

1993 年,英特尔发布了高性能的 Pentium 处理器,也是历史悠久的 Pentium 系列处理器的开端。Pentium 比之前的英特尔 486 处理器有很多改进,其中之一是更快的浮点除法算法。一年后,数论教授 Nicely 教授在研究孪生素数的倒数时发现了一个问题:他的 Pentium 芯片在执行浮点除法时有时会产生错误的结果。英特尔本来认为这是“一个非常小的技术问题”,但令他们惊讶的是,这个漏洞成为了媒体的头条新闻。受到数周的批评、嘲笑和负面宣传后,英特尔同意更换所有有问题的 Pentium 芯片,这家公司因此损失了 4.75 亿美元。
在本文中,我会讨论 Pentium 的除法算法,指出漏洞在 Pentium 芯片上的什么位置,仔细研究芯片电路,并解释问题成因。简而言之,除法算法使用了一个查找表。1994 年,英特尔声称该漏洞的原因是脚本错误导致表中遗漏了 5 个条目。但我的分析表明,由于查找表定义中的数学错误,遗漏的条目实际上有 16 个。其中 5 个缺失条目触发了该漏洞(也称为 FDIV 漏洞,以浮点除法指令“FDIV”命名),而另外 11 个缺失条目则没有影响。

这张 Pentium 芯片的照片显示了 FDIV 漏洞的位置。
虽然 Nicely 教授引发了人们对 FDIV 漏洞的关注,但他并不是第一个发现它的。1994 年 5 月,英特尔对 Pentium 的内部测试显示,浮点除法非常偶然时会出现轻微的误差。由于只有 90 亿分之一的值会导致此问题,因此英特尔认为问题微不足道:“这甚至不能算作错误。” 尽管如此,英特尔还是悄悄修改了 Pentium 电路以解决此问题。
几个月后,也就是 10 月,Nicely 注意到他的素数计算结果有误。他很快确定 1/824633702441 在三台不同的 Pentium 计算机上都是错误的,但他的旧计算机给出了正确答案。他打电话给英特尔技术支持,但遭到了拒绝,因此 Nicely 向十几家计算机杂志和个人发送了有关该错误的邮件。收件人之一是《没有文档的 DOS》的作者 Andrew Schulman。他将电子邮件转发给了 DOS 软件工具公司的联合创始人 Richard Smith。Smith 将电子邮件发布在 Compuserve 论坛上,这是 20 世纪 90 年代的社交媒体。
《电子工程时报》的一名记者发现了 Compuserve 的帖子,并在 11 月 7 日的期刊上撰写了有关 Pentium 漏洞的文章:英特尔修复了一个 Pentium FPU 故障。在文章中,英特尔解释说,漏洞出在芯片的一个组件 PLA(可编程逻辑阵列)中,该组件充当除法运算的查找表。英特尔已经修复了最新 Pentium 处理器中的漏洞,并将为相关客户更换有故障的处理器。
问题可能已经悄然结束,但英特尔决定限制可以获得替换品的客户数量。如果客户无法说服英特尔工程师他们需要精确度,他们就无法获得修复后的 Pentium 处理器。用户对只能继续用有故障的芯片而感到愤怒,因此他们将投诉提交给了 comp.sys.intel 等在线群组。11 月 22 日,当 CNN 报道该漏洞时,争议蔓延到了线下世界。随着报纸开始报道该漏洞,以及英特尔成为脱口秀节目的笑柄,公众对 Pentium 漏洞的认识加深了。
12 月 12 日,IBM 宣布停止销售 Pentium 计算机,英特尔陷入了困境。12 月 19 日,在 Nicely 首次报告该漏洞后不到两个月,英特尔屈服了,并宣布将为所有客户更换有问题的芯片。此次召回使英特尔损失了 4.75 亿美元(按当前币值计算超过 10 亿美元)。
与此同时,工程师和数学家正在分析该漏洞,其中包括设计浮点单元的工程师 Tim Coe。值得注意的是,通过研究 Pentium 的错误除法,Coe 对 Pentium 的除法算法进行了逆向工程,并找出了它出错的原因。Coe 和其他人撰写了论文,描述了 Pentium 漏洞背后的数学原理。但到目前为止,还没有人展示该漏洞是如何在物理芯片本身中实现的。
现在我将回顾一些有关浮点数的重要事项。二进制数可以有小数部分,类似十进制数。例如,二进制数 11.1001 在二进制小数点后有四位数字。二进制小数点后的第一个数字表示 1/2,第二个数字表示 1/4,依此类推。因此,11.1001 对应于 3 + 1/2 + 1/16 = 3.5625。这样的“定点”数可以表示小数值,但其范围有限。
