

作者:nanotron
校正:pprp
并行编程速成
将LLM训练从单个GPU扩展到数百个GPU需要在所有机器之间进行权重、梯度和数据的通信与同步。有一组分布式模式可以实现这一点,称为*集体操作 Collective Operation。在本节中,将进行一个小型的速成课程,涵盖诸如广播 BroadCast、全局归约 AllReduce、分散 Scatter 等操作。
现在,我们有许多独立的节点,可以是CPU核心、GPU或计算节点。每个节点执行一些计算,然后我们希望将结果或其部分传输到其他节点,用于下一个计算步骤(t+1)。
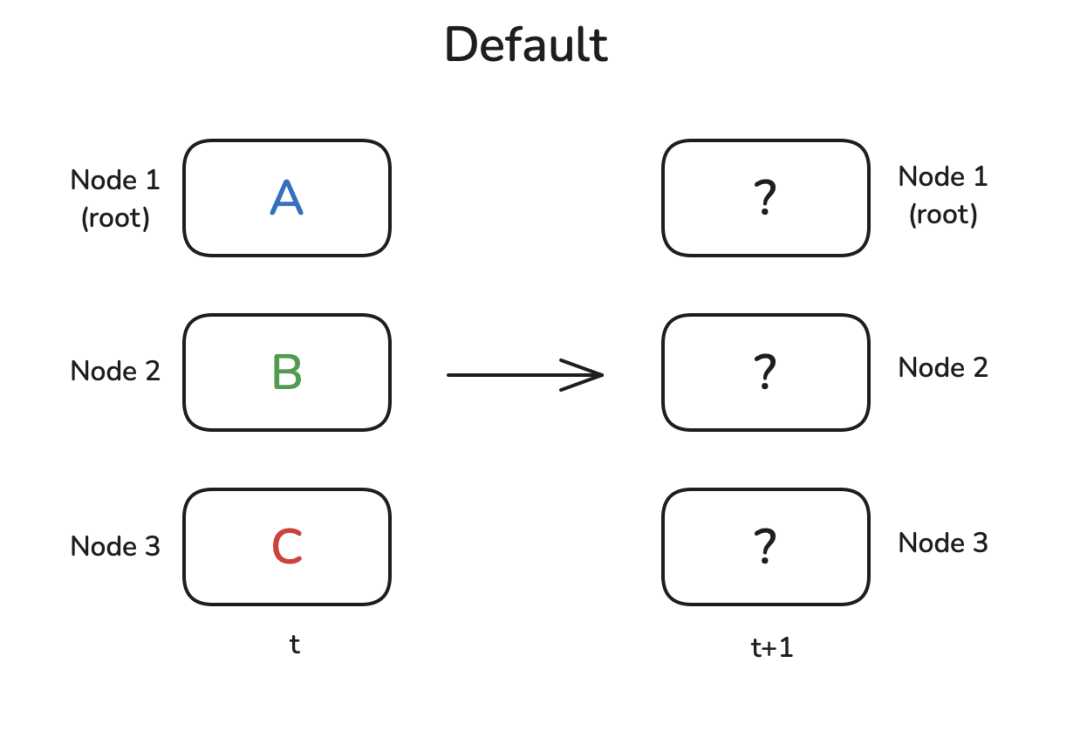
也许我们需要将一个节点的结果发送到所有其他节点,或者需要汇总每个节点的所有中间结果以报告总体结果。通常情况下,有一个具有显著地位的节点在操作中起到核心作用,在这里用 root表示,它是某些操作的目标或源。让我们从最简单的原语之一开始:广播操作 Broadcast。
广播(Broadcast)
一个非常常见的模式是,您在节点1上有一些数据,并希望与所有其他节点共享数据,以便它们可以使用数据进行一些计算。广播操作正是做到了这一点:
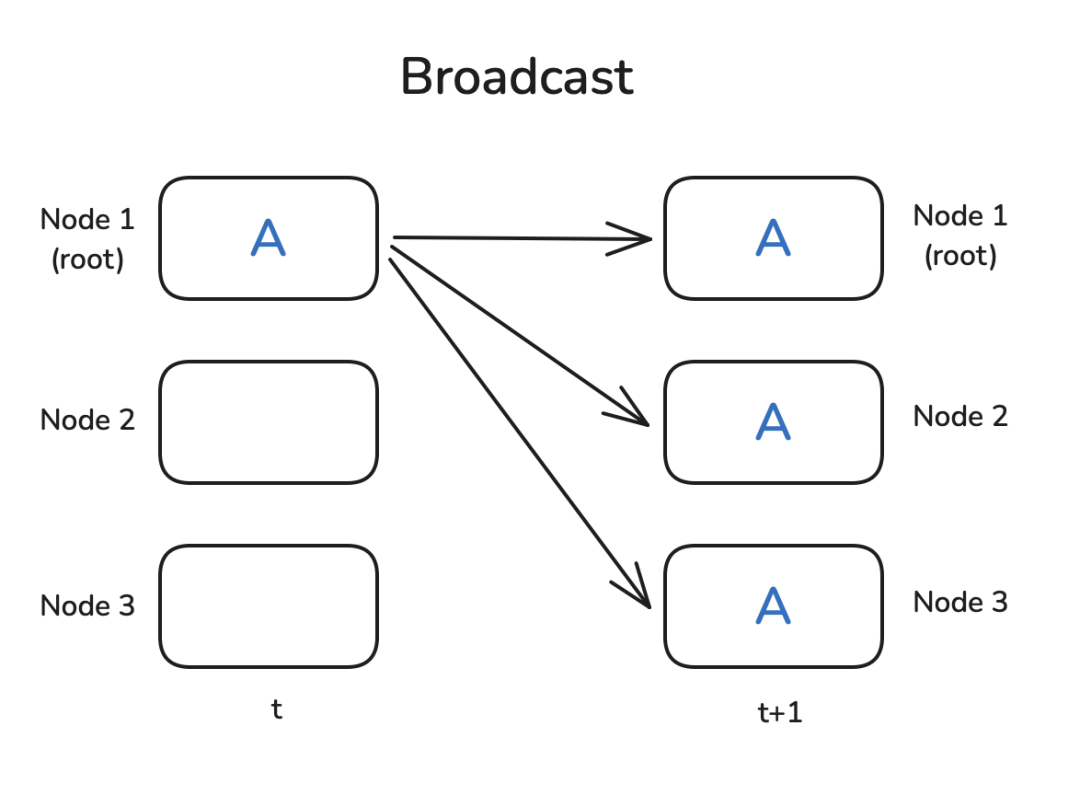
PyTorch原生提供了集体操作 Collective Operation,因此可以很容易地编写一个小例子来演示广播是如何工作的。我们首先需要使用 dist.init_process_group初始化一个进程组,设置通信后端(稍后我们将讨论NCCL),确定存在多少个 Workers(aka Nodes),并为每个工作者分配一个Rank(我们可以用 dist.get_rank获取)。最后,它在工作者之间建立连接。
为了展示 dist.broadcast操作,让我们创建一个张量,在 rank=0上有非零值,并在其他工作者上创建全零张量。然后,我们使用 dist.broadcast(tensor, src=0)将 rank=0的张量分发到所有其他排名:
import torch
import torch.distributed as dist
def init_process():
dist.init_process_group(backend='nccl')
torch.cuda.set_device(dist.get_rank())
def example_broadcast():
if dist.get_rank() == 0: # root
tensor = torch.tensor([1, 2, 3, 4, 5], dtype=torch.float32).cuda()
else:
tensor = torch.zeros(5, dtype=torch.float32).cuda()
print(f"Before broadcast on rank {dist.get_rank()}: {tensor}")
dist.broadcast(tensor, src=0)
print(f"After broadcast on rank {dist.get_rank()}: {tensor}")
init_process()
example_broadcast()
您可以使用 torchrun --nproc_per_node=3 dist_op.py运行上述脚本(您需要3个GPU,或者根据需要更改 nproc_per_node),您应该看到以下输出:
Before broadcast on rank 0: tensor([1., 2., 3., 4., 5.], device='cuda:0')
Before broadcast on rank 1: tensor([0., 0., 0., 0., 0.], device='cuda:1')
Before broadcast on rank 2: tensor([0., 0., 0., 0., 0.], device='cuda:2')
After broadcast on rank 0: tensor([1., 2., 3., 4., 5.], device='cuda:0')
After broadcast on rank 1: tensor([1., 2., 3., 4., 5.], device='cuda:1')
After broadcast on rank 2: tensor([1., 2., 3., 4., 5.], device='cuda:2')
