
Hugging Face 又出新教程啦!手把手教你构建 DeepSeek-R1 推理模型,笔者第一时间进行了学习,下面是整理的课程内容
课程链接:https://hf.co/learn/nlp-course/en/chapter12/1?fw=pt

推理大模型课程简介
LLM 在许多生成任务上表现出色。然而,直到最近,它们还在解决需要推理的复杂问题上举步维艰。例如,它们很难处理需要多步推理的谜题或数学问题。
Open R1 是一个旨在让 LLM 推理复杂问题的项目。它通过使用强化学习来鼓励 LLM 进行“思考”和推理。
简单来说,模型经过训练可以产生想法和输出,并构建这些想法和输出,以便用户可以分别处理它们。
让我们看一个例子。如果我们给自己布置了解决以下问题的任务,我们可能会这样想:
问题:“我有 3 个苹果和 2 个橙子。我总共有多少个水果?”
想法:“我需要将苹果和橘子的数量相加,得到水果的总数。”
答案:“5”
然后,我们可以构建这个想法和答案,以便用户可以分别处理它们。对于推理任务,可以训练 LLM 以以下格式生成想法和答案:
<think>我需要将苹果和橙子的数量相加,得到水果的总数。</think>
5
作为用户,我们可以从模型的输出中提取想法和答案,并用它们来解决问题。
作为一名大模型从业者,了解 Open R1 和强化学习在 LLM 中的作用很有价值,因为:
-
向我们展示尖端人工智能是如何开发的 -
为我们提供了亲身学习和贡献的机会 -
可以帮助我们了解人工智能技术的发展方向 -
为未来人工智能的职业机会打开了大门
本章分为四个部分,每个部分重点介绍Open R1的不同方面, 章节概述如下:
1️⃣ 强化学习简介及其在大模型 (LLM) 中的作用
我们将探索强化学习 (RL)的基础知识及其在训练LLM中的作用。
-
什么是 RL? -
RL 在 LLM 中如何应用? -
什么是 DeepSeek R1? -
DeepSeek R1 的主要创新是什么?
2️⃣ 理解 DeepSeek R1 论文
我们将分解启发Open R1的研究论文:
-
关键创新突破 -
训练流程和架构 -
结果及其意义
3️⃣ 在 TRL 中实现 GRPO
我们将通过代码示例进行实践:
-
如何使用 Transformer 强化学习 (TRL) 库 -
设置 GRPO 训练
4️⃣ 对齐模型的实际用例
我们将研究使用Open R1对齐模型的实际用例。
-
如何在 TRL 中使用 GRPO 训练模型 -
在 Hugging Face Hub 上分享你的模型
强化学习简介及其在大模型 (LLM) 中的作用
什么是强化学习(RL)?
想象一下,你正在训练一只狗。你想教它坐下。你可能会说“坐下!”,然后,如果狗坐下,你就给它零食和表扬。如果它不坐下,你可以温柔地引导它,或者再试一次。随着时间的推移,狗学会将坐下与积极的奖励(零食和表扬)联系起来,当你再次说“坐下!”时,它更有可能坐下。在强化学习中,我们将这种反馈称为奖励。
简而言之,这就是强化学习背后的基本思想!我们拥有的不是狗,而是语言模型(在强化学习中,我们称之为代理);我们拥有的不是你,而是提供反馈的环境。
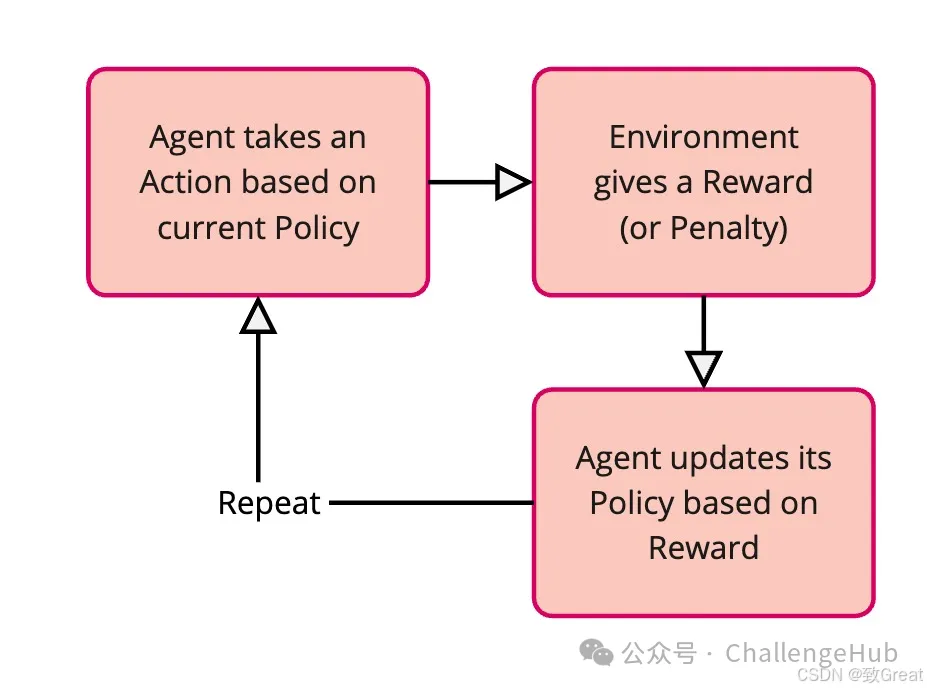
让我们分解一下 RL 的关键部分:
代理这是我们的学习者。在狗的例子中,狗是代理。在 LLM 的背景下,LLM 本身成为我们想要训练的代理。代理是做出决策并从环境及其奖励中学习的人。
环境这是代理所生活和互动的世界。对于狗来说,环境就是你的房子和你。对于 LLM 来说,环境有点抽象——可能是它与之互动的用户,也可能是我们为它设置的模拟场景。环境为代理提供反馈。
行动这些是代理可以在环境中做出的选择。狗的动作包括“坐”、“站”、“叫”等。对于 LLM 来说,动作可以是生成句子中的单词、选择对问题的答案,或者决定如何在对话中做出回应。
奖励这是环境在代理采取行动后给予的反馈。奖励通常是数字。
积极的奖励就像款待和表扬——它们告诉代理“干得好,你做对了!”。
负面奖励(或惩罚)就像一个温和的“不”——它们告诉代理“那不太对,试试别的”。对于狗来说,零食就是奖励。
