
地瓜机器人团队 投稿
量子位 | 公众号 QbitAI
让机器人精准抓起透明物体,这个难题终于被解决了。
而且还是仅靠一张图、单目的那种方法。
效果是这样的:

这就是由地瓜机器人和中科院自动化所等单位共同提出的一项新研究——
MODEST,一个针对透明物体的单目深度估计和语义分割的多任务框架。

MODEST算法框架作为通用抓取模型的前置模块,即插即用,灵活高效,且无需依赖额外传感器。
并且仅靠单张RGB图像,便可实现透明物体的抓取,效果上甚至要优于其它双目和多视图的方法。
可以广泛应用于智能工厂、实验室自动化、智慧家居等场景,降低设备成本并大幅提升机器人对透明物体的操作能力。
值得一提的是,这项研究已经入选全球机器人领域顶会ICRA 2025(IEEE机器人与自动化国际会议)。
如何做到的?
当前透明物体的抓取核心在于深度信息的获取,目前无论是深度传感器还是多视角重建的方法都无法获取透明物体准确完整的深度信息。
透明物体复杂的折射和反射特性给机器人感知造成了很大困难。在大多数RGB图像中的透明物体往往缺乏清晰的纹理,而容易与背景混为一体。
此外,商用深度相机也难以准确捕捉这些物体的深度信息,导致深度图缺失或噪声过多,从而限制了机器人在多个领域的广泛应用。
为了解决透明物体感知难题,传统方法大多依赖特殊传感设备或多视角图像,增加了时间和经济成本,并常常受限于应用场景。
MODEST单目框架首次突破了传统传感器处理透明物体时的限制,降低了设备成本和使用复杂度,提供了更加高效、经济和便捷的透明物体感知方案。
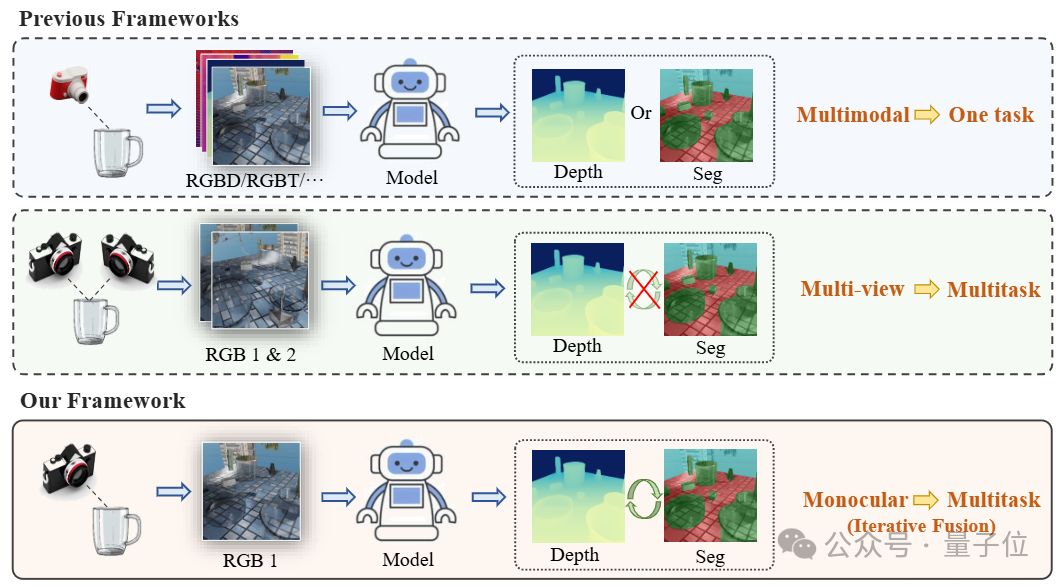
△单目透明物体感知框架与其他方法之间的对比
MODEST主要聚焦于透明物体的深度估计,通过设计的语义和几何结合的多任务框架,获取物体准确的深度信息,之后结合基于点云的抓取网络实现透明物体的抓取。
相当于在通用抓取网络前面增加一个针对透明物体的增强模块。
MODEST模型的整体架构如图所示,输入为单目RGB图像,输出为透明物体的分割结果和场景深度预测。
网络主要由编码、重组、语义几何融合和迭代解码四个模块组成。
输入图像首先经过基于ViT的编码模块进行处理,随后重组为对应分割和深度两个分支的多尺度特征。
