【新智元导读】LLM在推理任务中表现惊艳,却在自我纠正上的短板却一直令人头疼。UIUC联手马里兰大学全华人团队提出一种革命性的自我奖励推理框架,将生成、评估和纠正能力集成于单一LLM,让模型像人类一样「边想边改」,无需外部帮助即可提升准确性。
AI不仅能解答复杂的数学题,还能像老师一样检查自己的答案。
不仅如此,发现错误后自己立刻改正——这一切都不需要任何人帮忙!
近日,UIUC联手马里兰大学全华人研究团队最新研究Self-rewarding correction for mathematical reasoning,实现了上述目标。
该研究团队打造了一款「自我奖励推理模型」,让大模型 (LLM) 从生成推理路径到自我评估,再到纠正错误,全部一气呵成。
不仅性能碾压传统方法,连计算成本都大幅降低!
论文地址:https://arxiv.org/abs/2502.19613
LLM在数学和编程等推理任务中展现了惊人的能力,特别是在OpenAI o1发布后,具备强大推理能力的LLM以及提升推理的方法引起了更多关注。
这类模型的一个理想特性是能够检测自己生成回答中的不一致和错误,并通过反馈纠正这些错误,生成更好的回答,这种过程常被称为自我纠正。
研究表明,LLM可以根据外部真实奖励反馈改进初始回答,并决定何时停止自我纠正循环,这种方法在数学推理和一般任务中都证明是有效的。
然而,这些奖励模型通常本身也是LLM,在推理时需要运行多个模型,增加了计算成本和部署复杂性。
相比之下,若没有外部奖励反馈,当前LLM很难仅凭自身能力改进初始回答,这一局限被称为内在自我纠正的不足。
近期研究表明,LLM本身可以通过生成方式产生奖励信号。
例如,「LLM作为评判者」方法提示LLM评估文本输出,实际上替代了人类反馈。
另一个新兴方向是生成式奖励模型,将评估任务转化为遵循指令的问题,利用生成特定标记的概率作为奖励值,这些方法利用了LLM的下一标记预测能力,将生成和评估整合到一个统一框架中。
在这些见解的基础上,研究人员探讨了自我奖励推理模型,从而将三种能力集成到单一的LLM中。
地址:https://github.com/RLHFlow/Self-rewarding-reasoning-LLM
研究人员将自我奖励推理过程形式化为一个多轮马尔可夫决策过程(MDP)。
在观察到初始提示后,LLM将生成一个初始推理尝试。然后,LLM通过生成一个评估来自我奖励其响应。
如果模型评估其答案为正确,生成过程即停止。否则,LLM进入下一步,生成一个改进的响应和评估,其中生成过程基于更新后的状态。
自我改进过程持续进行,直到模型产生一个自我评估,判断答案为正确。
在本研究中,团队使用了ToRA验证脚本,该脚本基于Python符号数学库SymPy。下表1是自我奖励推理路径示例。

遵循LLMs的标准后训练实践,研究团队采用了两阶段方法:
1 自我奖励指令跟随微调(IFT)。从初始LLM(例如,一个通用聊天机器人)开始,他们通过顺序拒绝采样过程收集演示数据,并进行微调,得到改进模型,该模型集成了自我奖励推理能力。
2 强化学习(RL)优化。进一步使用强化学习优化上一步的改进模型,以其作为参考模型。这一阶段可以进一步提升模型评估正确性和改进先前响应的能力。
自我奖励指令跟随微调
通过标记预测进行自我奖励。为了训练LLMs评估推理步骤,研究团队将此任务形式化为一个指令跟随任务。
具体来说,他们允许模型在评估中包含推理,同时要求它们输出特定标记以指示评估结果。
(i) 提示「最近的最终答案是否正确(是或否)?」并以「Yes」和「No」作为响应标记;
(ii) 明确的标记,如「『VERIFY』correct」和「『VERIFY』wrong」。
他们的实验显示这些选择之间存在显著的性能差异。
在推理过程中,他们从分布中采样评估标记。这能够使用标准的推理流程,而无需任何特定调整。(参见表1的示例)
通过顺序拒绝采样的数据收集:研究人员采用了一种拒绝采样方法,生成大量自我纠正轨迹,并仅保留所需的轨迹。
他们按顺序提示基础模型并分别生成不同的步骤。然后,将它们组合成包含自我奖励和自我纠正模式的较长CoT(思维链)轨迹。
数据收集过程包括以下步骤:
1 生成初始推理响应:从MATH和GSM8K等数据集的训练提示中采样,每条提示生成N_1=50个初始响应作为基础轨迹。
2 自我奖励信号采样:对于每个提示和初始响应,进一步采样N_2=8个自我评估,并仅保留一个与真实结果 (ground truth) 相同的评估结果。然后,使用真实验证器r⋆ 将其分为Gcorrect和Gwrong。
3 纠正采样:对于Gwrong中的每个提示和初始响应,他们通过提供初始响应错误的反馈,采样M_1=8个完成结果,以收集成功修正错误响应的轨迹。而对于Gcorrect中的每个提示和初始响应,也告诉模型该响应是错误的,并收集M_2=4个完成结果。
通过这样做,他们还希望在错误判断的情况下额外收集「正确到正确」的轨迹。
最终,他们收集了8×|Gwrong|+4×|Gcorrect|条完整轨迹。
下表2中提供了一个数据收集过程的示例。由于资源限制,他们将迭代次数限制为两次,并对每个基础样本最多保留一条轨迹。

在这一阶段,研究团队使用强化学习进一步增强自我奖励的IFT模型。他们考虑了深度强化学习方法和直接对齐算法。
学习信号:为了便于强化学习阶段,他们假设存在一个针对轨迹τ的轨迹级奖励函数。然而,与RLHF中的BT模型或先前数学推理文献中的结果监督奖励 (ORM)从数据中学习代理奖励不同,他们主要使用Oracle奖励:
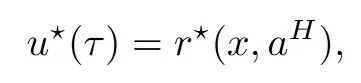
验证最终结果是否正确。其主要优点是Oracle奖励可以在很大程度上减轻奖励操控的风险。这在最近的文献中也被称为基于规则的强化学习 。