对于大模型士 (LLM) 来说,奖励旨在反映大模型士 (LLM) 在特定任务上的表现 – 可能是其回应有多大帮助、真实或无害。
策略这是代理选择动作的策略。这就像狗理解当你说“坐下!”时它应该做什么一样。在 RL 中,策略是我们真正想要学习和改进的。它是一组规则或一个函数,告诉代理在不同情况下应该采取什么行动。最初,策略可能是随机的,但随着代理的学习,策略在选择导致更高奖励的行动方面会变得更好。
强化学习过程:反复试验
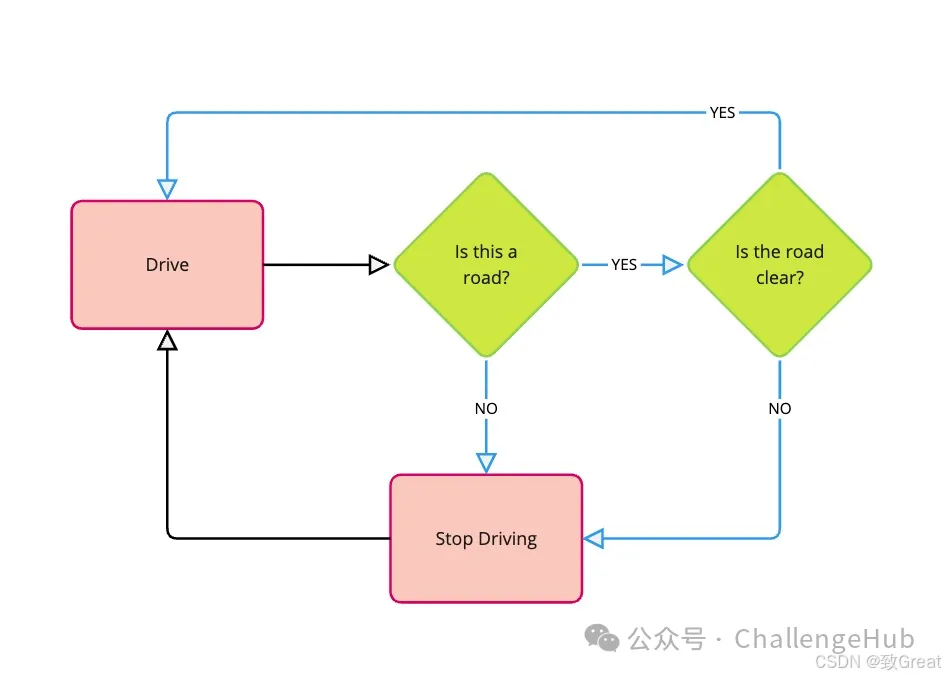 强化学习是通过反复试验的过程进行的:
强化学习是通过反复试验的过程进行的:
| 步骤 | 过程 | 描述 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
想想学骑自行车。一开始你可能会摇晃甚至摔倒(负面奖励!)。但当你设法保持平衡并平稳踩踏板时,你会感觉很好(正面奖励!)。你会根据这种反馈调整自己的动作——稍微倾斜、踩得更快等——直到你学会骑好自行车。RL 类似——它是通过互动和反馈进行学习。
RL 在大型语言模型 (LLM) 中的作用
现在,为什么 RL 对于大型语言模型如此重要?
训练真正优秀的 LLM 是件棘手的事。我们可以用互联网上的大量文本训练它们,它们会变得非常擅长预测句子中的下一个单词。这就是它们学会生成流畅且语法正确的文本的方式。
然而,仅仅流利是不够的。我们希望我们的大模型不只是擅长将单词串联起来。我们希望他们能够:
-
有帮助:提供有用且相关的信息。 -
无害:避免产生有毒、有偏见或有害的内容。 -
与人类偏好相一致:以人类认为自然、有帮助和有吸引力的方式做出回应。
预训练 LLM 方法主要依赖于从文本数据中预测下一个单词,但有时在这些方面存在不足。
虽然监督训练在产生结构化输出方面表现出色,但在产生有用、无害且一致的反应方面效果较差。我们将在第 11 章中探讨监督训练。
经过微调的模型可能会生成流畅且结构化的文本,但实际上这仍然是不正确的、有偏见的,或者不能以有用的方式回答用户的问题。
强化学习为我们提供了一种方法来微调这些预先训练过的 LLM,以更好地实现这些期望的品质。这就像对我们的 LLM 狗进行额外的训练,让它成为一个行为良好、乐于助人的伙伴,而不仅仅是一只知道如何流利吠叫的狗!
通过人类反馈进行强化学习(RLHF)
一种非常流行的语言模型对齐技术是强化学习人类反馈 (RLHF)。在 RLHF 中,我们使用人类反馈作为 RL 中“奖励”信号的代理。它的工作原理如下:
-
获取人类偏好:我们可能会要求人类比较 LLM 针对同一输入提示生成的不同响应,并告诉我们他们更喜欢哪个响应。例如,我们可能会向人类展示“法国首都是哪里?”这个问题的两个不同答案,并问他们“哪个答案更好?”。
-
训练奖励模型:我们利用这些人类偏好数据来训练一个单独的模型,称为奖励模型。这个奖励模型学会预测人类会喜欢什么样的反应。它学会根据有用性、无害性和与人类偏好的一致性对反应进行评分。
-
使用 RL 对 LLM 进行微调:现在我们使用奖励模型作为 LLM 代理的环境。LLM 生成响应(操作),奖励模型对这些响应进行评分(提供奖励)。本质上,我们正在训练 LLM 生成我们的奖励模型(从人类偏好中学习)认为不错的文本。
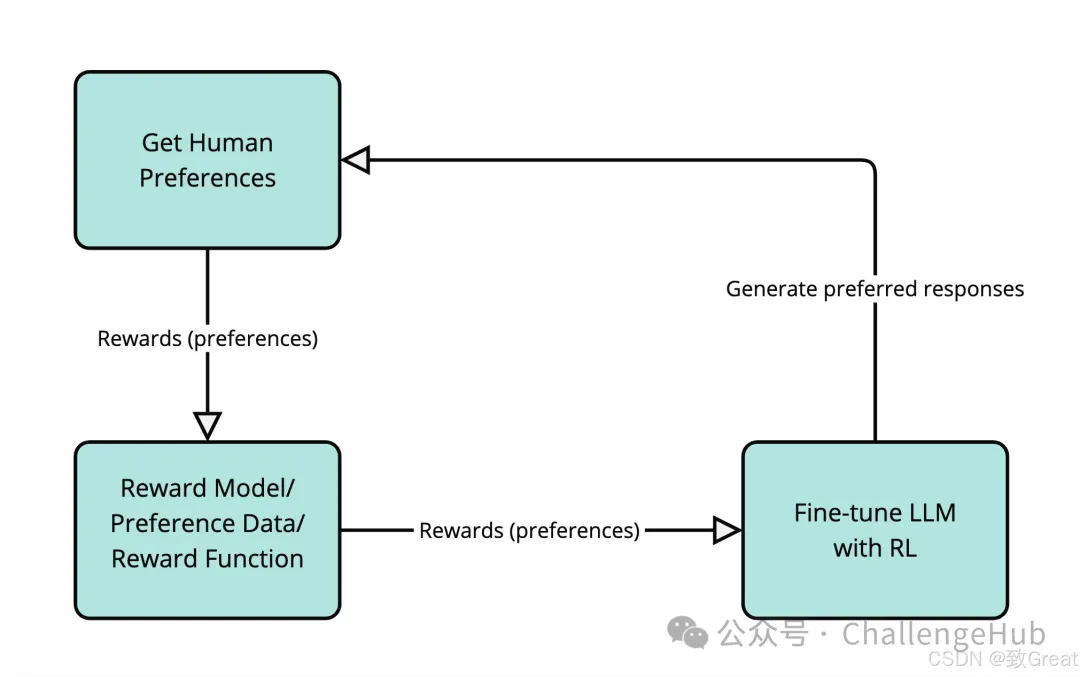 从总体角度来看,让我们看看在 LLM 中使用 RL 的好处:
从总体角度来看,让我们看看在 LLM 中使用 RL 的好处:
| 好处 | 描述 |
|---|---|
|
|
|
|
|
|
|
|
|
强化学习从人类反馈中获取信息已被用于训练当今许多最受欢迎的 LLM,例如 OpenAI 的 GPT-4、Google 的 Gemini 和 DeepSeek 的 R1。RLHF 有各种各样的技术,复杂程度和精密程度各不相同。在本章中,我们将重点介绍组相对策略优化 (GRPO),这是一种 RLHF 技术,已被证明可以有效地训练有用、无害且符合人类偏好的 LLM。
为什么我们应该关心 GRPO(组相对策略优化)?