很好,看起来正如预期的那样工作。请注意,Rank message可能会以无序的方式打印出来,因为无法控制哪个打印语句首先执行。现在让我们继续进行归约和全局归约模式!
归约 & 全局归约(Reduce & AllReduce)
归约模式 Reduce 是分布式数据处理中最基本的模式之一。其思想是通过一个函数 f()(例如求和或平均)来组合每个节点上的数据。在归约 Reduce 的例子中,结果仅发送到 root,而在全局归约 AllReduce 情况下,结果广播到所有节点:
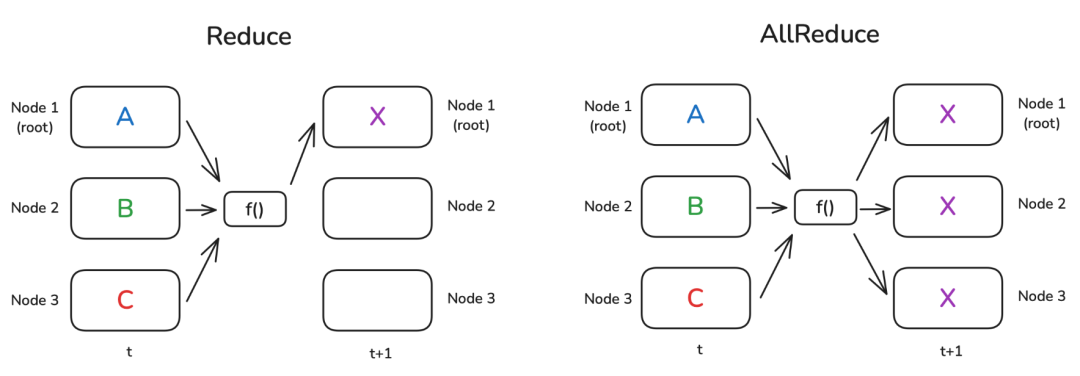
当然,并不存在一种神奇的“自由运行”节点,能够独自完成这样的运算。一般来说,在节点所构成的环形 Ring 或树形 Tree 结构中,每个节点都会进行一部分计算。下面举个简单的例子:假设我们要在每个节点上计算一组数字的总和,并且这些节点以环形方式连接。第一个节点将自身的数字发送给相邻节点,该相邻节点会把接收到的数字与自己的数字相加,然后再转发给下一个相邻节点。当沿着节点环完成一轮传递后,第一个节点将会收到总和。
这是运行简单的Reduce操作来计算张量总和的代码,我们使用 op=dist.ReduceOp.SUM指定要使用的操作(您可以在Pytorch文档 [1] 中找到有关支持操作的更多信息):
def example_reduce():
tensor = torch.tensor([dist.get_rank() + 1] * 5, dtype=torch.float32).cuda()
print(f"Before reduce on rank {dist.get_rank()}: {tensor}")
# dst=0 代表root节点
dist.reduce(tensor, dst=0, op=dist.ReduceOp.SUM)
print(f"After reduce on rank {rank}: {tensor}")
init_process()
example_reduce()
请注意,在Reduce操作中,仅更新了 dst节点上的张量:
Before reduce on rank 0: tensor([1., 1., 1., 1., 1.], device='cuda:0')
Before reduce on rank 1: tensor([2., 2., 2., 2., 2.], device='cuda:1')
Before reduce on rank 2: tensor([3., 3., 3., 3., 3.], device='cuda:2')
After reduce on rank 0: tensor([6., 6., 6., 6., 6.], device='cuda:0')
After reduce on rank 1: tensor([2., 2., 2., 2., 2.], device='cuda:1')
After reduce on rank 2: tensor([3., 3., 3., 3., 3.], device='cuda:2')
类似地,我们可以执行AllReduce操作(在这种情况下,我们不需要指定目标地点):
def example_all_reduce():
tensor = torch.tensor([dist.get_rank() + 1] * 5, dtype=torch.float32).cuda()
print(f"Before all_reduce on rank {dist.get_rank()}: {tensor}")
dist.all_reduce(tensor, op=dist.ReduceOp.SUM)
print(f"After all_reduce on rank {dist.get_rank()}: {tensor}")
init_process()
example_all_reduce()
在这种情况下,结果在所有节点上都可用:
Before all_reduce on rank 0: tensor([1., 1., 1., 1., 1.], device='cuda:0')
Before all_reduce on rank 1: tensor([2., 2., 2., 2., 2.], device='cuda:1')
Before all_reduce on rank 2: tensor([3., 3., 3., 3., 3.], device='cuda:2')