另一方面,浮点数包括了非常大的数字,例如 6.02×10^23,也包括非常小的数字,例如 1.055×10^−34。在十进制中,6.02×10^23 的有效数字(或尾数)为 6.02,乘以 10 的幂,指数为 23。在二进制中,浮点数的表示方式类似,也有有效数字和指数,只是有效数字乘以 2 的幂(而不是 10)。
计算机很早就开始就使用浮点数了,尤其是在科学计算场景中。多年来,不同的计算机对浮点数使用了不兼容的格式。最终,当英特尔开发出 8087 浮点协处理器芯片(与 8086/8088 处理器搭配)时,一个标准出现了。该芯片的特性在 1985 年成为标准 (IEEE 754)。随后,包括 Pentium 在内的大多数计算机都根据此标准实现浮点数。基本算术运算的结果应该精确到有效数字的最后一位。不幸的是,Pentium 处理器上的除法精度有时要差很多。
计算机如何执行除法?简单的方法类似于小学长除法,只是用的是二进制。这种方法用于英特尔 486 和更早的处理器,但过程很慢,商的每个位都需要一个时钟周期。Pentium 处理器使用一种称为 SRT 10 的新方法,以四进制执行除法。因此,SRT 每一步生成两位商,所以除法速度快一倍。我将用十进制示例简要解释 SRT;严格的解释在网上很容易找到。
下图展示了十进制长除法,并标明了重要部分。被除数除以除数,得到商。在长除法算法的每一步中,你都会生成商的另一位数字。然后将除数(1535)乘以商数(2),并从被除数中减去该数,得到部分余数。将部分余数乘以 10,然后重复该过程,每一步生成一个商数和一个部分余数。下图在两个商数之后停止,但你可以继续计算以获得所需的精度。
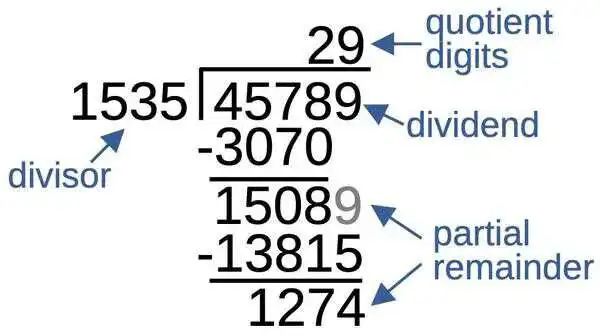
十进制除法的重要部分。
请注意,除法比乘法更难,因为没有简单的方法可以确定每个商数。你必须估计一个商数,将其乘以除数,然后检查商数是否正确。例如,你必须仔细检查 1535 能除以 4578 两次还是三次。
SRT 算法通过一种不寻常的方法简化了选择商数的运算:它允许商中有负数。这种改变让商数不需要那么精确。如果你选择的商数有点太大,则可以将负数用作下一位:这将抵消太大的数位,因为下一个除数将被添加而不是减去。
下面的示例显示了其原理。假设你选择 3 而不是 2 作为第一个商数。由于 3 太大,这一步的余数为负数(-261)。在一般的除法运算中,你需要使用不同的商数重试。但使用 SRT 时,你可以继续,在下一步中使用负数(-1)作为商数。最后,正数和负数的这些商可以转换为标准形式:3×10-1 = 29,与之前的商相同。

以 10 为基数的除法,使用负商数。结果与上例相同。
SRT 算法的一个优点是,由于商数只需接近,因此可以使用查找表来选择商数。具体来说,部分余数和除数可以截断为几位,这样查找表就不会那么大了。在此示例中,你可以将 1535 和 4578 截断为 15 和 45,该表显示 15 除 45 是 3,你可以使用 3 作为商数。
Pentium 不使用十进制,而是使用四进制的 SRT 算法:两位一组。因此,Pentium 上的除法比标准二进制除法快一倍。使用四进制 SRT 时,每个商数位可以是 -2、-1、0、1 或 2。在硬件中,乘以这些值都非常容易,因为乘以 2 可以通过位移位来完成。基数为 4 的 SRT 不需要 -3 或 3 的商数;这很方便,因为乘以 3 有点困难。总而言之,基数为 4 的 SRT 比常规二进制除法快一倍,但它需要更多的硬件:查找表、用于加或减 1 或 2 的倍数的电路以及将商转换为标准形式的电路。
SRT 查找表的目的是提供商数。也就是说,该表将部分余数 p 和除数 d 作为输入并提供适当的商数。正如 1994 年的人们解释的那样,Pentium 的查找表是除法错误的源头。该表缺少五个条目;如果 SRT 算法访问其中一个缺失的条目,它将生成错误的结果。在本节中,我将讨论查找表的结构并解释出了什么问题。
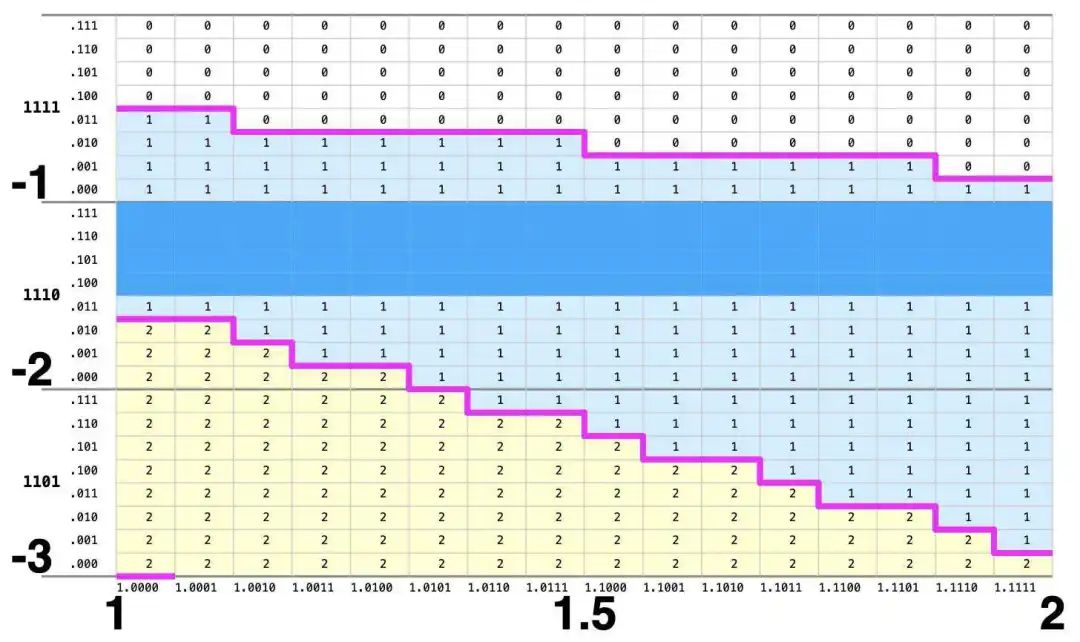