他们还将研究额外的规则设计,用于奖励值分配 (PPO训练) 或数据排序 (DPO训练),其中隐含的u^*由使用的规则集决定。
遵循标准的RLHF 方法,研究团队优化以下KL正则化目标:
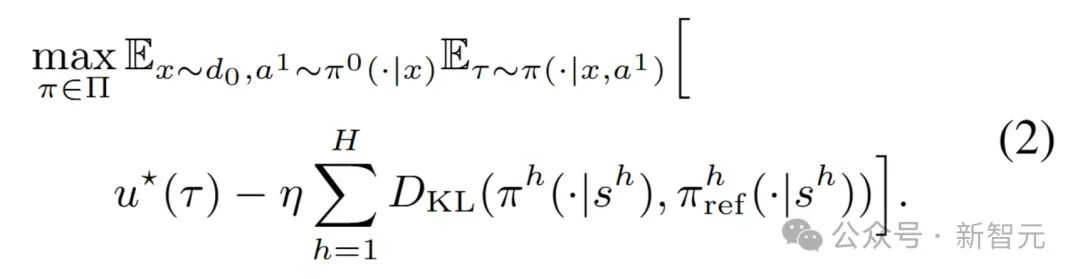
最优策略及其相关的优化值满足以下最优性条件。
简单来说,通过定义「最优值」和「最优策略」,让LLM在有限步骤内根据外部指令调整行为,同时用奖励机制(比如判断结果对错)来提升表现。
为了避免计算太复杂,研究团队还用了一种叫「直接偏好优化」(DPO) 的方法,通过比较不同选择的好坏来训练,让它更聪明地完成任务。
换句话说,这个模型就像教LLM玩一个游戏:先告诉它目标是什么(比如答对题),然后通过反复尝试和反馈(比如「这个错了,换个方法」),让LLM学会如何在几步之内找到正确答案,最后得出一个能衡量它表现的「损失函数」。
任务、数据集与数据格式
使用标准基准评估模型的数学推理能力,包括MATH500、OlympiadBench和Minerva Math。
这些数据集规模适中,确保模型评估的可靠性和高效性,涵盖代数、几何、概率、数论和微积分等主题。
在训练阶段,主要使用NumiaMath-CoT数据集中的提示。具体而言,使用50K子集进行自我奖励IFT阶段,10K子集用于验证和模型选择,其余数据用于强化学习训练。
在推理过程中,模型最多生成4096个token,并使用VLLM 0.5.4加速推理过程。
评估指标
采用两类指标来评估模型性能:(1)数学推理与自我修正能力;(2)奖励模型的准确性。
首先考虑以下指标来评估模型的数学推理和自我修正能力。
-
第一次尝试的准确性(Turn 1):第一次回答的准确性;
-
最终准确性(Final accuracy):最终答案的准确性;
-
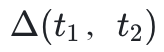 :从首次尝试到最终答案的准确性提升;
:从首次尝试到最终答案的准确性提升;
-
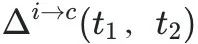 :从错误(incorrect)到正确(correct)的问题占比;
:从错误(incorrect)到正确(correct)的问题占比;
-
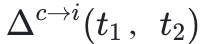 :从正确到错误的问题占比。
:从正确到错误的问题占比。
由于自我奖励推理框架的特性,引入了额外的衡量奖励模型准确性的指标。
同时,将对提出的框架进行更全面的分析,使用稍简化的模板,并在计算在面对误导性奖励时,将正确答案修改为错误答案的比例。
-
奖励模型准确率(RM Accuracy (a, b)):针对正确和错误轨迹的分类准确率。其中,a表示真阳性率(正确轨迹的识别率),b表示真阴性率(错误轨迹的识别率);
-
比例
