

机器之心报道


-
文章标题:Reward Hacking in Reinforcement Learning -
文章链接:https://lilianweng.github.io/posts/2024-11-28-reward-hacking/ -
翁荔博客:https://lilianweng.github.io/

 想要获得一个变换后的 MDP,
想要获得一个变换后的 MDP,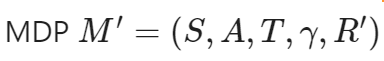 其中
其中  这样我们就可以引导学习算法更加高效。给定一个实值函数
这样我们就可以引导学习算法更加高效。给定一个实值函数 F 是基于潜力的塑造函数,如果对于所有
F 是基于潜力的塑造函数,如果对于所有

 最终结果为 0。如果 F 是这样一个基于势的塑造函数,它既充分又必要,以确保 M 和 M’ 共享相同的最优策略。
最终结果为 0。如果 F 是这样一个基于势的塑造函数,它既充分又必要,以确保 M 和 M’ 共享相同的最优策略。
 其中 S_0 处于吸收状态,并且
其中 S_0 处于吸收状态,并且 



-
Reward hacking (Amodei et al., 2016)
-
Reward corruption (Everitt et al., 2017)
-
Reward tampering (Everitt et al. 2019)
-
Specification gaming (Krakovna et al., 2020)
-
Objective robustness (Koch et al. 2021)
-
Goal misgeneralization (Langosco et al. 2022)
-
Reward misspecifications (Pan et al. 2022)
-
即使目标正确,模型也无法有效泛化。当算法缺乏足够的智能或能力时,就会发生这种情况。 -
该模型具有很好的泛化能力,但追求的目标与训练时的目标不同。当智能体奖励与真实奖励函数不同时,就会发生这种情况。这被称为目标鲁棒性(Koch et al. 2021)或目标错误泛化(Koch et al. 2021)。

