

本来是计划周末发出这篇推文的,因为临时忙其它事情,放到今天才发布。大家在使用模型的时候应该还记得 9.9 和 9.11 哪个数值更大的问题,之前的模型给出的结果是错的,到了DeepSeek-R1 总算把正确的分析思路和答案给出来了。
但是,个人实际使用过程中给到DeepSeek模型一张花的图片,它是没有办法识别“花具体是什么品种”的。因为多模态大模型的识别依赖大量训练数据,由于训练数据的细粒度类别标注成本巨大,所以导致了大模型缺乏细粒度视觉识别能力。
DeepSeek的“细粒度野心”
当全球AI社区仍在为参数规模和算力军备竞赛争论不休时,中国AI新势力DeepSeek正悄然开启另一条赛道,即细粒度多模态理解与可控生成。
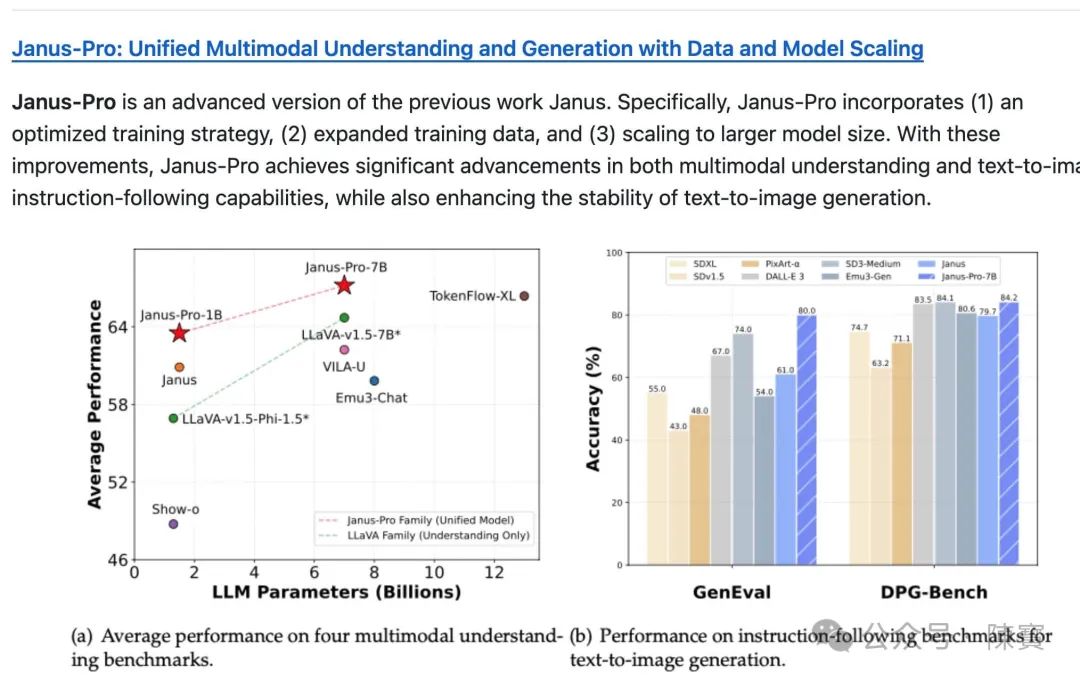
它最新发布的Janus-Pro多模态模型在GenEval基准测试中击败DALL-E 3和Stable Diffusion,而DeepSeek-VL系列更以“识别高分辨率图像中的细小物体”为卖点。
揭示了一个核心命题,AI的下一场战役,将从“暴力堆料”转向“精准拆解”。
细粒度能力绝非简单的技术指标提升,这是有难度的事情,因为它是对现有AI范式的三重颠覆。
感知维度重构,传统多模态模型依赖粗粒度特征融合,而DeepSeek-VL通过“视觉-语言适配器训练+联合预训练”的三阶段架构,将像素级细节与语义描述动态绑定。
例如,在医疗影像场景中,模型不仅能识别“肺部阴影”,还能解析“直径2mm的磨玻璃结节边缘纹理”。
生成控制升维,Janus-Pro通过“指令跟踪功能强化”,使文生图过程从“概率匹配”升级为“逻辑推演”。
用户输入“夕阳下奔跑的猎豹,毛发清晰且背景虚化”时,模型能解构“毛发清晰度”“景深参数”“运动模糊系数”等子任务,而非简单调用风格标签。
成本效率革命,凭借自研MLA架构压缩KV Cache、稀疏MoE层设计,DeepSeek以2048块H800 GPU、557万美元成本完成6700亿参数模型训练。
“低成本高精度”模式,为细粒度能力的大规模普及扫清算力障碍。
细粒度能力的“三重门”
数据困境中,存在从“大而全”到“小而精”的悖论。多模态训练依赖ShareGPT4V、LAION-GPTV等公开数据集,但这些数据存在显著缺陷。
图像标注多停留在物体级(如“狗”),缺乏部件级(“犬齿形态”)和属性级(“毛发反光系数”)描述。
现有数据以静态场景为主,难以支持视频中“细胞分裂过程”“机械臂微操作轨迹”等时空细粒度建模。
DeepSeek虽通过合成数据生成技术优化推理能力,但若无法建立跨模态细粒度标注体系,模型将长期受限于“见林不见树”的认知层级。
传统Transformer架构的全局注意力机制,本质上是一种“民主投票式”特征提取,难以聚焦微观特征。
DeepSeek虽通过多头潜在注意力(MHLA)提升局部感知,但在实际应用中仍暴露局限。
计算冗余,为捕捉细粒度特征被迫增加头数,导致H20芯片集群能耗攀升。
跨模态对齐偏差,视觉特征图中“电路板焊点”与文本描述“锡球直径0.3mm”的映射关系,常因注意力权重分配失衡而断裂。
这要求架构创新从“堆叠模块”转向“动态重组”。
例如,引入可微分神经架构搜索(DNAS),针对不同粒度任务自动优化子网络组合。
评价体系缺失之后,容易造成“基准测试”沦为“田忌赛马”。
现有评测标准严重滞后于技术发展,MATH基准测试关注数学题正确率,却忽视解题过程的逻辑链细粒度验证。
DPG-Bench虽能评估文生图质量,但对“可控生成”的测评仍停留在“风格匹配”层面,缺乏对“光照参数调整”“物理规则遵守”等微观控制力的量化。
