作者|沐风
来源|AI先锋官
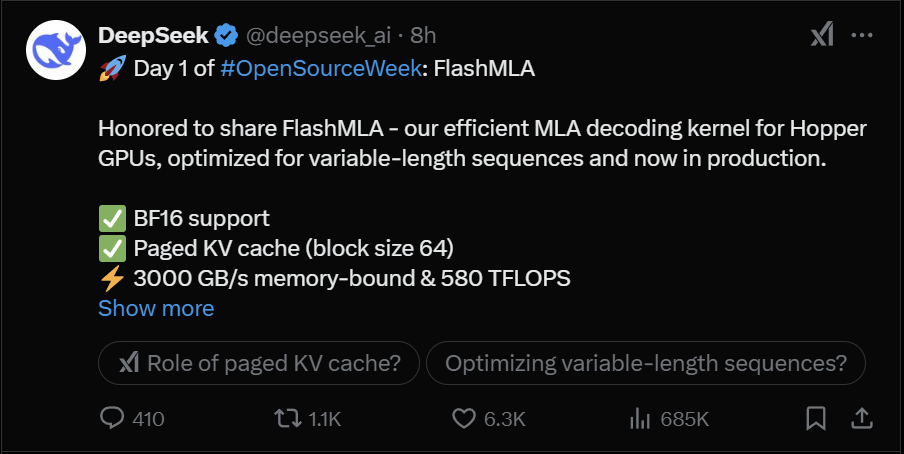
2月24日,DeepSeek的“开源周”,开源了他们第一天的项目FlashMLA。
开源地址:https://github.com/deepseek-ai/FlashMLA
在DeepSeek整个技术路线中,MLA(多头潜在注意力机制)是DeepSeek已经发布的V2、V3两款模型中,最为核心的技术之一。
此前,中国工程院院士、清华大学计算机系教授郑纬民曾提及:“DeepSeek自研的MLA架构为其自身的模型训练成本下降,起到了关键作用。”
他指出,“MLA通过改造注意力算子压缩了KV Cache大小,实现了在同样容量下可以存储更多的KV Cache,该架构和DeepSeek-V3模型中FFN 层的改造相配合,实现了一个非常大的稀疏MoE 层,成为DeepSeek训练成本低最关键的原因。”
而FlashMLA则是针对Hopper GPU开发的高效MLA解码内核,专为处理可变长度序列而设计,目前已投入了生产。
Hopper GPU是指基于英伟达Hopper架构研发的H系列GPU产品。
目前,英伟达该系列芯片已经发布H100、H800和H20等多款芯片。
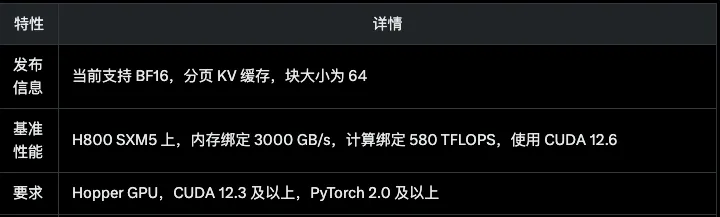
据DeepSeek方面介绍,在基准测试性能表现上,FlashMLA可以使得H800达到3000GB/s内存,实现580TFLOPS(每秒浮点运算次数)计算性能。
可以说,DeepSeek真的把自己最牛*的东西开源出来了。
公开资料显示,根据美国出口管制规定,H800的带宽上限被设定为600 GB/s,相比一些旗舰产品有所降低。
这意味着,使用FlashMLA优化后,H800的内存带宽利用率有望进一步提高甚至突破H800 GPU理论上限,在内存访问上达到极致,能让开发群体充分“压榨”英伟达H系列芯片能力,以更少的芯片实现更强的模型性能,最大化GPU价值。
虽然FlashMLA是一个针对Hopper GPU的优化代码库,但对于国产GPU而言,此次开源也有利好。
对于国产GPU而言,现在可以通过FlashMLA提供的优化思路和方法论,尝试让国产卡大幅提升性能,即使架构不同,后面国产卡的推理性能提升将是顺理成章的事儿。
结合此前DeepSeek发布的论文《Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention》。
如果将FlashMLA视为针对推理解码做的“终极性能提升”,那么Native Sparse Attention就是对训练和推理做更全面的“稀疏化改革”。
两者结合到一起,DeepSeek的意思就很明显,“无论训练还是推理,我都要把硬件榨干。”
目前,FlashMLA在Github上已经达到了5.9kStar。
可想而知,在后面的四天里,DeepSeek还会给大家带来多牛*的惊喜。
(文:AI先锋官)