RLHF 有很多技术,但本课程重点介绍 GRPO,因为它代表了语言模型强化学习的重大进步。
让我们简要考虑一下另外两种流行的 RLHF 技术:
-
近端策略优化(PPO) -
直接偏好优化(DPO)
近端策略优化 (PPO) 是 RLHF 的首批高效技术之一。它使用策略梯度法根据来自单独奖励模型的奖励来更新策略。
后来,直接偏好优化 (DPO) 被开发为一种更简单的技术,它直接使用偏好数据,无需单独的奖励模型。本质上,将问题定义为所选和拒绝的响应之间的分类任务。
与 DPO 和 PPO 不同,GRPO 将相似的样本分组并将它们作为一个组进行比较。与其他方法相比,基于组的方法提供了更稳定的梯度和更好的收敛特性。
GRPO 不使用像 DPO 那样的偏好数据,而是使用来自模型或函数的奖励信号比较相似样本组。
GRPO 在获取奖励信号的方式上非常灵活 – 它可以与奖励模型配合使用(就像 PPO 一样),但并不严格要求有奖励模型。这是因为 GRPO 可以整合来自任何可以评估响应质量的函数或模型的奖励信号。
例如,我们可以使用长度函数来奖励较短的响应,使用数学解算器来验证解决方案的正确性,或使用事实正确性函数来奖励更准确的响应。这种灵活性使 GRPO 特别适用于不同类型的对齐任务。
理解 DeepSeek R1 论文
DeepSeek R1 代表了语言模型训练的重大进步,特别是在通过强化学习开发推理能力方面。该论文介绍了一种名为“组相对策略优化”(GRPO)的新型强化学习算法。

突破性的“顿悟”时刻

R1-Zero 训练中的“顿悟时刻”现象
R1-Zero 训练中最引人注目的发现之一是“顿悟时刻”(Aha Moment)的出现。这种现象类似于人类在解决问题时的突然顿悟。它的工作原理如下:
-
初次尝试:模型首次尝试解决问题。 -
识别:识别潜在的错误或不一致之处。 -
自我纠正:根据识别出的问题调整自己的方法。 -
解释:能够解释为什么新方法更优。
这一突破让学习者产生共鸣,就像人类在学习过程中经历的“顿悟”时刻。它表明模型正在真正学习,而不仅仅是记忆已有模式。
例如,假设你正在尝试解决一个难题,例如拼图:
-
第一次尝试:“根据颜色,这块应该放在这里。” -
识别:“但是,形状不太合适。” -
更正:“啊,它实际上应该在那里。” -
解释:“因为这个位置的颜色和形状图案都匹配。”
这一过程并不是单纯地依赖记忆,而是模型在 RL 训练中自然产生的能力,无需明确编程。它展示了真正的学习,而不仅仅是从训练数据中死记硬背一个过程。
训练过程
训练过程 R1 是一个多阶段的过程。让我们分解一下各个阶段以及每个阶段中的关键创新。
最终形成两种模型:
-
DeepSeek-R1-Zero:纯粹使用强化学习训练的模型。 -
DeepSeek-R1:在 DeepSeek-R1-Zero 基础上添加监督微调的模型。
| 特征 | DeepSeek-R1-Zero | DeepSeek-R1 |
|---|---|---|
| 培训方式 |
|
|
| 微调 |
|
|
| 推理能力 |
|
|
| AIME 性能 |
|
|
| 主要特点 |
|
|
虽然 DeepSeek-R1-Zero 展示了纯强化学习在开发推理能力方面的潜力,但 DeepSeek-R1 在此基础上采用了一种更为平衡的方法,优先考虑推理性能和可用性。
训练过程包括四个阶段:
-
冷启动阶段 -
推理 RL 阶段 -
拒绝采样阶段 -
多样化 RL 阶段
接下来,我们详细分解每个阶段:
冷启动阶段(质量基础)
 此阶段旨在为模型的可读性和响应质量奠定坚实的基础。它使用来自 R1-Zero 的小型高质量样本数据集来微调 V3-Base 模型。从 DeepSeek-V3-Base 模型开始,该团队使用了来自 R1-Zero 的数千个经过验证的高质量样本进行监督微调。这种创新方法使用小型但高质量的数据集来建立强大的基线可读性和响应质量。
此阶段旨在为模型的可读性和响应质量奠定坚实的基础。它使用来自 R1-Zero 的小型高质量样本数据集来微调 V3-Base 模型。从 DeepSeek-V3-Base 模型开始,该团队使用了来自 R1-Zero 的数千个经过验证的高质量样本进行监督微调。这种创新方法使用小型但高质量的数据集来建立强大的基线可读性和响应质量。
推理 RL 阶段(能力建设)
 推理强化学习阶段侧重于开发数学、编码、科学和逻辑等领域的核心推理能力。此阶段采用基于规则的强化学习,奖励与解决方案的正确性直接相关。
推理强化学习阶段侧重于开发数学、编码、科学和逻辑等领域的核心推理能力。此阶段采用基于规则的强化学习,奖励与解决方案的正确性直接相关。
至关重要的是,此阶段的所有任务都是“可验证的”,因此我们可以检查模型的答案是否正确。例如,在数学的情况下,我们可以使用数学解算器检查模型的答案是否正确。
这一阶段的特别创新之处在于其直接优化方法,它消除了对单独奖励模型的需求,从而简化了训练过程。
拒绝取样阶段(质量控制)

在拒绝采样阶段,模型生成样本,然后通过质量控制流程进行过滤。DeepSeek-V3 充当质量评判者,在超越纯推理任务的广泛范围内评估输出。然后使用过滤后的数据进行监督微调。此阶段的创新之处在于它能够结合多种质量信号以确保高标准的输出。
多样化 RL 阶段(广泛对齐)
最后的多样化强化学习阶段使用复杂的混合方法处理多种任务类型。对于确定性任务,它采用基于规则的奖励,而主观任务则通过 LLM 反馈进行评估。此阶段旨在通过其创新的混合奖励方法实现人类偏好一致,将基于规则的系统的精确性与语言模型评估的灵活性相结合。
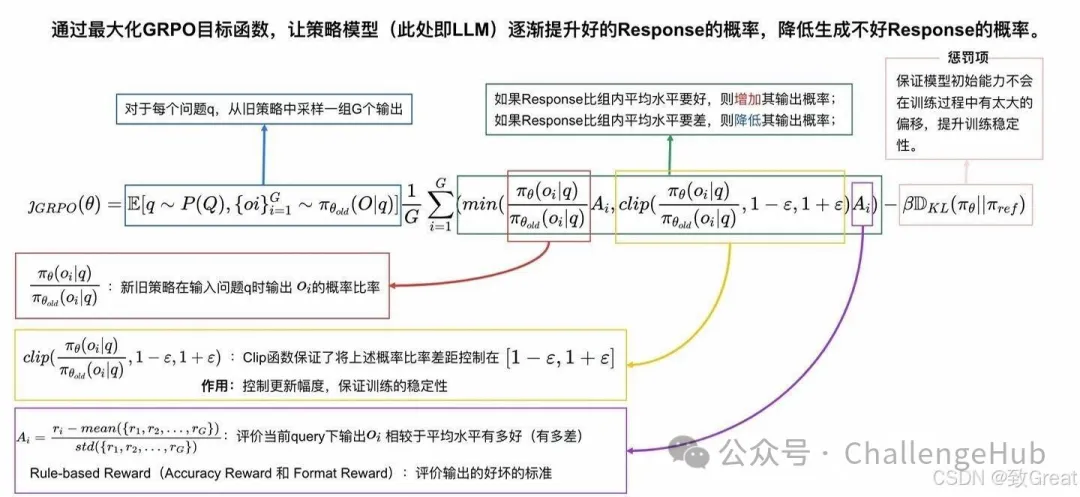
算法:组内相对策略优化(GRPO)
现在我们已经很好地了解了训练过程,让我们看看用于训练模型的算法。
作者将 GRPO 描述为模型微调的突破: GRPO 的创新之处在于它能够“直接优化偏好校正”。与传统的强化学习算法(如 PPO)相比,这意味着一种更直接、更有效的途径来使模型与期望的输出保持一致。让我们通过三个主要组件来分析 GRPO 的工作原理。