Pentium 的查找表包含 2048 个条目,如下所示。该表有五个区域,分别对应商数字 +2、+1、0、-1 和 -2。此外,表的上部和下部区域未使用(由于 SRT 的数学原理)。未使用的条目填充了 0,这非常重要。特别要注意的是,五个红色条目需要包含 +2,但却错误地填充了 0。
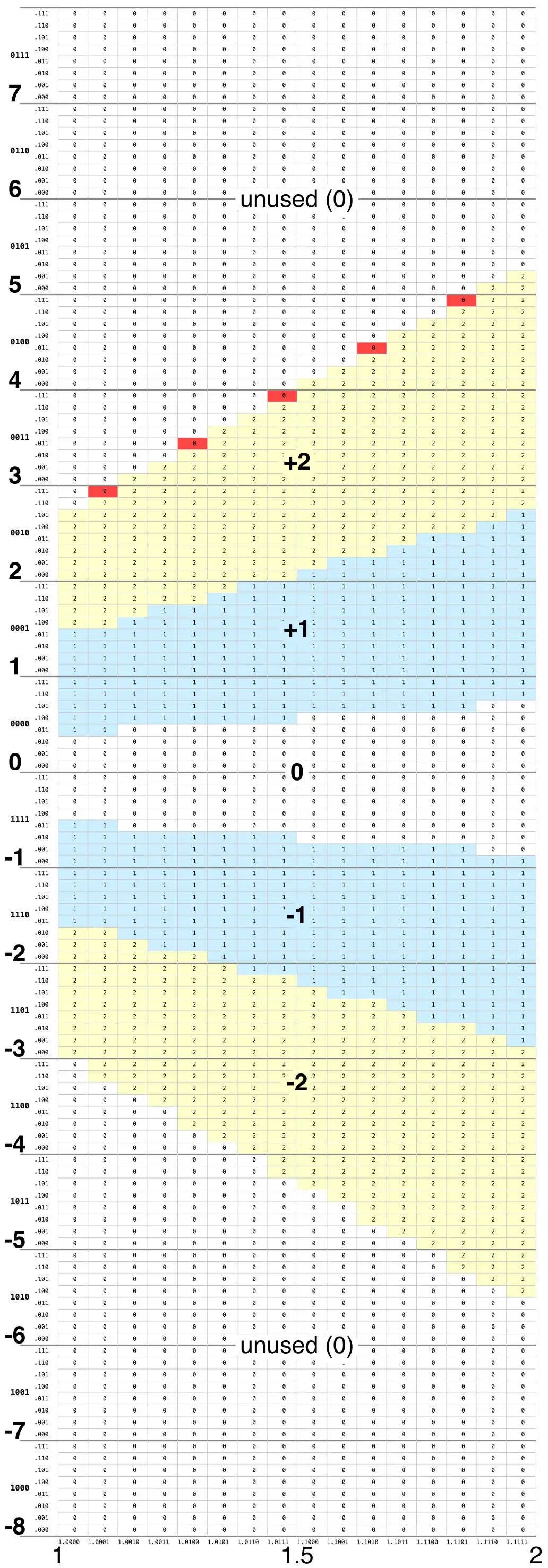
Pentium 用于除法的 2048 条目查找表。除数沿 X 轴,从 1 到 2。部分余数沿 Y 轴,从 -8 到 8。
当 SRT 算法使用上述表格时,部分余数 p 和除数 d 是输入。除数(缩放到 1 和 2 之间)为表格提供 X 坐标,而部分余数(在 -8 和 8 之间)提供 Y 坐标。表格坐标的细节很重要,所以我将详细介绍。要选择一个单元格,除数(X 轴)被截断为 5 位二进制值 1.dddd。(由于除数的第一位始终为 1,因此在表格查找中将其忽略。)部分余数(Y 轴)被截断为 7 位有符号二进制值 pppp.ppp。索引到表格中的 11 位意味着表格包含 2^11(2048)个条目。部分余数以 2 的补码表示,因此值 0000.000 到 0111.111 是从 0 到(几乎)8 的非负值,而值 1000.000 到 1111.111 是从 -8 到(几乎)0 的负值。
在本节中,我将解释如何在 Pentium 的硬件中实现查找表。查找表有 2048 个条目,因此可以将其存储在具有 2048 个两位输出的 ROM 中。11(由于商数符号与部分余数符号相同,因此符号未显式存储在表中。)但是,由于该表结构严谨(且大部分为空),因此可以更紧凑地存储在一个称为可编程逻辑阵列(PLA)的结构中。通过使用 PLA,Pentium 处理器将表存储在 112 行而不是 2048 行中,从而节省了大量空间。即便如此,PLA 在芯片上的体积也足够大,如果你眯起眼睛看,肉眼就可以看到它。
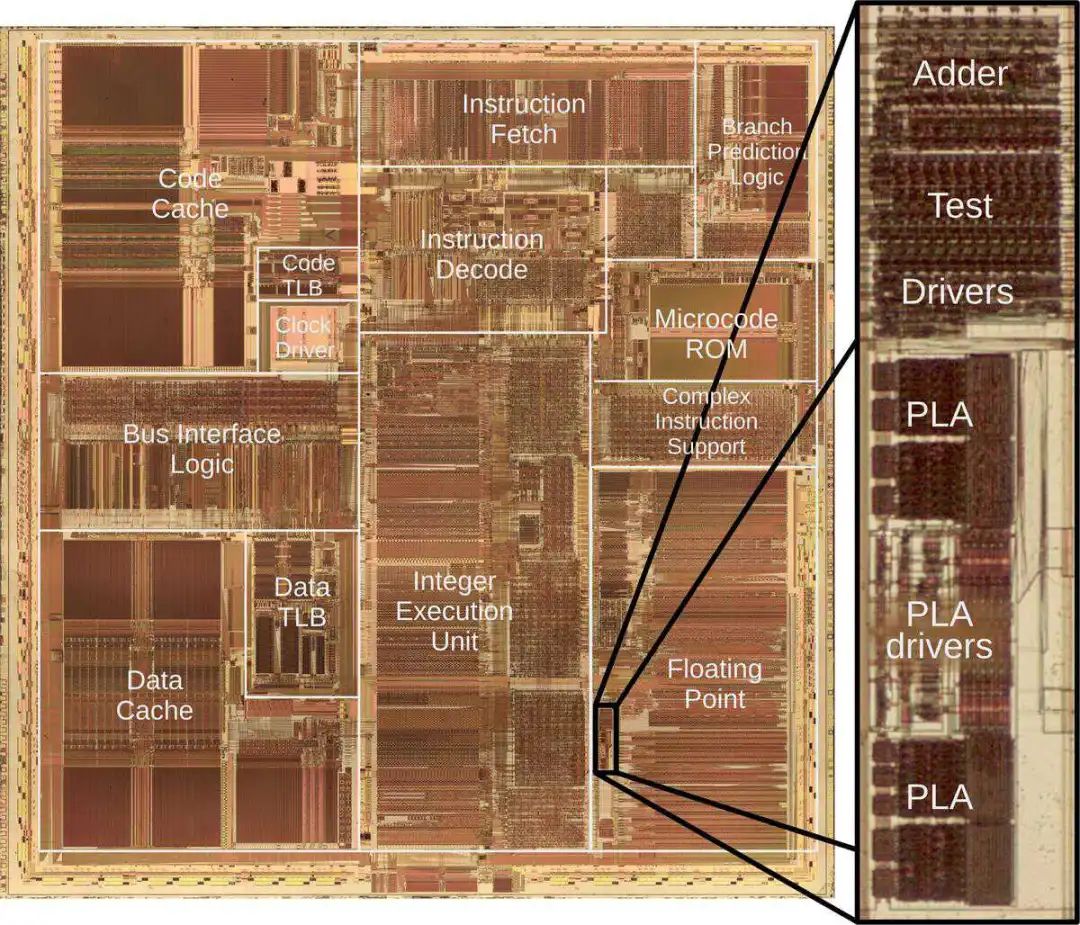
放大 Pentium 芯片上的 PLA 和相关电路。
PLA 的理念是提供一种密集且灵活的方式来实现任意逻辑函数。任何布尔逻辑函数都可以表示为“乘积之和”,即一组通过“或”运算(求和)在一起的 AND 项(乘积)。PLA 有一个称为 AND 平面的电路块,用于生成所需的和项。AND 平面的输出被馈送到第二个块,即 OR 平面,该平面将这些项进行“或”运算。AND 平面和 OR 平面被组织为一个网格。每个网格点可以有或没有晶体管,定义各种逻辑函数。关键在于,通过在网格中放置适当的晶体管模式,你可以创建任何函数。对于除法 PLA,有 22 个输入(除数和部分余数索引中的 11 位,以及它们的补码)和两个输出,如下所示。
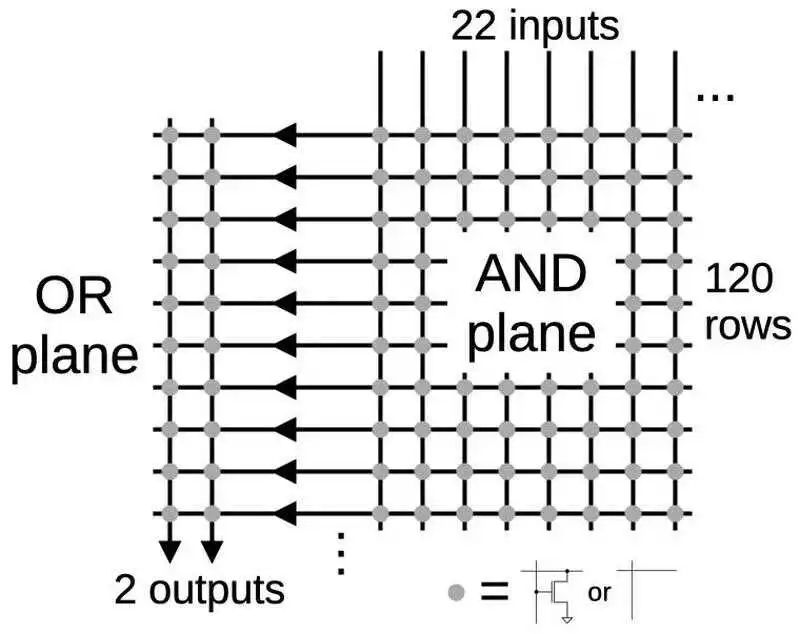
除法 PLA 的简化图。
如果函数结构允许用少量项来表达,则 PLA 比 ROM 更紧凑。PLA 的一个难点是弄清楚如何用最少的项来表达函数,以使 PLA 尽可能小。事实证明,这个问题通常是 NP 完备的。英特尔使用一个名为 Espresso 的程序通过启发式方法生成紧凑的 PLA。
下图显示了 Pentium 中的除法 PLA。PLA 有 120 行,分成两个 60 行的部分,中间有支持电路。11 个表输入位进入中间的 AND 平面驱动器,产生 PLA 的 22 个输入(每个表输入及其补码)。AND 平面晶体管的输出经过输出缓冲器并馈入 OR 平面。OR 平面的输出经过中心的额外缓冲器和逻辑,产生两个输出位,表示 ±1 或 ±2 商数。下图展示了修复该错误的更新后的 PLA;出故障的 PLA 长得差不多,只是晶体管模式不一样。特别要注意的是,更新后的 PLA 在底部有 46 个未使用的行,而原始故障 PLA 有 8 个未使用的行。

这块 PLA 已移除了金属层来展示电路。此图显示了更新后的 Pentium 中的 PLA,因为这张照片效果更好。
下图显示了 PLA 的 AND 平面的一部分。在网格中的每个点,晶体管可以存在或不存在。一行中晶体管的模式决定了该行的逻辑项。垂直的 doped silicon(绿色)接地。垂直的 polysilicon(红色)由输入位模式驱动。如果 polysilicon 穿过 doped silicon,则会形成一个晶体管(橙色),当激活时会将该行拉出来。有一条 metal line 连接一行中的所有晶体管行以产生输出;图中大部分 metal 已被去除,但在右侧仍可见一些。