After all_reduce on rank 0: tensor([6., 6., 6., 6., 6.], device='cuda:0')
After all_reduce on rank 1: tensor([6., 6., 6., 6., 6.], device='cuda:1')
After all_reduce on rank 2: tensor([6., 6., 6., 6., 6.], device='cuda:2')
现在让我们转向下一个分布式通信操作。在许多实际情况下,每个节点单独执行许多复杂的计算,我们需要在节点之间共享最终结果。Gather和AllGather是我们在这种情况下要使用的操作。让我们来看看!
Gather & AllGather 聚集 & 全聚集
Gather和AllGather与Broadcast非常相似,因为它们允许在节点之间分发数据而不修改。与Broadcast的主要区别在于,我们不需要从一个节点向所有其他节点共享一个值(aka Broadcast),而是**每个节点都有一个我们希望收集所有数据的个体数据块(aka Gather)**或在所有节点上收集所有数据的个体数据块(在AllGather的情况下)。一图胜千言,让我们看看:
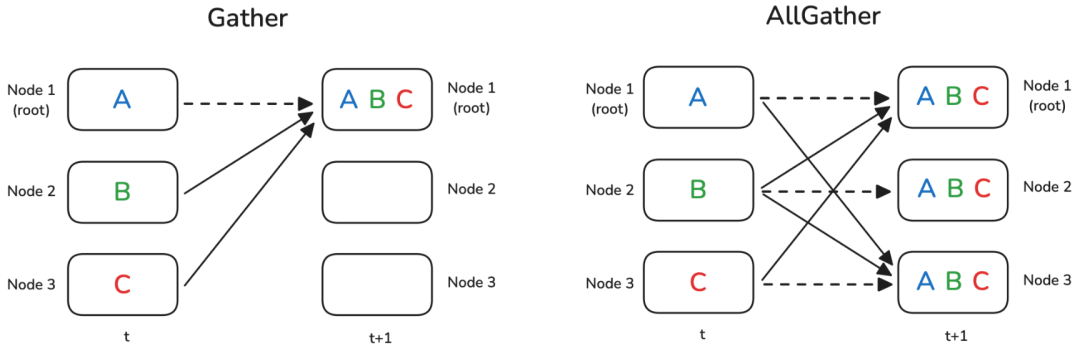
请注意,虚线表示某些数据实际上根本不移动(因为它已经存在于节点上)。
在gather操作的情况下,我们需要准备一个容器对象,用于存储聚合张量,例如 gather_list:
def example_gather():
tensor = torch.tensor([dist.get_rank() + 1] * 5, dtype=torch.float32).cuda()
if dist.get_rank() == 0:
gather_list = [
torch.zeros(5, dtype=torch.float32).cuda()
for _ in range(dist.get_world_size())
]
else:
gather_list = None
print(f"Before gather on rank {dist.get_rank()}: {tensor}")
dist.gather(tensor, gather_list, dst=0)
if dist.get_rank() == 0:
print(f"After gather on rank 0: {gather_list}")
init_process()
example_gather()
我们看到 gather_list确实包含所有排名的张量:
Before gather on rank 0: tensor([1., 1., 1., 1., 1.], device='cuda:0')
Before gather on rank 1: tensor([2., 2., 2., 2., 2.], device='cuda:1')
Before gather on rank 2: tensor([3., 3., 3., 3., 3.], device='cuda:2')
After gather on rank 0: [tensor([1., 1., 1., 1., 1.], device='cuda:0'),
tensor([2., 2., 2., 2., 2.], device='cuda:0'),
tensor([3., 3., 3., 3., 3.], device='cuda:0')]
编者注: dist.gather() 的工作方式确实不需要显式指定 source 的顺序,因为它会自动按照进程的 rank 顺序收集数据。
对于AllGather示例,唯一需要改变的是每个节点都需要一个结果的占位符:
def example_all_gather():
tensor = torch.tensor([dist.get_rank() + 1] * 5, dtype=torch.float32).cuda()
gather_list = [
torch.zeros(5, dtype=torch.float32).cuda()
for _ in range(dist.get_world_size())
]
print(f"Before all_gather on rank {dist.get_rank()}: {tensor}")
