

https://weitaikang.github.io/Intent3D-webpage/
论文地址:
https://arxiv.org/abs/2405.18295
项目代码:
https://github.com/WeitaiKang/Intent3D

在现实世界中,AI 能够根据自然语言指令执行目标检测,对人机交互至关重要。过去的研究主要集中在视觉指引(Visual Grounding),即根据人类提供的参照性语言,在 2D 图像或 3D 场景中定位目标物体。
然而,人类在日常生活中寻找目标物品往往是起源于某个特定的意图。例如,一个人可能会说:“我想找个东西靠着,以缓解背部压力”,而不是毫无理由的直接描述“找到椅子”或“找到沙发”。
目前,3D 视觉指引(3D Visual Grounding, 3D-VG)方法依赖用户提供明确的参照信息,如目标的类别、属性或空间关系。但在许多现实场景下,例如人在忙碌或有视觉障碍时,无法提供这样的参照描述。因此,让 AI 能够自动推理用户的意图并检测目标物体,才是更智能、更自然的交互方式。

▲ 图一:我们引入了 3D 意图定位(右),这一新任务旨在根据人类意图句子(例如:“我想要一个能支撑我的背部、缓解压力的物品”),在 3D 场景中通过 3D 边界框检测目标物体。相比之下,现有的 3D 视觉定位(左)依赖于人类的推理和参考来进行检测。该示意图清晰地区分了观察和推理的执行方式:左侧由人类手动完成,右侧则由 AI 自动完成。
如图一所示,相较于传统 3D-VG(左图),我们的 3D-IG 任务(右图)能够让 AI 直接基于用户的意图推理目标,而无需明确的物体描述。
1.2 为什么选择 3D 而非 2D?
近年来,基于意图的推理任务在 2D 视觉领域有所研究,如意图导向的目标检测(Intention-Oriented Object Detection)、隐式指令理解(Implicit Instruction Understanding)等。
然而,这些研究仅限于 2D 视角,无法完整反映现实世界的几何和空间信息。相比之下,3D 数据更加贴近现实世界,不仅包含深度信息,还能提供完整的物体几何、外观特征以及空间上下文。因此,在 3D 场景中进行意图推理,不仅能更准确地模拟真实需求,还能推动智能体(Embodied AI)、自动驾驶、AR/VR 等领域的发展。

为了推动 3D 意图定位研究,我们构建了 Intent3D 数据集,包含 44,990 条意图文本,涉及 209 类物体,基于 1,042 个 ScanNet 点云场景。由于意图表达的多样性,使用预定义格式进行标注会限制模型的泛化能力。
此外,众包标注往往缺乏可靠性,而专业标注成本高且难以扩展。因此,如图二所示,我们采用 GPT-4 生成意图文本,并经人工质量检查,确保高准确性和多样性。
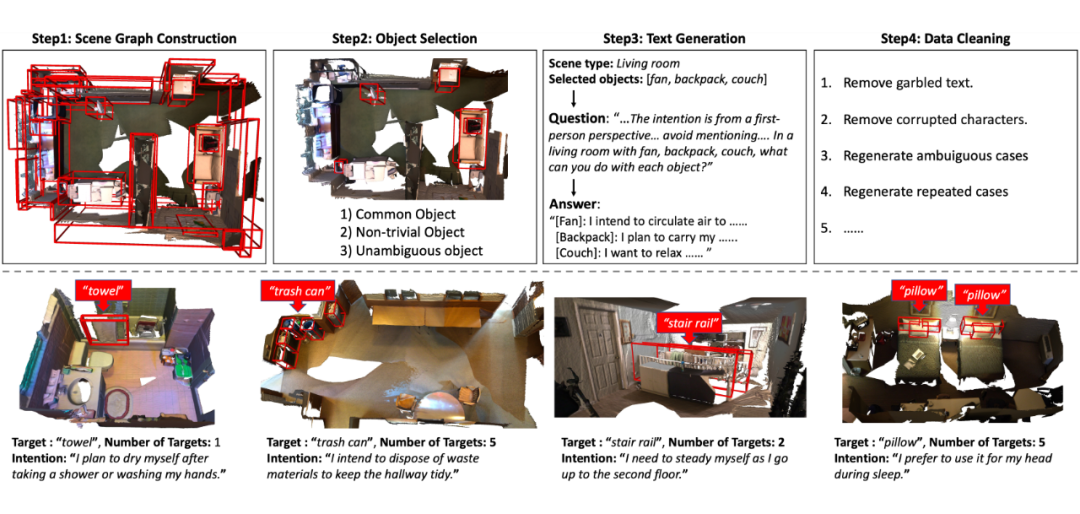
▲ 图二:(上排)数据集构建流程图。构建场景图后,我们根据三个标准选择对象:常见对象、非平凡对象、无歧义对象。我们使用 ChatGPT 根据我们设计的提示生成意图文本。最后,我们手动清理数据。(下排)我们的数据集中针对不同目标数量和文本长度的示例。
其次,为了充分评估我们目前解决这个问题的研究能力,我们使用三种主要的基于语言的 3D 目标检测技术为我们的基准构建了几个基线。
这涉及使用以下模型评估我们的数据集:专门为 3D 视觉定位设计的专家模型(BUTD-DETR, EDA)、为通用 3D 理解任务制定的基础模型(3D-VisTA)以及基于大型语言模型 (LLM) 的模型(Chat-3D-v2)。我们使用多种设置评估这些基线,即从头开始训练、微调和零样本。

