作者|子川
来源|AI先锋官
来了来了,终于等到了基于Qwen2.5-Max的推理模型!
就在今天,通义千问团队发布了最新的深度推理模型QwQ-Max-Preview预览版,这是继QwQ-32B-Preview之后,千问团队再次推出推理模型。
据介绍,QwQ-Max-Preview的基础模型是Qwen2.5-Max,它将更加擅长数学、编程、与Agent相关的任务。
虽然QwQ-Max-Preview目前是一个预览版,但实力非常抗打。
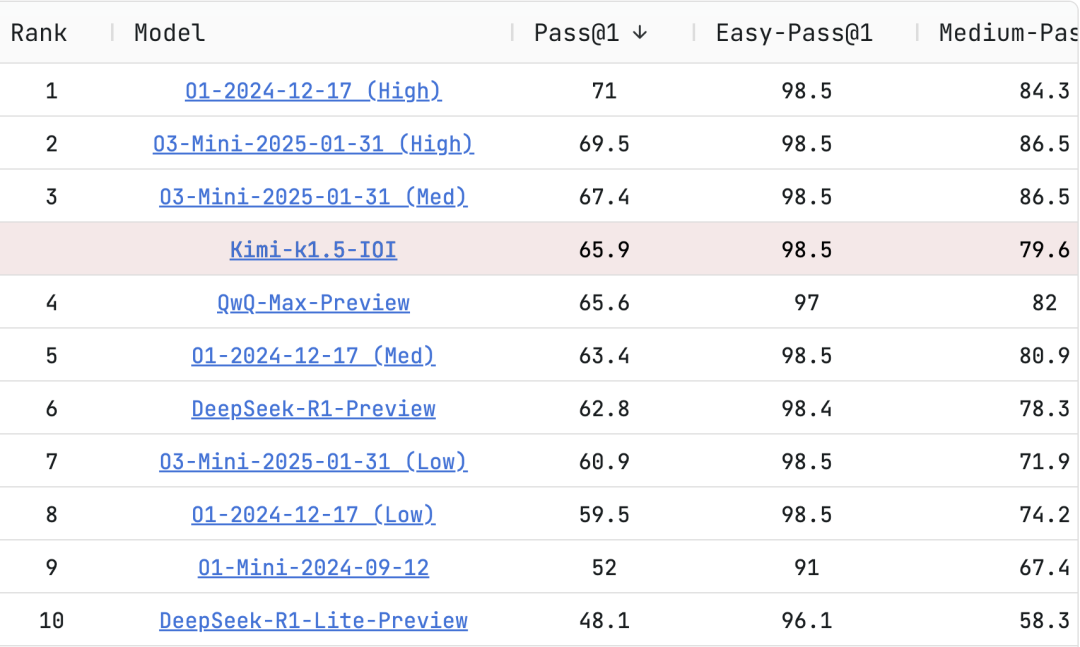
在LiveCodeBench编程测试上,QwQ-Max-Preview 表现比肩 o1-medium ,超越了DeepSeek R1等顶尖模型。
