
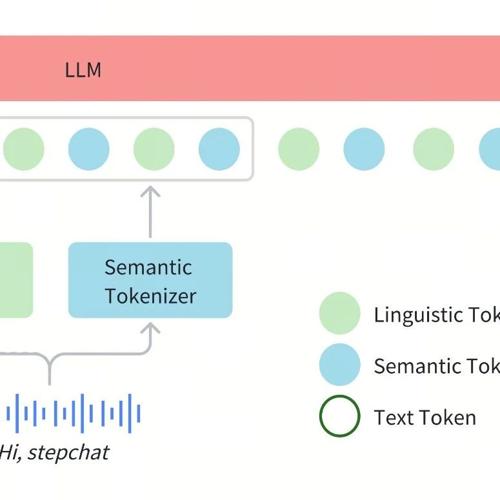
Step-Audio-TTS-3B是业界首个能够生成RAP和哼唱的TTS模型,标志着语音合成领域的一次重大进步。




参考文献:
[1] https://huggingface.co/stepfun-ai/Step-Audio-TTS-3B
[2] https://github.com/stepfun-ai/Step-Audio
[3] https://huggingface.co/stepfun-ai/Step-Audio-Tokenizer
[4] https://huggingface.co/stepfun-ai/Step-Audio-Chat
[5] Step-Audio: Unified Understanding and Generation in Intelligent Speech Interaction:https://arxiv.org/abs/2502.11946
(文:NLP工程化)