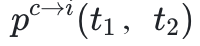 :在面对误导性奖励时,将正确答案修改为错误答案的概率。
:在面对误导性奖励时,将正确答案修改为错误答案的概率。
在所有评估中,遵循惯例,使用零样本思维链提示(zero-shot CoT prompting)和贪婪解码(greedy decoding)方法,基于Qwen-2.5-Math模型进行评估。
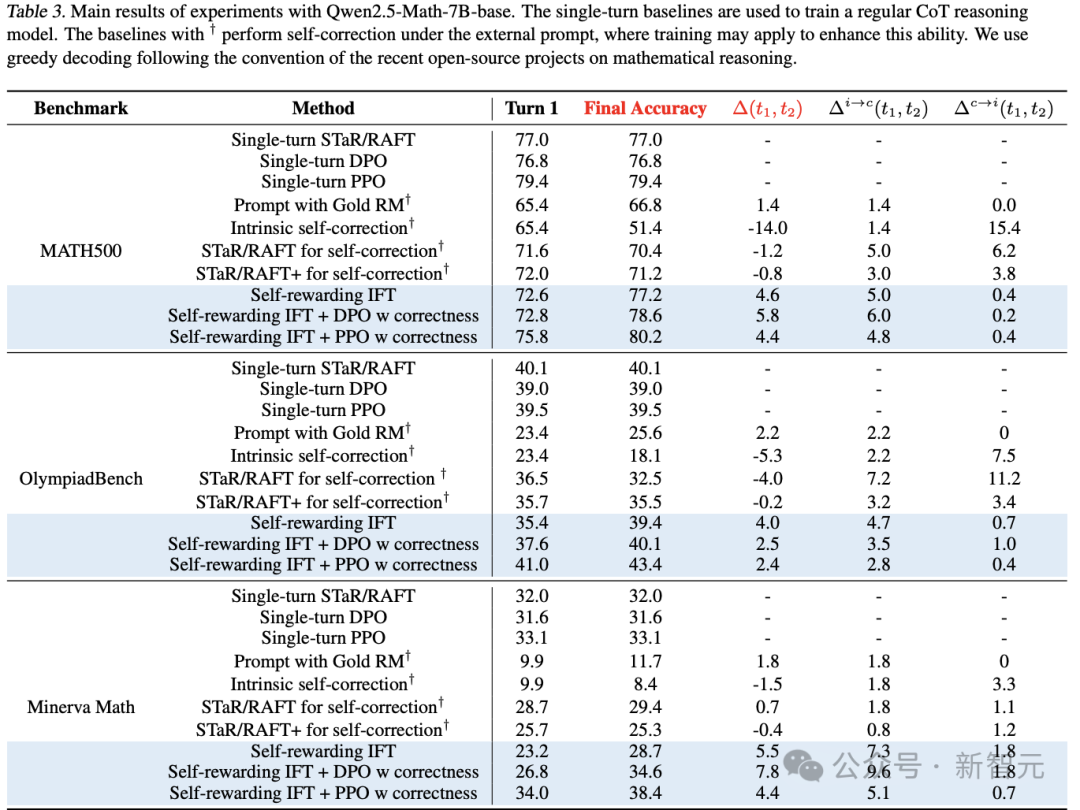
表3中报告了主要结果。需要注意的是,由于四舍五入,可能存在0.1的误差。
表3. Qwen2.5-Math-7B-base 实验的主要结果
单轮基线模型用于训练常规的CoT推理模型。带有†符号的基线模型在外部提示下执行自我修正,其中训练可能用于增强这种能力。遵循近期开源数学推理项目的惯例,使用贪婪解码方法进行评估。
内在自我修正与提示通常失败
首先观察到,在没有明确奖励信号的情况下,内在的自我修正通常会降低最终测试的准确性。
分析输出结果,发现模型倾向于修改初始响应,而不管其正确性如何,因为它们缺乏机制来确定何时应该优化答案,何时应该终止修正过程。
此外,即使提供了真实奖励,在错误到正确转换方面,仅通过提示的基础模型也只能取得微小的改进。
还注意到,STaR/RAFT方法(通过对修正的错误尝试进行微调)未能显著提升性能。
此外,在修改初始尝试时,STaR/RAFT+变体(包含正确到正确的轨迹)变得更加保守。虽然这减少了错误的修正(∆c→i(t1, t2)),但也降低了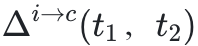 ,最终导致测试准确性下降。
这些发现与之前的研究一致,凸显了内在自我修正的局限性,即使通过训练也难以克服。
,最终导致测试准确性下降。
这些发现与之前的研究一致,凸显了内在自我修正的局限性,即使通过训练也难以克服。
新模型显著优于现有的自我修正基线方法
在所有任务中,自我奖励推理模型通过更高的∆(t1, t2)持续提升了最终准确性,优于基线方法。
注意到,在具有自我修正行为的合成轨迹上进行微调,能够显著提高模型的,这表明模型更擅长修正自我生成响应中的错误。
与STaR/RAFT不同,通过自我奖励IFT训练的模型还表现出显著更低的,表明由于额外的自我奖励信号,它们更擅长识别何时停止修正。
由于STaR/RAFT(+)和自我奖励IFT使用了相同的数据合成方法(拒绝采样),但基于不同的自我修正框架,这些结果凸显了自我奖励推理框架的优势。
新模型相比单轮基线方法提升了最终准确性
自我自我奖励推理模型(经过RL训练)还与单轮对应的模型进行了比较。
无论是PPO还是DPO,自我奖励推理模型由于额外的修正步骤,均实现了更高的最终测试准确性。
例如,自我奖励IFT + PPO模型在OlympiadBench上的最终准确性为43.4%,在Minerva Math上为38.4%,而其单轮对应模型分别为39.5%和33.1%。