dist.all_gather(gather_list, tensor)
print(f"After all_gather on rank {dist.get_rank()}: {gather_list}")
init_process()
example_all_gather()
确实,可以看到现在每个节点都有了所有数据:
Before all_gather on rank 0: tensor([1., 1., 1., 1., 1.], device='cuda:0')
Before all_gather on rank 1: tensor([2., 2., 2., 2., 2.], device='cuda:1')
Before all_gather on rank 2: tensor([3., 3., 3., 3., 3.], device='cuda:2')
After all_gather on rank 0: [tensor([1., 1., 1., 1., 1.], device='cuda:0'),
tensor([2., 2., 2., 2., 2.], device='cuda:0'),
tensor([3., 3., 3., 3., 3.], device='cuda:0')]
After all_gather on rank 1: [tensor([1., 1., 1., 1., 1.], device='cuda:1'),
tensor([2., 2., 2., 2., 2.], device='cuda:0'),
tensor([3., 3., 3., 3., 3.], device='cuda:0')]
After all_gather on rank 2: [tensor([1., 1., 1., 1., 1.], device='cuda:2'),
tensor([2., 2., 2., 2., 2.], device='cuda:2'),
tensor([3., 3., 3., 3., 3.], device='cuda:2')]
那么反向操作gather又是什么呢?在这种情况下,我们将所有数据都集中在一个节点上,并希望在节点之间分发/切片它,可能还会进行一些中间处理?我们可以使用Scatter,或者在操作之间使用ReduceScatter模式:
Scatter & ReduceScatter
正如名称所暗示的,Scatter操作的目标是将数据从一个节点分发到所有其他节点。因此,它与Broadcast操作不同,后者是复制数据而不进行切片 Slicing,并且它逻辑上是Gather操作的反向。
ReduceScatter模式略微复杂:想象一下,在Reduce情况下应用操作,但我们不仅将结果移动到一个节点,还将其均匀分布到所有节点:
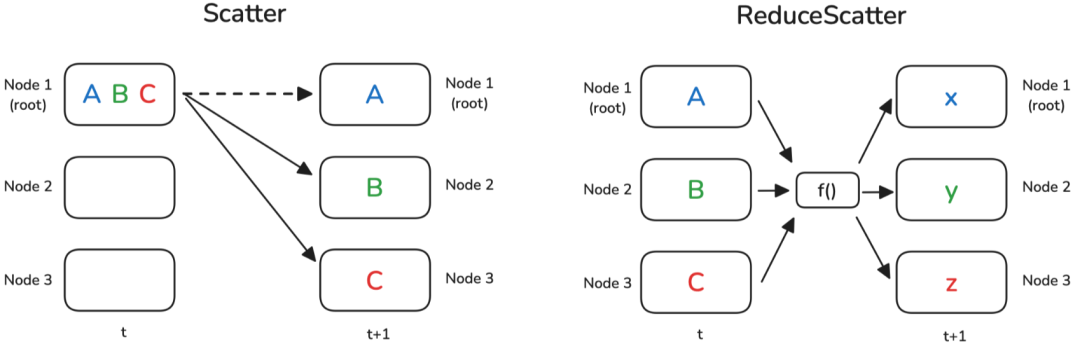
Scatter操作在代码中的表示方式与Gather相反:我们准备源数据作为我们希望分发的张量列表,而不是准备一个张量列表作为目标。还需要指定 src:
def example_scatter():
if dist.get_rank() == 0:
scatter_list = [
torch.tensor([i + 1] * 5, dtype=torch.float32).cuda()
for i in range(dist.get_world_size())
]
print(f"Rank 0: Tensor to scatter: {scatter_list}")
else:
scatter_list = None
tensor = torch.zeros(5, dtype=torch.float32).cuda()
print(f"Before scatter on rank {dist.get_rank()}: {tensor}")
dist.scatter(tensor, scatter_list, src=0)
print(f"After scatter on rank {dist.get_rank()}: {tensor}")
init_process()
example_scatter()
结果显示,空张量已被 scatter_list的内容填充:
Rank 0: Tensor to scatter: [tensor([1., 1., 1., 1., 1.], device='cuda:0'),
