
今天是2025年3月1日,星期六,北京,天气霾。
今天我们来看关于R1推理用于多模态的13个工作,一个整理的技术工作。
DeepSeek-R1在处理数学、编码、谜题和科学问题以及回应一般问题时表现出出色的推理能力。然而,作为一个纯文本推理模型,R1无法处理图像等多模态输入,这限制了其在某些情况下的实用性。
但这一块,目前已经有很多的工作了,我们来做下归拢,有9个值得一提的思路,归纳成4个代表。一个是基于R1-zero类方案增强图像数学问题推理的简单尝试、通过语义化图像信息提升复杂视觉任务推理能力R1-Onvision、使用SFT+课程式学习或者Agent提升多模态推理能力、Open-R1-Video切帧转文本推升视频模态推理。
从实际代码出发去看,会有更多思路。
专题化,体系化,会有更多深度思考。大家一起加油。
一、基于R1-zero方案增强图像数学问题推理的简单尝试
1、VLM-R1
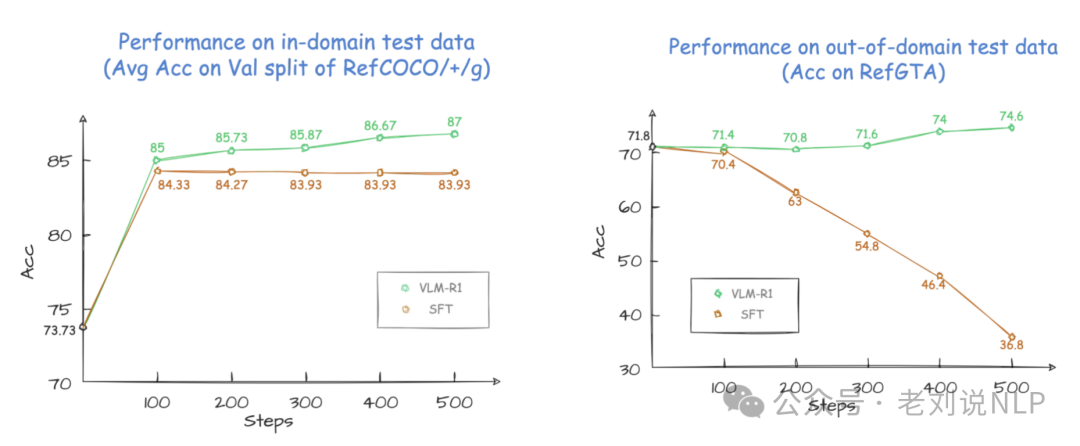
在指代表达理解(REC)任务中,使用R1和SFT方法对Qwen2.5-VL进行了训练。

结果显示,在领域内测试数据上,SFT模型的性能略低于R1模型,在领域外测试数据上,随着步数的增加,SFT模型的性能显著下降,而R1模型则表现出稳定的提升。
地址:https://github.com/om-ai-lab/VLM-R1
2、R1-V
借助R1-V框架,探索了将可验证奖励的强化学习(RLVR)和来自DeepSeekR1的推理轨迹蒸馏应用于视觉推理任务中的大型视觉-语言模型(LVLMs)
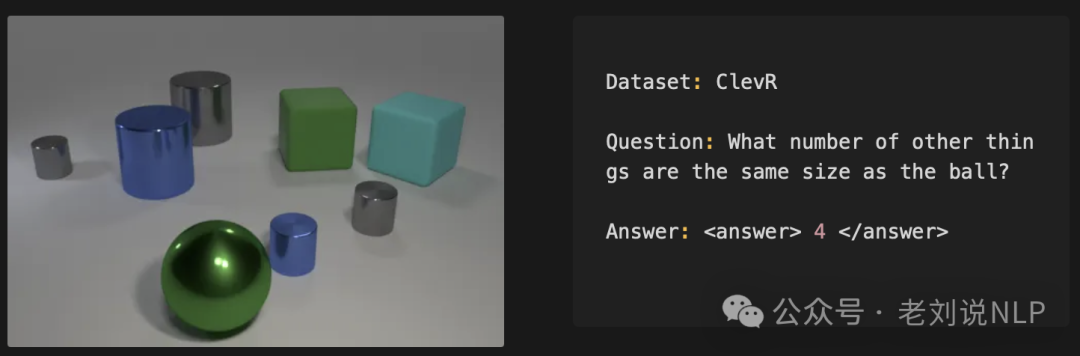
在SFT上,通过蒸馏R1的数据进行处理。
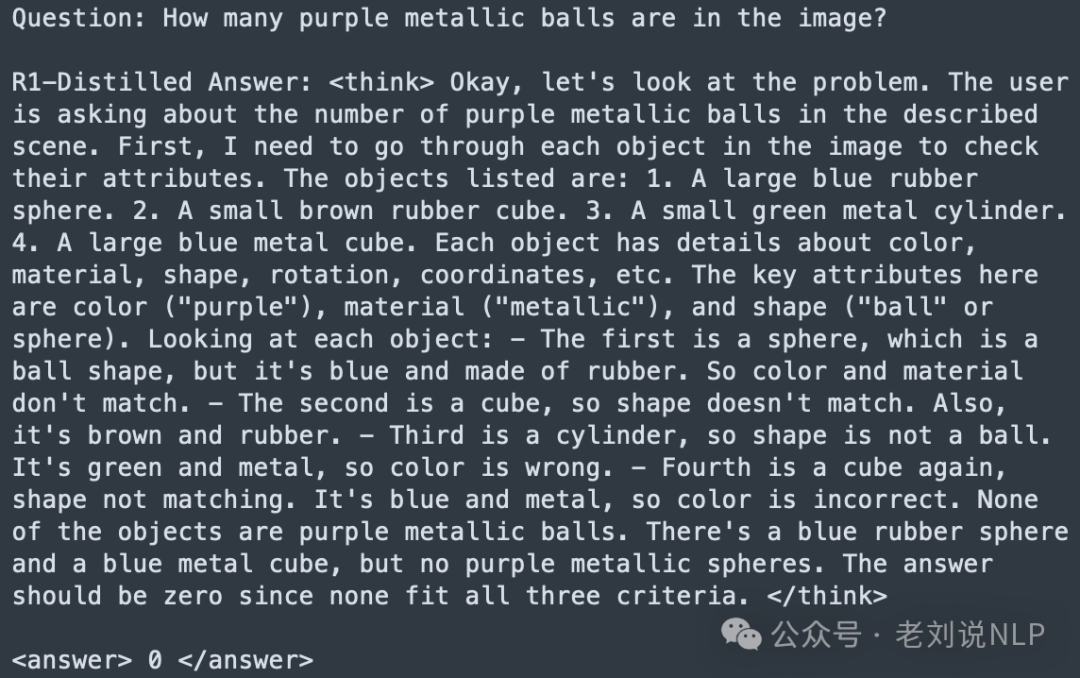
在强化实验上,GRPO方法上,设置了两个基于规则的0/1奖励,并将结果相加作为最终奖励:
1)准确率奖励:输出中的数字<answer>Number-Generated</answer>是否与真实值<answer>Number-Groundtruth</answer>匹配。 2)格式奖励:输出响应是否遵循<think>.*?</think>\s*<answer>.*?</answer>。