同样,使用DPO的自我奖励推理模型在MATH500上达到78.6%,在OlympiadBench上为40.1%,在Minerva Math上为34.6%,而单轮DPO模型分别为76.8%、39.0%和31.6%。
然而,由于额外的修正步骤,自我奖励模型在推理过程中使用了更多的token。
深度强化学习算法优于直接对齐算法
可以观察到,PPO(近端策略优化)在性能上大幅优于迭代DPO(直接偏好优化)。
例如,经过PPO训练的模型在Olympiad Bench上的最终准确性为43.4%,而DPO方法仅为40.1%。
这表明,当绝对奖励信号可用时,强制偏好结构(如Bradley-Terry模型)可能是不必要的,甚至可能降低性能。
注意到,在实验设置中,只能为40%到60%的提示收集到比较对。
对于剩余的提示,模型要么没有生成任何正确轨迹,要么所有轨迹都是正确的。因此,DPO使用的训练数据少于PPO,这可能是其准确性较低的原因之一。
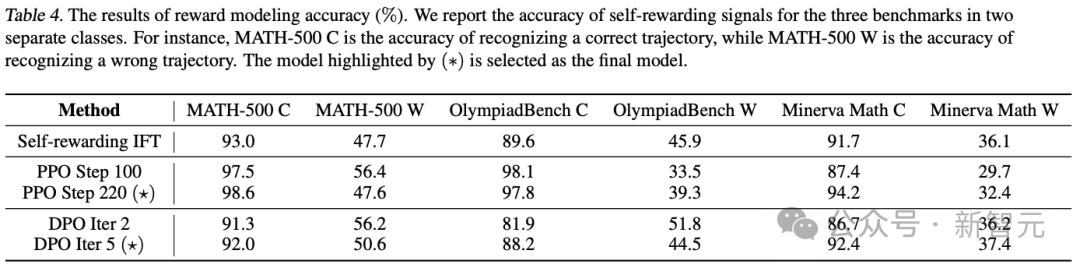
奖励模型(RM)准确性
由于自我奖励框架将生成器和奖励模型统一起来,所以评估了模型作为奖励模型的准确性。
Qwen2.5-Math-7B-base有时可能无法严格遵循格式,可能是因为模型未经过指令微调。
然而,这种情况发生的比例不到10%,因此重点关注包含评估步骤的样本,并进一步引入人工监督以总结统计数据。
在三个基准测试中,自我奖励信号在两类情况下的准确性。例如,MATH-500 C表示识别正确轨迹的准确性,而MATH-500 W表示识别错误轨迹的准确性。标有(∗)的模型被选为最终模型。
RL阶段的学习动态
尽管RL训练提高了最终准确性,但最终测试准确性由第一轮准确性(turn-1 accuracy)和∆(t1, t2)共同决定。
研究团队特别注意到,最终准确性的提升主要来自更高的第一轮准确性,因为经过RL训练的模型,通常具有更高的第一轮准确性,但同时也表现出较低的。
为了理解RL训练的学习动态,在图1中绘制了三个基准测试的测试准确性随RL训练步骤的变化情况。
研究团队观察到,在RL训练的早期阶段,第一轮准确性和最终准确性均有所提升,且它们之间的差距∆(t1, t2)也有所增加或保持稳定水平。
然而,在训练步骤达到100左右时,最终准确性的提升主要来自更高的第一轮准确性,且两者之间的差距缩小。
最初,长度有所减少,因为Qwen2.5-Math-7B-base模型倾向于生成大量Python代码,导致响应较长。
代码通常占用大量token,可能导致推理路径不完整,并且这种行为会被奖励信号抑制。
随后,生成长度在下一阶段增加,表明RL训练也鼓励了反思和自我修正能力。
最终,生成长度再次减少,同时伴随着更高的第一轮准确性和更小的∆(t1, t2)。
数据格式:简化的两轮对话框架
此前,将多个推理步骤合并为一个长的思维链(CoT)轨迹,这与常见的实践一致。