GRPO 的创新之处在于它能够“直接优化偏好校正”。与传统的强化学习算法(如 PPO)相比,这意味着一种更直接、更有效的途径来使模型与期望的输出保持一致。让我们通过三个主要组件来分析 GRPO 的工作原理。
Group Formation:创造多种解决方案
GRPO 的第一步非常直观 – 类似于学生通过尝试多种方法来解决难题。当给出提示时,模型不会只生成一个响应;相反,它会创建多次解决同一问题的尝试(通常是 4、8 或 16 次不同的尝试)。
假设你正在教一个模型解决数学问题。对于一个关于在农场数鸡的问题,该模型可能会生成几种不同的解决方案:
-
一个解决方案可能是逐步分解问题:首先计算鸡的总数,然后减去公鸡的数量,最后计算不下蛋的母鸡的数量 -
另一个人可能会使用不同但同样有效的方法 -
一些尝试可能包含错误或效率较低的解决方案
所有这些尝试都作为一个整体保存,就像有多个学生的解决方案可供比较和学习一样。

Preference Learning:理解什么是好的解决方案
这就是 GRPO 真正以其简单性而出彩的地方。与其他 RLHF 方法不同,这些方法总是需要单独的奖励模型来预测解决方案的好坏,而 GRPO 可以使用任何函数或模型来评估解决方案的质量。例如,我们可以使用长度函数来奖励较短的响应,或者使用数学求解器来奖励准确的数学解决方案。
评估过程考察每个解决方案的各个方面:
-
最终答案正确吗? -
解决方案是否遵循正确的格式(例如使用正确的 XML 标签)? -
推理是否与提供的答案相符?
这种方法之所以特别巧妙,是因为它处理评分的方式。GRPO 不只是给出绝对分数,而是将每个组内的奖励标准化。它使用一个简单但有效的公式来估计组相对优势:
Advantage = (reward - mean(group_rewards)) / std(group_rewards)
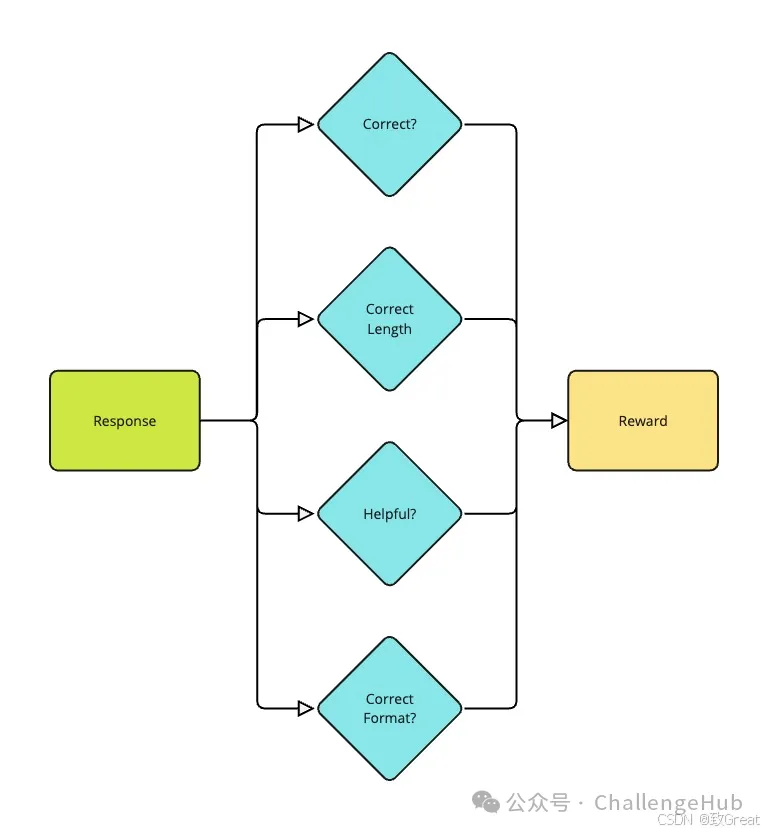 这种标准化就像是按曲线评分,但针对的是人工智能。它可以帮助模型了解组中哪些解决方案比同类解决方案更好或更差,而不仅仅是看绝对分数。
这种标准化就像是按曲线评分,但针对的是人工智能。它可以帮助模型了解组中哪些解决方案比同类解决方案更好或更差,而不仅仅是看绝对分数。
Optimization:从经验中学习
最后一步是 GRPO 根据从评估解决方案组中学到的知识来教导模型进行改进。这个过程既强大又稳定,使用两个主要原则:
-
它鼓励模型产生更多像成功的解决方案,同时摆脱效率较低的方法 -
它包含一个安全机制(称为 KL 散度惩罚),可防止模型一下子发生太大变化
事实证明,这种方法比传统方法更稳定,因为:
-
它同时考虑多个解决方案,而不是一次只比较两个 -
基于组的规范化有助于防止奖励扩展问题 -
KL 惩罚就像一个安全网,确保模型在学习新事物时不会忘记已经知道的知识
GRPO 的主要创新包括:
直接从任何函数或模型学习,消除对单独奖励模型的依赖。 基于小组的学习,比成对比较等传统方法更稳定、更高效。
这种分解很复杂,但关键在于 GRPO 是一种更有效、更稳定的训练模型推理的方法。
GRPO 算法的伪代码
现在我们了解了 GRPO 的关键组件,让我们看看伪代码中的算法。这是算法的简化版本,但它捕获了关键思想。
输入:
- initial_policy:需要训练的起始模型
- reward_function:评估输出的函数
- training_prompts:训练示例集-
group_size:每个提示的输出数量(通常为 4-16)
算法GRPO:
1. 对于每次训练迭代:
a.设置 reference_policy = initial_policy(快照当前策略)
b. 对于批次中的每个提示:
i.使用 initial_policy 生成 group_size 不同输出
ii.使用 reward_function 计算每个输出的奖励
iii. 标准化组内的奖励:
normalized_advantage = (reward - mean(rewards)) / std(rewards)iv. 通过最大化裁剪比率
更新策略:min(prob_ratio * normalized_advantage,
clip(prob_ratio, 1-epsilon, 1+epsilon) * normalized_advantage)
- kl_weight * KL(initial_policy || reference_policy)
输出:优化的策略模型
该算法展示了 GRPO 如何将基于组的优势估计与策略优化相结合,同时通过剪辑和 KL 散度约束保持稳定性。
结果与性能
现在我们已经探索了算法,让我们看看结果。DeepSeek-R1 在多个领域实现了最先进的性能:
| Domain | Key Results |
|---|---|
| Mathematics |
• 97.3% on MATH-500 |
| Coding |
• LiveCodeBench: 65.9% |
| General Knowledge |
• GPQA Diamond: 71.5% |
| Language Tasks |
• FRAMES: 82.5% |
该模型的实际影响超越了基准测试,因为它不仅提供了经济高效的 API 定价(每百万输入token $0.14),还在不同规模(15 亿至 700 亿参数)上成功进行了模型提炼。
值得注意的是,即使是7B 模型在 AIME 2024 上也能达到 **55.5%**,而70B 提炼版本在 MATH-500 上接近o1-mini性能(94.5%),表明在不同规模上都能有效保持能力。
GRPO 的局限性和挑战
虽然 GRPO 代表了语言模型强化学习的重大进步,但了解其局限性和挑战也很重要:
-
生成成本:相比仅生成一两个完成,每个提示生成多个完成(4-16)会显著增加计算需求。 -
批次大小限制:需要同时处理多组完成任务,这可能会限制有效批次大小,增加训练复杂性,并可能减慢训练速度。 -