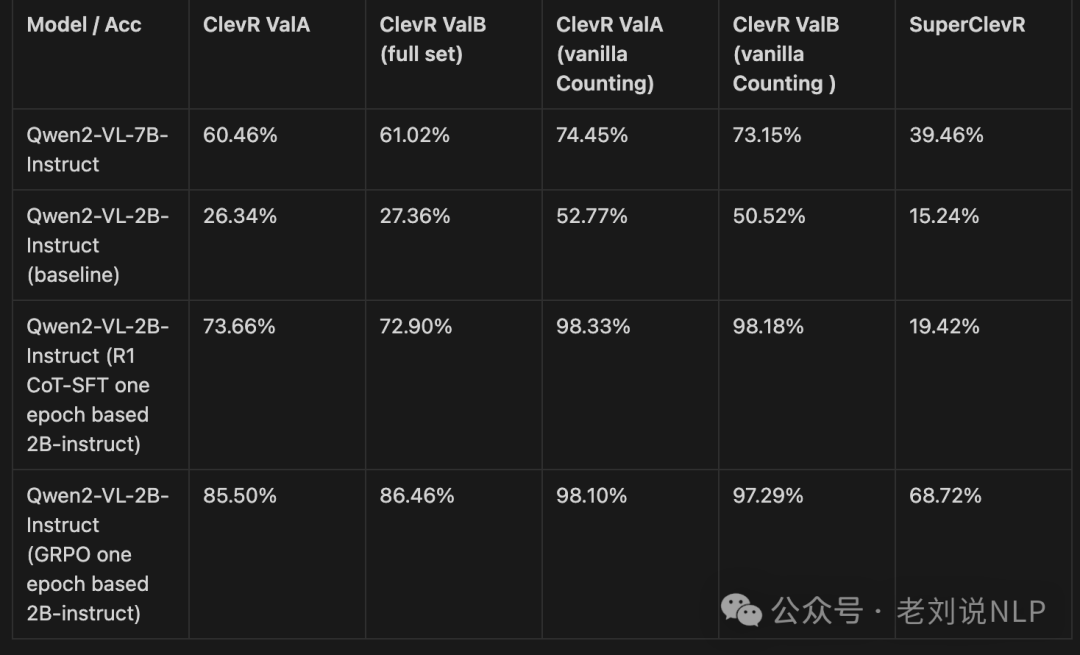
有几个发现:
1)在分布外(OOD)视觉推理任务(例如复杂计数/问答)中,可验证奖励的强化学习(RLVR)优于监督式微调(SFT),而SFT在领域内的几何场景等任务中表现更好。
2)在SFT中强制执行“逐步推理”往往会损害小型视觉-语言模型的性能。RLVR的GRPO方法能够在无人工引导的情况下实现自适应推理(无/长链推理),从而实现强大的泛化能力。
但也有几个关键未解问题:
一个是为什么RL和SFT会在不同领域表现出色?如何将它们结合起来?一个是模型规模如何影响RL与SFT的性能差异?一个是如何为开放式的视觉/代理任务设计奖励?未来的工作目标是统一这些方案?
地址:https://github.com/Deep-Agent/R1-V,https://deepagent.notion.site/rlvr-in-vlms
3、open-r1-multimodal
基于HuggingFace的https://github.com/huggingface/open-r1和DeepSeekAI的https://github.com/deepseek-ai/DeepSeek-R1实现了多模态R1,整合了Qwen2-VL系列、Aria-MoE以及其他在Transformers中可用的视觉-语言模型(VLMs)。
开源了第一批专注于数学推理的8k多模态强化学习训练样本,这些数据由GPT4o生成,包含推理路径和可验证的答案,基于Math360K和Geo170K数据集。提供了一个脚本,用户可以检查和创建自己的数据,数据集可在https://huggingface.co/datasets/lmms-lab/multimodal-open-r1-8k-verified获取,使用GRPO训练。
模型可在https://huggingface.co/lmms-lab/Qwen2-VL-2B-GRPO-8k和https://huggingface.co/lmms-lab/Qwen2-VL-7B-GRPO-8k获取。