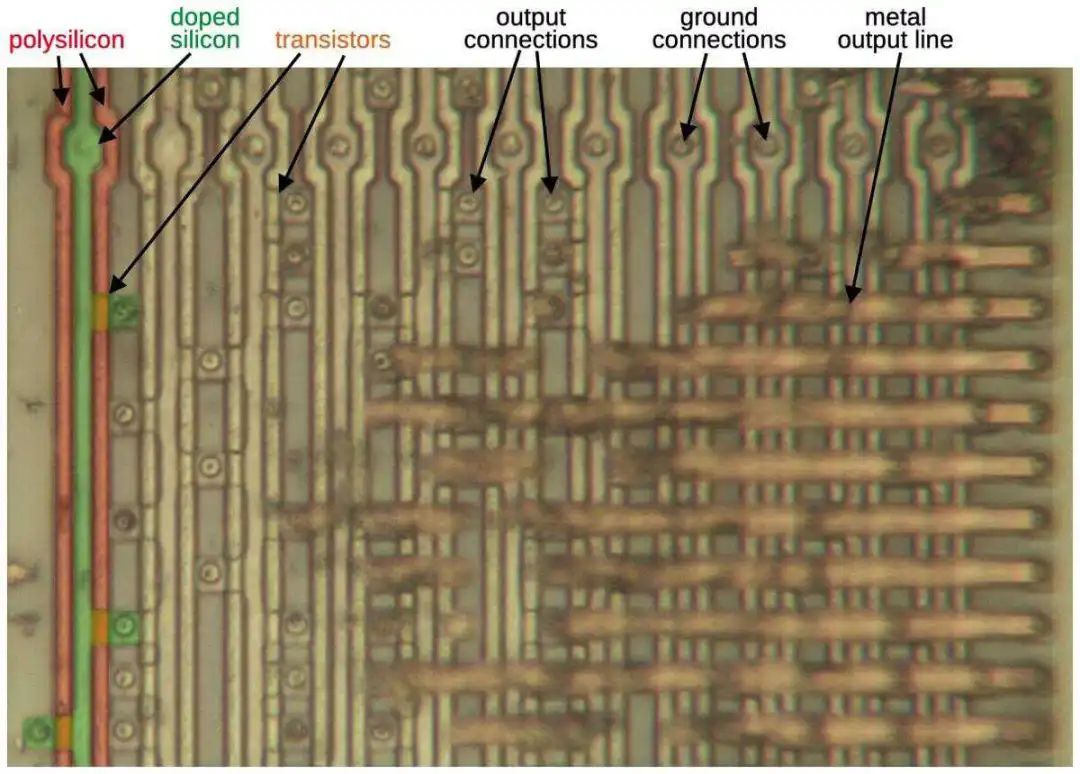
Pentium 中的 AND 平面的一部分。我分别将第一条 silicon 和 polysilicon 涂成绿色和红色。
在显微镜下仔细检查 PLA 后,我提取了 PLA 网格中的晶体管图案。从晶体管图像中,我可以确定每个 PLA 行的方程式,然后生成查找表的内容。请注意,PLA 中的晶体管不直接映射到表内容(与 ROM 不同)。因此,没有与 5 个缺失表条目相对应的晶体管的具体位置。
PLA 的左侧实现 OR 平面(下图)。OR 平面确定行输出产生的商是 1 还是 2。OR 平面相对于 AND 平面成 90° 方向:输入是水平 polysilicon(红色),而输出线是垂直的。与之前一样,晶体管(橙色)形成在 polysilicon 与 doped silicon 的交叉处。奇怪的是,每个 OR 平面都有四个输出,而 PLA 本身有两个输出。
PLA 的 OR 平面的一部分。我移除了金属层以显示底层的 silicon 和 polysilicon。我画了接地线和输出线,显示了金属线的位置。
接下来,我将精确展示 AND 平面如何生成一个项。对于除法表,输入是 7 个部分余数位和 4 个除数位,如前所述。我将部分余数位称为 p6p5p4p3.p2p1p0,将除数位称为 1.d3d2d1d0。这 11 位及其补码会垂直输入 PLA,如下图顶部所示。这些线是 polysilicon,因此它们将形成晶体管栅极,在激活时打开相应的晶体管。底部的箭头指向第一行中的九个晶体管。(很难分辨 polysilicon 是经过 doped silicon 还是经过 silicon 上方,因此晶体管并不都很明显。)查看晶体管及其输入可发现 PLA 中的第一个项由 p0p1p2p3p4’p5p6d1d2 生成。
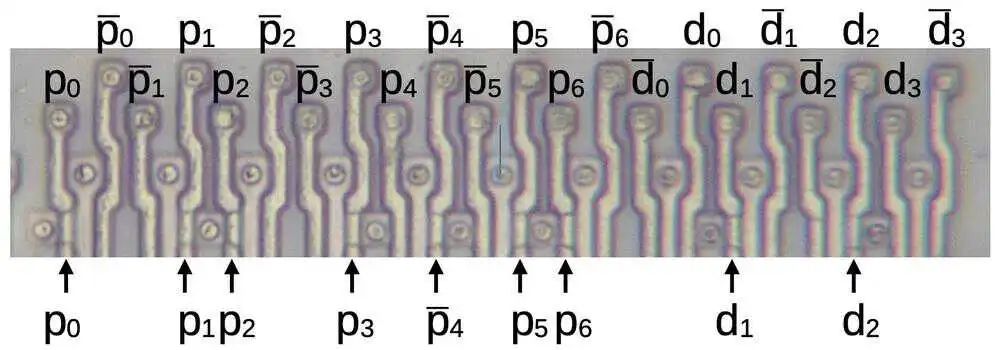
出错 Pentium 芯片中的 PLA 的第一行。
下图是一个查找表的特写,显示了此 PLA 行如何将值 1 分配给四个表格单元格(深蓝色)。你可以将 PLA 的每个项视为与二进制模式的模式匹配,该模式可以包含“无关”值。第一个 PLA 项(上图)与模式 P=110.1111, D=x11x 匹配,其中“无关”的 x 值可以是 0 或 1。由于一个 PLA 行可以实现多个单元格,因此 PLA 比 ROM 更高效;PLA 只需 112 行,而 ROM 需要 2048 行。
PLA 中的第一个条目将值 1 分配给四个深蓝色单元格。
从几何学上讲,你可以将每个 PLA 项(行)视为覆盖表格中的一个或多个矩形。但是,矩形不能是任意的,而必须在位边界上对齐。请注意,表格边界(洋红色)中的每个“凸起”都需要一个单独的矩形,因此需要一个单独的 PLA 行。(这在后面很重要。)
如果区域恰好对齐,PLA 行可以生成一个大矩形,一次填充许多表格单元格。例如,PLA 中的第三项匹配 d=xxxx,p=11101xx。这个 PLA 行有效地填充了 64 个表格单元格(如下所示),取代了 ROM 中所需的 64 行。
PLA 中的第三项将值 1 分配给 64 个深蓝色单元格。
总而言之,PLA 中的晶体管模式实现了一组方程,这些方程定义了表格的内容,并根据需要将商设置为 1 或 2。尽管表格有 2048 个条目,但 PLA 仅用 112 行表示内容。通过仔细检查晶体管模式,我确定了出错的 Pentium 芯片和修复后的 Pentium 芯片中的表格内容。
如前所述,查找表具有与商数 +2、+1、0、-1 和 -2 相对应的区域。这些区域有着由数学边界定义的不规则倾斜形状。在本节中,我将解释这些数学边界,因为它们是理解 Pentium 漏洞机制的关键。