奖励函数设计:训练质量很大程度上取决于奖励函数的设计。如果奖励函数设计不佳,可能会导致意外行为或针对错误目标的优化。 -
群组规模权衡:选择最佳群组规模需要在解决方案的多样性和计算成本之间取得平衡。样本太少可能无法提供足够的多样性,而样本太多会增加训练时间和资源消耗。 -
KL 散度调整:找到 KL 散度惩罚的正确平衡至关重要——如果惩罚太高,模型可能无法有效学习;如果惩罚太低,模型可能会偏离其初始能力过远。
结论
DeepSeek R1 论文代表了语言模型开发的一个重要里程碑。组相对策略优化 (GRPO) 算法已经证明纯强化学习确实可以发展出强大的推理能力,挑战了之前关于监督微调必要性的假设。
或许最重要的是,DeepSeek R1 表明,在高性能与成本效益和可访问性等实际考虑之间取得平衡是可能的。该模型在不同规模(从 15 亿到 700 亿个参数)中的功能成功提炼,为让高级 AI 功能更广泛地普及指明了方向。
在 TRL 中实现 GRPO
首先,我们来回顾一下 GRPO 算法的一些重要概念:
-
群体形成:模型为每个提示生成多个完成。 -
偏好学习:模型从比较完成组的奖励函数中学习。 -
训练配置:模型使用配置来控制训练过程。
实施 GRPO 需要哪些步骤?
-
定义提示的数据集。 -
定义奖励函数,该函数接受完成列表并返回奖励列表。 -
使用 GRPOConfig配置训练过程。 -
使用 GRPOTrainer训练模型。
以下是 GRPO 训练的简单示例:
from trl import GRPOTrainer, GRPOConfig
from datasets import load_dataset
# 1. Load your dataset
dataset = load_dataset("your_dataset", split="train")
# 2. Define a simple reward function
def reward_func(completions, **kwargs):
"""Example: Reward longer completions"""
return [float(len(completion)) for completion in completions]
# 3. Configure training
training_args = GRPOConfig(
output_dir="output",
num_train_epochs=3,
per_device_train_batch_size=4,
gradient_accumulation_steps=2,
logging_steps=10,
)
# 4. Initialize and train
trainer = GRPOTrainer(
model="your_model", # e.g. "Qwen/Qwen2-0.5B-Instruct"
args=training_args,
train_dataset=dataset,
reward_funcs=reward_func,
)
trainer.train()
关键组件
1.数据集格式
我们的数据集应包含模型将响应的提示。GRPO 训练器将为每个提示生成多个完成,并使用奖励函数对它们进行比较。
2.奖励函数
奖励函数至关重要——它决定了模型如何学习。以下是两个实际的例子:
# 示例 1:基于完成长度的奖励
def reward_length(completions, **kwargs):
return [float(len(completion)) for completion in completions]
# 示例 2:根据匹配模式进行奖励
import re
def reward_format(completions, **kwargs):
pattern = r"^<think>.*?</think><answer>.*?</answer>$"
return [1.0 if re.match(pattern, c) else 0.0 for c in completions]
3.训练配置
需要考虑的关键参数GRPOConfig:
training_args = GRPOConfig(
# Essential parameters
output_dir="output",
num_train_epochs=3,
num_generation=4, # Number of completions to generate for each prompt
per_device_train_batch_size=4, # We want to get all generations in one device batch
# Optional but useful
gradient_accumulation_steps=2,
learning_rate=1e-5,
logging_steps=10,
# GRPO specific (optional)
use_vllm=True, # Speed up generation
)
该num_generation参数对于 GRPO 尤其重要,因为它定义了组大小 – 模型将为每个提示生成多少个不同的完成。这是与其他 RL 方法的关键区别:
-
太小(例如 2-3):可能无法提供足够的多样性以进行有意义的比较 -
推荐(4-16):在多样性和计算效率之间实现良好的平衡 -
较大的值:可能会改善学习,但会显著增加计算成本
应根据我们的计算资源和任务的复杂性来选择组大小。对于简单任务,较小的组(4-8)可能就足够了,而更复杂的推理任务可能需要较大的组(8-16)。
成功秘诀
内存管理:根据您的 GPU 内存per_device_train_batch_size进行调整。gradient_accumulation_steps
速度:use_vllm=True如果您的模型受支持,则可实现更快的生成。
监控:观察训练期间记录的指标:
-
reward:完成任务的平均奖励 -