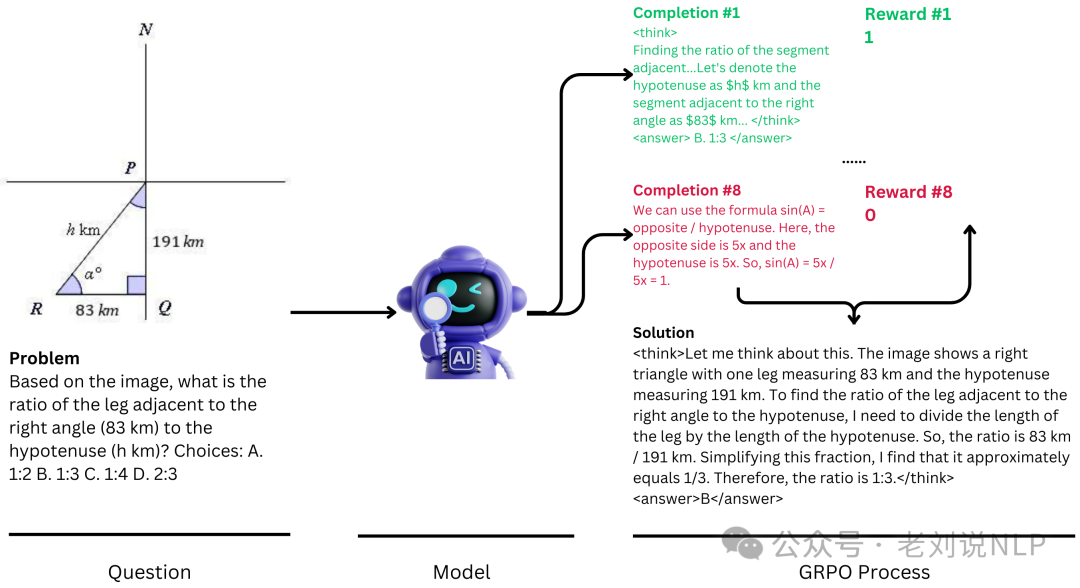
效果:
地址:https://github.com/EvolvingLMMs-Lab/open-r1-multimodal
4、VisualThinker-R1-Zero
VisualThinker-R1-Zero 是对DeepSeek-R1-Zero在视觉推理领域的复现。首次在仅使用20亿参数且未经监督微调(SFT)的模型中成功观察到视觉推理中出现的“顿悟时刻”以及回答长度的增加。
先看起实验:
本着更长的推理过程可以极大地助力以视觉为中心的任务的原则。从Qwen2-VL-2B基础模型出发,直接在SAT数据集上进行强化学习。训练过程使用了来自SAT训练数据集的约12,000个查询,这些查询专门关注空间推理问题。与DeepSeek-R1-Zero类似,直接在基础模型上应用RL,而没有进行任何SFT训练。
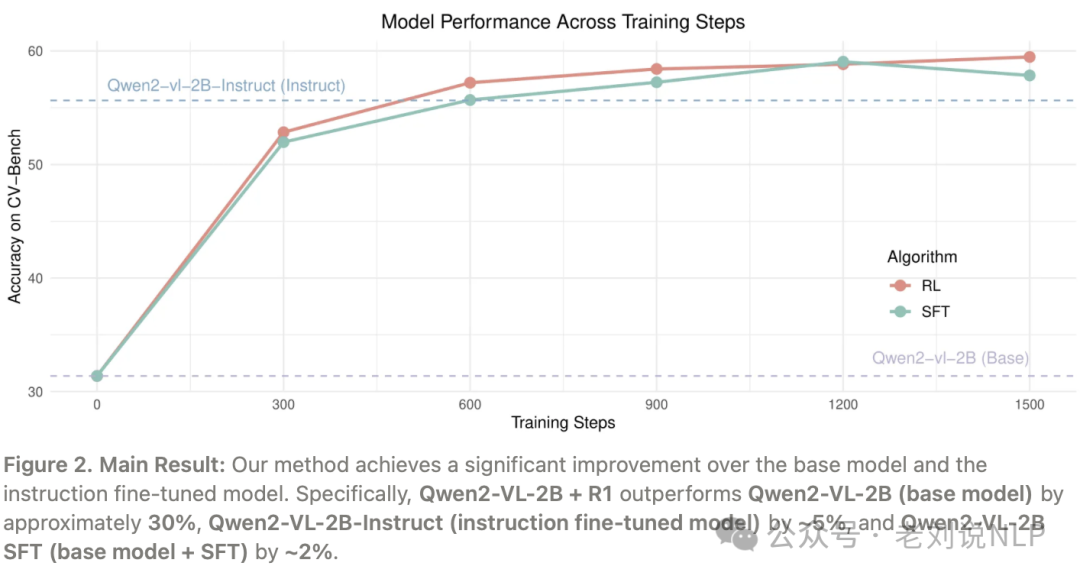
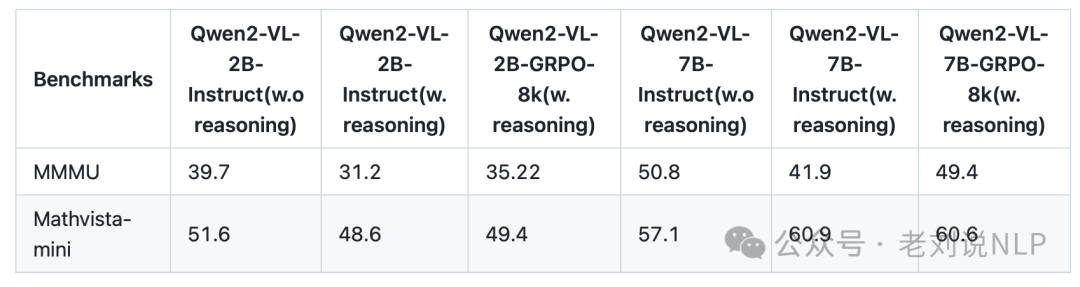
实验表明,在基准测试中的表现比Qwen2-VL-2B(基础模型)高出约30%,比Qwen2-VL-2B-Instruct(指令微调模型)高出约5%,比Qwen2-VL-2BSFT(基础模型+SFT)高出约2%。这表明视觉推理也可以从R1-Zero训练中受益,通过RL探索多样化的推理路径,实现了更具可扩展性的训练。其中,强化学习方式采用了GRPO算法,并使用基于规则的奖励函数,根据回答的格式和正确性来评估响应:

此外还有几个有趣的发现:
一个是,是否应该在指令微调模型上做RL。
在指令微调模型上应用RL。虽然这种方法提升了性能,但模型的响应却退化为毫无意义或琐碎的推理,最终得出答案。

有趣的点来了,视觉为中心的任务上的RL是否主要提升了模型的视觉能力。为了探究这一点,冻结了视觉编码器,并应用RL来评估其影响。
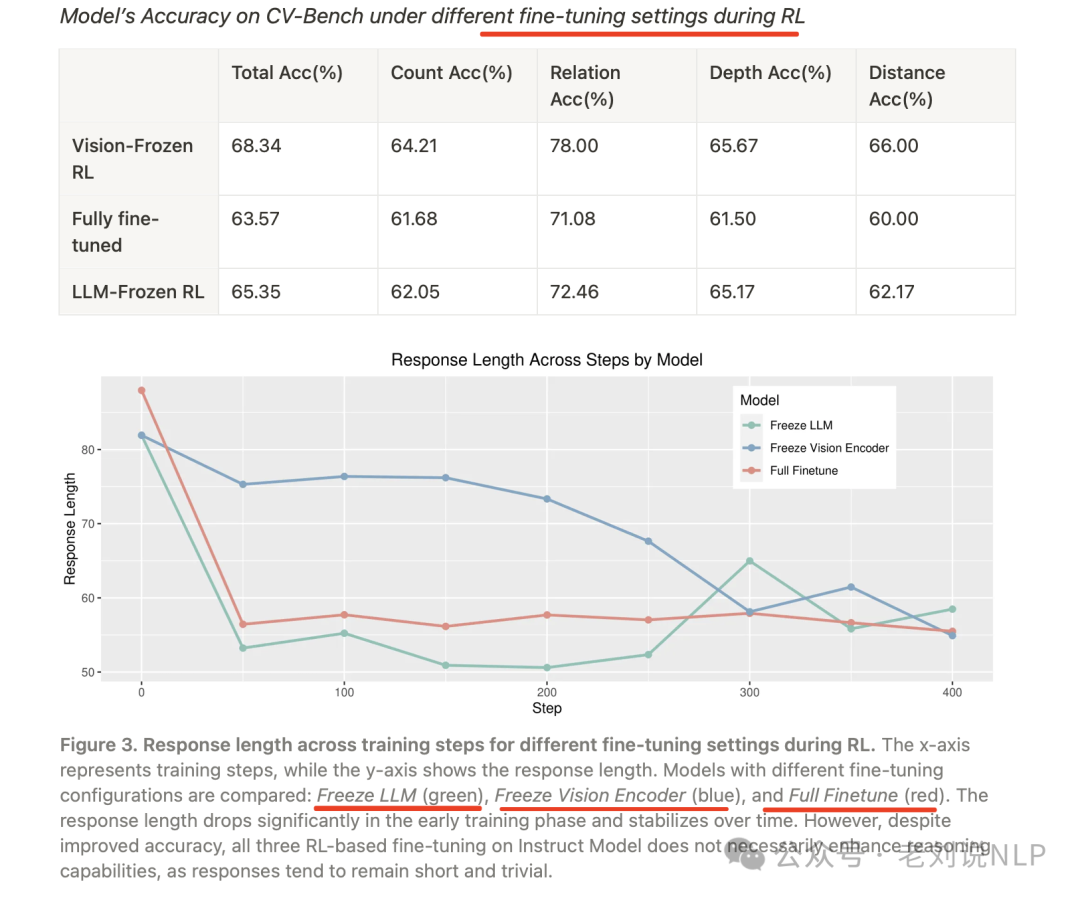
