


AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com

-
论文标题:Context-Alignment: Activating and Enhancing LLMs Capabilities in Time Series -
论文链接:https://openreview.net/forum?id=syC2764fPc -
代码链接:https://github.com/tokaka22/ICLR25-FSCA
-
细粒度图结构将每个 token 视为一个节点,强调 token 之间的相互独立性,保留时序的具体信息。通过两个线性层(如图 1 中所示的
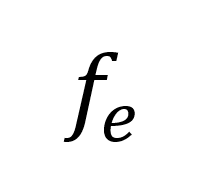 和
和 ),将连续且冗长的时序数据嵌入和 prompt 嵌入分别映射为两种粗粒度节点。
),将连续且冗长的时序数据嵌入和 prompt 嵌入分别映射为两种粗粒度节点。 -
粗粒度图结构将连续的、模态一致的 tokens 映射为一个节点,表示了模态的整体性。
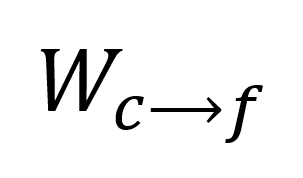 和分配矩阵计算,参考原文公式 4),使粗粒度节点能够向细粒度节点传递更新后的信息,细粒度节点在完成自己的更新后整合来自粗粒度节点的信息。最后,粗粒度节点和细粒度节点嵌入将分别输入预训练的大语言模型。
和分配矩阵计算,参考原文公式 4),使粗粒度节点能够向细粒度节点传递更新后的信息,细粒度节点在完成自己的更新后整合来自粗粒度节点的信息。最后,粗粒度节点和细粒度节点嵌入将分别输入预训练的大语言模型。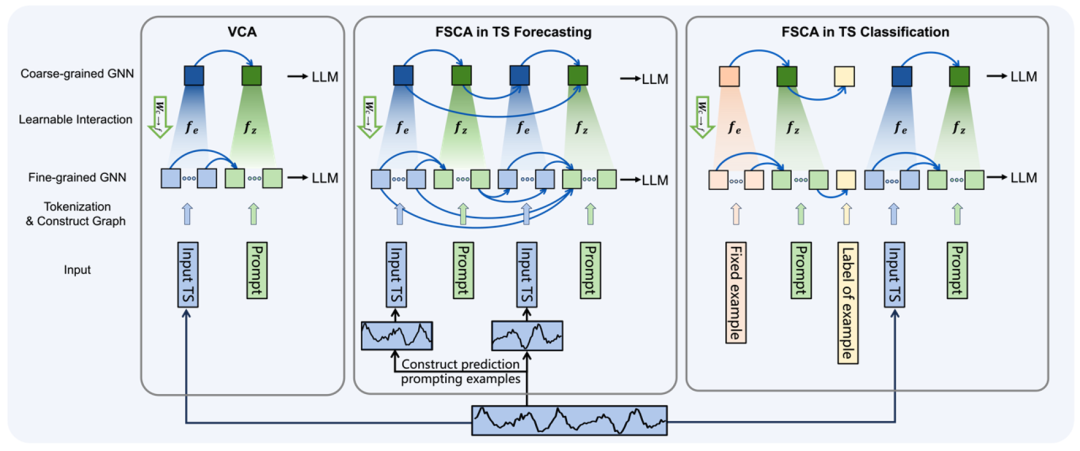 图 1 双尺度语境对齐图结构
图 1 双尺度语境对齐图结构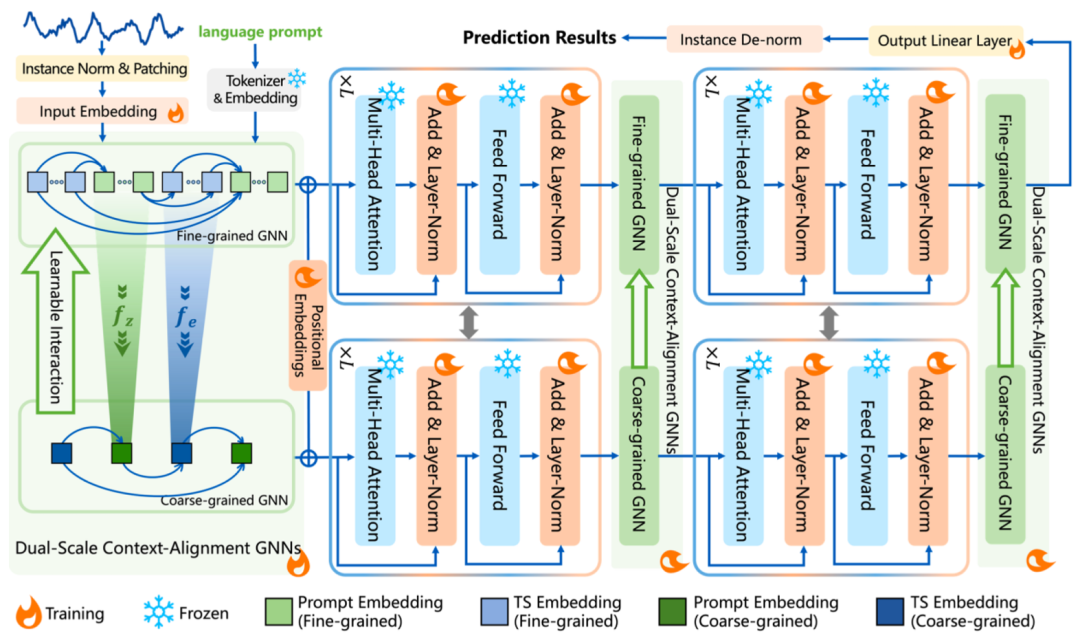



(文:机器之心)