tensor([2., 2., 2., 2., 2.], device='cuda:0'),
tensor([3., 3., 3., 3., 3.], device='cuda:0')]
Before scatter on rank 0: tensor([0., 0., 0., 0., 0.], device='cuda:0')
Before scatter on rank 1: tensor([0., 0., 0., 0., 0.], device='cuda:1')
Before scatter on rank 2: tensor([0., 0., 0., 0., 0.], device='cuda:2')
After scatter on rank 0: tensor([1., 1., 1., 1., 1.], device='cuda:0')
After scatter on rank 1: tensor([2., 2., 2., 2., 2.], device='cuda:1')
After scatter on rank 2: tensor([3., 3., 3., 3., 3.], device='cuda:2')
让我们创建更有趣的数据来演示ReduceScatter的逻辑:在每个节点上,我们创建一个包含幂指数和节点排名偏移函数的2元素向量列表(这有点难以想象,所以看下面的示例):
def example_reduce_scatter():
rank = dist.get_rank()
world_size = dist.get_world_size()
input_tensor = [
torch.tensor([(rank + 1) * i for i in range(1, 3)], dtype=torch.float32).cuda()**(j+1)
for j in range(world_size)
]
output_tensor = torch.zeros(2, dtype=torch.float32).cuda()
print(f"Before ReduceScatter on rank {rank}: {input_tensor}")
dist.reduce_scatter(output_tensor, input_tensor, op=dist.ReduceOp.SUM)
print(f"After ReduceScatter on rank {rank}: {output_tensor}")
init_process()
example_reduce_scatter()
让我们打印一下我们创建的数据模式。我们也可以立即看到ReduceScatter的模式:第一个排名接收了每个节点的第一个张量的总和,第二个排名包含了每个节点的第二个张量的总和,依此类推:
Before ReduceScatter on rank 0: [tensor([1., 2.], device='cuda:0'),
tensor([1., 4.], device='cuda:0'),
tensor([1., 8.], device='cuda:0')]
Before ReduceScatter on rank 1: [tensor([2., 4.], device='cuda:1'),
tensor([ 4., 16.], device='cuda:1'),
tensor([ 8., 64.], device='cuda:1')]
Before ReduceScatter on rank 2: [tensor([3., 6.], device='cuda:2'),
tensor([ 9., 36.], device='cuda:2'),
tensor([ 27., 216.], device='cuda:2')]
After ReduceScatter on rank 0: tensor([ 6., 12.], device='cuda:0')
After ReduceScatter on rank 1: tensor([14., 56.], device='cuda:1')
After ReduceScatter on rank 2: tensor([ 36., 288.], device='cuda:2')
下面简要地看一下一个常见的使用ReduceScatter和AllGather的AllReduce实现:Ring AllReduce。
快速关注Ring AllReduce
