
大型语言模型的训练数据暴露安全隐患!

Truffle Security公司最近曝出一个重磅发现:他们扫描了400TB的DeepSeek训练数据,发现了约12000个活跃的API密钥和密码!

这些密钥分布在276万个网页上,其中一个密钥竟然在不同页面上出现了超过57000次!

但这个发现立即引发了争议。
有人质疑这是在对中国AI企业DeepSeek进行有针对性的攻击,而实际上问题可能存在于几乎所有使用Common Crawl数据的大模型中。
Teortaxes直接点出了问题所在:
研究报告标题说「扫描DeepSeek的训练数据」,但正文却改口为「扫描Common Crawl——一个被DeepSeek等大模型用于训练的海量数据集」。
这种表述上的微妙变化引发了不少争议。
有人认为这是西方对中国AI公司的选择性针对,毕竟OpenAI等美国公司也大量使用了Common Crawl数据。
Teortaxes 继续指出:
他们选择攻击鲸鱼(DeepSeek的标志)而不是GPT-4.5,尽管明显DeepSeek和OpenAI都使用了Common Crawl数据。
究竟发现了什么?
Truffle Security在博客中详细介绍了他们的发现:
-
11908个活跃密钥被检测到,分布在400TB的网络数据中
-
276万个网页包含活跃密钥
-
密钥高度重复:63%的密钥在多个网页上重复出现
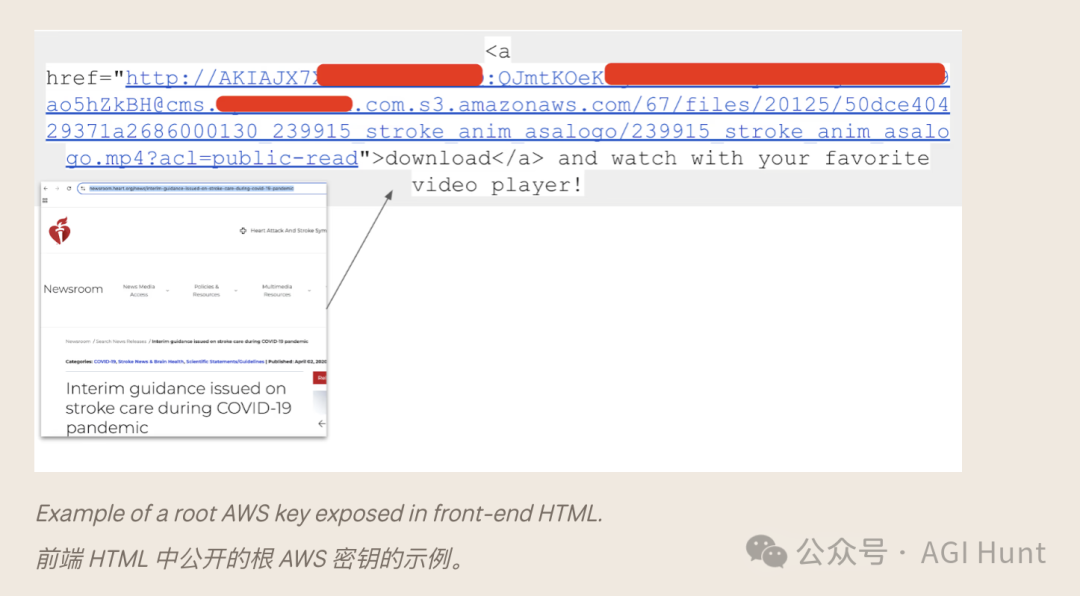
更令人担忧的是,这些密钥种类多达219种不同类型,包括AWS根密钥、Slack网络钩子等敏感凭证。

研究团队发现了一些令人瞠目的案例:
-
一个网页上同时硬编码了17个不同的Slack网络钩子
-
近1500个独特的Mailchimp API密钥被硬编码在前端HTML和JavaScript中
-
一些软件开发公司在多个客户网站上使用相同的API密钥,这让人轻易就能识别出他们的客户名单
该研究揭示了一个的问题:大语言模型可能在无意中学习并复制不安全的编码实践。
上个月,Truffle Security 已经发表文章指出大语言模型正在教开发者硬编码API密钥。而这次研究则找到了可能的根源:训练数据本身就包含大量硬编码的密钥。

虽然LLM的输出受多种因素影响,但训练数据中充斥着数百万包含硬编码密钥的代码示例,无疑会对模型生成安全代码的能力产生负面影响。
研究人员特别指出,这些问题不应归咎于Common Crawl组织。Common Crawl的目标是提供一个免费、公开的数据集,而不是筛选其中的敏感信息。

真正的问题在于开发者在公开网页的前端代码中硬编码密钥的做法。
研究人员面临的最大挑战是:如何联系约12000个不同网站的所有者,向他们解释什么是密钥泄露,并说服他们更新受影响的密钥?
最终,研究团队选择了联系那些用户受影响最大的供应商,与他们合作撤销用户的密钥。

这一策略成功帮助相关组织集体轮换/撤销了数千个密钥。
研究人员建议开发者和企业可以采取以下措施:
-
在VS Code或Cursor中使用Copilot Instructions或Cursor Rules为LLM消息提供安全指导
-
扩大密钥扫描范围,包括公共网页和存档数据集
而对于整个行业来说,大语言模型可能需要通过改进对齐和额外的安全措施(如Constitutional AI技术)来降低无意中复制或暴露敏感信息的风险。

好了不说了,我要去找 DeepSeek 套密钥去了。
(文:AGI Hunt)