并且通义千问团队还表示后续将推出 QwQ-Max 和 Qwen2.5-Max 的官方 Apache 2.0 许可开源版本。
除此之外,公告还透露将发布Qwen Chat APP和开源更小的推理模型,如qwq-32b,可直接在本地设备部署。
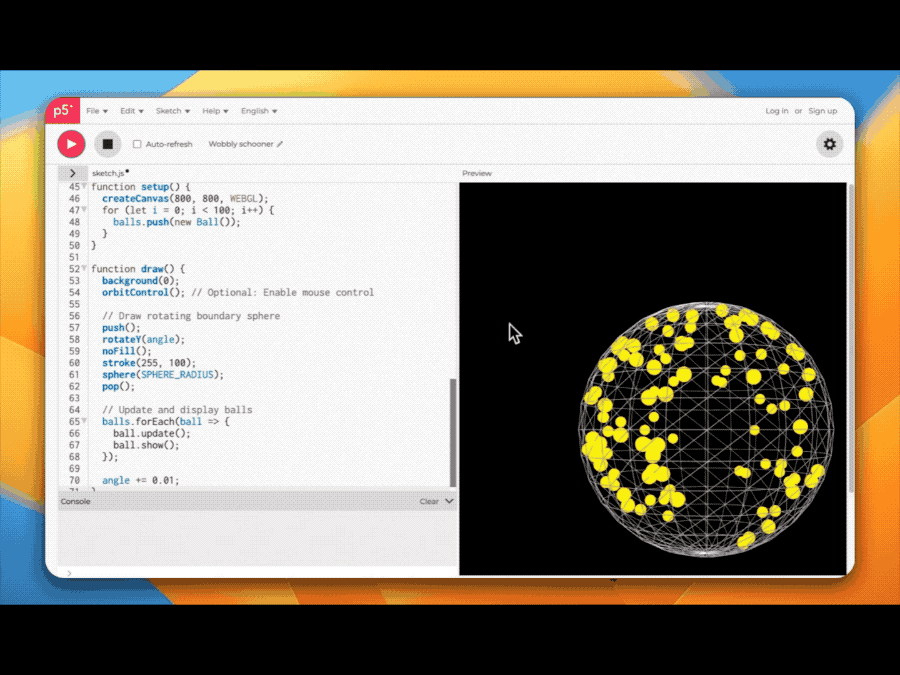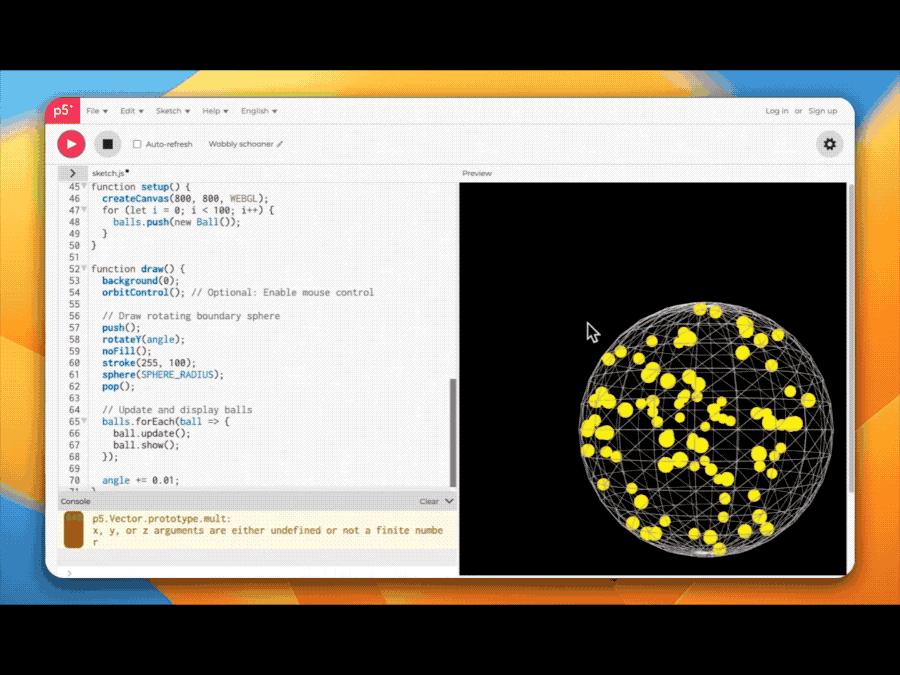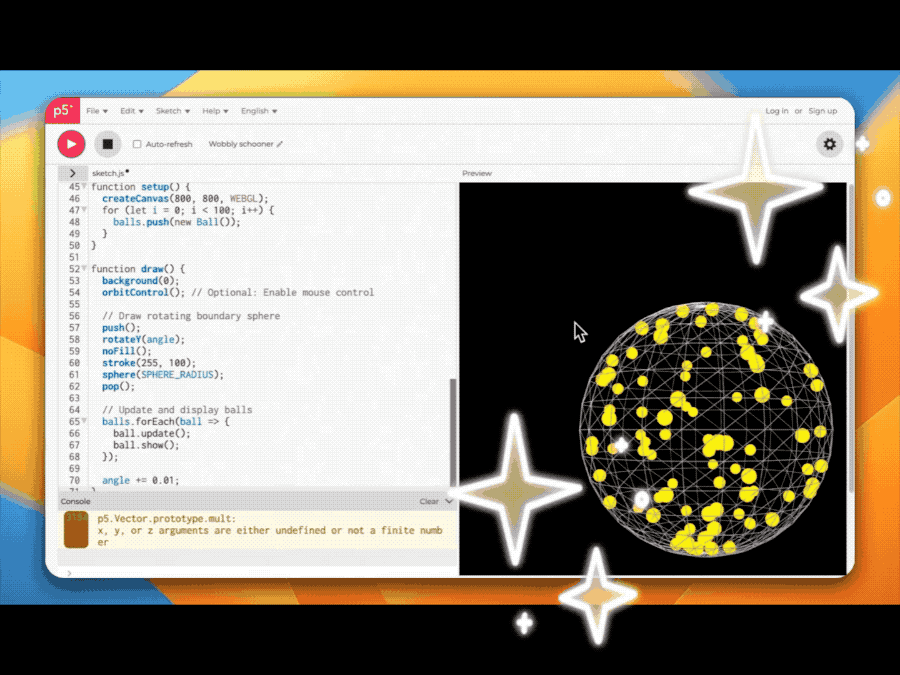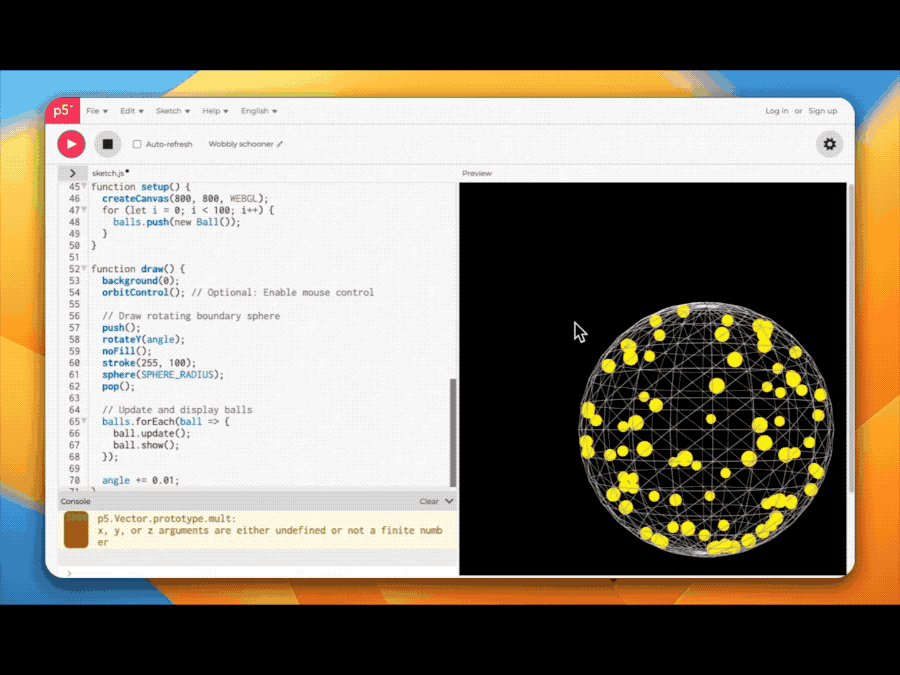