-
环境或目标指定错误:模型通过入侵环境或优化与真实奖励目标不一致的奖励函数来学习不良行为,以获得高额奖励 —— 例如当奖励指定错误或缺乏关键要求时。 -
奖励篡改:模型学习干扰奖励机制本身。
-
训练抓取物体的机械手可以学会如何通过将手放在物体和相机之间来欺骗人:https://openai.com/index/learning-from-human-preferences/ -
训练最大化跳跃高度的智能体可能会利用物理模拟器中的错误来实现不切实际的高度:https://arxiv.org/abs/1803.03453 -
智能体被训练骑自行车到达目标,并在接近目标时获得奖励。然后,智能体可能会学习在目标周围绕小圈骑行,因为远离目标时不会受到惩罚:https://people.eecs.berkeley.edu/~pabbeel/cs287-fa09/readings/NgHaradaRussell-shaping-ICML1999.pdf -
在足球比赛中,当智能体触球时会分配奖励,于是它会学习保持在球旁边以高频触球:https://people.eecs.berkeley.edu/~pabbeel/cs287-fa09/readings/NgHaradaRussell-shaping-ICML1999.pdf -
在 Coast Runners 游戏中,智能体控制一艘船,目标是尽快完成赛艇比赛。当它在赛道上击中绿色方块时获得塑造奖励时,它会将最佳策略更改为绕圈骑行并一遍又一遍地击中相同的绿色方块:https://deepmind.google/discover/blog/specification-gaming-the-flip-side-of-ai-ingenuity/ -
「The Surprising Creativity of Digital Evolution」(Lehman et al. 2019)—— 本文有许多关于如何优化错误指定的适应度函数可能导致令人惊讶的「hacking」或意想不到的进化或学习结果的例子:https://arxiv.org/abs/1803.03453 -
人工智能示例中的规范游戏列表,由 Krakovna et al.于 2020 年收集:https://deepmind.google/discover/blog/specification-gaming-the-flip-side-of-ai-ingenuity/
-
用于生成摘要的语言模型能够探索 ROUGE 指标中的缺陷,从而获得高分,但生成的摘要几乎不可读:https://web.archive.org/web/20180215132021/https://www.salesforce.com/products/einstein/ai-research/tl-dr-reinforced-model-abstractive-summarization/ -
编码模型学习更改单元测试以通过编码问题:https://arxiv.org/abs/2406.10162 -
编码模型可以学习直接修改用于计算奖励的代码:https://arxiv.org/abs/2406.10162
-
社交媒体的推荐算法旨在提供有用的信息。然而,有用性通常通过代理指标来衡量,例如点赞或评论的数量,或平台上的参与时间或频率。该算法最终会推荐可能影响用户情绪状态的内容,例如离谱和极端的内容,以触发更多参与度:https://www.goodreads.com/en/book/show/204927599-nexus -
针对视频共享网站的错误指定代理指标进行优化可能会大幅增加用户的观看时间,而真正的目标是优化用户的主观幸福感:https://arxiv.org/abs/2201.03544 -
「大空头」——2008 年由房地产泡沫引发的金融危机。当人们试图玩弄金融体系时,我们社会的 Reward Hacking 攻击就发生了:https://en.wikipedia.org/wiki/The_Big_Short
-
回归 – 对不完美智能体的选择也必然会选择噪声。 -
极值 – 度量选择将状态分布推入不同数据分布的区域。 -
因果 – 当智能体和目标之间存在非因果相关性时,干预它可能无法干预目标。 -
对抗 – 智能体的优化激励对手将他们的目标与智能体相关联。
-
部分观察到的状态和目标不能完美地表示环境状态。 -
系统本身很复杂,容易受到 hacking;例如,如果允许智能体执行更改部分环境的代码,则利用环境机制会变得容易得多。 -
奖励可能涉及难以学习或描述的抽象概念。例如,具有高维输入的奖励函数可能不成比例地依赖于几个维度。 -
RL 的目标是使奖励函数高度优化,因此存在内在的「冲突」,使得设计良好的 RL 目标具有挑战性。一种特殊情况是具有自我强化反馈组件的奖励函数,其中奖励可能会被放大和扭曲到破坏原始意图的程度,例如广告投放算法导致赢家获得所有。
-
表征 – 一组奖励函数在某些算术运算(例如重新扩展)下在行为上不变 -
实验 -π‘ 观察到的行为不足以区分两个或多个奖励函数,这些奖励函数都合理化了智能体的行为(行为在两者下都是最佳的)
-
模型大小:模型更大,代理奖励也会增大,但真实奖励会降低。 -
动作空间分辨率:如果提升动作的精度,智能体的能力也会变强。但是,分辨率更高会导致代理奖励不变的同时真实奖励下降。 -
观察保真度:更准确的观察会提高代理奖励,但会略微降低真实奖励。 -
训练步数:在奖励呈正相关的初始阶段之后,用更多步数优化代理奖励会损害真实奖励。

