


翻译自:https://huggingface.co/spaces/nanotron/ultrascale-playbook
作者:nanotron
校正:pprp
寻找最佳训练配置
目前已经讨论了所有实际用于分发和训练大型模型的并行技术,以及它们如何以及为什么可以组合在一起。现在还有一个普遍问题:最终我们应该选择哪些技术,以及如何决定具体的组合方式?
我们在前一节中稍微提到了这个问题,但现在详细地走一遍可能的决策过程,逐步进行,记住我们需要运行一些实验,以找到适合给定计算集群的最终最优设置,考虑其各种物理特性、网络带宽、每个节点的GPU数、每个GPU的内存等。
步骤1:将模型放入到Memory中 (Model Size维度)
首先,我们需要弄清楚如何将完整的模型实例适配到GPU上。一般有两种情况。
GPU丰富情况 🤑 – 当您有大量GPU可用时:
-
对于小于10B参数的模型,可以使用单一的并行技术,例如张量并行TP或ZeRO-3/DP结合在8个GPU上进行完整重计算 -
对于需要超过8个GPU的10B-100B参数模型,您有几个选项: -
结合张量并行(TP=8)和流水线并行(PP) -
结合张量并行(TP=8)和数据并行(ZeRO-3) -
仅使用ZeRO-3(即纯粹的数据并行) -
在512+ GPU规模下,纯DP/ZeRO-3由于通信成本开始变得低效 – 在这种情况下,结合DP与TP或PP可能更好 -
在1024+ GPU规模下,推荐的设置可以是张量并行TP=8与DP(ZeRO-2)和流水线并行PP结合
特殊情况:
-
对于非常长的序列,可能需要跨节点使用上下文并行(CP)。 -
对于专家混合体系结构,将优先使用跨节点的专家并行(EP)。
GPU资源匮乏情况 😭 – 当您的GPU资源可能不足时:
-
可以启用完全的Activation Recomputation,用计算来换空间,但是这会导致训练速度变慢。 -
可以增加梯度累积 Gradient Accumulation 中的Micro Batch 以处理具有有限内存的更大批次。
现在我们已经有了第一个模型实例进行训练,那么如何正确的设置batch size?
步骤2:实现目标Global Batch Size (BS维度)
根据步骤1中Micro Batch和DP,当前的BS可能太小或太大。如何达到target batch size?
为了增加当前的Global Batch Size:
-
可以扩展数据并行DP或梯度积累Gradient Accumulation步骤 -
对于长序列,我们可以利用上下文并行 CP
为了减少当前的Global Batch Size:
-
可以减少数据并行DP,转而支持其他并行策略 -
对于长序列,可以减少上下文并行 CP
好的,现在我们的模型在模型大小和Batch Size方面运行在我们想要的一般配置下,但我们是否正在以最快的方式训练它?现在让我们尽可能地开始优化吞吐量。
步骤3:优化训练吞吐量 (Throughput维度)
我们希望确保训练尽可能快速,以便我们所有宝贵的GPU在任何时候都能得到充分利用。只要内存和通信不是瓶颈,我们可以尝试以下方法:
-
扩展张量并行 TP(利用快速的节点内带宽),直到接近节点大小,以便减少其他并行性。 -
增加数据并行 DP 与ZeRO-3,同时保持Target Batch Size -
当数据并行 DP 通信开始成为瓶颈时,过渡到使用流水线并行 PP -
逐个尝试扩展不同的并行策略 -
尝试几种 Micro Batch(MBS),以寻求最大GBS、模型大小、计算和通信之间的最佳平衡。
成千上万个配置的基准测试
现在我们已经详细介绍了每一步,让我们将这个搜索过程应用于现实中。
您将在 nanotron 仓库[1]中找到几个脚本,可以用来运行我们上述讨论的所有实验,并能够在实际基准测试您自己的模型和集群。
我们实际上对数千种分布式配置进行了自我基准测试,涵盖了上述讨论的所有模型大小,以及能够尝试的非常大量的集群配置(即 8xH100s 的 1-64 个节点),可以用来复现本书中的结果。