在博客中,通义千问团队放出了多个实测案例,分别展示QwQ-Max-Preview在代码、数学、搜索、Agent、创意写作等方面的能力。
比如QwQ-Max-Preview轻松搞定模拟海量小球运动的代码。
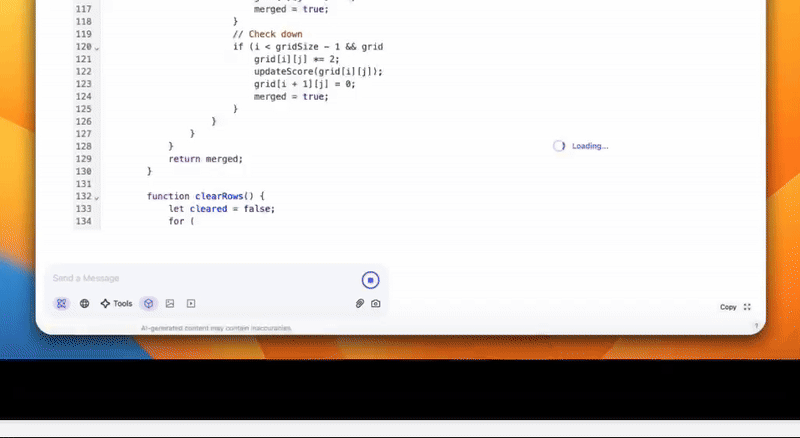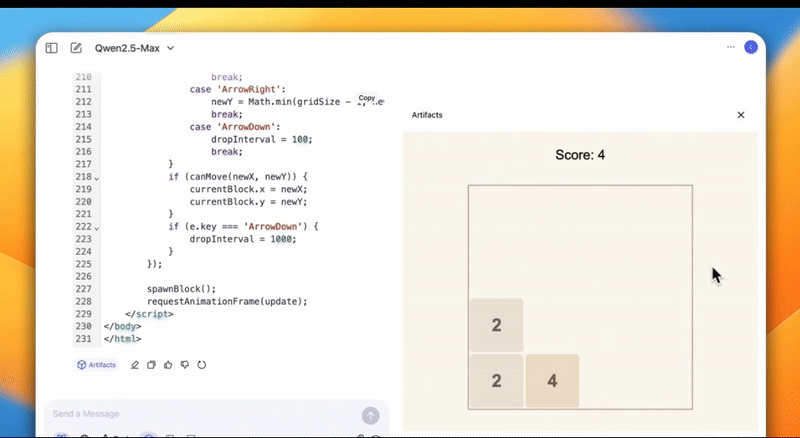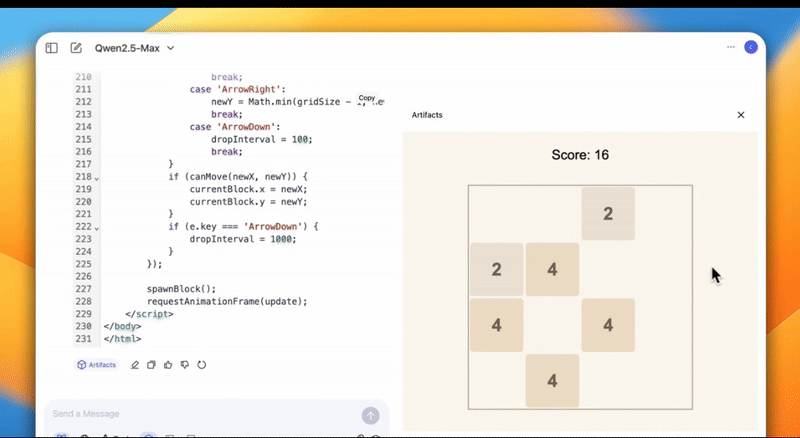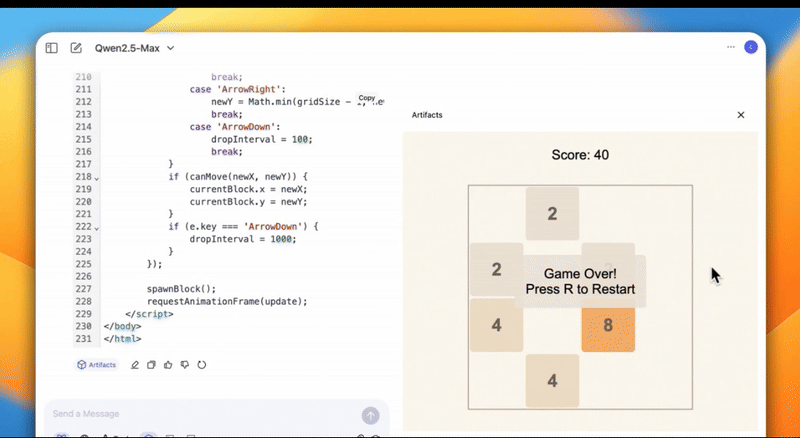
还能开发游戏,把《俄罗斯方块》和《2048》两款游戏整合在一起。
甚至能给淘宝服装店生成一张海报和二维码,二维码实测也可以跳转至淘宝官网。
这样看起来,QwQ-Max-Preview的表现确实牛。
老规矩,接下来,实测一下,看一下QwQ-Max-Preview的推理能力到底有多强。
下面就用QwQ-Max-Preview和o3-mini、混元T1打个PK。
某地有两个奇怪的村庄,张庄的人在星期一、三、五说谎,李村的人在星期二、四、六说谎。在其他日子他们说实话。一天,外地的王从明来到这里,见到两个人,分别向他们提出关于日期的题。两个人都说:“前天是我说谎的日子。”如果被问的两个人分别来自张庄和李村,那么这一天是星期几?
