAI 观察到的最令人惊讶的事情之一是,o1 可以通过在一页建筑图纸上获取图例,并在没有明确指示的情况下将其正确应用于另一页,从而在不同的图像之间建立联系。在下图中,您可以看到,对于 4×4 PT 木柱,o1 根据图例识别出“PT”代表经过压力处理。
6. 审查、调试和改进代码质量
推理模型在审查和改进大量代码方面特别有效,鉴于模型的较高延迟,通常在后台运行代码审查。
“OpenAI 在 GitHub 和 GitLab 等平台上提供自动化的 AI 代码审查。虽然代码审查过程本身对延迟不敏感,但它确实需要理解跨多个文件的代码差异。这就是 o1 真正擅长的地方——它能够可靠地检测到代码库中可能被人工审查员遗漏的微小变化。在切换到 o 系列模型后,OpenAI 能够将产品转化率提高 3 倍。”
——CodeRabbit,一家 AI 代码审查初创公司
虽然 GPT-4o 和 GPT-4o mini 可能更适合以其较低的延迟编写代码,但 OpenAI 也看到 o3-mini 在对延迟不太敏感的用例的代码生成方面有所突破。
“o3-mini 始终如一地生成高质量、结论性的代码,并且当问题定义明确时,即使对于非常具有挑战性的编码任务,也经常能够得出正确的解决方案。虽然其他模型可能仅适用于小规模、快速的代码迭代,但 o3-mini 擅长规划和执行复杂的软件设计系统。”
——Windsurf,由 Codeium 构建的协作式、基于智能体的 AI 驱动的 IDE
7. 评估和基准测试其他模型的响应
OpenAI 还看到推理模型在基准测试和评估其他模型响应方面表现出色。 数据验证对于确保数据集质量和可靠性非常重要,尤其是在医疗保健等敏感领域。传统验证方法使用预定义的规则和模式,但像 o1 和 o3-mini 这样的高级模型可以理解上下文并对数据进行推理,从而实现更灵活和智能的验证方法。
“许多客户使用 LLM-as-a-judge 作为他们在 Braintrust 中评估流程的一部分。例如,一家医疗保健公司可能会使用像 gpt-4o 这样的工作负载模型来总结患者问题,然后使用 o1 评估摘要质量。一位 Braintrust 客户看到,使用 4o 时,评判者的 F1 分数从 0.12 提高到使用 o1 时的 0.74!在这些用例中,他们发现 o1 的推理在发现完成结果中的细微差异方面,是一个游戏规则改变者,尤其适用于最困难和最复杂的评分任务。”
——Braintrust,一个 AI 评估平台
如何有效地设计推理模型的提示词
这些模型在使用直接提示时表现最佳。 一些提示工程技巧,例如指示模型“逐步思考”,可能不会提高性能(有时甚至会阻碍性能)。请参阅下面的最佳实践,或从提示示例开始。
-
• 开发者消息是新的系统消息:从 o1-2024-12-17开始,推理模型支持开发者消息而不是系统消息,以与模型规范中描述的命令链行为保持一致。 -
• 保持提示简单直接:模型擅长理解和响应简短、清晰的指令。 -
• 避免思维链式提示:由于这些模型在内部执行推理,因此提示它们“逐步思考”或“解释您的推理”是不必要的。 -
• 使用分隔符(如 Markdown、XML 标记和章节标题)以提高清晰度:使用分隔符来清晰地指示输入的不同部分,帮助模型适当地解释不同的部分。 -
• 先尝试零样本学习,如果需要再尝试小样本学习:推理模型通常不需要小样本示例来产生良好的结果,因此请尝试首先编写没有示例的提示。如果您对所需输出有更复杂的要求,那么在提示中包含一些输入和所需输出的示例可能会有所帮助。只需确保示例与您的提示说明非常接近,因为两者之间的差异可能会产生不良结果。 -
• 提供具体指南:如果您希望明确限制模型的响应(例如“提出预算低于 500 美元的解决方案”),请在提示中明确概述这些约束。 -
• 非常具体地说明您的最终目标:在您的说明中,尝试为成功的响应提供非常具体的参数,并鼓励模型继续推理和迭代,直到它符合您的成功标准。 -
• Markdown 格式:从 o1-2024-12-17开始,API 中的推理模型将避免生成带有 Markdown 格式的响应。要向模型发出信号,表明您确实希望响应中包含 Markdown 格式,请在开发者消息的第一行包含字符串Formatting re-enabled。
推荐阅读
如需更多灵感,请访问下列资源链接,了解OpenAI的模型和推理能力:
-
• 推理模型最佳实践:https://platform.openai.com/docs/guides/reasoning-best-practices -
• 视频课程:使用 o1 进行推理:https://www.deeplearning.ai/short-courses/reasoning-with-o1/ -
• 关于高级提示以改进推理的论文:https://cookbook.openai.com/related_resources#papers-on-advanced-prompting-to-improve-reasoning
(文:子非AI)