现在汇总和分析我们所有基准测试的结果,看看除了理论之外,是否可以在真实数据上发现各种配置彼此之间的差异。
所有以下基准测试均以序列长度为4096和Global Batch Size为1M tokens进行。我们收集了每个模型和集群大小的最佳配置,并在以下热图中进行了展示:
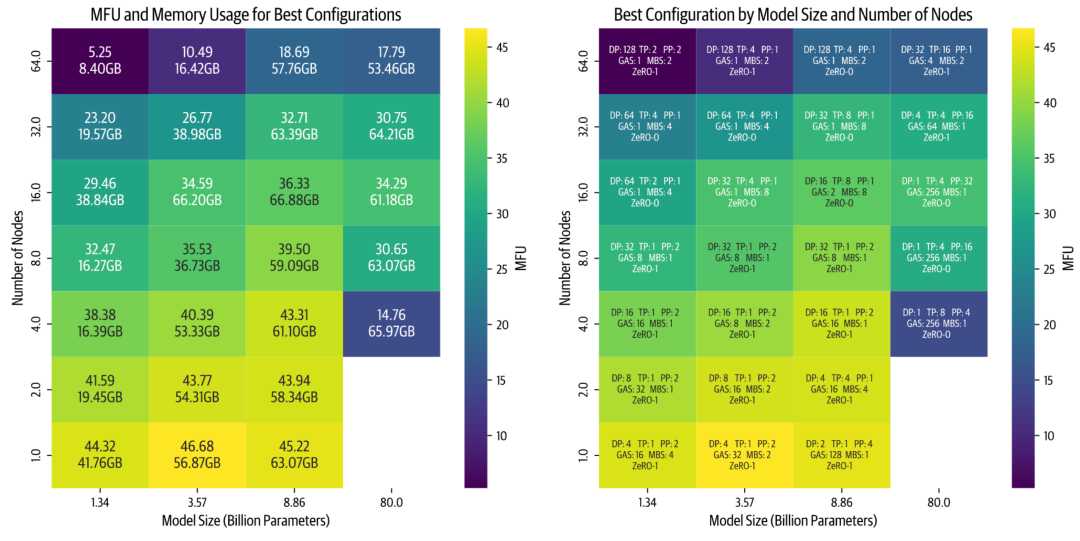
编者注: GAS: Gradient Accumulation Steps; MBS: Micro Batch Size; MFU: Model FLOPs Utilization; 这张图非常宝贵,因为我们可以直接用来查询显存使用情况,比如当前有一个Node,我希望训练一个8B的模型,那么可以通过上图查询得到每张卡至少需要63GB显存,并且最优配置给出了,DP2 TP1 PP4 GAS128 Zero-1。
通过这个高级别的可视化,我们可以得出几个重要的insight:
-
随着节点数量的增加(更高的并行性),效率会下降。这种效果在较小的模型中尤为显著,因为其计算与模型大小比例较低。虽然通常可以通过增加批次大小来补偿小模型大小,但我们受到全局批次大小 GBS 限制 1M 的约束。 -
较大的模型表现出了不同的挑战。随着模型大小的增加,内存需求显著增加。这导致了两种情况在较少节点时出现: -
要么模型根本不适合 (上图右下角空白处) -
要么几乎适合但由于接近GPU内存限制而运行效率低下(例如在 4 个节点上训练 80B 参数模型)。
最后,基准测试显示性能严重依赖于实现质量。当首次实施两种并行策略时,张量并行(TP)优于流水线并行(PP)。在优化了PP代码之后,它成为了更快的选项。现在我们正在改进TP实现中的通信重叠,预计它将重新获得性能优势。
基准测试中的经验教训
我们对本书的目标不仅仅是讨论理论和实现,还提供实际数据点。因此,计划很简单:运行每种模型的每种可能的分布式配置,以及多个集群大小(即每个节点8xH100的1-64个节点)。即使排除了不可能的配置,我们仍然需要运行数千次实验。
这听起来足够简单:我们可以在集群上轻松启动大量作业。然而,一旦我们启动了第一批实验,问题就开始出现:
-
PyTorch进程有时无法正确清理 -
Slurm作业管理器会强制终止作业,导致节点故障 -
本应只需几分钟的简单基准测试变成了几个小时 -
有些作业会无限期挂起
在有限的时间内运行所有实验需要额外的工程设计,最终花费了大量时间处理诸如:
-
最小化集群重启时间并优化空闲时间 -
分析详细的NCCL调试日志 -
了解内存使用模式和CUDA内存分配器行为 -
改进多节点上的流水线并行性能
这些挑战值得分享,但它们教会了我们有关分布式训练基础设施复杂性的宝贵教训。理论上看起来简单的东西,在实践中往往需要对许多运作部件进行仔细关注。
在实践中复现理论结果是具有挑战性的,特别是由于生产训练代码的有限可用性。通过像 nanotron 和 picotron 这样的开源项目,我们希望能够帮助使分布式训练技术更加可访问,并在简单高效的代码库上进行合作,帮助研究人员和从业者充分利用他们的硬件资源。
到这里,这结束了我们对5D并行方法分布的深入探讨。
回顾我们迄今为止的讨论,我们的许多讨论都依赖于一个关键假设 – 即可以在GPU上有效地重叠计算和通信,而不会对计算吞吐量产生影响。现实情况更加微妙。当使用像NCCL send/recv这样的常见通信原语时,我们面临计算资源和通信资源之间的隐藏竞争,因为通信核心通常会使用相同的GPU流处理器(SM),这些SM用于计算,导致在通信与计算重叠时吞吐量降低。要真正优化分布式训练,需要更深入地了解GPU架构本身。
Reference
[1] https://github.com/huggingface/nanotron
[2] https://github.com/huggingface/picotron
(文:GiantPandaCV)