然而,这种方法对新研究提出了重大挑战,因为模型(尤其是Qwen2.5-Math-7B-base)往往无法严格遵循基于历史评估或修正响应的指令。
例如,即使自我评估结果为「[VERIFY] wrong」,模型有时仍会生成评估结果并选择是否修正响应。
此外,模型可能执行多轮自我评估和修正,但这些步骤紧密耦合,无法轻松解耦为独立的阶段。
为了解决这些问题,研究团队采用了简化的两轮对话框架,其中用户在不同步骤之间提供明确的指令。
具体而言,在接收到数学问题后,模型首先生成思维链推理a₁和自我评估y。然后,用户根据自我评估y提供一个确定性指令o:
-
由于你的初始响应自我评估为错误,上述解决方案可能因对问题的理解不足而存在错误。请修正错误(如有)并重写解决方案。将最终答案放在方框内;
-
由于你的初始响应自我评估为正确,请确认其正确性并提供进一步的修改。将最终答案放在方框内。
同时,在收集数据时,根据设计的模板,自我奖励信号直接由真实奖励(ground-truth oracle reward)确定,无需额外的推理。
尽管这种简化可能会降低奖励模型的准确性,但通过修改自我奖励信号,有助于受控实验。
Llama模型与Qwen模型实验结果几乎一致
Llama模型的实验与Qwen模型的结果高度一致。
实验表明,Llama模型表现出与Qwen模型相似的趋势。
具体而言,内在自我修正(无论是否结合类似STaR/RAFT的训练)无法可靠地修正自我生成响应中的错误。
模型倾向于修改其初始响应,而不管其正确性如何,这使得这些方法主要对较弱模型有益。
然而,对于在第一次尝试中就能解决大多数问题的较强模型,内在自我修正和STaR/RAFT方法显著降低了第二轮准确性。
相比之下,自我奖励IFT模型通过有效修正错误并保留已经正确的响应,持续提升了第一轮准确性。
为了进一步评估自我奖励IFT模型,将自我奖励信号与真实奖励(oracle reward)保持一样,以消除奖励信号质量的影响,并直接评估模型修正错误响应的能力。
新框架提高了计算扩展的效率
自我修正需要生成多个LLM响应,因此在相同的推理预算下比较模型性能至关重要。
在响应数量受限的情况下,先前的自我修正方法,通常表现不如自一致性方法。
为了解决这一问题,在按比例分配的测试计算预算下,对自我奖励修正进行分析,采样N条推理路径,并使用多数投票确定最终输出。
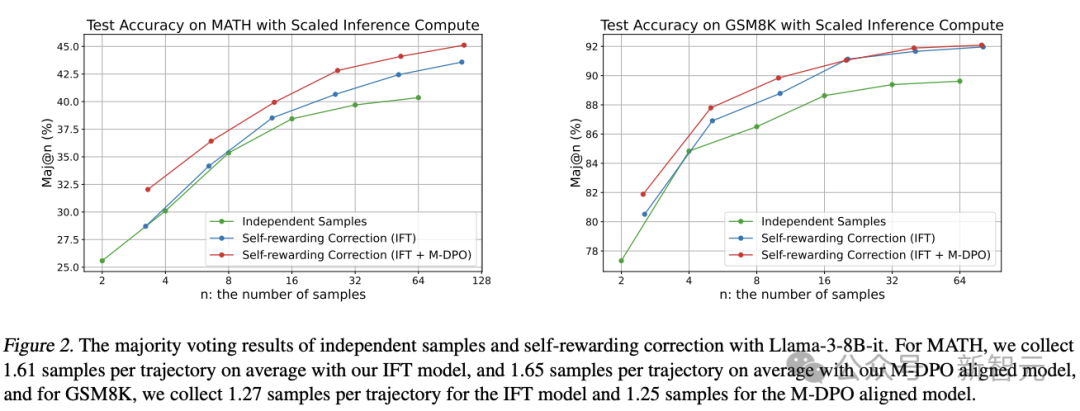
图2. Llama-3-8B-it的独立采样与自我奖励修正的多数投票结果
在实验中,对于MATH任务,IFT模型平均每条轨迹收集1.61个样本,M-DPO对齐模型平均每条轨迹收集1.65个样本;对于GSM8K任务,IFT模型平均每条轨迹收集1.27个样本,M-DPO对齐模型平均每条轨迹收集1.25个样本。
对于MATH和GSM8K任务,在固定的推理预算下,自我奖励修正模型始终优于独立采样方法。