在RL训练过程中,不同微调设置下的响应长度变化。x轴表示训练步骤,y轴显示响应长度。比较了不同微调配置的模型:冻结LLM(绿色)、冻结视觉编码器(蓝色)和全微调(红色)。响应长度在早期训练阶段显著下降,并随着时间推移趋于稳定。然而,尽管准确率有所提高,所有三种基于RL的指令模型微调并不一定增强推理能力,因为响应仍然简短且琐碎。

结果表明,冻结视觉编码器进行MLLMs训练可以提升性
一个是,单纯奖励长回答是否能提升性能?另一个自然的问题是,响应的长度本身是否是提升推理能力的关键因素。为了探究这一点,进行了实验,以评估单纯激励更长回答是否能提升模型的推理能力。具体来说,为模型生成的每个额外token奖励+0.001。
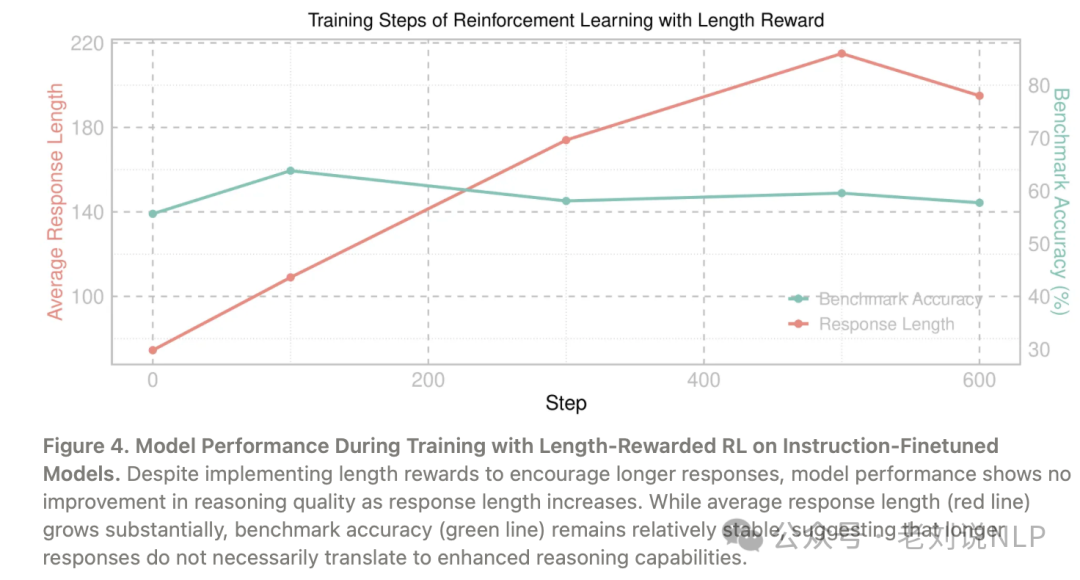
在指令微调模型上,使用长度奖励的RL训练过程中的模型性能。尽管实施了长度奖励以鼓励更长的回答,但模型性能在推理质量上并未随着回答长度的增加而提升。尽管平均回答长度(红线)显著增加,但基准测试准确率(绿线)相对稳定,这表明更长的回答并不一定转化为更强的推理能力。
结论是,单纯奖励长回答并不能提升模型性能。
地址:https://github.com/turningpoint-ai/VisualThinker-R1-Zero,https://turningpointai.notion.site/the-multimodal-aha-moment-on-2b-model
二、通过语义化图像信息提升复杂视觉任务推理能力R1-Onvision
1、R1-Vision
R1-Vision: Let’s first take a look at the image,这个项目还在建设当中,构建这个项目是为了创建一个可以用文本和图像进行推理的模型。【注意,这个项目还没完,还很初步】
在https://huggingface.co/collections/yuyq96/r1-vision-67a6fb7898423dca453efa83中发布了第一个工作,使用DeepSeek-R1-Distill-Qwen-32B模型进行推理,使用GPT-4o-mini模型进行图像字幕和数据格式化。
在实现上,
与推理强迫技巧类似,让模型在思考过程开始时通过为图像添加标题来假装“看到”图像。使用一个简单的模板:

这里其实还是通过添加caption来实现:
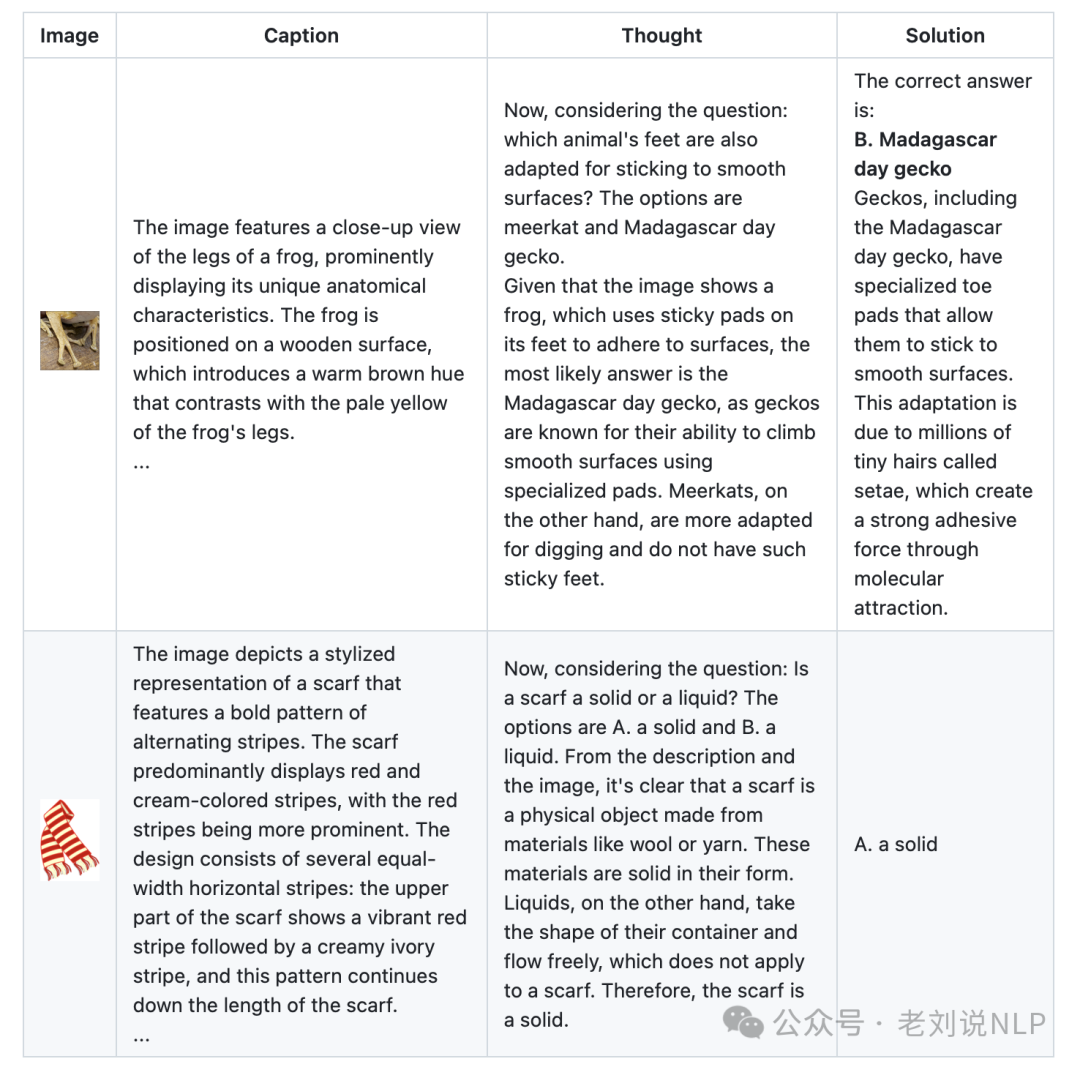
另一种,用LLM重新格式化原始问题,在图像上渲染重新格式化的LaTeX文件,这个可以理解是一种数据扩充。
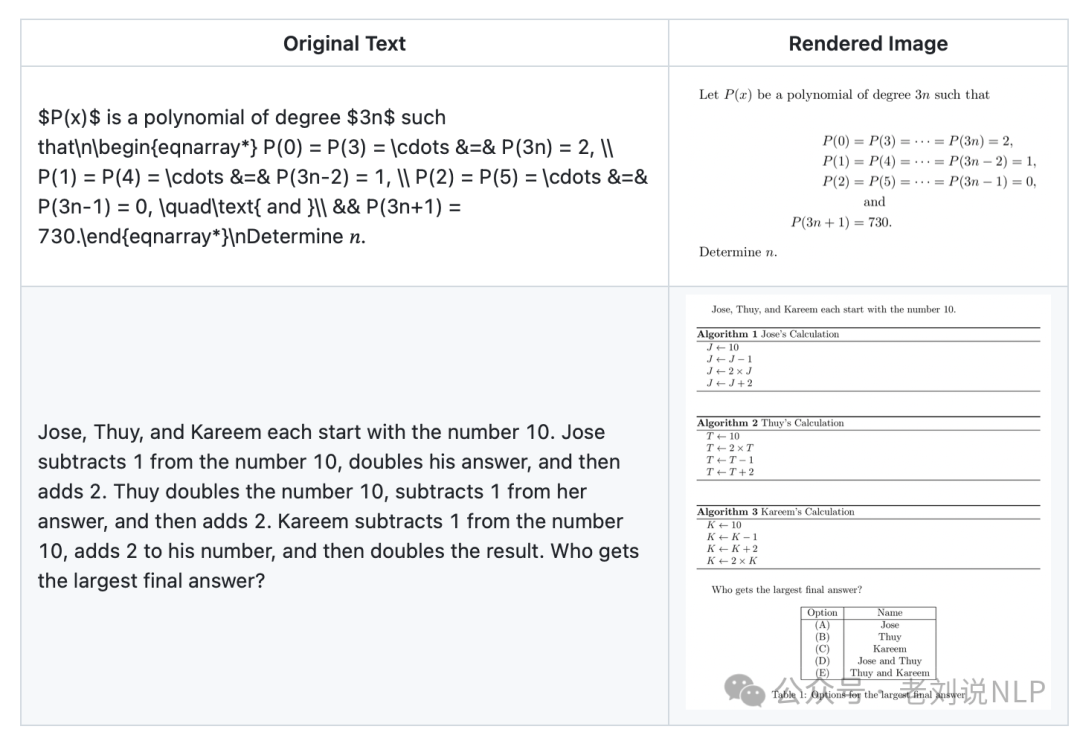
最后,评估TextHawk2-7B and Qwen2.5-VL-7B,然后做RL,不过这些都还没做。
地址:https://github.com/yuyq96/R1-Vision
2、R1-Onevision
《R1-Onevision:Open-Source Multimodal Large Language Model with Reasoning Ability》这个工作,还是做的R1系列用于多模态范畴,这个比上一个完善的多。

地址在:https://github.com/Fancy-MLLM/R1-Onevision,https://huggingface.co/datasets/Fancy-MLLM/R1-Onevision,https://huggingface.co/datasets/Fancy-MLLM/R1-OneVision-Bench,https://huggingface.co/Fancy-MLLM/R1-OneVision-7B,https://huggingface.co/spaces/Fancy-MLLM/R1-OneVision,https://paperswithcode.com/dataset/r1-onevision
来看看一些实现细节,可以看https://yangyi-vai.notion.site/r1-onevision,技术路线图如下: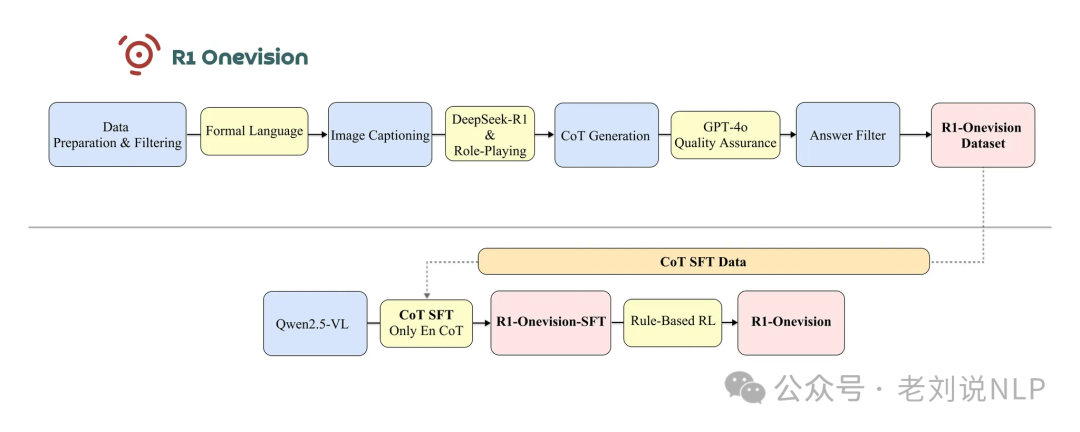
与上面不同的是,是个多阶段的,先做SFT,再做GRPO强化。
三、使用SFT+课程式学习或者Agent提升多模态推理能力
1、LlamaV-o1
《LlamaV-o1: Rethinking Step-By-Step Visual Reasoning in LLMs》,采用课程学习方法,从简单的任务(如总结和生成描述)逐步过渡到复杂的多步推理任务。