***环形 Ring AllReduce***是AllReduce的一种特定实现,经过优化以实现可伸缩性。与所有设备直接相互通信不同(这可能会造成通信瓶颈),环形All-Reduce可以分解为两个关键步骤:ReduceScatter和AllGather。它的工作原理如下:
-
ReduceScatter -
每个设备将其数据(例如梯度)分割成块,并将一个块发送给其邻居。同时,每个设备从其另一个邻居接收一个块。 -
当每个设备接收到一个块时,它将其对应的块添加(减少)到接收到的块中。 -
这个过程在环中持续进行,直到每个设备持有一个部分减少的块,表示该块的梯度在所有设备中的总和。 -
AllGather -
现在,每个设备需要从其他设备收集完全减少的块。 -
设备开始将它们的减少块发送给邻居。 -
每个设备转发收到的块,直到每个设备都有了完全减少的块,使每个设备得到完整的、总结的梯度。
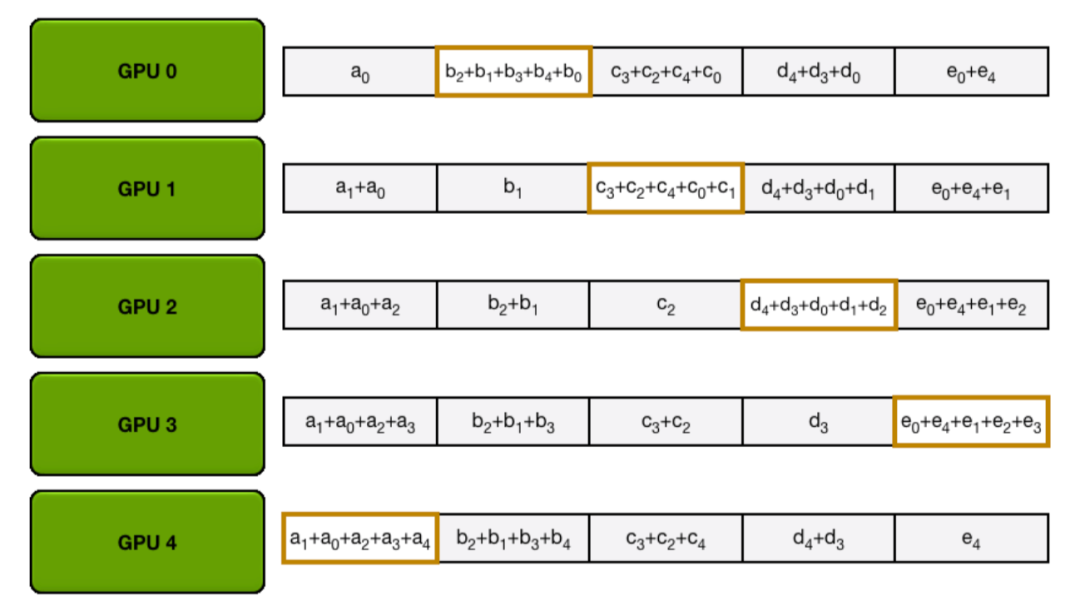
让我们通过以下动画来说明,我们有5个GPU,每个GPU都有长度为5的张量。第一个动画显示了ReduceScatter步骤,最终每个GPU都接收到了特定数据块的减少结果(橙色矩形):
编者注:以下两张均为gif图,建议访问网站来得到更好的阅读体验
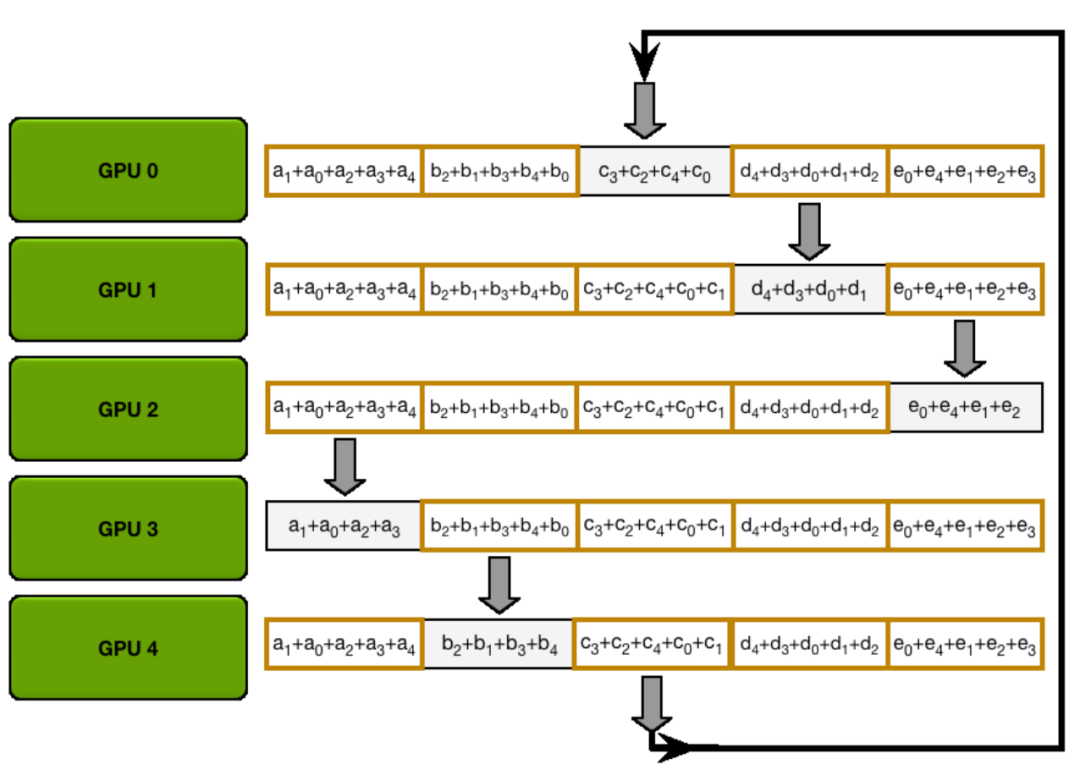
接下来的动画展示了AllGather步骤,在此过程结束时,每个GPU获取了AllReduce操作的完整结果(即上文提到的:AllReduce=ReduceScatter + AllGather):
您可能已经注意到,在reduce-scatter和all-gather步骤中,每个GPU发送和接收值 次。每个GPU每次传输发送 个值,其中 K 是数组长度。因此,每个GPU发送和接收的总数据量为 。当 N(GPU的数量)较大时,每个GPU发送和接收的总数据量约为2×K,其中 K是总参数数量。
对于AllReduce,有两个关键点需要记住:
-
当N(GPU的数量)较大时,AllReduce的通信成本约为2×K。 -
一个AllReduce操作可以分解为reduce-scatter和all-gather两个步骤。这两个操作的通信成本是AllReduce的一半,约为K。
正如我们所看到的,即使在节点之间带宽有限的情况下,这种实现也可以有效利用。
现在已经了解了分布式操作的主要构建模块,但在实际操作中让我们看看用于同步的特殊操作之前,来看看一个特殊操作:Barrier。
Barrier 屏障
Barrier是一种简单的操作,用于同步所有节点。直到所有节点都到达Barrier之前,Barrier不会被解除。然后才能继续进行进一步的计算:
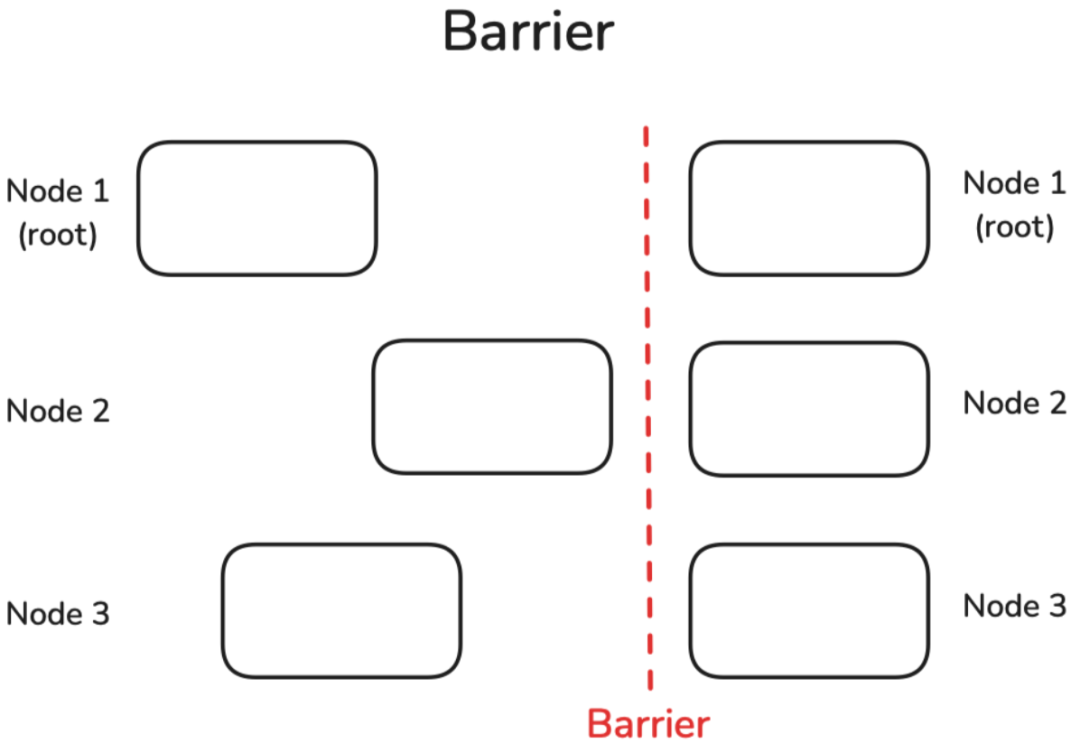
我们可以通过在每个节点上设置不同的睡眠时间来轻松模拟延迟的节点,然后看看它们通过Barrier所需的时间:
def example_barrier():
rank = dist.get_rank()
t_start = time.time()
print(f"Rank {rank} sleeps {rank} seconds.")
time.sleep(rank) # Simulate different processing times
dist.barrier()
print(f"Rank {rank} after barrier time delta: {time.time()-t_start:.4f}")
init_process()
example_barrier()
我们可以看到,尽管第一个排名没有睡眠,但它也需要2秒才能通过Barrier:
Rank 0 sleeps 0 seconds.
Rank 1 sleeps 1 seconds.
Rank 2 sleeps 2 seconds.
Rank 0 after barrier time delta: 2.0025
Rank 1 after barrier time delta: 2.0025
Rank 2 after barrier time delta: 2.0024
需要小心地进行这种方式的所有节点同步操作,因为这会打败并行独立操作的目的,可能会减慢整个处理速度。在许多情况下,如果快速节点已经开始处理下一个作业,这可能是可以接受的,因为快速节点在下一个迭代中可能会变慢,从而平衡整个过程中的延迟。
在转向实际分布式训练实现之前,先来了解:NCCL到底是什么?