数据分布的消融研究
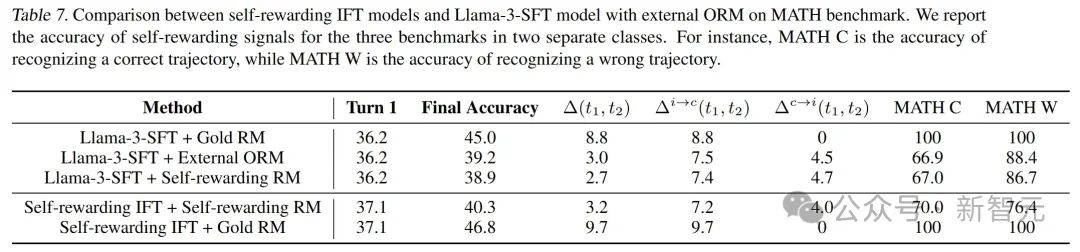
自我奖励IFT模型优于使用外部ORM的自我纠正。为了更好地理解自我奖励信号的动态,研究团队将自我奖励IFT模型与在相同数据集上训练的外部ORM(结果监督奖励模型)进行了比较,结果见下表7。
他们观察到,自我奖励IFT模型在第二轮准确性 (turn-2 accuracy)和∆(t1, t2)上均优于使用外部ORM的自我纠正方法。这凸显了将生成器和奖励模型统一于单一LLM的潜力。
然而,他们也注意到,外部ORM(用于评估Llama-3-SFT策略)和自我奖励RM(用于评估自我奖励IFT策略)在奖励模型准确性上存在显著差距。
具体来说,自我奖励IFT方法(自我奖励IFT策略+自我奖励RM)在识别正确轨迹时的准确率为70.0%,略高于Llama-3-SFT策略+外部ORM的66.9%。
但对于错误答案的轨迹,自我奖励IFT模型的准确率为76.4%,远低于Llama-3-SFT策略+外部ORM的88.4%。
为了深入探究这一差异,他们使用自我奖励RM来指导Llama-3-SFT策略的自我纠正。
有趣的是,在这种设置下,Llama-3-SFT 的奖励模型准确性与外部ORM更为接近,这表明可能存在分布外 (OOD) 问题。
具体而言,在自我奖励IFT阶段,策略从Llama-3-SFT转变为自我奖励IFT策略,而奖励模型是在原始Llama-3-SFT策略生成的数据上训练的。
此外,即使使用自我奖励RM和外部ORM评估相同的Llama-3-SFT策略,也观察到自我奖励训练略微降低了奖励模型的能力,这主要归因于模型容量的限制。
RL训练中的额外规则设计
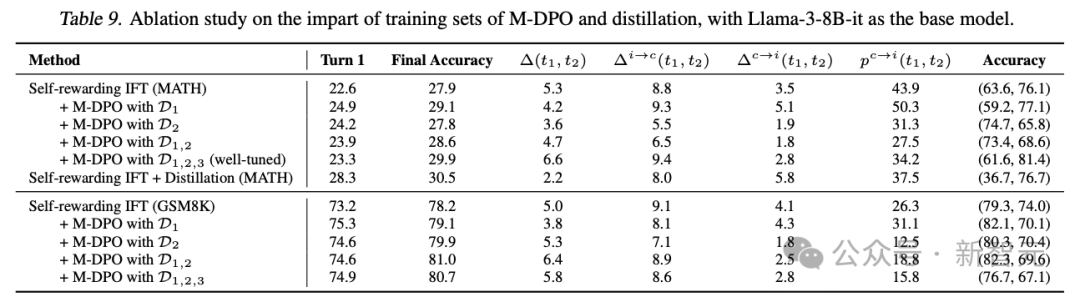
研究团队还对下列策略进行了初步实验,以分析它们对模型性能的影响。
对于固定的(x, a₁),研究团队尝试了以下排序策略:
为了简化实验,仅对模型进行了一次迭代训练。结果如表9所示。
表9. 使用Llama-3-8B-it作为基础模型,对M-DPO和蒸馏训练集影响的消融研究。
在不同的基础模型和任务中,观察到模型在将正确的初始答案错误分类为错误时更加保守。因此,经过M-DPO微调的模型显著降低了。
相应地,M-DPO方法进一步增强了自我奖励推理语言模型,提高了第二轮准确性和∆(t1, t2)。有趣的是,尽管训练过程中并未明确涉及a₁的生成,但第二轮中的修正能力自然迁移,从而提高了第一轮准确性。
然而,当超过某个阈值时,过低的可能使模型过于保守,最终降低修正率。
这一点在使用仅D_M-DPO²的实验中得到了验证,其中在MATH任务中从8.8%降至5.6%。相反,使用D_M-DPO¹进行训练会鼓励模型修改其初始响应,表现为更高的p_c→i(t1, t2),并略微增强了修正能力。