DeepSeek R1被指“选择性披露优势测试结果”,在部分任务中仍落后于谷歌Gemini Flash 2.0,这暴露出行业亟需建立细粒度能力的“显微镜式”评测体系。
“感知智能”到“控制智能”
想突破上述困局,DeepSeek 就需要引领一场多模态学习范式的系统性变革了,它的核心路径概括为“一个基础、两条主线、三层重构”。
(一)基础:构建“原子级”多模态知识图谱。
数据原子化,将图像分解为超像素(Superpixel)、视频拆解为时空体素(Spatiotemporal Voxel)、文本解析为语义角色框架(SRL),建立跨模态的“最小可解释单元”映射库。
知识蒸馏,借鉴High-Flyer在金融AI中的“高频信号分解”经验,设计针对细粒度特征的层次化蒸馏策略。
例如,将“芯片显微图像分析”任务分解为“金属层厚度测量→导线排布合规性检测→热力学仿真”子模块链。
(二)主线:开发“显微级”动态注意力机制和打造“手术刀式”可控生成引擎。
MLA架构基础上,引入视觉局部窗口注意力(Local Window Attention)与语言依存树注意力(Dependency Tree Attention)的混合计算模式,实现“像素-词素-句法”三级对齐。
借鉴Janus-Pro的指令跟踪优化思路,将细粒度生成任务建模为马尔可夫决策过程,通过PPO算法动态调整注意力权重分配策略。
基于DeepSeek-R1的蒸馏模型特性,开发“参数空间编辑”工具,允许用户通过滑动条精确控制生成结果的粒度属性(如“图像锐化度±5%”“文本情感强度0.8→0.9”)。
工业设计场景中,将生成器与有限元分析(FEA)工具链集成,确保“齿轮模数设计图”既符合视觉细节要求,又满足力学性能指标。
(三)重构:技术栈、基础设施、应用生态的协同进化。
算力层,依托英特尔酷睿Ultra处理器的端侧推理能力,推动细粒度模型向边缘计算迁移,实现“显微镜+手术刀”的实时级应用。
平台层,借鉴基石智算云服务的模型分发模式,构建细粒度能力API市场,支持开发者按需调用“细胞核分割”“法律条文歧义检测”等微观功能模块。
评价层,联合学术界建立OpenGrader开源评测框架,新增“细粒度一致性(Fine-grained Consistency)”“可控性熵(Controllability Entropy)”等指标,终结基准测试的“盲人摸象”时代。
DeepSeek的探索预示着,AI正在从“大力出奇迹”的蛮荒时代,走向“纤毫毕现”的精密时代,我认为该转变将引发链式反应。
⋯ ⋯
半导体检测、病理诊断等高精度领域将迎来自动化革命,据测算,仅芯片缺陷检测效率即可提升300%。
细粒度生成能力也会重塑内容创作范式,未来自媒体或需标注“文章情感粒度分布图”“视频镜头切换动机树”以通过平台审核。
“像素级伪造”与“语义级操控”的叠加,将使深度伪造检测从“真伪判别”升级为“意图溯源”,催生新型数字伦理框架。
⋯ ⋯
获得最后胜利之前,隐忧的问题总是一直存在的。当DeepSeek以“小米加步枪”式的创新颠覆行业时,它的技术民主化愿景也会遭遇算力寡头的反制。
久久为功,是很重要的事情。若不能建立开放协同的细粒度技术生态,中国AI或将在“精密能力”赛道再次陷入“架构领先,生态滞后”的怪圈。
DeepSeek的突围,本质上是一场“降维打击”与“升维思考”的辩证实践。当行业沉迷于参数竞赛时,它选择深耕“微观世界”。当巨头固守封闭生态时,它坚持开源开放,战略定力正是中国AI跳出“追赶叙事”、定义新范式的关键。
(文:陳寳)