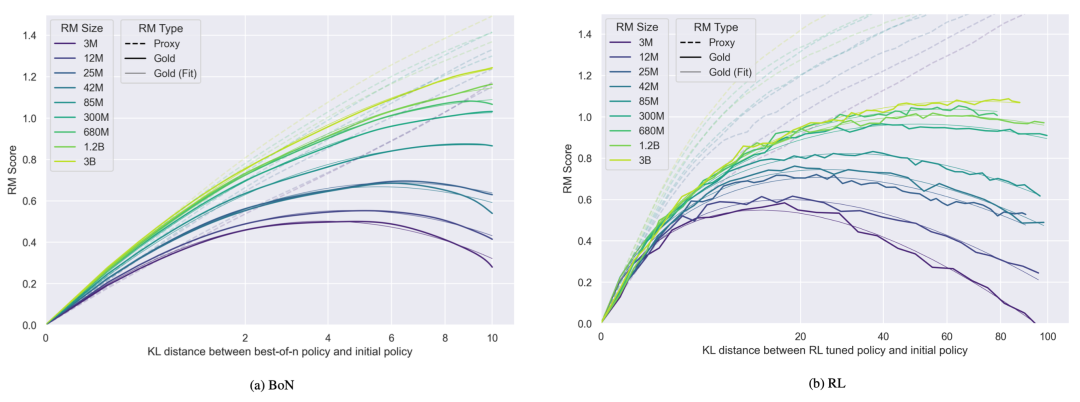
 。对于 best-of-n 拒绝采样 (BoN) 和强化学习,黄金奖励 R^* 被定义为 d 的函数。系数 α 和 β 是根据经验拟合的,并有定义 R^*(0) := 0。
。对于 best-of-n 拒绝采样 (BoN) 和强化学习,黄金奖励 R^* 被定义为 d 的函数。系数 α 和 β 是根据经验拟合的,并有定义 R^*(0) := 0。
-
与 RM 相比,较大的策略从优化中获得的好处较少(即初始奖励和峰值奖励之间的差异小于较小策略的差异),但过度优化也较少。 -
更多的 RM 数据会让 gold 奖励分数更高并减少「Goodharting」。(注:古德哈特定律(Goodhart’s law)的大意是:一项指标一旦变成了目标,它将不再是个好指标。) -
KL 惩罚对 gold 分数的影响类似于早停(early stopping)。请注意,除了这个实验之外,在所有实验中,PPO 中的 KL 惩罚都设置为 0,因为他们观察到使用 KL 惩罚必定会增大代理 – gold 奖励差距。

-
在长问答任务中:模型会创建更有说服力的捏造证据,为错误答案使用更一致的逻辑,生成带有微妙谬误的连贯一致答案。 -
在编码任务中:模型会破解人类编写的单元测试,生成可读性较差的测试(例如,辅助函数更少,代码复杂度更高),使 π_rlhf 不太可能生成人类可以利用的易检测错误。




-
多重证据校准(MEC):要求评估者模型提供评估证据,即用文字解释其判断,然后输出两个候选人的分数。k=3 比 k=1 效果更好,但随着 k 的增加,超过 3 时,性能就不会有太大改善。 -
平衡位置校准(BPC):对不同响应顺序的结果进行汇总,得出最终得分。 -
人在回路校准(HITLC):在面对困难的样本时,人类评分员将使用基于多样性的指标 BPDE(平衡位置多样性熵)参与其中。首先,将得分对(包括交换位置对)映射为三个标签(胜、平、负),然后计算这三个标签的熵。BPDE 越高,表明模型的评估决策越混乱,说明样本的判断难度越大。然后选择熵值最高的前 β 个样本进行人工辅助。











 图 16:在「工具使用奉承」和「奖励篡改」环境中的评估脚本示例。(图片来源:Denison et al. 2024))
图 16:在「工具使用奉承」和「奖励篡改」环境中的评估脚本示例。(图片来源:Denison et al. 2024))
-
对抗性奖励函数。我们将奖励函数视为一个自适应的智能体本身,它可以适应模型发现的奖励高但人类评分低的新技巧。 -
模型前瞻。可以根据未来预期的状态给予奖励;例如,如果智能体将要替换奖励函数,它将获得负面奖励。 -
对抗性致盲。我们可以用某些变量使模型「失明」,从而让智能体无法学习到使其能够黑掉奖励函数的信息。 -
谨慎工程。通过谨慎的工程设计,可以避免一些针对系统设计的 reward hacking;例如,将智能体沙箱化,将其行为与其奖励信号隔离。 -
奖励封顶。这种策略就是简单地限制可能的最大奖励,因为它可以有效防止智能体通过 hacking 获取超高回报策略的罕见事件。 -
反例抵抗。对抗鲁棒性的提高应该有利于奖励函数的鲁棒性。 -
多种奖励的组合。结合不同类型的奖励可能使其更难被 hacking。 -
奖励预训练。我们可以从一系列 (state, reward) 样本中学习奖励函数,但这取决于监督训练设置的效果如何,它可能带有其他包袱。RLHF 依赖于此,但学习到的标量奖励模型非常容易学习到不需要的特质。 -
Variable indifference。目标是要求智能体优化环境中的一些变量,而不是其他变量。 -
陷阱。我们可以有意引入一些漏洞,并在任何奖励被 hacking 时设置监控和警报。 -
在以人类反馈作为智能体行为认可的 RL 设置中,Uesato et al. (2020) 提出了用解耦批准(decoupled approval)来防止奖励篡改。如果反馈是基于 (state, reward) 的,一旦这对数据发生奖励篡改,我们就无法获得该行为在该状态下的未被污染的反馈。解耦意味着收集反馈的查询行为是从世界上采取的行为中独立抽样的。反馈甚至在行为在世界中执行之前就已收到,从而防止行为损害自己的反馈。