在数据上,包括PixMo数据集,用于训练模型的基础推理技能,如生成摘要和描述,包含18,000个样本,包含基于输入问题的有根据的描述(groundedcaptions),帮助模型理解视觉内容与文本之间的关系。Geo170K数据集,用于训练模型的推理步骤生成能力,包含57,000个样本。每个样本包含问题-答案对及其推理步骤,帮助模型学习逐步推理的逻辑;Llava-CoT数据集,用于第二阶段训练,专注于复杂多步推理任务。包含99,000个结构化样本,涵盖多个领域(如一般视觉问答和科学目标视觉问答)。数据来源多样,包括ShareGPT4V、ChartQA、A-OKVQA、DocVQA、PISC、CLEVR等。每个样本包含摘要、详细描述、详细推理步骤和最终答案,帮助模型学习从简单到复杂的推理过程。
训练策略上,采用课程学习(CurriculumLearning),通过逐步增加任务难度,模型能够更好地泛化到复杂的推理场景,同时避免因直接在复杂任务上微调而导致的过拟合和遗忘问题。第一阶段从简单的任务(如生成摘要和描述)开始,帮助模型建立基础推理能力。
第二阶段逐步过渡到复杂的多步推理任务,确保模型能够处理更复杂的逻辑和推理路径。其中,多步推理训练,包括任务理解:模型首先理解问题和上下文;任务总结:生成对视觉数据的总结,为后续推理提供基础;详细描述生成:进一步生成详细的描述,识别图表中的具体标签及其值;逻辑推理:基于总结和描述,进行逻辑推理,分解任务为子目标;最终答案生成**:根据推理过程输出最终答案。
模型上采用Llama-3.2-11B-Vision-Instruct,采用监督微调(SupervisedFine-Tuning,SFT)方法,使用8个NVIDIAA100(80GB)GPU进行训练,确保高效处理大规模数据集和模型的计算需求。采用BeamSearch技术优化推理效率,通过并行生成多个推理路径并选择最优路径,显著提高推理速度和质量。