在融合模块中对两组特征进行混合和增强,最后通过多次迭代逐步更新特征,并获得最终预测结果。

△基于语义几何融合和迭代策略的透明物体单目多任务框架
对于透明物体来说,语义分割任务可以为深度估计提供语义和上下文信息,而同样深度估计可以为分割提供边界、表面等几何信息。
为了充分挖掘两个任务间的互补信息,MODEST 算法框架构建了基于注意力机制的语义几何融合模块,旨在同时提升两个任务的性能。
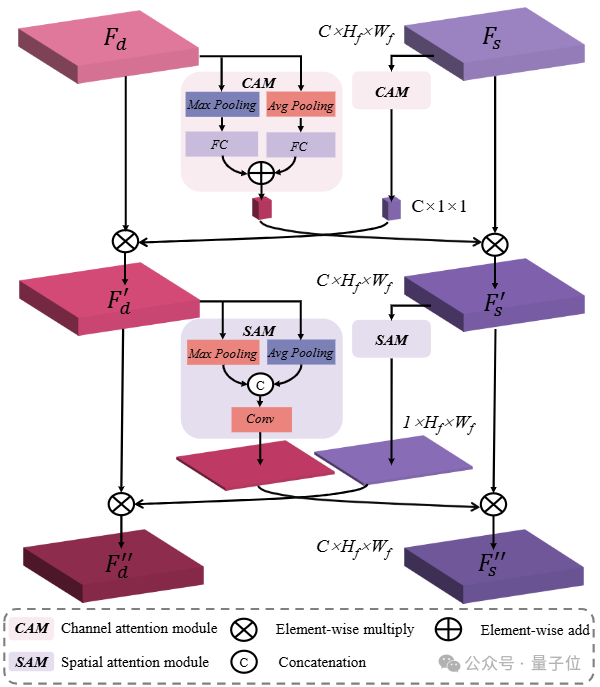
△语义几何融合模块结构
当人类观察透明物体等不显著物体时,我们人类会倾向于先注意物体的整体轮廓,然后是局部细节。受人眼启发,MODEST框架提出了一种由粗到细的特征更新策略,进一步提升预测精度。
实验结果
为了测试MODEST全新算法框架的检测效果,团队选取了透明物体领域两个影响力广泛的公开仿真数据集Syn-TODD和真实数据集ClearPose。
在其上与目前最先进的透明物体双目方法SimNet、多视图方法MVTran以及多任务方法InvPT和TaskPrompter进行对比实验。
两个大规模数据集都拥有超过100k的良好标注图像数据,并且包含了严重遮挡等极端场景。
1、公开数据集上的定性和定量对比实验
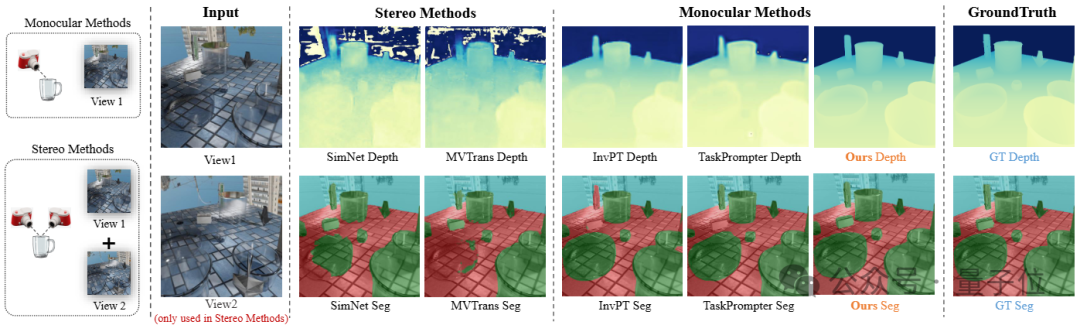
△仿真数据集Syn-TODD上的定性对比结果
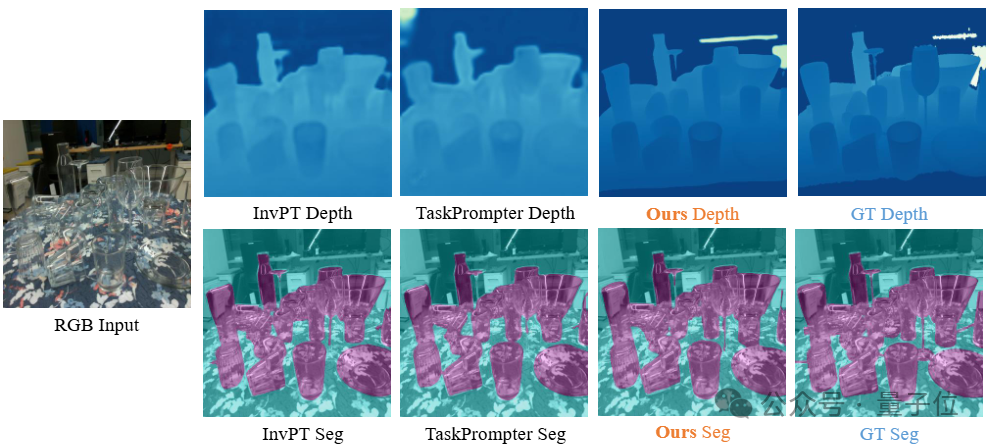
△真实数据集ClearPose上的定性对比结果
通过在两个数据集上的定性对比结果可以看出,由于透明物体会错误地折射背景,并且在RGB图像中缺乏纹理,因此SimNet、MVTrans等方法无法获得令人满意的预测,从而导致深度图和分割掩膜的大面积缺失。
然而,通过有效的融合和迭代,在某些即使人眼都难以分析和判断的场景,团队的方法依然能够产生完整和清晰的预测结果。
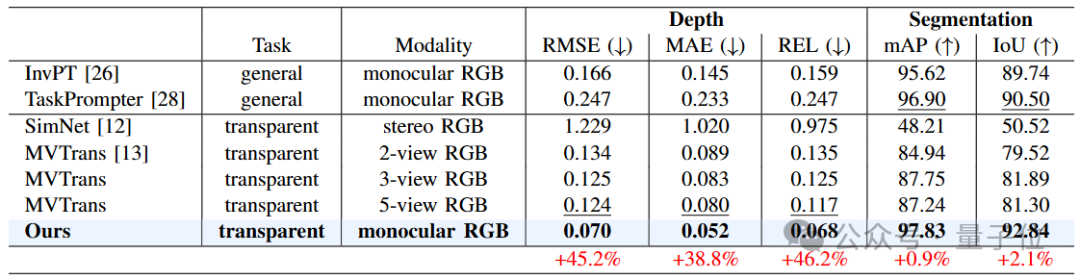
△仿真数据集Syn-TODD上的定量对比结果
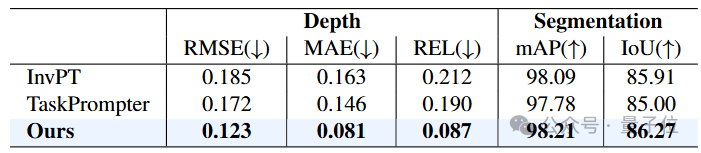