在GSM8K任务中,使用D_M-DPO¹训练的模型的有较低的,这主要是由于奖励模型准确性较低和第一轮准确性较高所致。
如果考虑修正轨迹的比例,自我奖励IFT实现了45.9%,而M-DPO对齐模型略优于它,达到46.4%。
此外,结合D_M-DPO¹和D_M-DPO²通常能产生接近最优的结果,通过使模型更清楚何时修改其初始响应来达到平衡。
DPO训练无法一致提升奖励模型准确性
在实验过程中,研究人员观察到M-DPO训练也会改变a₁的生成分布,从而不可预测地影响奖励模型的准确性。
尽管在D_M-DPO³中包含了比较对,并尽力调整该数据集中的数据组合,但仍然面临正确答案识别性能下降的问题。
此外,对于简单的平衡D_M-DPO³(例如在GSM8K中),两类奖励模型的准确性都变得更差。
无论是哪种情况,奖励模型的准确性并未得到一致提升。
怀疑这是由于DPO隐式奖励(log π/π_ref)与采样概率log π之间的不匹配所致。
同样,对于PPO训练,可能也需要采用多轮设计,而新研究仅对部分响应施加KL正则化,并允许模型更容易地调整自我奖励阶段。
还研究了PPO训练中不同的奖励信号设计,旨在增强自我修正能力,特别是在训练的后期阶段。
-
如果第一次尝试错误且最终答案正确,则分配1.5的奖励;否则,最终答案正确分配1.0,错误分配0.0。
-
将学习分为两个阶段。在第一阶段,我们仅使用基于正确性的奖励进行训练;然后从第一阶段初始化模型,并应用第一种方案中的修改奖励分配。
研究人员观察到,模型很容易利用第一种奖励设计中的漏洞,即它们故意在第一次尝试中预测错误答案,然后在第二轮中修正它。
尽管简单的奖励修改失败了,但预计更复杂的多轮RL策略可以进一步改进RL训练。
Wei Xiong
目前,Wei Xiong是伊利诺伊大学厄巴纳-香槟分校(UIUC)计算机科学博士生。
2023年8月,他从香港科技大学获数学硕士学位;2021年,从中国科学技术大学获数学与电子工程双学士学位,其中统计专业绩点第一,电子工程排名第二。
他的研究兴趣主要集中在基于人类反馈的强化学习(RLHF),用于对齐大型语言模型。
Chenlu Ye

她是伊利诺伊大学厄巴纳-香槟分校(UIUC)计算机科学博士生。
2024年8月,她从香港科技大学获人工智能与信息处理(IIP – AI)硕士(MPhil)学位。她从中国科学技术大学获得统计学学士学位。
Hanning Zhang

伊利诺伊大学厄巴纳-香槟分校(UIUC)计算机科学硕士一年级学生,导师是张彤教授。
2024年毕业于香港科技大学(HKUST),主修计算机科学。曾担任张彤教授指导下的研究实习生,研究主题LLM幻觉和对齐。2023年夏季,在Blender Lab担任研究实习生,导师是季恒教授。
研究兴趣包括自然语言处理(NLP)和大模型(LLMs)。对LLM对齐有广泛的兴趣。正在研究数学推理的奖励建模。过去还研究过LLM幻觉。
(文:新智元)