NCCL:NVIDIA 集体通信库
当在许多GPU上训练大型模型时,经常会遇到NCCL!那是什么?
有几个实现集体通信 Collective Communication 的库,并得到PyTorch的支持:有经典的MPI(消息传递接口),有Meta的Gloo,最后还有 NCCL(NVIDIA集体通信库)。它们在集体通信模式方面提供类似的功能,但针对不同的硬件设置进行了优化;NCCL设计用于有效地服务GPU-GPU通信,而MPI和Gloo则设置为CPU-CPU或CPU-GPU通信。PyTorch提供了一个很好的指南 [2] 来决定使用哪一个:
-
GPU训练:使用NCCL -
CPU训练:使用Gloo
分布式训练性能分析
内核
假设内核已经集成到PyTorch中。作为一个简单的例子,我们可以查看在PyTorch中实现的Layer Normalization函数 torch.nn.functional.layer_norm。有几种方法可以分析此函数的核心。最直接的方法可能是使用Python的 time模块。然而,由于CUDA操作是异步的,使用这种方法测量时间只会捕获Python中启动内核的开销,而不是内核本身的实际执行时间。
为了解决这个问题,可以利用 torch.cuda.Event来进行准确的时间测量,并使用 torch.cuda.synchronize()指令确保等待内核执行完成。以下代码段展示了这种方法:
def profile_pytorch(func, input):
# 创建CUDA事件以跟踪时间。CUDA操作是异步的,
start = torch.cuda.Event(enable_timing=True) # 事件标记开始时间
end = torch.cuda.Event(enable_timing=True) # 事件标记结束时间
# 预热以消除第一次运行的任何开销,这可能不反映
# 实际性能。
for _ in range(10):
func(input)
# 在执行函数之前记录开始时间
start.record()
func(input) # 调用我们想要分析的函数
# 在函数完成后记录结束时间
end.record()
# 同步CUDA操作,以确保所有操作完成后再测量
torch.cuda.synchronize()
# 计算并返回耗时(毫秒)。
return start.elapsed_time(end)
更有效的性能分析方法是利用之前介绍的PyTorch Profiler。例如,考虑以下代码:
import torch
import torch.nn.functional as F
def pytorch_layer_norm(input):
return F.layer_norm(input, input.size()[1:])
a = torch.randn(10000, 10000).cuda()
with torch.profiler.profile(
activities=[
torch.profiler.ProfilerActivity.CPU, # 分析CPU活动
torch.profiler.ProfilerActivity.CUDA, # 分析CUDA活动
],
# 定义分析器的调度
schedule=torch.profiler.schedule(
wait=1, # 在开始分析之前等待1次迭代
warmup=3, # 进行3次迭代的预热,以稳定性能
active=2, # 进行2次活动迭代的分析
repeat=1, # 将分析调度重复一次
),
on_trace_ready=torch.profiler.tensorboard_trace_handler('.'),
) as p:
for iter in range(10):
pytorch_layer_norm(a)
p.step()
# 打印按总CUDA时间排序的汇总分析结果表,限制显示前8个条目
print(p.key_averages().table(sort_by="cuda_time_total", row_limit=8))
这将打印按总CUDA时间排序的汇总分析结果表,输出如下:

您还可以尝试在 chrome://tracing/ 上检查跟踪:
提示
如果您是第一次使用该工具,可以使用右箭头和左箭头键导航跟踪。此外,您还可以按住Alt键,同时使用鼠标左右滚动来放大和缩小。
放大后,可以观察调用 layer_norm 时操作流程的跟踪:

序列从CPU(上部分)开始,使用 aten::layer_norm,然后转到 aten::native_layer_norm,最后过渡到 cudaLaunchKernel。从那里,我们进入GPU,调用 vectorized_layer_norm_kernel 内核。
注意可以通过将分析器中的
profile_memory设置为True来启用内存分析。但这可能会导致更复杂的跟踪。
虽然PyTorch Profiler提供了快速的性能概述,但NVIDIA Nsight Compute (ncu) 提供了更深入的GPU性能洞察,包括每个内核的详细执行时间和内存使用情况。要运行分析器非常简单:
ncu --set full python layer_norm.py
这里的 layer_norm.py 是执行层归一化函数的简单文件。此命令将生成日志输出,但更有效的方法是通过设置输出标志来可视化结果:
ncu --set full -o output python layer_norm.py
然后使用Nsight Compute打开文件 output.ncu-rep,您将看到类似于以下的视图:

其中清晰地显示了关于计算和内存利用率的警告,以及如何优化内核以实现最大占用率。
CPP扩展
如果要分析的内核尚未集成到PyTorch中,您可以使用PyTorch的 cpp_extension 模块轻松编译和运行自定义CUDA代码。这个过程非常简单 —— 只需在 .cu 文件中创建您的CUDA内核,并使用 cpp_extension 模块中的 load 函数将其加载到Python中。
例如,一个简单的 add 内核的 .cu 文件如下:
#include
#include
#include
__global__ void add_kernel(float* x, float* y, float* output, int size) {
int index = blockIdx.x * blockDim.x + threadIdx.x;
if (index < size) {
output[index] = x[index] + y[index];
}
}
void add_cuda(torch::Tensor x, torch::Tensor y, torch::Tensor output) {
int threads = 1024;
int blocks = (x.size(0) + threads - 1) / threads;
