新智元报道
新智元报道
【新智元导读】DeepSeek开源第四天,连更三个项目。DualPipe、EPLB、以及计算与通信重叠机制的优化并行策略,让大模型训练更快,成本更低,还能保持顶尖性能。
-
DualPipe:一种用于V3/R1模型训练中实现计算与通信重叠的双向流水线并行算法 -
EPLB:一个针对V3/R1的专家并行负载均衡工具 -
深入分析V3/R1模型中的计算与通信重叠机制



DualPipe
调度方案

流水线气泡与内存使用比较

快速入门
python example.py注意:在实际生产环境中,需要根据模块特点来实现一个定制化的overlapped_forward_backward方法。 专家并行负载均衡器(EPLB)
在使用专家并行(EP)时,不同的专家模块会被分配到不同的GPU上。由于各个专家的计算负载会随当前任务而变化,因此保持各GPU间负载均衡至关重要。 如DeepSeek-V3论文所述,研究人员采用了冗余专家(redundant experts)策略,对高负载专家进行复制。 随后,通过启发式算法将这些复制的专家合理分配到各GPU上,确保计算资源的平衡利用。 此外,由于DeepSeek-V3采用了组内限制专家路由(group-limited expert routing)机制,研究团队尽可能将同一组的专家放置在同一节点上,以减少节点间的数据传输开销。 为了便于复现和部署,DeepSeek在eplb.py文件中开源了EP负载均衡算法。该算法能够根据估计的专家负载,计算出均衡的专家复制和放置方案。 需要说明的是,专家负载的具体预测方法不在此代码库的讨论范围内,一种常用的方法是采用历史统计数据的滑动平均值。 算法原理
负载均衡算法提供了两种策略,适用于不同场景: · 层次负载均衡(Hierarchical Load Balancing) 当服务器节点数量能够整除专家组数量时,研究人员采用层次负载均衡策略,来充分利用组内限制专家路由机制。 首先,他们将专家组均匀分配到各节点,确保节点间负载平衡;然后,在每个节点内部复制专家模型;最后,将复制后的专家打包分配到各个GPU上,实现GPU间的负载均衡。 这种层次化策略特别适用于预填充阶段(prefilling stage),此时专家并行规模较小。 · 全局负载均衡(Global Load Balancing) 在其他情况下,研究人员采用全局负载均衡策略,不考虑专家组的限制,直接在全局范围内复制专家并分配到各个GPU上。这种策略更适合解码阶段使用,此时专家并行规模较大。 接口示例
负载均衡器的核心函数是eplb.rebalance_experts。 下面的代码展示了一个双层混合专家模型(MoE)的示例,每层包含12个专家。 DeepSeek为每层引入了4个冗余专家,总计16个专家副本被分配到2个计算节点上,每个节点配有4个GPU。 import torchimport eplbweight = torch.tensor([[ 90, 132, 40, 61, 104, 165, 39, 4, 73, 56, 183, 86],[ 20, 107, 104, 64, 19, 197, 187, 157, 172, 86, 16, 27]])num_replicas = 16num_groups = 4num_nodes = 2num_gpus = 8phy2log, log2phy, logcnt = eplb.rebalance_experts(weight, num_replicas, num_groups, num_nodes, num_gpus)print(phy2log)# Output:# tensor([[ 5, 6, 5, 7, 8, 4, 3, 4, 10, 9, 10, 2, 0, 1, 11, 1],# [ 7, 10, 6, 8, 6, 11, 8, 9, 2, 4, 5, 1, 5, 0, 3, 1]])该层次负载均衡策略产生的结果,展示了如下专家复制与分配方案。 DeepSeek基础设施中的性能剖析数据
在这里,DeepSeek公开分享来自训练和推理框架的性能剖析数据,旨在帮助社区更深入地理解通信与计算重叠策略以及相关底层实现细节。 这些剖析数据是通过PyTorch Profiler工具获取的。 你可以下载后在Chrome浏览器中访问chrome://tracing(或在Edge浏览器中访问edge://tracing)直接进行可视化查看。 需要说明的是,为了便于剖析,研究人员模拟了一个完全均衡的MoE路由策略。 训练过程
训练剖析数据展示了,研究人员在DualPipe中如何实现单对前向和后向计算块的重叠策略。每个计算块包含4个MoE层。 并行配置与DeepSeek-V3预训练设置保持一致:采用EP64、TP1,序列长度为4K。 为简化剖析过程,未包含流水线并行(PP)通信部分。 推理过程
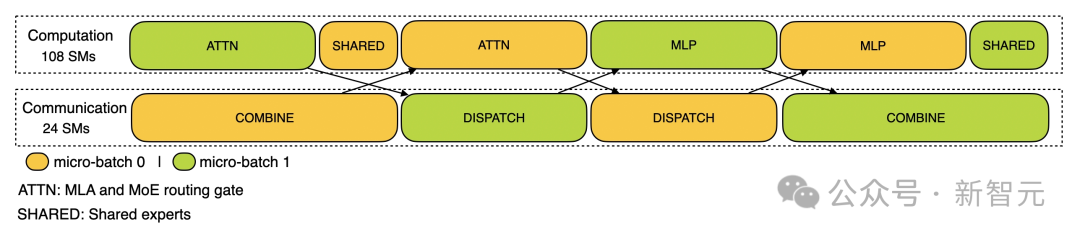
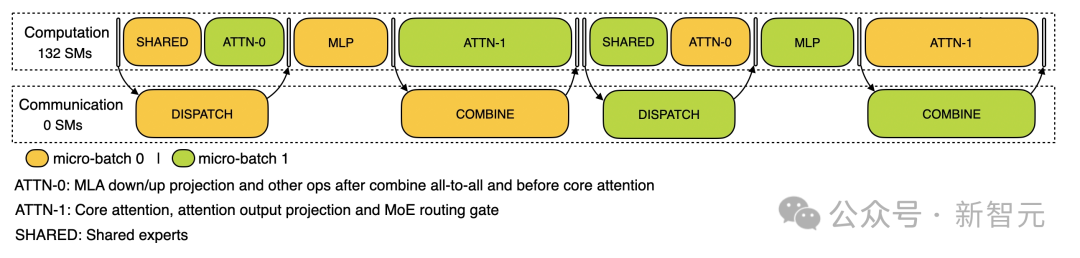
· 预填充 在预填充阶段,剖析配置采用EP32和TP1的配置(与DeepSeek V3/R1实际在线部署一致),提示长度设为4K,每GPU批处理量为16K个token。 研究人员在预填充阶段使用两个micro-batches来实现计算与all-to-all通信的重叠,同时确保注意力机制的计算负载在两个micro-batches间保持平衡——这意味着同一条提示信息可能会被分割到不同micro-batches中处理。 · 解码 解码阶段的剖析配置采用EP128、TP1,提示长度4K(与实际在线部署配置非常接近),每GPU批处理量为128个请求。 与预填充类似,解码阶段也利用两个micro-batches来重叠计算和all-to-all通信。 然而不同的是,解码过程中的全联通通信不占用GPU流处理器(SM):RDMA消息发出后,所有GPU流处理器立即被释放,系统在完成计算后等待全联通通信完成。 关于all-to-all通信实现的更多技术细节,请参考DeepEP文档。 (文:新智元)