

AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
-
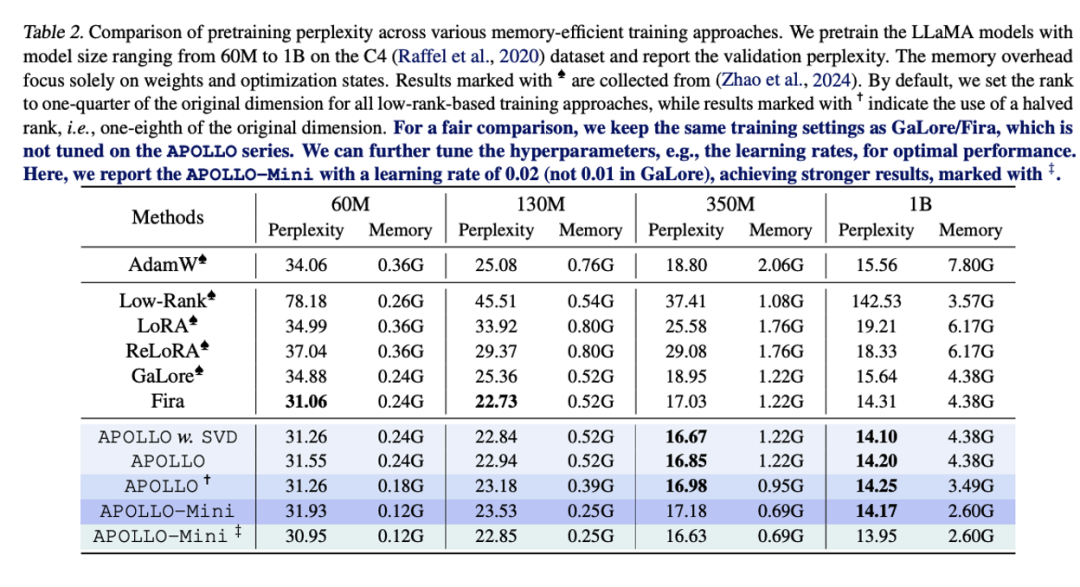
极低内存消耗:首次以类 SGD 内存成本完成大模型训练,达到甚至超越 AdamW 的性能。 -
无需 SVD 计算:首次实现仅需轻量级随机投影进行大模型预训练,甚至在 7B 模型上优化速度超越 Adam。
-
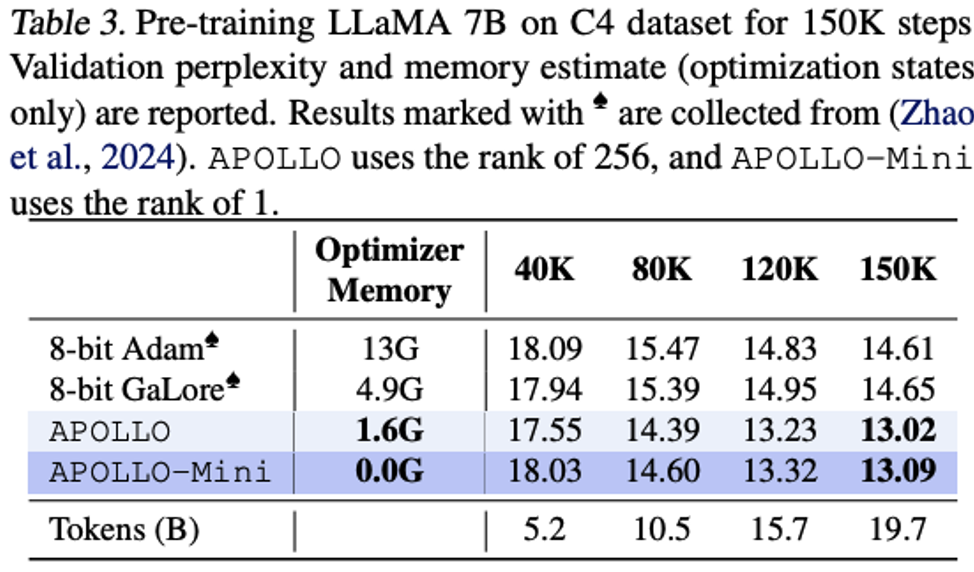