QwQ-Max-Preview
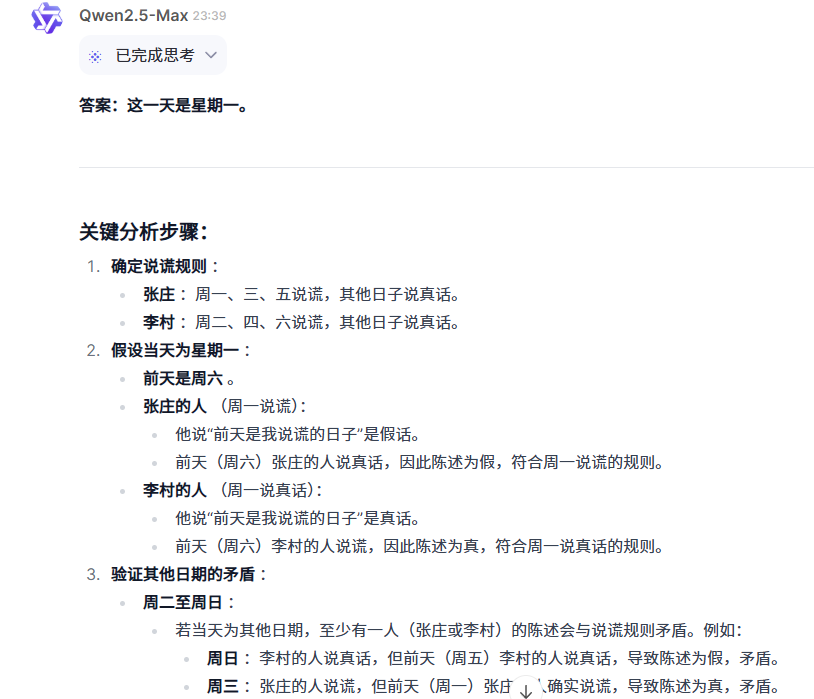
好家伙,只有o3-mini回答错误,QwQ-Max-Preview和混元T1都回答正确,逆推一下发现o3-mini明显回答错误了。
在一个夜晚,同时有4人需要过一桥,一次最多只能通过两个人,且只有一只手电筒,而且每人的速度不同。A、B、C、D需要时间分别为:1,2,5,10分钟。问:在17分钟内这四个人怎么过桥?

全部回答正确,是时候上上难度,来一个挖坑推理题,能不能难住它们。
一根8米长的竹竿是否能通过一个4米高、2米宽的门?

这道挖坑题把混元T1难住了,回答错误,混元T1按照惯性思维计算斜对角的长度,它不理解竹杠是可以穿过去的。
相反,QwQ-Max-Preview和o3-mini没有被坑到,回答正确,目前只剩下QwQ-Max-Preview还保持全对,上上难度。
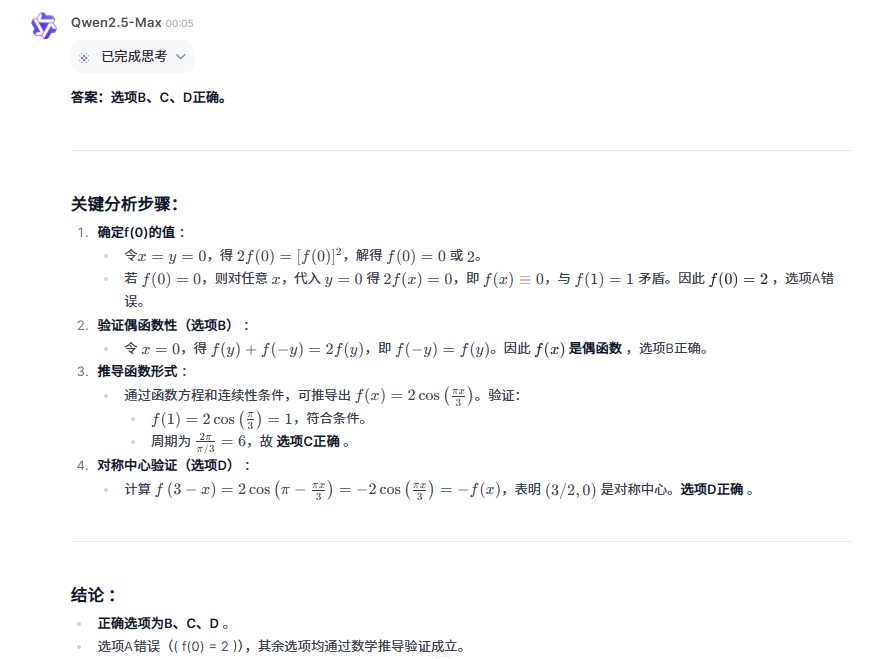
专门挑了选择题的最后一题,在过去,最后一道题往往只有数学老师和数学大神能做出来,看看它们三是否能做出来。
又是只有o3-mini一个人回答错误的名场面出现了…..
整体测试下来,唯一保持全胜记录的只有QwQ-Max-Preview,会发现其推理能力要比o3-mini强得多。
目前QwQ-Max-Preview模型已经上线,大家感兴趣的话,可以试玩一下
此前DeepSeek蒸馏出的6个开源模型中,有4个就是基于Qwen-32B来蒸馏。
还有李飞飞团队用不到50美元的费用,以Qwen2.5-32B-Instruct开源模型为底座,在16块H100 GPU上监督微调26分钟,训练出新模型s1-32B。
据不完全统计,Qwen系列衍生模型总数超过5万个,已经成为仅次于Llama的世界级模型群。
(文:AI先锋官)