reward_std:奖励组内的标准差 -
kl:与参考模型的 KL 散度
奖励函数设计
DeepSeek R1 论文展示了几种有效的奖励函数设计方法,我们可以根据自己的 GRPO 实现进行调整:
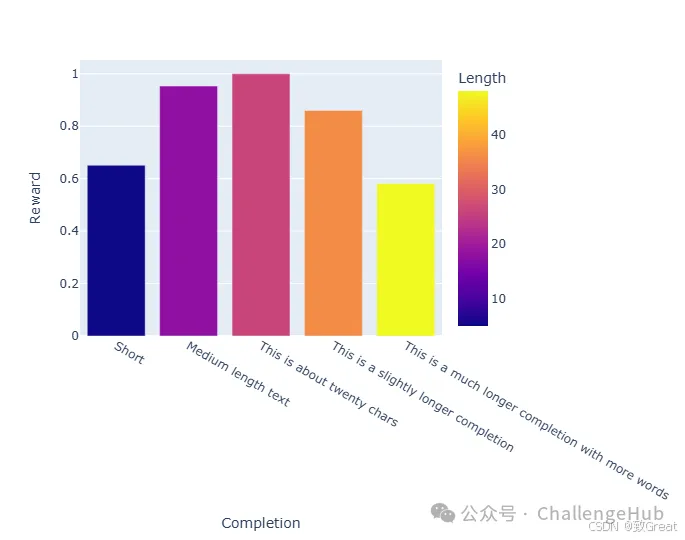
1.基于长度的奖励
最容易实现的奖励之一是基于长度的奖励。你可以奖励更长的完成时间:
def reward_len(completions, **kwargs):
ideal_length = 20
return [-abs(ideal_length - len(completion)) for completion in completions]
该奖励函数会惩罚太短或太长的完成,鼓励模型生成接近理想长度 20 个标记的完成。
2. 基于规则的可验证任务奖励
对于具有客观正确答案的任务(如数学或编码),你可以实现基于规则的奖励函数:
def problem_reward(completions, answers, **kwargs):
"""具有可验证答案的数学问题的奖励函数
completions:要评估的完成情况列表
answers:数据集中问题的答案列表
"""
rewards = []
for completion, correct_answer in zip(completions, answers):
# Extract the answer from the completion
try:
# This is a simplified example - you'd need proper parsing
answer = extract_final_answer(completion)
# Binary reward: 1 for correct, 0 for incorrect
reward = 1.0if answer == correct_answer else0.0
rewards.append(reward)
except:
# If we can't parse an answer, give a low reward
rewards.append(0.0)
return rewards
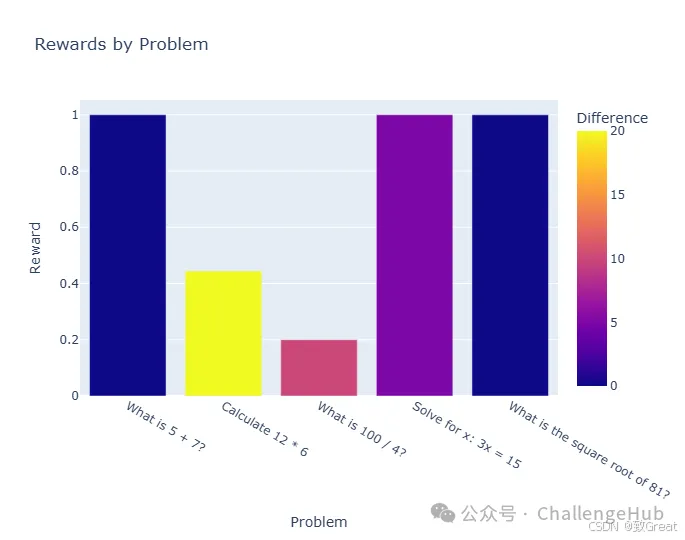
其实我们也可以设置准确答案的容忍度,就是上面代码是百分百匹配,我们也可以设置相似匹配
3. 基于格式的奖励
我们还可以奖励正确的格式,这在 DeepSeek R1 训练中非常重要:
def format_reward(completions, **kwargs):
"""遵循所需格式的奖励完成"""
# Example: Check if the completion follows a think-then-answer format
pattern = r"<think>(.*?)</think>\s*<answer>(.*?)</answer>"
rewards = []
for completion in completions:
match = re.search(pattern, completion, re.DOTALL)
if match:
# Check if there's substantial content in both sections
think_content = match.group(1).strip()
answer_content = match.group(2).strip()
if len(think_content) > 20and len(answer_content) > 0:
rewards.append(1.0)
else:
rewards.append(
0.5
) # Partial reward for correct format but limited content
else:
rewards.append(0.0) # No reward for incorrect format
return rewards
思考格式
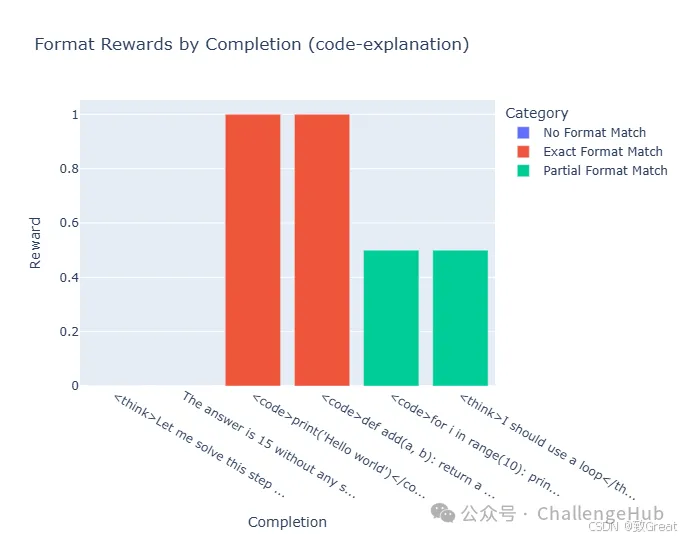
代码格式
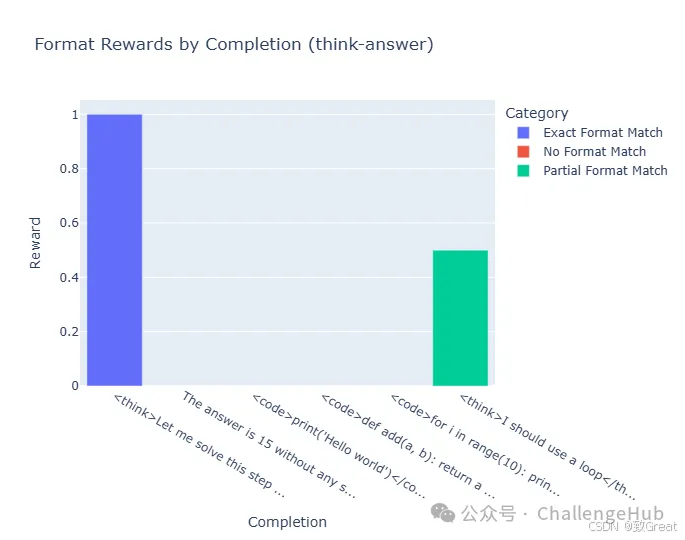
这些示例展示了如何实现受 DeepSeek R1 训练过程启发的奖励函数,重点关注正确性、格式和组合信号。
实践练习:使用 GRPO 微调模型
安装依赖项
首先,让我们安装本练习所需的依赖项。
!pip install -qqq datasets==3.2.0 transformers==4.47.1 trl==0.14.0 peft==0.14.0 accelerate==1.2.1 bitsandbytes==0.45.2 wandb==0.19.7 --progress-bar off
!pip install -qqq flash-attn --no-build-isolation --progress-bar off
现在我们将导入必要的库。
import torch
from datasets import load_dataset
from peft import LoraConfig, get_peft_model
from transformers import AutoModelForCausalLM, AutoTokenizer
from trl import GRPOConfig, GRPOTrainer
导入并登录 Weights & Biases
Weights & Biases 是一款用于记录和监控实验的工具。我们将使用它来记录我们的微调过程。
import wandb
wandb.login()
我们无需登录 Weights & Biases 即可进行此练习,但建议这样做以跟踪您的实验并解释结果。
加载数据集
现在,让我们加载数据集。在本例中,我们将使用mlabonne/smoltldr包含短篇小说列表的数据集。
