
简介
在本研究中,我们针对多模态大语言模型(MLLM)在辨识微小视觉信息时的局限性,提出了一套无需额外训练的“可视化干预”方法,巧妙地挖掘并利用模型自身的内部知识(注意力与梯度信息),从而提升模型对小尺度目标的感知能力。
具体而言,我们设计了三种自动裁剪方案,分别根据模型内在的注意力分布、梯度对目标位置的敏感性,以及组合利用这两类内部信号来确定最具辨识度的局部区域。在推理过程中,这些方法会围绕模型潜在的关注焦点动态地产生更“聚焦”的视图,帮助模型在回答视觉问题时忽略干扰并放大关键细节。
有趣的是,这些裁剪策略并不依赖针对性的数据标注或额外训练:它们仅依据模型原生的注意力机制和梯度反馈,即可更精准地定位微小目标所在。如此一来,我们不仅保留了通用型 MLLM 在海量数据中学习到的知识,还能在关键任务(如医学图像分析、安全监控等)中显著减少漏检小目标带来的风险。
我们在多项视觉问答基准上对该方法进行评估,结果表明,裁剪后的图像能够让 MLLM 在区分细微目标时表现更为准确和稳定,且这一增益在对小尺度目标尤其敏感的数据集上最为显著。
总而言之,这些训练无关的可视化干预手段充分利用了 MLLM 内在的多模态表征能力,为解决视觉细节缺失和小目标识别不佳的问题提供了一条灵活、高效且通用的新思路。

论文链接:
https://arxiv.org/abs/2502.17422
https://github.com/saccharomycetes/mllms_know

MLLMs 对大小物体感知的敏感度
在这一部分,我们主要探究多模态大语言模型在面对不同大小的视觉目标时,是否会对小尺度信息“视而不见”。
我们选取了 TextVQA 数据集作为切入点:该数据集中每个问题都有对应的真实边界框,标注了提供正确文字答案的具体位置。我们依据边界框占整张图片的相对面积,将验证集划分为“小”“中”“大”三类,观察模型在不同大小视觉概念上的识别准确度。
直觉上,如果模型的感知能力与目标大小无关,它在这三种场景中的表现应该相差无几。
但实验结果却显示,无论是零样本推理模型(如 BLIP-2、InstructBLIP)还是经过 TextVQA 训练的模型(如 LLaVA-1.5、Qwen-VL),它们对小目标的准确率都显著低于大目标,就连最新商业模型 GPT-4o 也不能幸免,足见其对小尺度视觉细节依旧存在偏差。
为了进一步确认“小尺度”是否真的是模型无法识别小目标的因果原因,我们还进行了额外的“干预实验”:在输入原始图像的同时,我们把包含正确答案位置的最小正方形区域截取出来、放大到模型可接受的分辨率,再与原始图像共同输入到模型中。这样一来,我们就能直接测量“专注裁剪”对识别效果的影响。
结果显示,特别是在小目标场景下,模型准确率都有了相当明显的提升;而在大目标场景下,这种改进相对较弱。这不仅印证了小视觉概念的存在确实会“压制”模型的识别能力,也表明简单而直接的图像裁剪方法就能在很大程度上缓解这一问题。
通过这些实验,我们得以更深入地了解 MLLM 的视觉感知局限,为后续改进小目标感知提供了思路。

▲ 表1: 在 TextVQA 任务中,MLLM 的准确率对视觉目标的大小极其敏感:当答案区域在图像中的相对面积逐渐缩小(从右到左),未裁剪的模型表现明显下降;而采用人工裁剪(human-CROP)后,小目标的识别准确率可显著提升。

重要发现:即使回答错误,多模态大模型的注意力位置仍然精准
在本部分,我们探讨多模态大语言模型在视觉问答时,是否能准确找到图像中的关键区域。小目标识别不佳通常有两种可能:要么模型无法顺利定位到小目标,要么虽然知道位置却无法精确识别细节。我们观察到,模型即便回答错误,依然常常关注到目标周边,说明它们确实“知道”该往哪儿看,但缺乏对局部细节的充分感知能力。
为量化这种情况,我们从 MLLM 的跨注意力机制入手:提取“答案到图像 token” 的注意力,再结合“图像 token 到图像区域”的注意力,生成对各图像区域的综合关注度。
考虑到模型也会对某些“注册”或全局信息产生注意,我们提出“相对注意力”概念,将回答问题时的注意力值与模型对同张图片进行“通用描述”时的注意力值进行对比,以突出与答题真正相关的部分。
在 TextVQA 数据集上的实验证明,无论模型回答是否正确,其对包含答案的边界框都维持较高注意力比率。这提示 MLLM 定位能力并非主要瓶颈,真正的挑战在于它们对小尺度特征的精细识别能力。