除法算法的基本步骤是将部分余数 p 除以除数 d 以获得商数。下图显示了 p/d 如何确定商数。比率 p/d 将在顶部的线上定义一个点。(出于数学原因,该点将在 [-8/3, 8/3] 范围内。)该点将落入下面五条线中的一条,定义商数 q。但五个商区域是重叠的;如果 p/d 位于绿色段之一,则有两个可能的商数。图表的下一部分说明了如何从部分余数 p 中减去 q*d,从而将 p/d 移到中间,即 -2/3 和 2/3 之间。最后,将结果乘以 4(左移两位),将间隔扩展 19 回 [-8/3, 8/3],与原始间隔大小相同。8/3 的界限可能看起来是随机的,但其动机是确保新间隔与原始间隔大小相同,因此可以重复该过程。(出于代数原因,界限都是三分之一;值 3 来自底数 4 减 1.20)
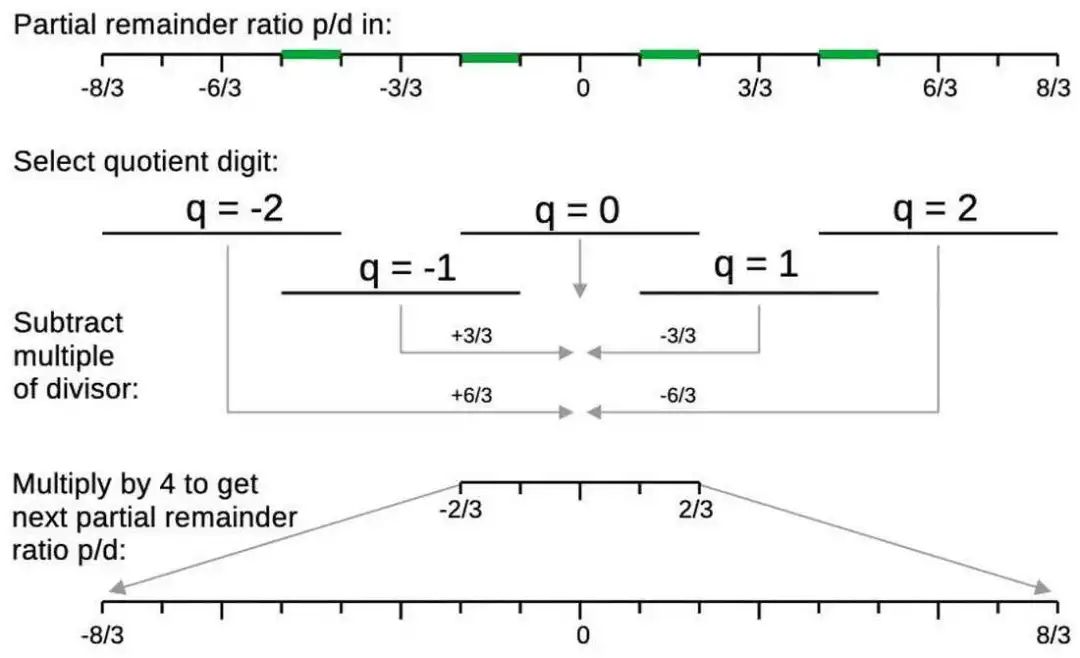
处理除法步骤的输入,产生下一步的输入。
请注意,SRT 算法有一些冗余,但无法处理“太错误”的 q 值。具体来说,如果 p/d 位于绿色区域,则可以选择两个 q 值中的任意一个。但算法通常无法从错误的 q 值中恢复。例如,如果 q 应该是 2,但选择了 0,则下一个部分余数将超出间隔,算法无法恢复。这就是导致 FDIV 错误的原因所在。
下图显示了 SRT 查找表的结构(也称为 P-D 表,因为轴是 p 和 d)。上图中的每个边界都会变成表中的一条线。例如,上面的 p/d 在 4/3 和 5/3 之间的绿色部分会变成下表中的绿色区域,其中 4/3 d ≤ p ≤ 5/3 d。这些斜线显示了可以使用特定商数 q 的区域。
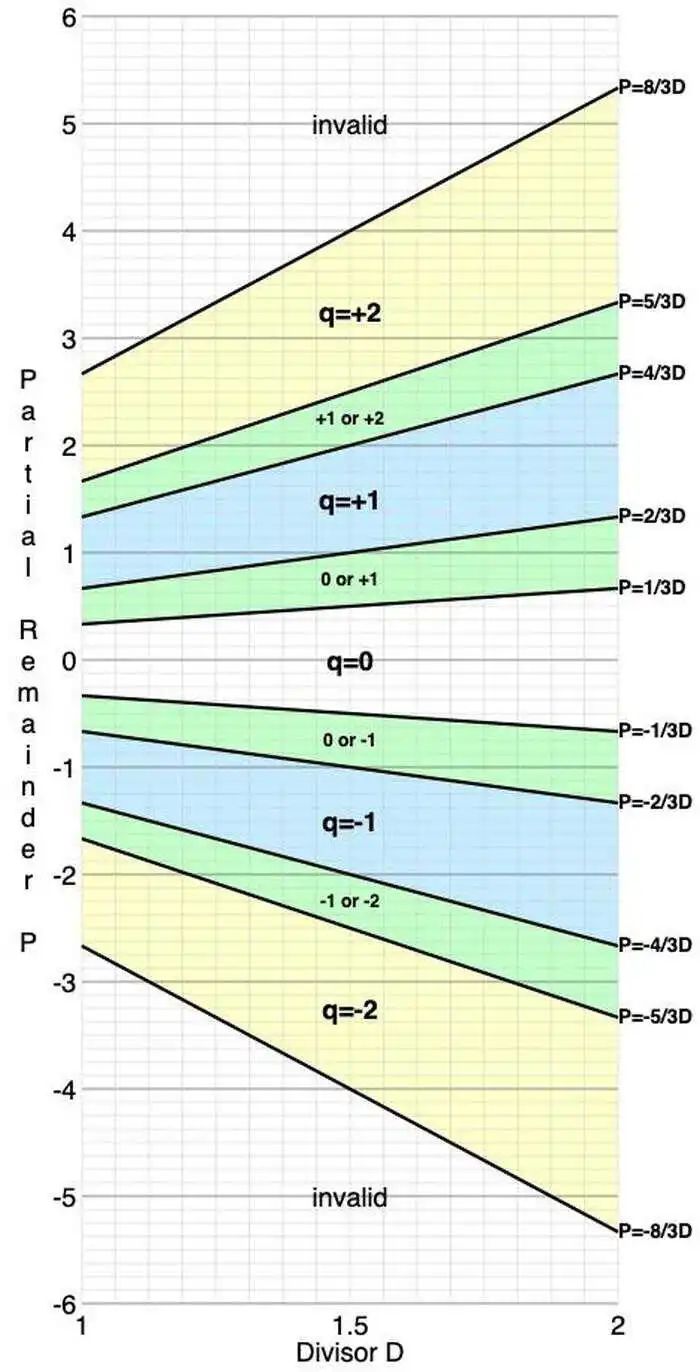
P-D 表指定部分余数(Y 轴)和除数(X 轴)的商数。
Pentium 中的查找表基于上表,每个单元都量化为 q 值。但还有一个约束需要讨论。
Pentium 的除法电路使用一种特殊电路来高效执行加法和减法:它叫做进位保存加法器。此加法器带来的一个后果是,每次访问查找表都可能转到“正确”单元正下方的单元。这是预料之中的,应该没什么问题,但在非常罕见和复杂的情况下,这种行为会导致 Pentium 的五个缺失单元之一被访问,从而触发除法错误。在本节中,我将讨论除法电路使用进位保存加法器的原因、进位保存加法器的工作原理以及进位保存加法器如何触发 FDIV 错误。
加法的问题是进位会使加法变慢。考虑手动计算 99999+1 这个例子。你将从 9+1=10 开始,然后进位 1,生成另一个进位,然后生成另一个进位,依此类推,直到计算完所有数字。计算机加法也存在同样的问题。如果你要将两个 64 位数相加,则低位可以生成进位,然后该进位会传播到所有 64 位。进位信号经过 64 层电路的时间很长,可能会限制 CPU 性能。因此,CPU 使用特殊电路来加快加法速度。
Pentium 的除法电路使用一种称为进位保存加法器的不寻常加法器电路来加(或减)除数和部分余数。如果你要执行大量加法(如除法期间所发生的情况),进位保存加法器会加快加法速度。其想法是,你不是在发生进位时向每个数字添加进位,而是将进位保存在一个单独的字符中。举个十进制的例子,499+222 等于 611,进位为 011;你不用将 1 进位到第二位,而是保留它。下次做加法时,添加之前保存的进位,并再次保存任何新的进位。进位保存加法器的优点是可以并行计算每个数字位置的和与进位,速度很快。缺点是你需要在加法序列的末尾做一个缓慢的加法来添加剩余的进位以得到最终答案。但是如果你执行多个加法(如除法),进位保存加法器总体上会更快。
进位保存加法器给查找表带来了问题。我们需要使用部分余数作为查找表的索引。但进位保存加法器将部分余数分成了两部分:和位和进位位。要获得表索引,我们需要将和位和进位位相加。由于除法的每一步都需要进行这种加法,我们似乎又回到了使用慢速加法器的时代,而进位保存加法器只会让事情变得更糟。
诀窍在于,我们只需要部分余数的 7 位作为表索引,因此我们可以使用另一种类型的加法器——超前进位加法器——使用强力逻辑并行计算每个进位。超前进位加法器中的逻辑对于每个位都变得越来越复杂,因此超前进位加法器对于大数字来说是不切实际的,但对于 7 位值来说是实用的。