3 倍预训练加速:在 8 块 A100 GPU 上,APOLLO 预训练 LLaMA 7B 模型实现了 3 倍的加速。 -
突破规模限制:首次利用 DDP 成功训练 13B 模型,并在 12GB 内存的消费级 GPU(如 NVIDIA RTX 4090)上完成 7B 模型的预训练,无需依赖模型并行、检查点或卸载策略。


-
论文地址:https://arxiv.org/pdf/2412.05270 -
论文网站:https://zhuhanqing.github.io/APOLLO/ -
论文代码: https://github.com/zhuhanqing/APOLLO
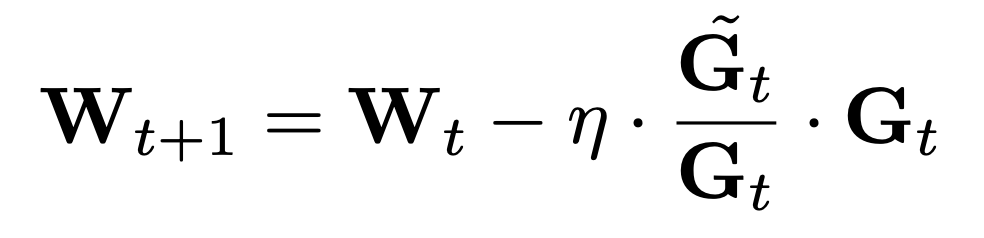
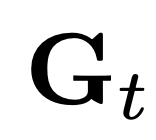 施加一个基于梯度动量和方差的梯度缩放因子
施加一个基于梯度动量和方差的梯度缩放因子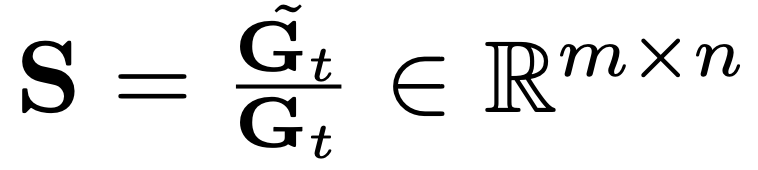 ,进一步发现这一缩放因子可以通过结构化更新(例如按通道或张量进行缩放)来近似实现。
,进一步发现这一缩放因子可以通过结构化更新(例如按通道或张量进行缩放)来近似实现。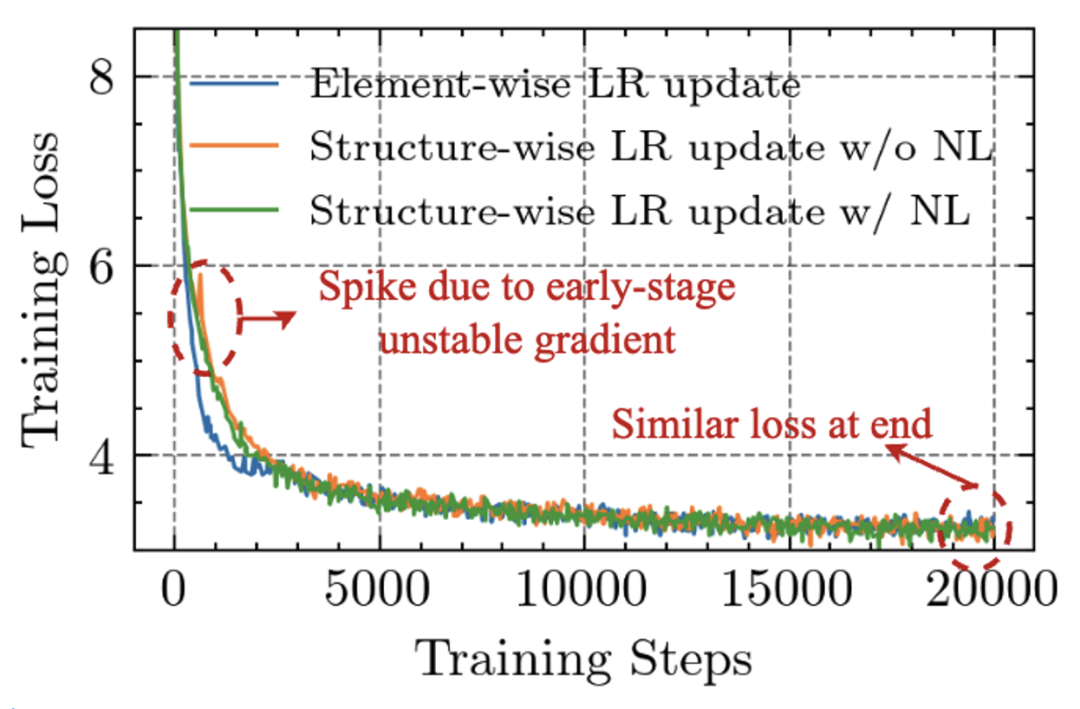