▲ 图1:在本图中,我们展示了 MLLM 在不同网络层的注意力比率(基于 TextVQA 的平均值,带 95% 置信区间)。该比率用于衡量模型对真实答案边界框的关注程度。结果显示,在多数网络层中,该比率都大于 1,意味着即便模型未能正确回答,也能聚焦到图像中与答案相关的关键区域。

VICROP方法
在前面章节的研究中,我们发现 MLLM 对于小尺度目标的“聚焦”能力并不差,真正的问题在于其难以清晰辨别小目标的细节。因此,本节提出一种无需额外训练的图像裁剪方法(ViCrop),以充分利用模型内部的注意力和梯度线索,实现自动化的“放大镜”式细节解析。
具体来说,我们先让模型处理一张图像与问题,提取其关键的关注区域。具体来讲,Relative Attention ViCrop(rel-att)方法通过获取模型对“回答问题”与“通用描述”这两种场景的注意力差异,锁定与问题语义最相关的图像部位。
Gradient-Weighted Attention ViCrop(grad-att)则借助模型输出分布对注意力进行梯度加权,以筛除无关的注意力热点;Input Gradient ViCrop(pure-grad)更直接地利用模型对原始图像像素的梯度,找出视觉中最能影响决策的细节区域。
这些方法均会输出裁剪后的“放大图”,并与原图一同输入模型,从而让 MLLM 对关键部位做更精细的分析。具体细节请见论文以及代码。
为将这些注意力或梯度图自动转化为可用裁剪框,我们借鉴目标检测的思路,通过多种不同大小的滑窗在整幅图像上移动,寻找在“高关注度”区域上得分最高的位置;再结合基于邻域变化的启发式策略,选出最能平衡“大而全”和“小而聚焦”的最佳窗口。
针对超高分辨率图像(如大于 1K 的场景),我们采用“两阶段”方案:先将大图分块计算关注图,再拼接回原图后选取裁剪区域。
最后,我们将裁剪后的“局部放大版”与原图共同输入模型。这样,一方面可充分保留全局信息,另一方面也能让模型更好地“看清”微小细节。

▲ 图2: ViCrop 帮助 MLLM 纠正错误的示例(青色边界框显示 ViCrop 裁剪的区域)
我们将所提出的 ViCrop 方法应用于两款开源 SOTA 多模态大语言模型(InstructBLIP 和 LLaVA-1.5),并在 7 个数据集上验证了它们在“看清”小目标时的改进成效。
结果显示,ViCrop 无需任何额外训练,就能显著提高模型在细节敏感型数据集(例如 TextVQA、V*)上的回答准确率;同时,对主要包含大目标的通用数据集(如 GQA、AOKVQA、VQAv2),也几乎不会造成性能下降。
特别值得关注的是,LLaVA-1.5 在裁剪后收获的提升幅度更明显,或与其针对视觉 token 进行更深入的模型调优有关。总体来看,ViCrop 在推理阶段提供了一个简单而高效的“小目标放大镜”方案,为解决 MLLM 在小尺度识别任务中的局限带来了新的思路。
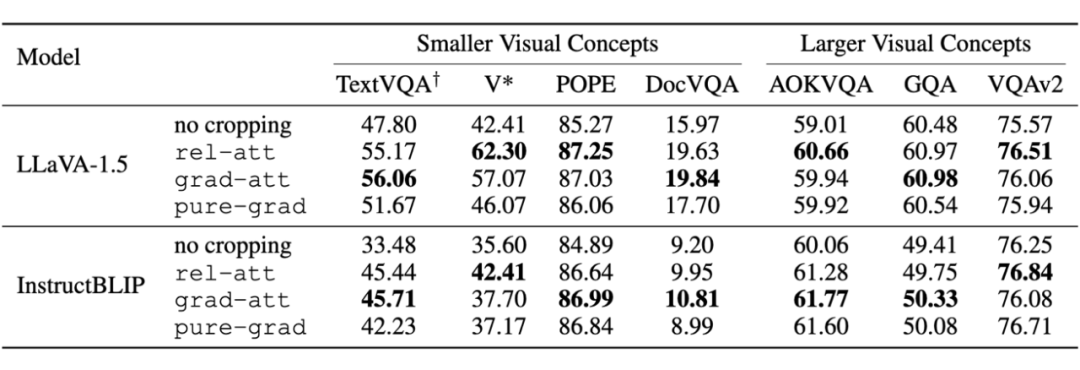
▲ 表2:ViCrop 应用于两个主流 MLLM,在不同 benchmark 下的表现
(文:PaperWeekly)


