


智东西3月6日报道,今日凌晨,阿里云发布最新推理模型QwQ-32B,性能媲美DeepSeek-R1,在消费级显卡上也能实现本地部署。
该模型在Hugging Face和ModelScope上以Apache 2.0许可证开源。这意味着它可用于商业和研究用途,因此企业可以立即使用它来为他们的产品和应用程序提供动力(即使是他们向客户收费使用的产品和应用程序)。
Hugging Face地址:
huggingface.co/Qwen/QwQ-32B
魔搭社区地址:
https://modelscope.cn/models/Qwen/QwQ-32B

聚焦DeepSeek的颠覆与重构!4月1-2日,智东西参与主办的2025中国生成式AI大会(北京站)举办。50+位嘉宾将围绕GenAI应用、大模型、DeepSeek R1与推理模型、AI智能体和具身智能大模型等重要议题进行分享和讨论。欢迎报名~
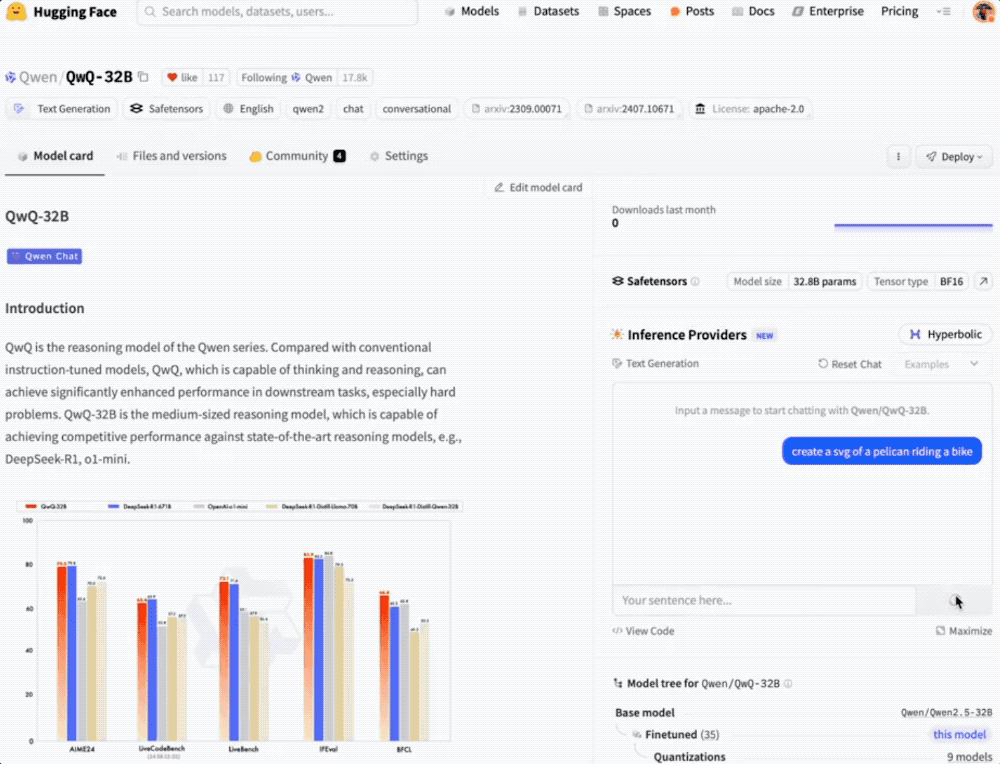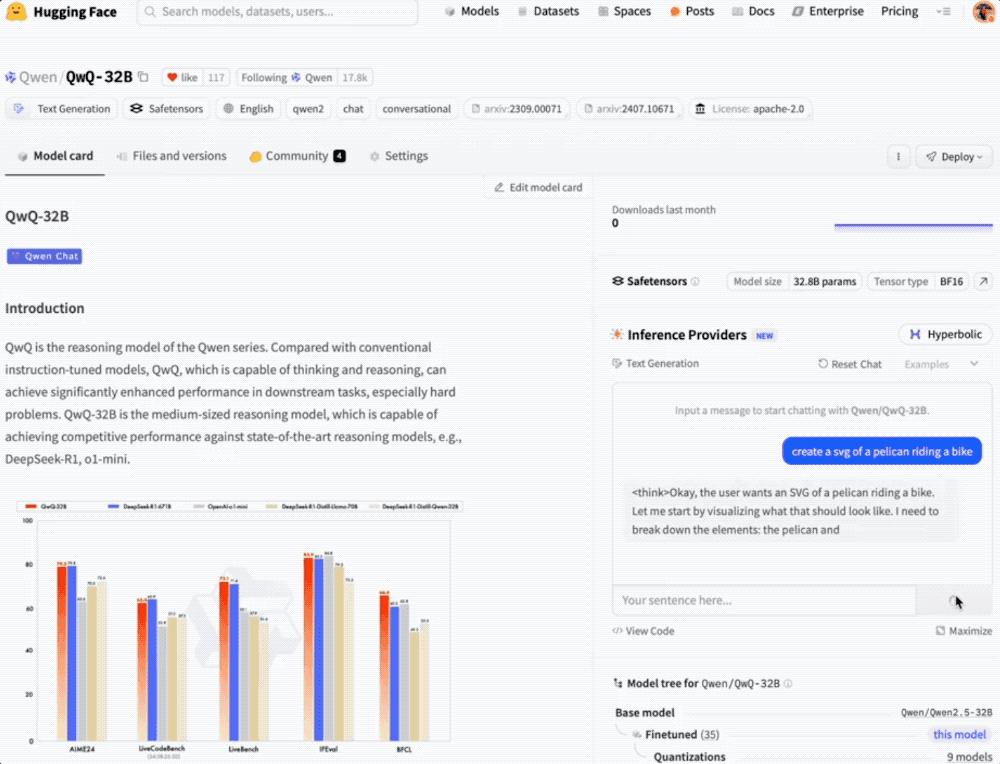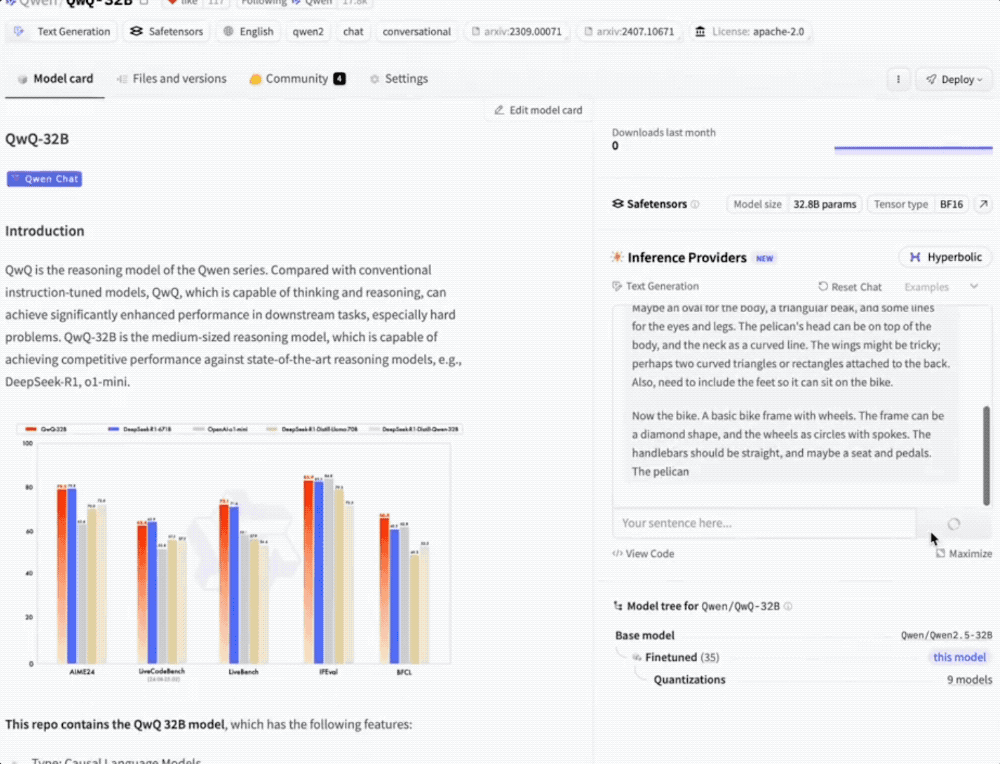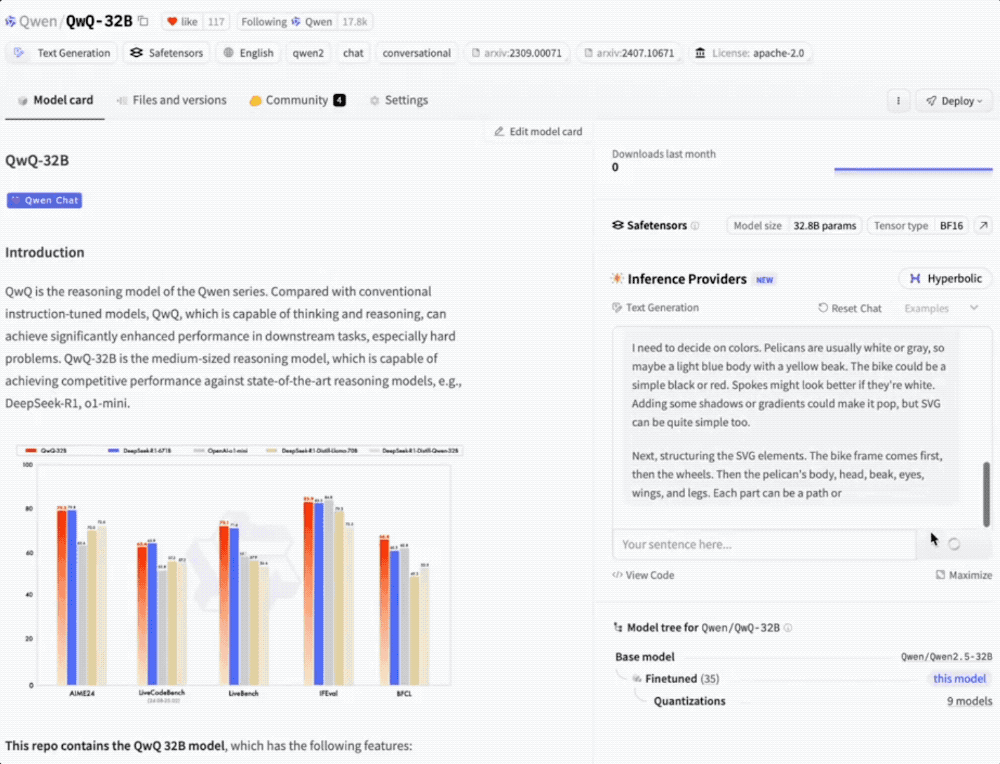
QwQ-32B与DeepSeek-R1-Distilled-Qwen-32B、DeepSeek-R1-Distilled-Llama-70B、o1-mini以及DeepSeek-R1进行了对比。