地址:LlamaV-o1 Project: https://mbzuai-oryx.github.io/LlamaV-o1/,LlamaV-o1 Model: https://huggingface.co/omkarthawakar/LlamaV-o1,LlamaV-o1 Code: https://github.com/mbzuai-oryx/LlamaV-o1,VRC-Bench https://huggingface.co/datasets/omkarthawakar/VRC-Bench
2、Insight-V
《Insight-V: Exploring Long-Chain Visual Reasoning with Multimodal Large Language Models》(https://arxiv.org/pdf/2411.14432)核心是一个多智能体系统,包含两个主要组件:推理智能体(Reasoning Agent)负责生成详细的推理过程,将复杂问题分解为多个步骤,逐步解决问题。总结智能体(Summary Agent):负责评估推理过程的质量,并根据推理结果选择性地回答问题。这种设计将问题解决过程分解为推理和总结两个阶段,推理智能体专注于生成推理路径,而总结智能体则负责评估推理路径的准确性和相关性,从而提升模型的推理能力和鲁棒性。
这里就涉及到训练过程。
数据生成上,使用推理生成器生成长链推理路径,通过多粒度评估系统筛选高质量推理路径。具体的,使用推理生成器(Reasoning Generator)逐步生成结构化的推理过程。每一步生成器提供当前步骤的简要总结、详细推理响应以及下一步的动作(继续或总结)。通过重复这一过程,为每个问题生成多个结构化的推理路径。
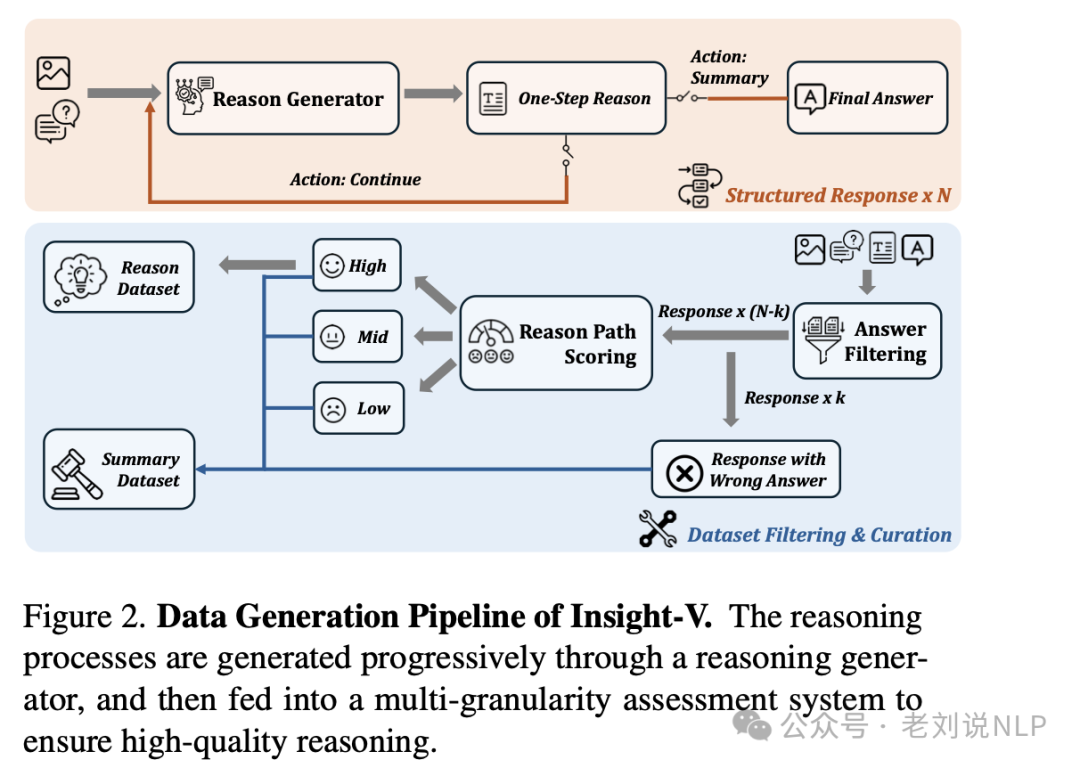
然后进行多粒度评估,使用LLM(如Qwen2)对生成的推理路径进行评估,过滤掉错误的推理路径。通过推理路径评分代理(Scoring Agent)对剩余路径进行评分,确保数据质量。通过这种方式,Insight-V能够生成高质量、长链的推理数据,为推理智能体的训练提供支持。
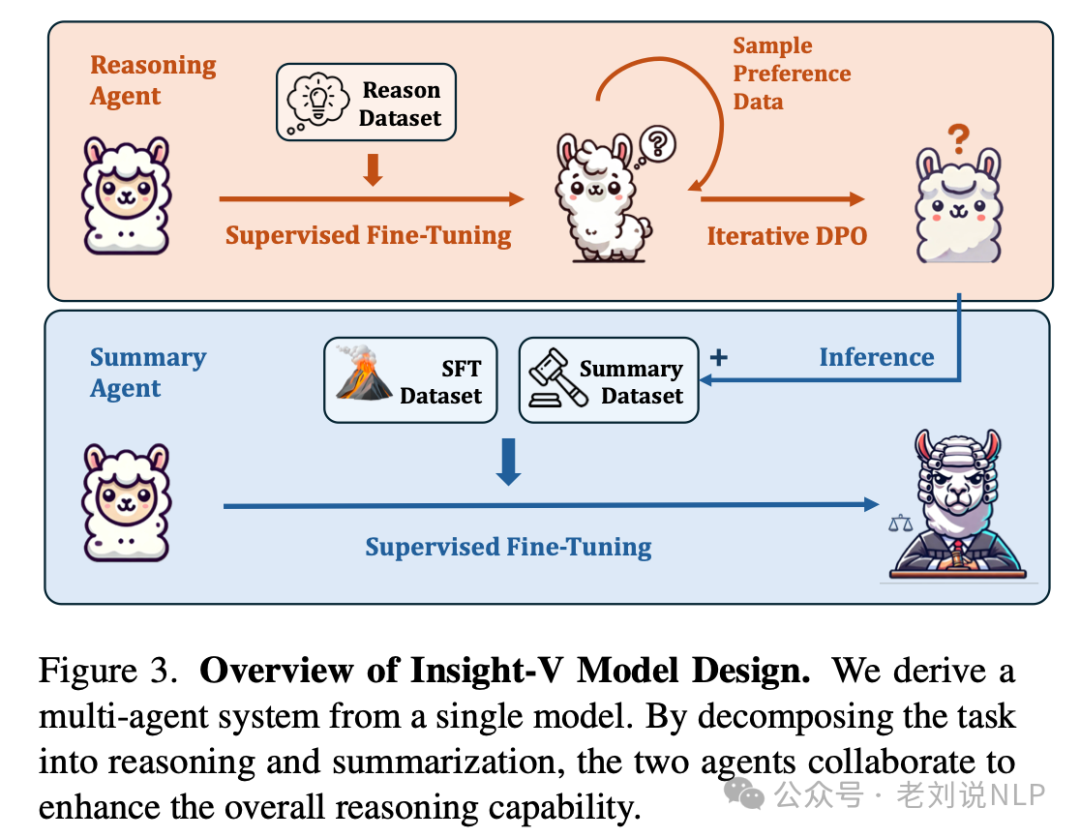