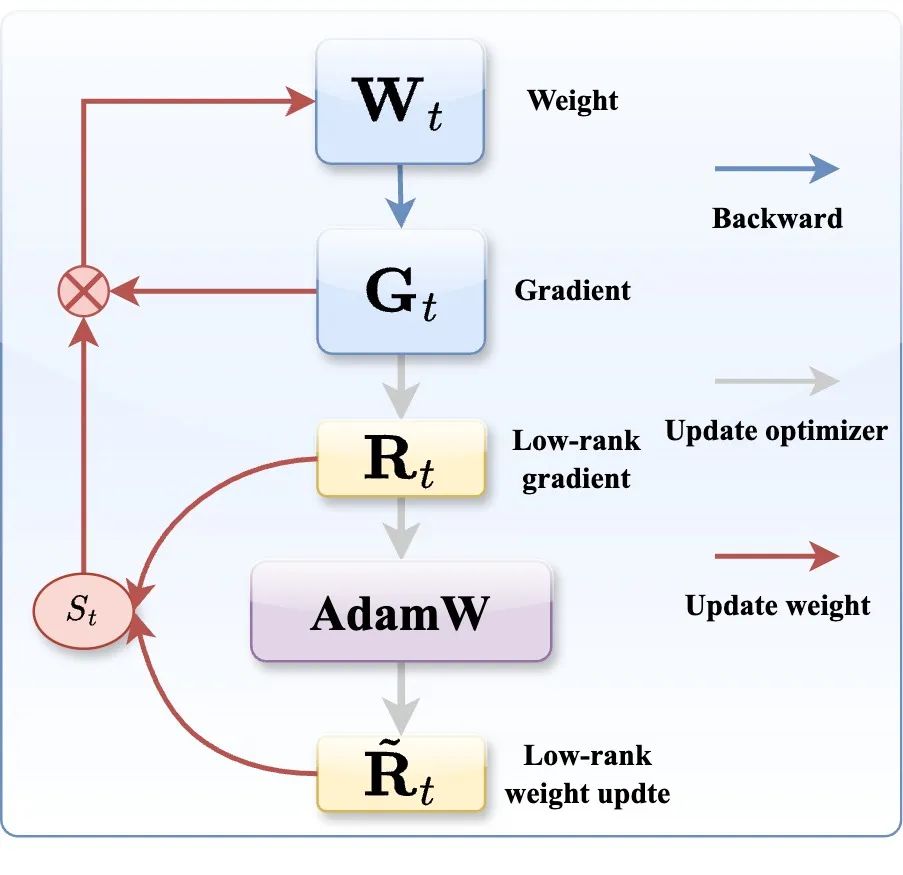 图 2: APOLLO 框架
图 2: APOLLO 框架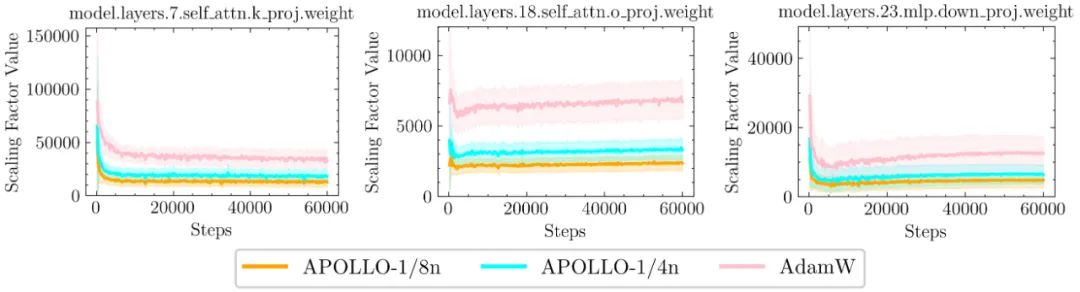

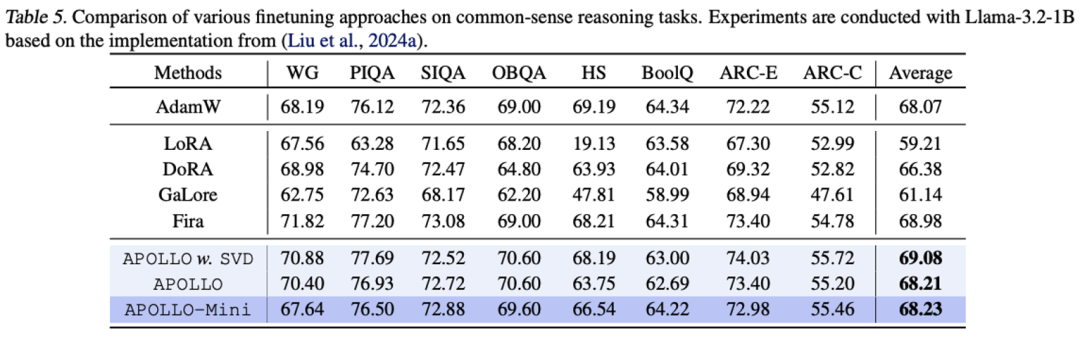
-
加速训练
-
极低内存消耗
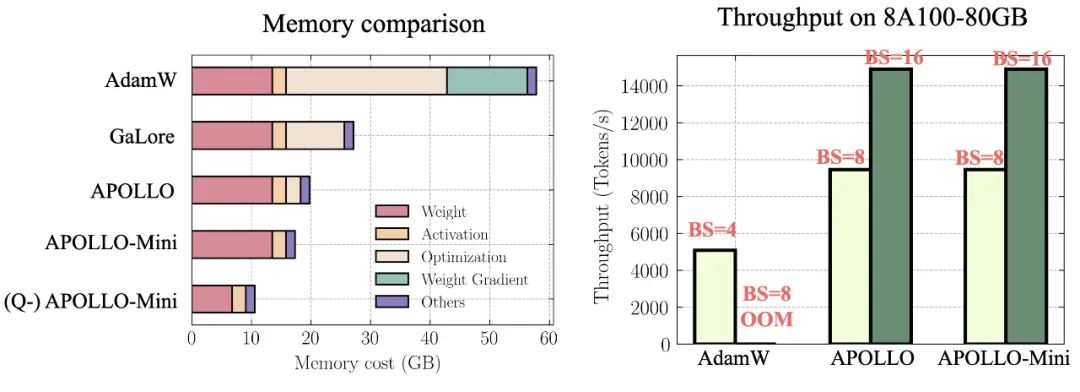
-
极低的计算开销
(文:机器之心)