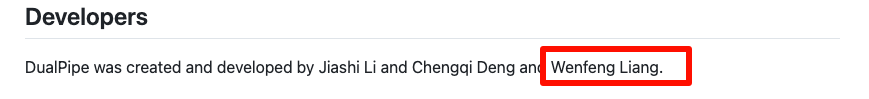跳至内容
团队在 OpenSourceWeek 的第四天,DeepSeek 大招如约而至,开源了两项堪称「AI 训练加速神器」的技术,其中还有梁文锋亲自参与的项目。这对于动辄需要数百万美元、耗时数月的大模型训练来说是一剂「强心针」,体现在:
减少管道泡沫:它通过高效调度前向和后向传递,减少训练过程中的空闲时间。
重叠计算与通信:DualPipe 让计算和通信同时进行,从而隐藏通信延迟,降低训练时间。
优化硬件利用率:它可能利用 GPU 的部分核心处理通信任务,相当于在 GPU 内创建一个虚拟数据处理单元(DPU),这在分布式训练中尤为重要。
那么,这三大神器到底是什么?它们又是如何让 AI 训练变得如此高效?
DeepSeek 开源周,APPSO 将持续带来最新动态和解读,往期回顾👇
Day1 :一文看懂 DeepSeek 刚刚开源的 FlashMLA,这些细节值得注意
Day2 :榨干每一块 GPU!DeepSeek 开源第二天,送上降本增效神器
Day3:一文看懂 DeepSeek 开源项目第三弹,300 行代码揭示 V3/R1 推理效率背后的关键
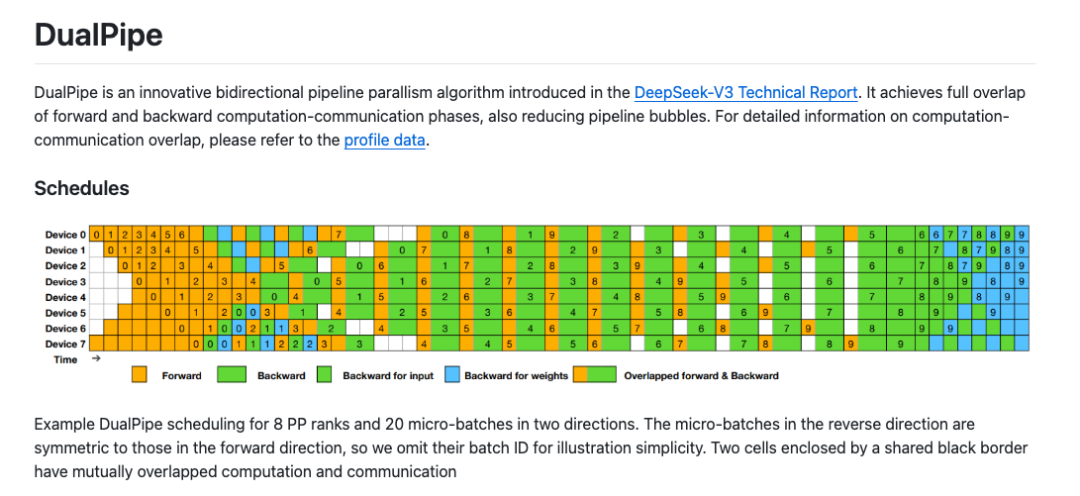
传统的 AI 训练就像一条单行道,数据必须先完成前向计算(从北到南),然后等待完全结束后,才能开始反向传播(从南到北)。这就像一条单向铁路,列车必须等前一班车完全到站卸货后,才能发车,效率低得令人发指。
如果这时候有一条双向高铁线,南北方向的列车可以同时行驶。更厉害的是,乘客不用等到站,在列车行驶途中就开始处理工作。这就是 DualPipe 的核心思想——让前向计算和反向传播同时进行,并且在数据传输的同时就开始下一步计算。
这就像麦当劳的双车道得来速:一边有车辆取餐离开,另一边同时有新车进入点单。而且厨师看到你的车牌就开始做餐,等你开到窗口,餐也刚好能取,整个过程无需停车等待,完全无缝衔接。
DualPipe 的这些提升在 DeepSeek-V3 的训练中发挥了关键作用。根据技术报告,DeepSeek-V3 的预训练仅需 278.8 万 H800 GPU 小时,成本约为 557.6 万美元。这一成本远低于同规模模型的预期,部分归功于 DualPipe 的高效性。例如,与 OpenAI 的 GPT-4o 或 Anthropic 的 Claude 3.5 Sonnet 相比,DeepSeek-V3 在代码、数学和多语言任务上表现出色,而训练资源却少了很多。
值得注意的是,梁文锋本人也参与了 DualPipe 的开发,真·大佬亲自下场。
在大模型训练中,尤其是 MoE(混合专家模型)架构中,存在一个让工程师头疼的问题:资源分配极不均衡。
想象一下,有 100 个「专家」(计算单元)在工作,但 80%的任务都挤到了 20 个专家那里,导致这 20 个专家忙得焦头烂额,而其他 80 个专家却闲得发慌。这种情况在 AI 训练中太常见了,严重浪费计算资源。
DeepSeek 如何解决这个问题?EPLB(Expert Parallel Load Balancing)是用于优化大型语言模型在专家并行(Expert Parallelism, EP)架构中的训练效率。它通过动态调整专家(MoE 模型中的子网络)的分配来平衡 GPU 之间的工作负载,同时减少跨节点通信开销。
这就像春节火车票系统,系统实时监控哪些列车爆满,哪些有空位,然后动态调整,把乘客分流到不同车次,确保每趟车都坐满但不超载。没有白跑的空车,也没有挤不上的乘客。
这几天公开分享出来的训练和推理框架,所涉及到性能分析数据也进一步披露了,开发者们能更好地理解通信-计算重叠策略和低级实现细节。性能分析数据是使用 PyTorch Profiler 捕获的,可以通过 Chrome 插件直接对其进行可视化,也可以当作一种性能检测的方式。
1. 速度翻倍 – DualPipe 让数据像高铁一样双向同时流动,还能「车上办公」,训练速度提升 30%。
2. 资源不浪费 – EPLB 像春运指挥中心,确保每台计算机都忙得恰到好处,资源利用率提升 20%以上。
这次的开源也是同样普大喜奔的一天,评论区的欢呼从不迟到:

我们正在招募伙伴
✉️ 邮件标题
「姓名+岗位名称」(请随简历附上项目/作品或相关链接)

(文:APPSO)