△真实数据集ClearPose上的定量对比结果
从表格中的定量对比可以看出,MODEST算法框架在各项指标上都要大幅超过其他所有方法。
值得注意的是,尽管只使用单张RGB图像作为输入,MODEST在深度估计和语义分割方面都要明显优于其他双目甚至多视图方法。
并且在Syn-TODD数据集上,与排名第二的方法相比,MODEST算法框架在RMSE和REL两项指标有着超过45%的提升,语义分割的精度也均超过了90%。
2、真实平台抓取实验
团队还将算法迁移到真实机器人平台,开展了透明物体抓取实验。
平台主要由UR机械臂和深度相机构成,在借助MODEST方法进行透明物体精确感知的基础之上,采用GraspNet进行抓取位姿的生成。
在多个透明物体上的实验结果表明,MODEST方法在真实平台上具有良好的鲁棒性和泛化性。
One More Thing
值得一提的是,除了MODEST之外,地瓜机器人主导研发的DOSOD开放词汇目标检测算法,也入选了ICRA 2025。
MODEST是通过动态语义理解框架提升复杂场景识别准确率,而DOSOD则是结合几何建模与语义分析技术优化透明物体操作精度。
两项技术成果均已在规模化商业场景中得到有效验证。
感兴趣的小伙伴可以戳下方链接了解详情哦~
MODEST文章地址:
https://arxiv.org/pdf/2502.14616
MODEST代码地址:
https://github.com/D-Robotics-AI-Lab/MODEST
DOSOD文章地址:
https://arxiv.org/abs/2412.14680
DOSOD代码地址:
https://github.com/D-Robotics-AI-Lab/DOSOD?tab=readme-ov-file
学术投稿请于工作日发邮件到:
ai@qbitai.com
标题注明【投稿】,告诉我们:
你是谁,从哪来,投稿内容
附上论文/项目主页链接,以及联系方式哦
我们会(尽量)及时回复你

一键关注 👇 点亮星标
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
(文:量子位)