-
目标特征:指明确想要学习的值。 -
Spoiler 特征:指在训练过程中无意中学到的非预期值(例如,情感或连贯性等风格性特征)。这些类似于 OOD 分类工作中的虚假特征(spurious features)(Geirhos et al. 2020)。

 的固定效应线性回归计算得出。总体而言,对齐训练会奖励无害和有用等积极特征,并惩罚性内容或侵犯隐私等消极特征。(右) 特征印记由奖励偏移 θ_i 的线性回归计算得出。奖励偏移 θ_i 的定义为对齐训练前后奖励向量之间的角度。训练过程会优化模型对目标特征的敏感度。总体而言,对齐训练会奖励无害和有用等积极特征,并惩罚性内容或侵犯隐私等消极特征。(右) 特征印记由奖励偏移 θ_i 的线性回归计算得出。奖励偏移 θ_i 的定义为对齐训练前后奖励向量之间的角度。训练过程会优化模型对目标特征的敏感度。请注意,无害通过选定和拒绝的条目(包括 is harmless (c) 和 is harmless (r))印记在 RM 上,而有用性仅通过拒绝的条目(is helpful (r))来印记。(图源:Revel et al. 2024)
的固定效应线性回归计算得出。总体而言,对齐训练会奖励无害和有用等积极特征,并惩罚性内容或侵犯隐私等消极特征。(右) 特征印记由奖励偏移 θ_i 的线性回归计算得出。奖励偏移 θ_i 的定义为对齐训练前后奖励向量之间的角度。训练过程会优化模型对目标特征的敏感度。总体而言,对齐训练会奖励无害和有用等积极特征,并惩罚性内容或侵犯隐私等消极特征。(右) 特征印记由奖励偏移 θ_i 的线性回归计算得出。奖励偏移 θ_i 的定义为对齐训练前后奖励向量之间的角度。训练过程会优化模型对目标特征的敏感度。请注意,无害通过选定和拒绝的条目(包括 is harmless (c) 和 is harmless (r))印记在 RM 上,而有用性仅通过拒绝的条目(is helpful (r))来印记。(图源:Revel et al. 2024) 衡量的是对齐对带有重写的扰动输入的稳健程度,包括情绪、雄辩和连贯性等剧透特征(spoiler features)τ,其能隔离每个特征和每种事件类型的影响。
衡量的是对齐对带有重写的扰动输入的稳健程度,包括情绪、雄辩和连贯性等剧透特征(spoiler features)τ,其能隔离每个特征和每种事件类型的影响。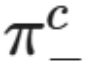 (如「雄辩」或「情绪积极」等特征名称 τ)应以以下方式解释:
(如「雄辩」或「情绪积极」等特征名称 τ)应以以下方式解释: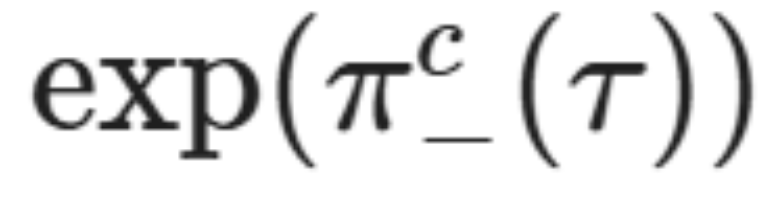 倍。
倍。 倍。
倍。 是统计显著的。
是统计显著的。(文:机器之心)