dataset = load_dataset("mlabonne/smoltldr")
print(dataset)
加载模型
现在,让我们加载模型。
在本练习中,我们将使用该SmolLM2-135M模型。
这是一个小型的 135M 参数模型,可在有限的硬件上运行。这使得该模型非常适合学习,但它并不是最强大的模型。如果我们可以使用更强大的硬件,可以尝试微调更大的模型,例如SmolLM2-1.7B。
model_id = "HuggingFaceTB/SmolLM-135M-Instruct"
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype="auto",
device_map="auto",
attn_implementation="flash_attention_2",
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
设置LoRA
现在,让我们加载 LoRA 配置。我们将利用 LoRA 来减少可训练参数的数量,从而减少微调模型所需的内存占用。
# Load LoRA
lora_config = LoraConfig(
task_type="CAUSAL_LM",
r=16,
lora_alpha=32,
target_modules="all-linear",
)
model = get_peft_model(model, lora_config)
print(model.print_trainable_parameters())
总可训练参数:135M
定义奖励函数
如上一节所述,GRPO 可以使用任何奖励函数来改进模型。在本例中,我们将使用一个简单的奖励函数,鼓励模型生成长度为 50 个标记的文本。
# Reward function
ideal_length = 50
def reward_len(completions, **kwargs):
return [-abs(ideal_length - len(completion)) for completion in completions]
定义训练参数
现在,让我们定义训练参数。我们将使用GRPOConfig类以典型方式定义训练参数transformers。
如果这是我们第一次定义训练参数,可以查看TrainingArguments类以获取更多信息
# Training arguments
training_args = GRPOConfig(
output_dir="GRPO",
learning_rate=2e-5,
per_device_train_batch_size=8,
gradient_accumulation_steps=2,
max_prompt_length=512,
max_completion_length=96,
num_generations=8,
optim="adamw_8bit",
num_train_epochs=1,
bf16=True,
report_to=["wandb"],
remove_unused_columns=False,
logging_steps=1,
)
现在,我们可以用模型、数据集和训练参数初始化训练器并开始训练。
# Trainer
trainer = GRPOTrainer(
model=model,
reward_funcs=[reward_len],
args=training_args,
train_dataset=dataset["train"],
)
# Train model
wandb.init(project="GRPO")
trainer.train()
在单个 A10G GPU 上进行训练大约需要 1 小时,可通过 Google Colab 或 Hugging Face Spaces 进行。
训练期间将模型推送到 Hub
如果我们将push_to_hub参数设置为True并将model_id参数设置为有效的模型名称,则模型将在训练时被推送到 Hugging Face Hub。
解释训练结果
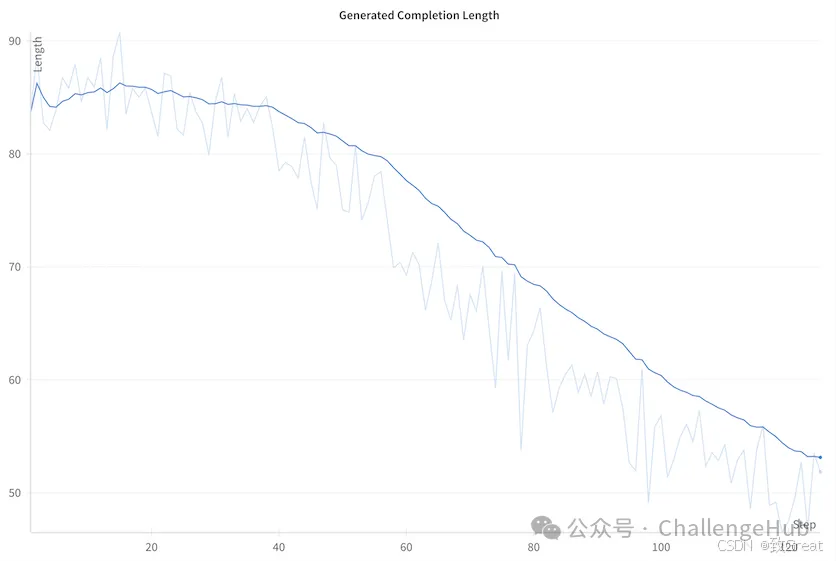
GRPOTrainer记录奖励函数的奖励、损失和一系列其他指标。
我们将重点关注奖励函数中的奖励和损失。
如我们所见,随着模型的学习,奖励函数的奖励越来越接近 0。这是一个好兆头,表明模型正在学习生成正确长度的文本。
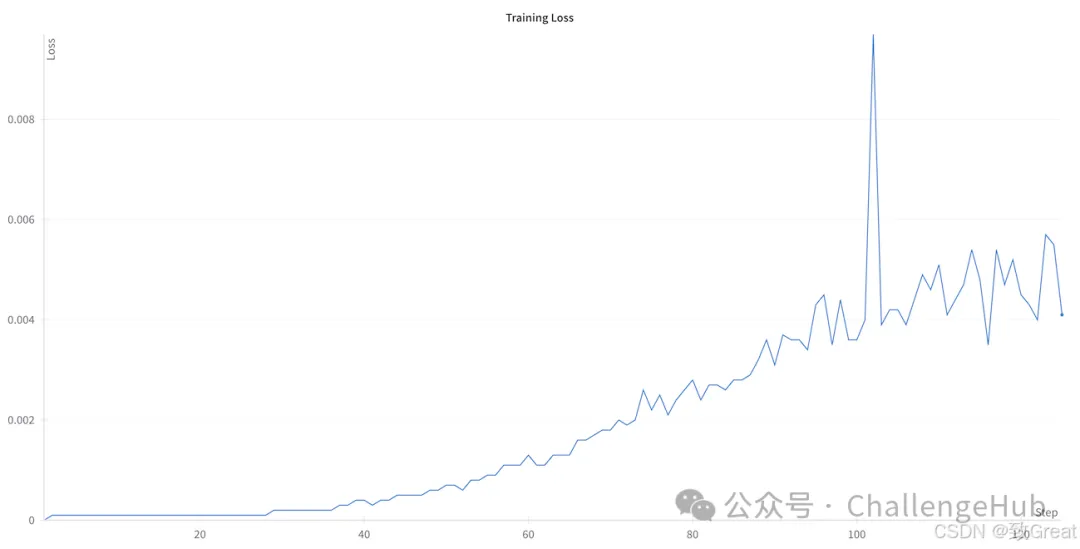
 我们可能会注意到,损失从零开始,然后在训练过程中增加,这似乎违反直觉。这种行为在 GRPO 中是可以预料到的,并且与算法的数学公式直接相关。GRPO 中的损失与 KL 散度(相对于原始策略的上限)成正比。随着训练的进行,模型会学习生成与奖励函数更匹配的文本,从而导致其与初始策略的偏差更大。这种不断增加的散度反映在不断上升的损失值中,这实际上表明模型正在成功适应以优化奖励函数。
我们可能会注意到,损失从零开始,然后在训练过程中增加,这似乎违反直觉。这种行为在 GRPO 中是可以预料到的,并且与算法的数学公式直接相关。GRPO 中的损失与 KL 散度(相对于原始策略的上限)成正比。随着训练的进行,模型会学习生成与奖励函数更匹配的文本,从而导致其与初始策略的偏差更大。这种不断增加的散度反映在不断上升的损失值中,这实际上表明模型正在成功适应以优化奖励函数。
保存并发布模型
到这里,我们可以上传分享这个模型了!
merged_model = trainer.model.merge_and_unload()
merged_model.push_to_hub(
"SmolGRPO-135M", private=False, tags=["GRPO", "Reasoning-Course"]
)
生成文本
🎉 我们已成功使用 GRPO 对模型进行微调!现在,让我们使用该模型生成一些文本。
首先,我们要定义一个非常长的文档!
prompt = """