监督微调(SFT)阶段,使用生成的推理数据集对推理智能体进行训练,使其能够生成详细的推理过程。总结智能体的训练数据集包含与推理智能体生成的高质量推理路径配对的问题以及错误推理路径的数据,用于提升总结智能体对推理质量的评估能力。总结智能体通过学习这些数据,能够评估推理路径的质量,并选择性地回答问题。
迭代直接偏好优化(DPO)阶段,采用了迭代DPO: 每次迭代中,模型使用前一次迭代生成的偏好数据进行训练。
地址:https://github.com/dongyh20/Insight-V
四、Open-R1-Video切帧转文本推升视频模态推理
1、Open-R1-Video
在使用4块A100(80GB)GPU的情况下,在简单的视频数据集open-r1-video-4k上训练了Qwen2-VL-7B-Instruct模型,训练过程中仅使用视频、查询以及正确答案(即正确答案的字母)作为输入。
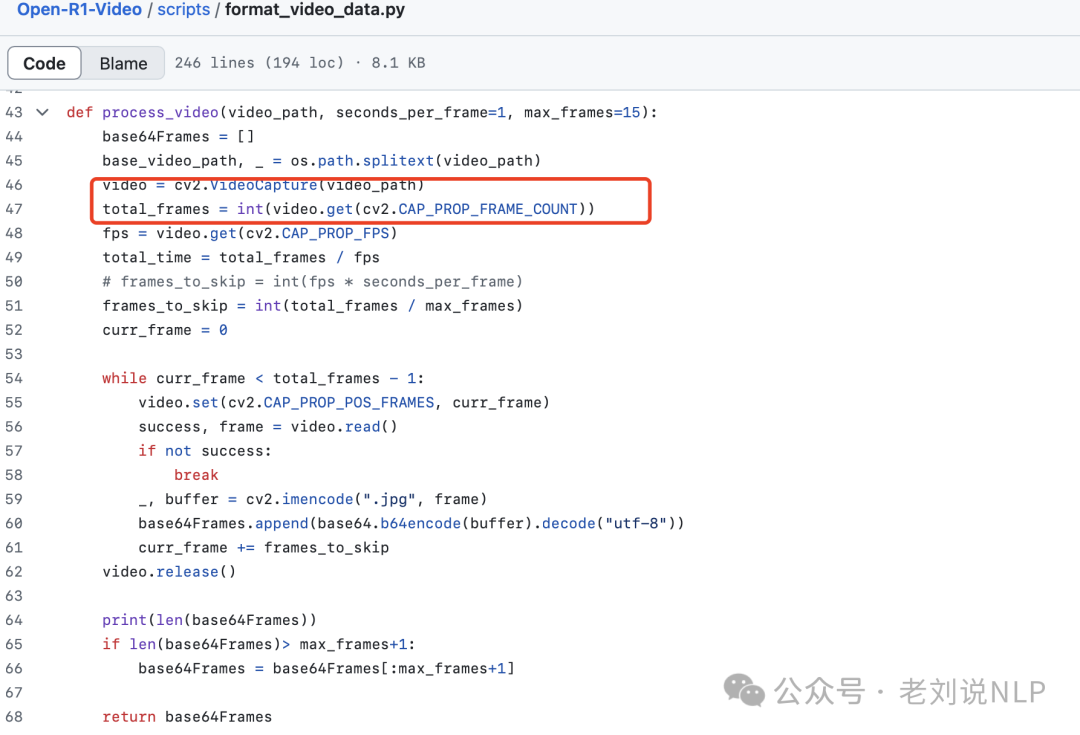
对于视频数据的处理代码在:https://kkgithub.com/Wang-Xiaodong1899/Open-R1-Video/blob/main/scripts/format_video_data.py
核心思路就是,视频抽帧:
,然后送GPT4-O进行视频分析
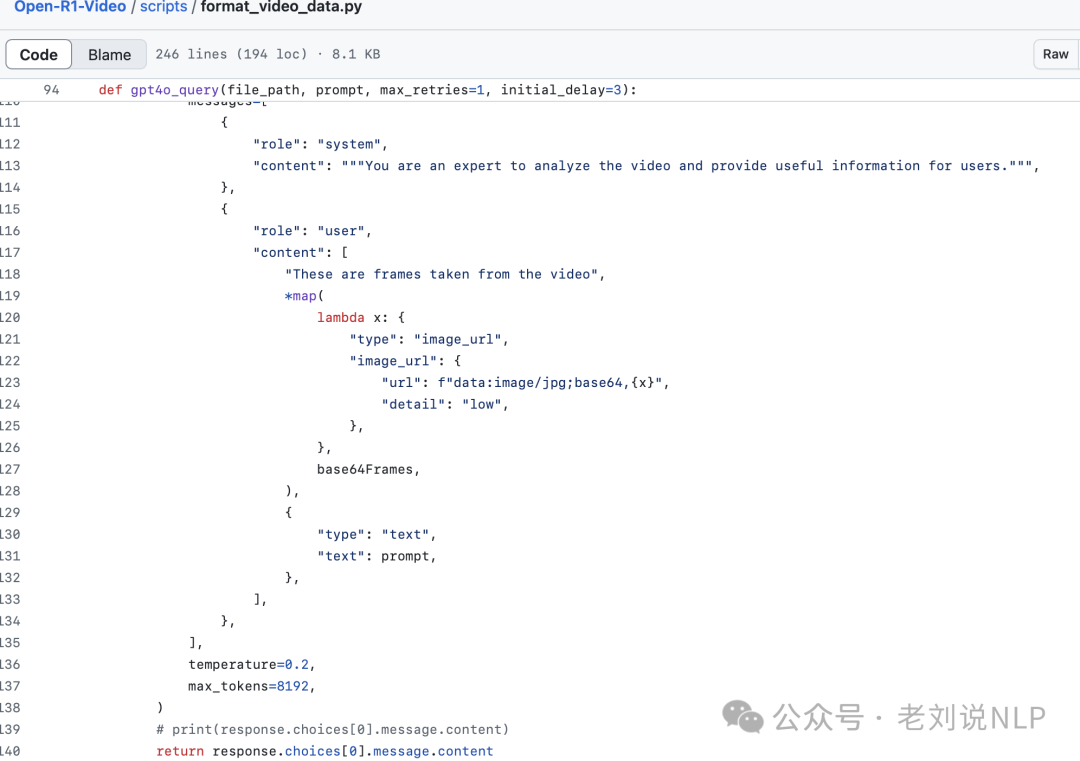
仅采用GRPO(纯强化学习,不使用标注的推理轨迹)来训练模型。训练阶段的prompt设计如下:
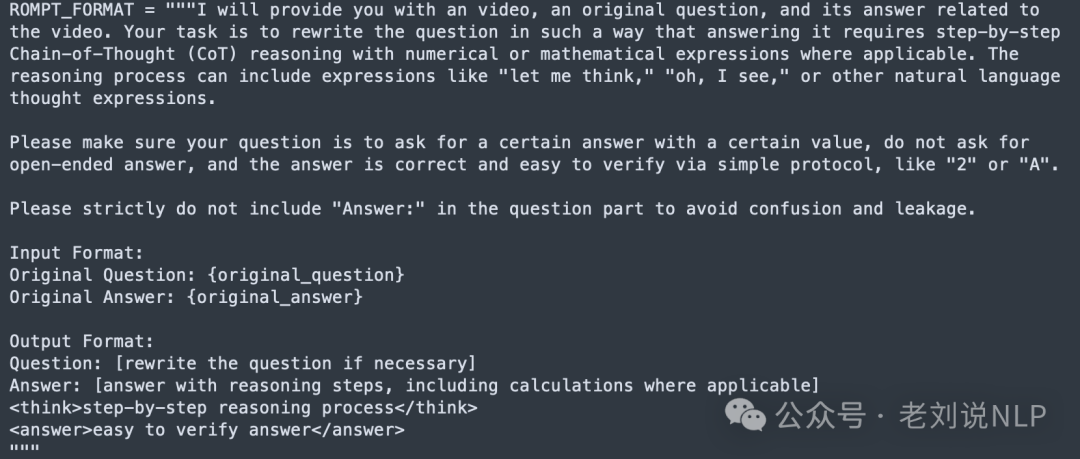
结论如下:
对应的指标如下: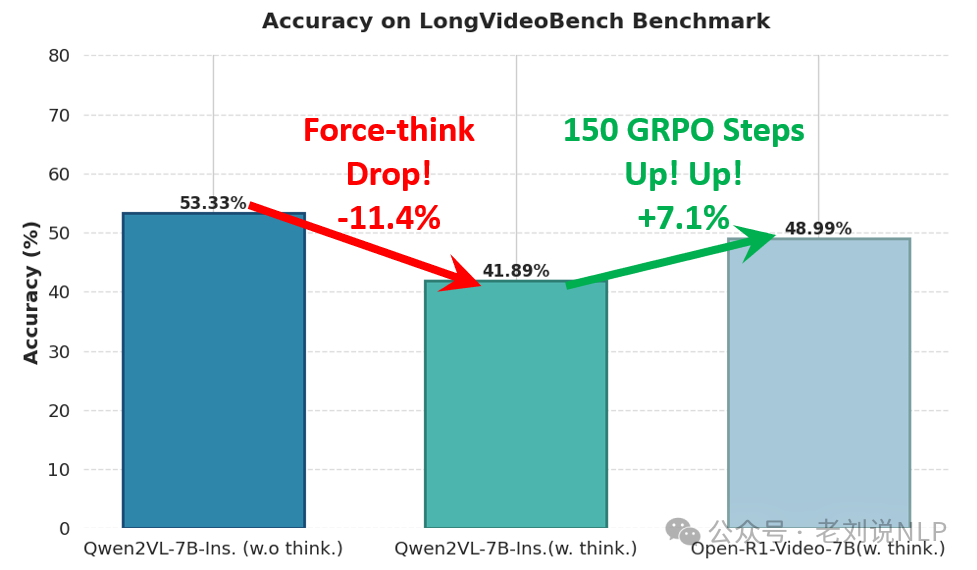

地址:https://github.com/Wang-Xiaodong1899/Open-R1-Video
总结
本文主要介绍了有9个值得一提的将深度推理用于多模态的思路,归纳成4个代表。一个是基于R1-zero类方案增强图像数学问题推理的简单尝试、通过语义化图像信息提升复杂视觉任务推理能力R1-Onvision、使用SFT+课程式学习或者Agent提升多模态推理能力、Open-R1-Video切帧转文本推升视频模态推理。
多看看,细节信息可以看给出的地址,大家一起加油。
(文:老刘说NLP)