add_kernel<<>>(x.data_ptr(), y.data_ptr(), output.data_ptr(), x.size(0));
}
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("add_cuda", &add_cuda, "Vector addition (CUDA)");
}
以及用于加载内核的Python文件:
import torch
from torch.utils.cpp_extension import load
# 加载并编译CUDA扩展
vector_add = load(
name="vector_add",
sources=["add_kernel.cu"],
verbose=True
)
# 定义输入张量
size = 10000
x = torch.randn(size, device='cuda')
y = torch.randn(size, device='cuda')
output = torch.empty(size, device='cuda')
# 运行CUDA内核
vector_add.add_cuda(x, y, output)
使用这种方法,您可以像之前展示的那样,使用PyTorch的分析器或NVIDIA工具来分析自定义CUDA内核。
计算LLM 训练中的规模
让我们了解LLM训练中的典型尺度。当我们谈论内存或计算时,通常是在计算“元素” – 可以将其视为张量中的数值。要得到实际的内存占用(以字节为单位),您需要乘以每个数字的大小(例如,bf16为2字节,fp32为4字节)。
以下是一些快速的粗略估计:
-
输入令牌(Input tokens):对于每个批次,我们处理 个令牌,其中mbs是微批次大小,seq是序列长度。 -
激活(隐藏状态)(Activations (hidden states)):对于单个层,隐藏状态张量的大小为 个元素。 -
模型权重和梯度(Model weights and gradients):模型中的每个权重矩阵(如线性层中的)大约有 个元素。这是每个权重矩阵的元素数量。梯度与权重的大小相同。 -
优化器状态(Optimizer states):对于每个权重矩阵(元素数量为 ),如果你使用像Adam这样的优化器进行混合精度训练,它会在fp32精度下保留动量和方差状态( ),以及主权重在fp32( )。因此,每个权重矩阵的总优化器状态将约为 。 -
总模型参数:对于每个transformer块: -
输入嵌入: -
LM头: (如果不与输入嵌入绑定) -
位置嵌入(如果使用): -
Gate和Up Proj: 参数(2个大小为 的矩阵) -
Down Proj: 参数(1个大小为 的矩阵) -
QKV投影: 参数 -
输出投影: 参数 -
注意力参数: -
带有GLU的MLP参数: -
每个块的总参数:使用GLU MLPs时为 ,不使用GLU时为 -
对于完整模型: (使用GLU) -
额外参数: -
前向和反向传递计算(FLOPs):前向传递的FLOPs的非常粗略的估计为 。反向传递计算是前者的两倍: 。
计算/通信重叠需要的计算
使用前一节中的公式,我们可以估计在分布式训练中计算和通信何时可以有效重叠。让我们以数据并行(Zero-0)为例。
数据并行DP通信分析
需要通信的总梯度大小为:
-
梯度 = 参数 ≈
在反向传递过程中,这些梯度以Buckets(默认25MB)的形式进行通信。每个桶的AllReduce通信时间为:
注意:对于带宽计算,我们使用来自 NCCL文档 [3] 的总线带宽公式。这些公式考虑了在计算GPU之间计算有效带宽时的具体通信模式。
编者注: Peak_bw 代表 Peak Bandwidth; DP代表DP度,可以简单理解为有多少卡使用DP。
反向传递的计算时间为:
为了有效重叠,我们需要:
这个比率有助于确定通信是否会成为训练中的瓶颈。当比率小于1时,通信可以与计算完全重叠。
Zero-3 (FSDP) 通信分析
对于 Zero-3,参数和梯度在 GPU 之间共享。让我们分析一个具有每个大小为 参数的 transformer 块的模型的通信模式:
-
对于前向传播中的每个 transformer 块: -
AllGather:每个 rank 字节 -
对于反向传播中的每个 transformer 块: -
AllGather:每个 rank 字节 -
ReduceScatter:每个 rank 字节 -
每个块的总通信: 字节 -
整个模型的总通信: 字节
AllGather 的通信时间是:
一个解码器层的前向传播的计算时间是:
为了有效地在计算和通信之间进行重叠,我们需要:
当这个比率小于 1 时,下一层的参数通信可以隐藏在当前层的计算之后。
TP 通信分析
对于张量并行 (TP),在线性层期间激活值在 GPU 之间被分片。让我们分析通信模式:
-
对于前向传播中的每个列线性层: -
AllGather 激活值:每个 rank 字节 -
对于反向传播中的每个列线性层: -
ReduceScatter:每个 rank 字节 -
对于行线性层反之亦然。每个 transformer 块有 2 个列线性层和 2 个行线性层。 -
每个块的总通信: 字节 -
整个模型的总通信: 字节
让我们分析我们是否可以将一层的收集器通信与下一层线性层的计算重叠。收集操作的通信时间是:
而下一个线性层(具有参数 )的计算时间是:
为了有效重叠,我们希望通信时间小于计算时间:
这个比率告诉我们我们是否可以成功地将收集器通信隐藏在下一个线性层的计算之后。有趣的是,这个比率仅取决于隐藏大小 和张量并行度 TP,而不是序列长度或批量大小。
PP 通信分析
对于流水线并行 (PP),激活值和梯度在流水线阶段之间进行通信。让我们分析通信模式:
-
对于前向传播中的每个微批次: -
接收和发送激活值: 字节 -
对于反向传播中的每个微批次: -
接收和发送梯度: 字节 -
每个Micro Batch的总通信: 字节 -
对于梯度累积步骤 (gas),总通信: 字节
让我们分析我们是否可以将激活值/梯度的通信与下一个 transformer 块的计算重叠。下一个流水线阶段中 transformer 块的计算时间是:
而 P2P 传输的通信时间是:
为了有效重叠,我们希望:
与 TP 类似,这个比率与序列长度和批量大小无关。它取决于隐藏大小 ,下一个流水线阶段中的层数,以及计算与硬件 P2P 带宽能力的比率。
编者注:全书结束,感谢阅读。
Reference
[1] https://pytorch.org/docs/stable/distributed.html#torch.distributed.ReduceOp
[2] https://pytorch.org/docs/stable/distributed.html#which-backend-to-use
(文:GiantPandaCV)