Fish Audio 的 OpenAudio S1:新一代语音生成,让机器也能“声临其境”!

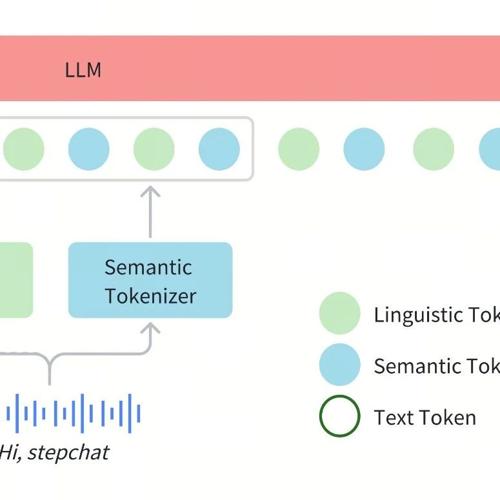
OpenAudio S1 是 Fish Audio 推出的多语言 TTS 模型,基于超过200万小时的音频数据训练,采用双自回归架构和强化学习与人类反馈技术。支持13种语言、40亿参数版本及5亿参数开源版,并具备零样本语音克隆功能。
OpenAudio S1 是 Fish Audio 推出的多语言 TTS 模型,基于超过200万小时的音频数据训练,采用双自回归架构和强化学习与人类反馈技术。支持13种语言、40亿参数版本及5亿参数开源版,并具备零样本语音克隆功能。

HyperAI超神经官网推出OpenAudio-s1-mini教程,介绍高效文本转语音生成工具。OpenAudio S1包含OpenAudio-S1和OpenAudio-S1-mini版本,在大规模音频数据上训练,参数扩展至40亿,并引入奖励建模及RLHF训练机制,显著提升音频质量、情感表达和说话人相似度。该模型仅需每百万字节15美元(约0.8美元/小时),支持多种情感、语调和特殊标记。HyperAI超神经提供免费RTX 4090资源体验OpenAudio-s1-mini功能。
Resemble AI 推出免费开源 TTS 模型 Chatterbox,在盲测中击败 ElevenLabs,具备情感控制能力,并支持语音克隆和风格定制。

怪怪的TTS让作者关掉公众号的朗读功能,直到体验到新的TTS模型后才改变看法。MiniMax Audio模型具备顶尖TTS技术、高精度声音克隆和丰富的音色效果等亮点,支持多个语种,并且海外版具有更出色的效果。

网易有道 EmotiVoice 开源模型支持多语言和多种音色,具有情感合成功能。通过Docker镜像或本地安装方式快速部署使用,满足开发者和企业多样化需求。
OpenAI 发布三款新模型:语音转文本(STT)和文本转语音(TTS),以及一个调试工具网站 OpenAI.fm。STT 模型价格更优且性能更好;TTS 效果一般但可控性强;PlayGround 界面友好,支持代码导出功能。