下图显示了除法器使用的超前进位加法器。奇怪的是,加法器是一个 8 位加法器,但只使用了 7 位;也许 8 位加法器是英特尔的标准逻辑块。我在这里只对加法器做一个快速总结,细节留到另一篇文章中。在顶部,逻辑门并行计算 8 对输入中的每对的信号:求和、生成进位和传播进位。接下来,复杂的进位预测逻辑并行确定每个位置是否有进位。最后,XOR 门将进位应用于每个位。中间的电路用于测试;请参阅脚注。在底部,驱动器放大加法器各个部分的控制信号,并将 PLA 输出发送到芯片的其他部分。通过计算重复电路块的数量,你可以看到哪些块是 8 位宽、11 位宽等等。每个位的进位预测逻辑都不同,因此没有重复的结构。

为查找表提供信息的超前进位加法器。该电路块位于芯片上的 PLA 正上方。我移除了金属层,因此这张照片显示了 doped silicon(深色)和 polysilicon(淡灰色)。
进位保存和超前进位加法器可能看起来平平无奇,但它们是 FDIV 错误的关键部分,因为它们会更改表上的约束。原因在于部分余数是 64 位,但计算表索引的加法器是 7 位。由于其余位在求和之前被截断,因此表索引的部分余数和可能略低于实际的部分余数。具体而言,表索引可以比正确单元低一个单元,偏移量为 1/8。回想一下之前的图表,其中对角线将区域分开。必须将其中部分(但不是全部)行向下移动 1/8 以解决进位保存效应,但英特尔做出了错误的调整,这就是 FDIV 错误的根本原因。(这种效应当时众所周知,并在 SRT 除法论文中提到过,因此英特尔本不应出错。)
FDIV 错误一个有趣的地方在于它极其罕见。如果 2048 个表中有 5 个错误的条目,那么错误的除法应该很常见。但是,由于涉及进位保存加法器的复杂数学原因,实践中几乎从未遇到过丢失的表条目:只有大约 90 亿次随机除法中的 1 次会遇到问题。要找到缺失的表项,你需要连续多次从进位保存加法器中得到“不幸”的结果,这让中奖的几率与中彩票的几率差不多。
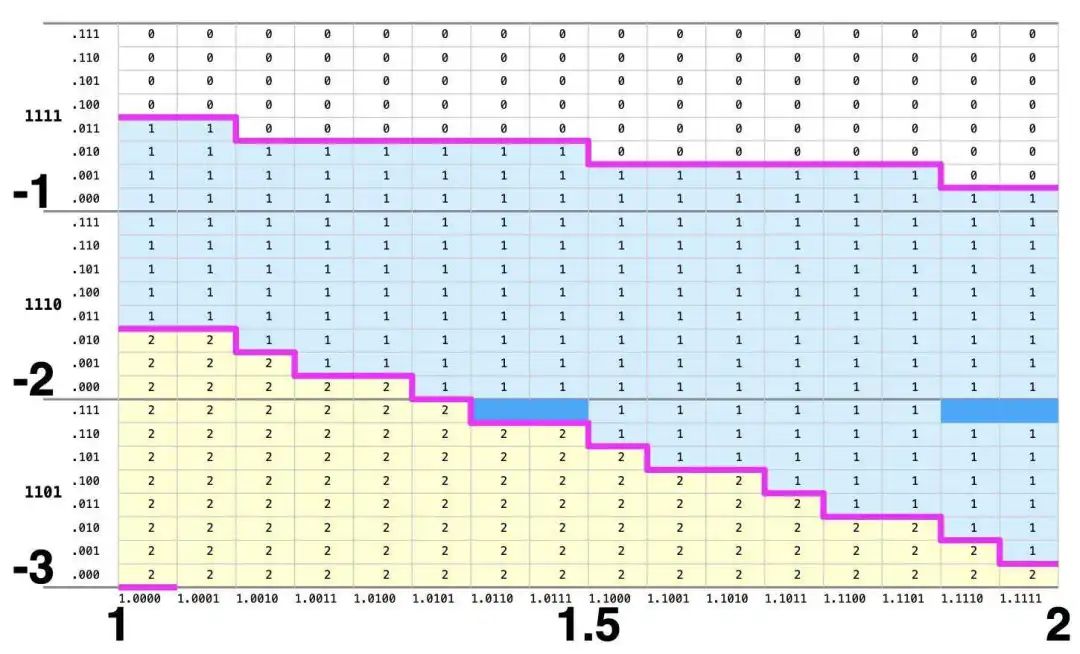
我认为下图是解释 FDIV 错误发生原因的“确凿证据”:顶部的洋红色线应该位于倾斜的黑线上方,但它反复穿过黑线。洋红色线小心翼翼地保持在灰线上方,但那是错误的线。换句话说,英特尔在定义表的 +2 区域时选择了错误的边界线。在本节中,我将解释为什么这会导致错误。

查找表的上半部分,解释了 FDIV 错误的根源。
该图根据 Pentium 查找表中存储的商值来着色:黄色代表 +2、蓝色代表 +1、白色代表 0,洋红色线条表示不同值之间的边界。对角黑线是表格上的数学约束,定义必须为 +2 的区域、可以为 +1 或 +2 的区域、必须为 +1 的区域等等。为了让表格正确,表格中的每个单元格值都必须满足这些约束。中间的洋红色线是正确的:它位于两条黑线之间(冗余的 +1 或 +2 区域),因此所有需要为 +1 的单元格都是 +1,所有需要为 +2 的单元格都是 +2,正如所要求的那样。同样,底部的洋红色线位于黑线之间。但是,顶部的洋红色线有故障:它必须位于顶部黑线上方,但它却越过了黑线。结果是,一些需要 +2 的单元格最后变成了 0:这些是导致 FDIV 错误的缺失单元格。
请注意,顶部洋红色线保持在对角灰线上方,同时尽可能紧密地跟随它。如果灰线是正确的线,那么表格将是完美的。不幸的是,英特尔在生成表格时为表格的上限选择了错误的约束线。
但是为什么有些对角线降低了 1/8,而其他线没有降低呢?如上一节所述,由于进位保存加法器截断,查找表的结果可能最终比实际 p 值指示的低一个单元格,即表索引的 p 值比实际值低 1/8。正确的单元格和下面的单元格都必须满足 SRT 约束。因此,如果这会使约束更严格,则线会向下移动,但如果这会扩大冗余区域,则线不会向下移动。特别是,顶线不能向下移动,但显然英特尔将线向下移动并生成了错误的查找表。
然而,英特尔对这个错误有不同的解释。英特尔白皮书指出,问题出在将表格下载到 PLA 的脚本中:一个错误导致脚本省略了 PLA 中的几个条目。我不相信这个解释:缺失的条目对应的是数学错误,而不是复制错误。我怀疑英特尔的说法在技术上是正确的,但有误导性:他们运行了一个 C 程序(他们称之为脚本)来生成表格,但该程序在边界方面存在数学错误。