方法
3.1 如何解决 3D 意图定位问题?
如图三所示,我们设计了一种新方法 IntentNet,结合多个关键技术:
动宾对齐(Verb-Object Alignment):先识别意图中的动词,再与相应宾语特征进行对齐,提高意图理解能力。
候选框匹配(Candidate Box Matching):在稀疏 3D 点云中显式匹配候选目标框,提高多模态意图推理能力。
级联自适应学习(Cascaded Adaptive Learning):根据不同损失函数的优先级,自适应调整损失函数权重,提升模型性能。
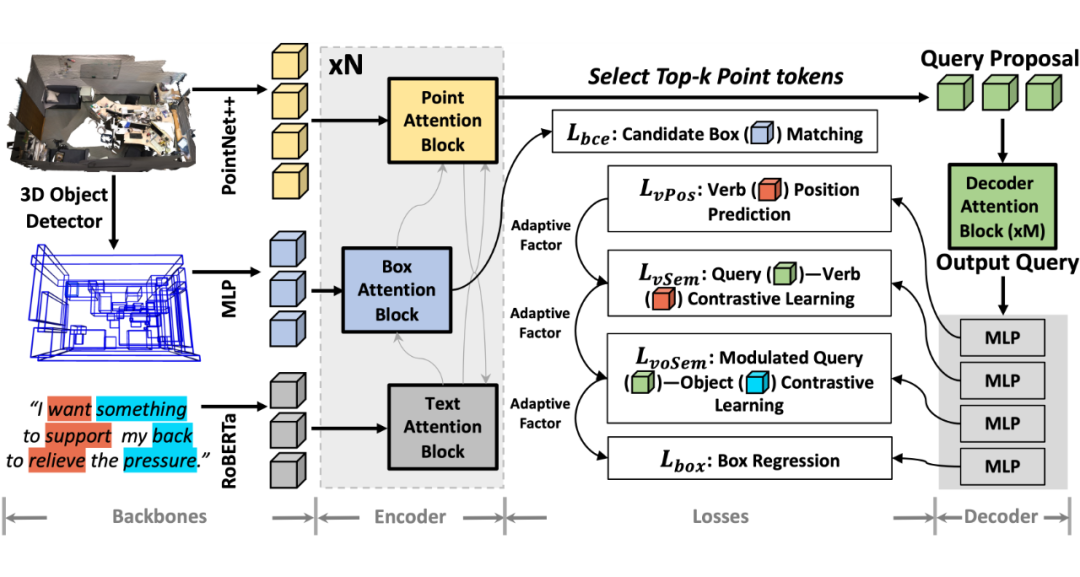
▲ 图三:IntentNet:(骨干网络)PointNet++ 用于提取点特征;MLP 编码 3D 目标检测器预测的框;RoBERTa 编码文本输入。(编码器)基于注意力的块用于多模态融合,通过与文本特征的集成来增强框特征。(解码器)具有最高置信度的前 k 个点特征被选择为提出的查询(query),然后通过基于注意力的块进行更新。几个 MLP 用于线性投影查询,以便进行后续的损失计算。(损失函数)该模型学习使用 L_bce 将候选框与目标对象进行匹配;查询(query)被训练以识别动词(L_vPos),与动词对齐(L_vSem),并与宾语对齐(L_voSem)。

实验
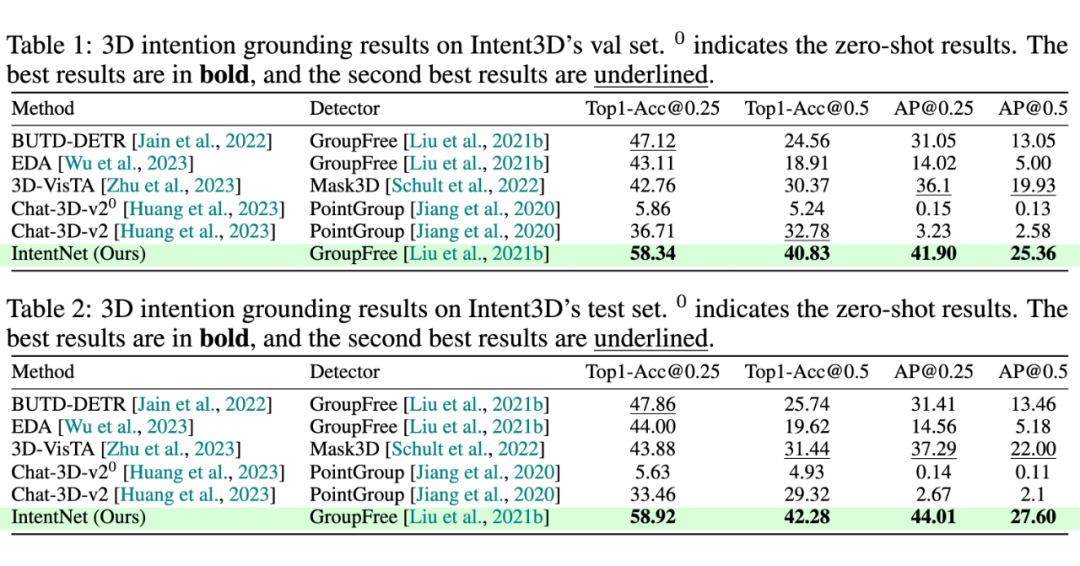
由于对意图语言理解和推理进行了显式建模,我们的 IntentNet 明显优于所有以前的方法。与验证集上的第二佳方法相比,我们在 Top1-Acc@0.25 和 Top1-Acc@0.5 中分别实现了 11.22% 和 8.05% 的改进。此外,我们分别将 AP@0.25 和 AP@0.5 提高了 9.12% 和 5.43%。
同样,在测试集上,我们在 Top1-Acc@0.25 和 Top1-Acc@0.5 中分别获得了 11.06%、10.84% 的改进;在 AP@0.25 和 AP@0.5 中分别获得了 6.72%、5.6% 的改进。
(文:PaperWeekly)