# A long document about the Cat
The cat (Felis catus), also referred to as the domestic cat or house cat, is a small
domesticated carnivorous mammal. It is the only domesticated species of the family Felidae.
Advances in archaeology and genetics have shown that the domestication of the cat occurred
in the Near East around 7500 BC. It is commonly kept as a pet and farm cat, but also ranges
freely as a feral cat avoiding human contact. It is valued by humans for companionship and
its ability to kill vermin. Its retractable claws are adapted to killing small prey species
such as mice and rats. It has a strong, flexible body, quick reflexes, and sharp teeth,
and its night vision and sense of smell are well developed. It is a social species,
but a solitary hunter and a crepuscular predator. Cat communication includes
vocalizations—including meowing, purring, trilling, hissing, growling, and grunting—as
well as body language. It can hear sounds too faint or too high in frequency for human ears,
such as those made by small mammals. It secretes and perceives pheromones.
"""
messages = [
{"role": "user", "content": prompt},
]
现在,我们可以用模型生成文本。
# Generate text
from transformers import pipeline
generator = pipeline("text-generation", model="SmolGRPO-135M")
## Or use the model and tokenizer we defined earlier
# generator = pipeline("text-generation", model=model, tokenizer=tokenizer)
generate_kwargs = {
"max_new_tokens": 256,
"do_sample": True,
"temperature": 0.5,
"min_p": 0.1,
}
generated_text = generator(messages, generate_kwargs=generate_kwargs)
print(generated_text)
DeepSeek-R1测试题
1. 强化学习的关键组成部分是什么?
-
✅代理、环境、行动、奖励和政策 -
❌ 模型、数据、损失函数和优化器 -
❌ 输入层、输出层和隐藏层
2. RLHF 对于训练语言模型的主要优势是什么?
-
✅它有助于使模型与人类的偏好和价值观保持一致 -
❌ 它使模型更快地生成文本 -
❌ 它减少了模型的内存使用量
3. 在大语言模型 (LLM) 的实践研究中,什么代表“动作”?
-
✅在对话中生成单词或选择答案 -
❌ 更新模型权重 -
❌ 处理输入标记
4. 奖励在 RL 语言模型训练中起什么作用?
-
✅就模型的响应与期望行为的匹配程度提供反馈 -
❌ 测量模型的词汇量 -
❌ 确定模型的训练速度
5. 在 RL 背景下的 LLM 奖励是什么?
-
✅衡量响应质量的数字分数 -
❌ 生成响应的函数 -
❌ 评估响应质量的模型
6. DeepSeek R1 论文的主要创新是什么?
-
✅GRPO 算法可以在有或没有奖励模型的情况下从偏好中进行学习 -
❌ 使用比以往任何模型都多的 GPU 进行训练 -
❌ 创建比现有更大的语言模型
7. DeepSeek R1 训练过程的四个阶段是什么?
-
✅冷启动、推理 RL、拒绝采样和多样化 RL -
❌ 预训练、微调、测试和部署 -
❌ 数据收集、模型训练、评估和优化
8. R1-Zero 训练中的“顿悟时刻”现象是什么?
-
✅模型识别错误、自我纠正并解释其纠正的过程 -
❌ 模型达到人类水平的表现 -
❌ 当模型完成训练过程时
9. GRPO 的群组组建是如何进行的?
-
✅它为同一问题生成多个解决方案(4-16)并一起评估它们 -
❌ 它将多个模型组合成一个整体 -
❌ 将训练数据分成不同的组
10. DeepSeek-R1-Zero 和 DeepSeek-R1 之间的主要区别是什么?
-
✅R1-Zero 使用纯 RL,而 R1 将 RL 与监督微调相结合 -
❌ R1-Zero 小于 R1 -
❌ R1-Zero 的训练数据较少
本文由 Hugging Face 中文社区内容共建项目提供,稿件由社区成员投稿,经授权发布于 Hugging Face 公众号。文章内容不代表官方立场,文中介绍的产品和服务等均不构成投资建议。了解更多请关注公众号:
https://hf.link/tougao
(文:Hugging Face)