在《 Pentium 编年史》中,作者,Pentium Pro 的架构师 Robert Colwell 对 FDIV 错误提供了不同的解释。他声称 Pentium 设计最初使用与 486 相同的查找表,但在发布前不久,管理层向工程师施加压力,要求缩小电路以节省芯片空间。工程师优化了表格来缩小电路,并证明优化是可行的。不幸的是,他们的证明是有缺陷的,但测试人员信任工程师,没有彻底测试这个改动,导致 Pentium 芯片带着错误发布了。这种解释的问题在于,Pentium 从一开始就采用了与 486 完全不同的除法算法:Pentium 使用基数为 4 的 SRT,而 486 使用标准二进制除法。由于 486 没有查找表,这个故事就不攻自破了。此外,只要删除 8 个未使用的行,PLA 可以很容易地变小,因此工程师们显然没有试图缩小它。我怀疑,由于 Colwell 在俄勒冈州开发了 Pentium Pro,而最初的 Pentium 是在加利福尼亚州开发的,因此 Colwell 没有获得有关 Pentium 问题的第一手资料。
英特尔对该错误的修复很简单,但也令人惊讶。你可能认为英特尔会将五个缺失的表值添加到 PLA 中,而这正是当时报道的内容。《纽约时报》写道,英特尔通过在芯片上添加几十个晶体管来修复了该缺陷。《EE Times》写道:“这个修复需要在 PLA 中添加条目或额外的门序列。”
但是,更新后的 PLA(如下)显示了完全不同的结果。更新后的 PLA 与原始 PLA 的大小完全相同。但大约 1/3 的条目从 PLA 中删除,从而减少了数百个晶体管。PLA 的 120 行中只有 74 行被使用,其余都留空。(原始 PLA 有 8 行空。)从 PLA 中删除条目是怎么解决问题的?

更新后的 PLA 有 46 行未使用。
解释是,英特尔并没有用正确的值 2 填充五个缺失的表条目。相反,英特尔用 2 填充了所有未使用的表条目,如下所示。这有两个效果。首先,它消除了任何误击空条目的可能性。其次,它让 PLA 方程式变得简单得多。你可能认为表中的条目越多,PLA 就越大,但 PLA 项的数量取决于数据的结构。用 2 填充未使用的单元格后,未使用区域(白色)和“2”区域(黄色)之间的锯齿状边框就会消失。如前所述,一个大矩形可以用一个 PLA 项覆盖,但锯齿状边框需要很多项。因此,更新后的 PLA 比原始的有缺陷的 PLA 小约 1/3。一个后果是,新 PLA 中的项与旧 PLA 中的项完全不同,因此无法找出修复该错误的具体晶体管。
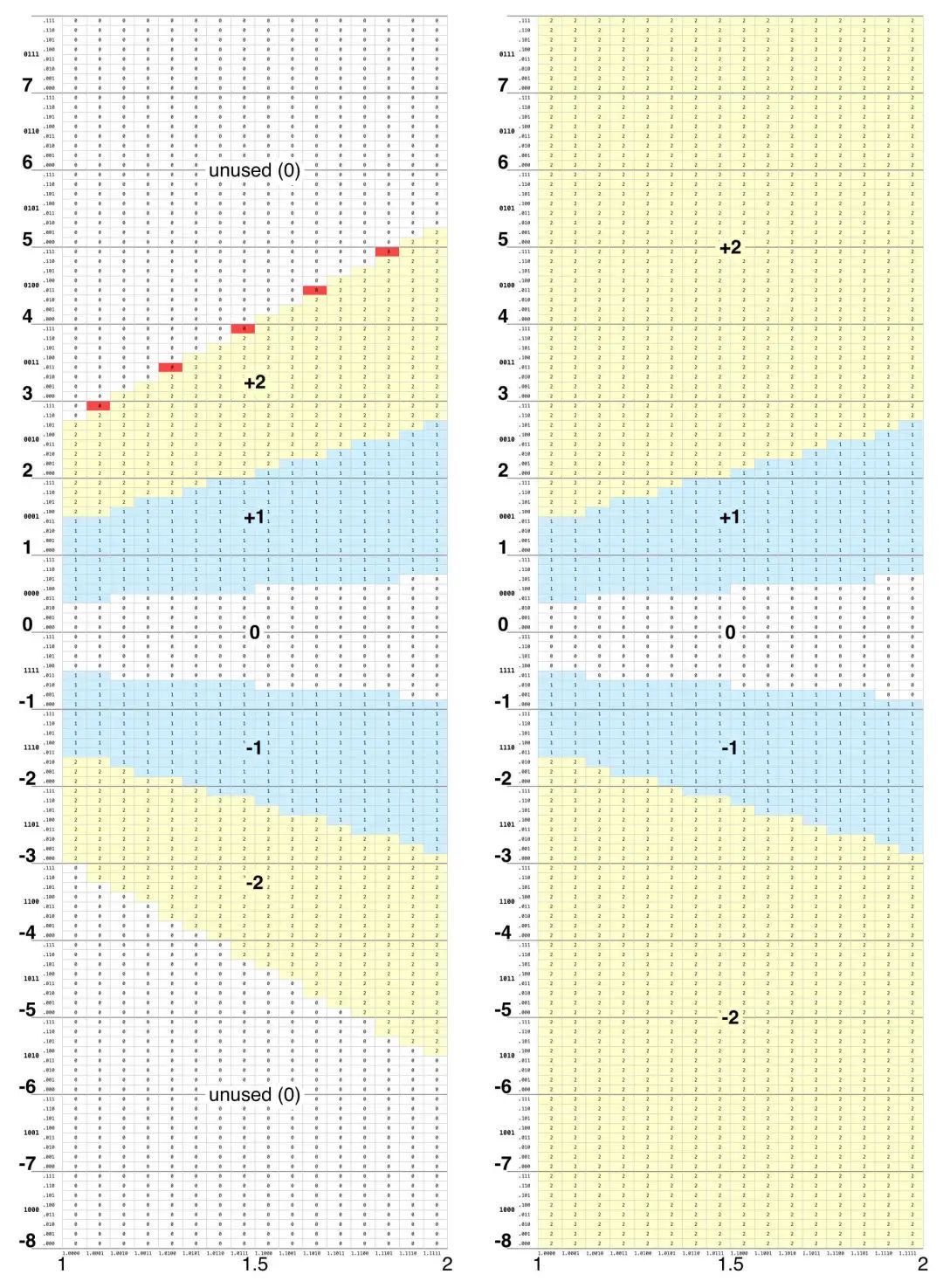
错误的查找表(左)和修正后的查找表(右)的对比。
下图显示了出错的 PLA 的前 14 行和修正后的 PLA 的前 14 行。如你所见,晶体管图案(以及 PLA 项)完全不同。

错误的 PLA 的顶部(左)和修正的 PLA(右)。
Pentium 芯片的错误有多重要?这成为了一个极具争议的话题。随机除法运算失败的情况非常罕见:大约 90 亿个值中只有一个会触发该错误。此外,错误的除法仍然基本准确:错误通常出现在小数点后第 9 位或第 10 位,最坏情况下,也就是错误出现在第 4 位有效数字中的情况非常罕见。英特尔的白皮书声称,典型用户每 27,000 年会遇到一次问题,与 DRAM 位翻转等其他错误源相比,这微不足道。英特尔表示:“我们的总体结论是,Pentium 处理器浮点单元的缺陷与绝大多数用户无关。科学 / 工程和金融工程领域应用程序的少数用户可能需要使用没有缺陷的更新处理器或软件解决方法。”
然而,IBM 做了自己的分析,表明该问题可能每隔几天就会影响客户,IBM 暂停了 Pentium 的销售。(巧合的是,IBM 有一个处理器竞品 PowerPC。)这场争论登上了各大报纸;《洛杉矶时报》报道了双方的发现,将争论放在台面上。英特尔很快作出让步,同意更换所有 Pentium 处理器,解决了争端。
我基本同意英特尔的分析。似乎只有一个人(Nicely 教授)在实际使用中注意到了这个错误。IBM 的分析似乎是故意找出触发错误的数字。大多数人永远不会遇到这个错误,即使他们遇到了,浮点精度的轻微下降对大多数人来说也没什么影响。从整个社会来看,更换 Pentium 处理器是一笔巨大的开支,而收益却微乎其微。但另一方面,客户期望处理器能提供准确的结果是合理的预期。
请注意,Pentium 错误是确定性的:如果你使用触发问题的特定除数和被除数,你将 100% 得到错误的答案。Pentium 工程师 Ken Shoemaker 表示,人们对该错误的强烈抗议是因为客户很容易重现它。当客户可以在自己的计算机上轻松看到该错误时,即使这种情况是有意为之,英特尔也很难说客户永远不会遇到该错误。
FDIV 错误是最著名的处理器错误之一。通过检查芯片,可以准确地看到它在芯片上的位置。但英特尔还有其他一些重要的错误。一些早期的 386 处理器存在 32 位乘法问题。与确定性的 FDIV 错误不同,386 会在特定温度 / 电压 / 频率条件下不可预测地产生错误的结果。这里的根本问题是布局问题,厂商没有提供足够的电气裕度来处理最坏的情况。英特尔还是出售了有故障的芯片,但将它们限制在 16 位市场;坏芯片被标记为“仅 16 位软件”,而好处理器则标有 32 位适用。尽管英特尔不得不忍受诸如“英特尔称某些 386 系统无法运行 32 位软件”等令人尴尬的新闻头条,但这个漏洞很快就被人们遗忘了。

386 的好坏版本对比。请注意底线上的标签。
另一个令人难忘的 Pentium 问题是“F00F 错误”,即以 F0 0F 开头的特定指令序列会导致处理器锁定,直到重新启动。该错误于 1997 年被发现,并通过操作系统更新得到解决。该错误可能存在于 Pentium 的大量微代码中。
你可能想知道为什么英特尔需要发布 Pentium 的新版本来修复 FDIV 错误,而不是更新微代码了事。问题是 Pentium(和更早的处理器)的微代码被硬编码到 ROM 中,无法修改。英特尔在 Pentium Pro(1995 年)中添加了可修补的微代码。英特尔最初实现此特性是为了芯片调试和测试。但在 FDIV 漏洞之后,英特尔意识到可修补的微代码对于修复漏洞也很有价值。Pentium Pro 将微代码存储在 ROM 中,但它还有一个可容纳多达 60 条微指令的静态 RAM。在启动期间,BIOS 可以将微代码补丁加载到此 RAM 中。在现代英特尔处理器中,微代码补丁已用于解决从 Spectre 漏洞到电压问题等各种问题。

Pentium PLA 的顶部金属层被移除,露出了 M2 和 M1 层。OR 和 AND 平面位于顶部和底部,中间是驱动程序和控制逻辑。
正如摩尔定律所述,随着处理器中晶体管的数量呈指数级增长,处理器使用了更复杂的电路和算法。除法就是一个例子。早期的微处理器,如英特尔 8080(1974 年,6000 个晶体管),没有硬件支持除法或浮点运算。英特尔 8086(1978 年,29,000 个晶体管)在微代码中实现了整数除法,但需要 8087 协处理器芯片才能实现浮点运算。英特尔 486(1989 年,120 万个晶体管)在芯片上增加了浮点支持。Pentium (1993 年,310 万个晶体管)转向了速度更快但更复杂的 SRT 除法算法。仅 Pentium 的 PLA 部分就有大约 4900 个晶体管点,比 MOS Technology 6502 处理器还多——也就是说 Pentium 芯片一部分电路的一个组件使用的晶体管比 1975 年的整块处理器还要多。
FDIV 漏洞对英特尔的长期影响是一个争议话题。一方面,AMD 等竞争对手从英特尔的错误中获益。AMD 的广告列出了 AMD 芯片的优势来嘲笑 Pentium 的问题,例如“你不必仔细检查你的数学”和“实际上可以处理除法等复杂计算的严谨性。”另一方面,Pentium Pro 的架构师 Robert Colwell 表示,FDIV 漏洞可能对英特尔产生了净收益,因为它为 Pentium 创造了巨大的知名度,同时也表明英特尔愿意支持其品牌形象。无论如何,英特尔在 FDIV 漏洞中幸存了下来;时间将告诉我们英特尔如何渡过今天它遇到的新问题。
原文链接:
https://www.righto.com/2024/12/this-die-photo-of-pentium-shows.html
声明:本文由 InfoQ 翻译,未经许可禁止转载。
直播预告
智能编码工具层出不穷,究竟怎么选、如何用?3 月 5 日 -14 日,InfoQ 极客传媒将发起「智能编码系列」直播,邀请阿里、百度、腾讯、字节、商汤、思码逸等企业一起在线 Coding,与所有开发者直观感受和评测数款国内外在线编码工具在企业真实生产场景中的表现。欢迎扫码或点击按钮一键预约直播!

今日荐文

(文:AI前线)