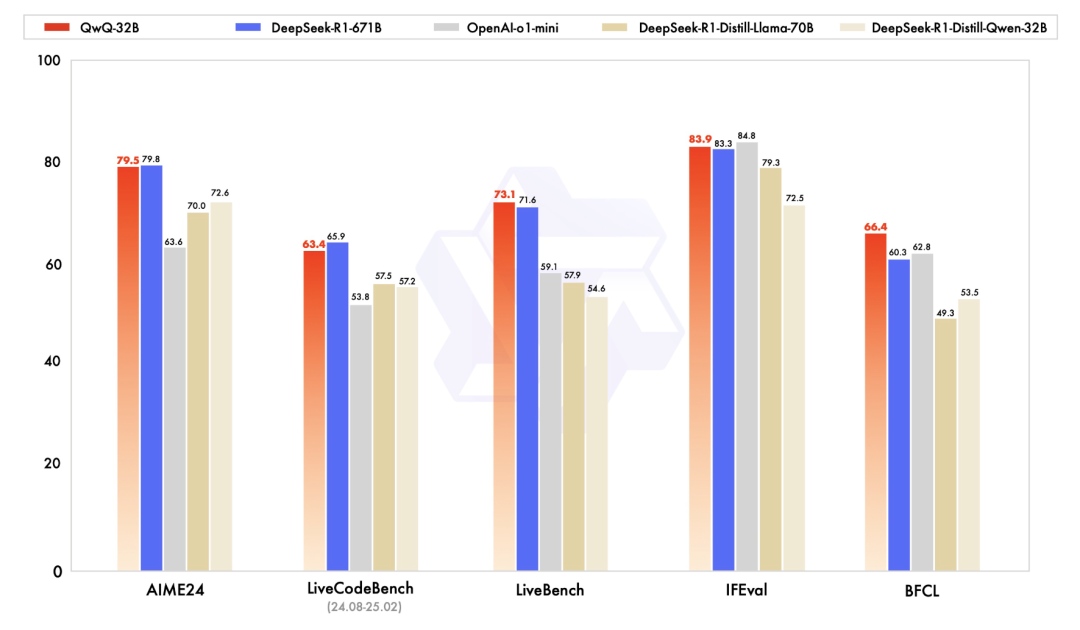
在测试数学能力的AIME24评测集以及评估代码能力的LiveCodeBench中,QwQ-32B表现与DeepSeek-R1相当,强于o1-mini及相同尺寸的R1蒸馏模型。
在由Meta首席科学家杨立昆领衔的“最难LLMs评测榜”LiveBench、谷歌等提出的指令遵循能力IFEval评测集、由加州大学伯克利分校等提出的评估准确调用函数或工具方面的BFCL测试中,QwQ-32B得分超越DeepSeek- R1。
社交平台X上的网友已经为之疯狂,到处充斥着“太震惊了”的言论。
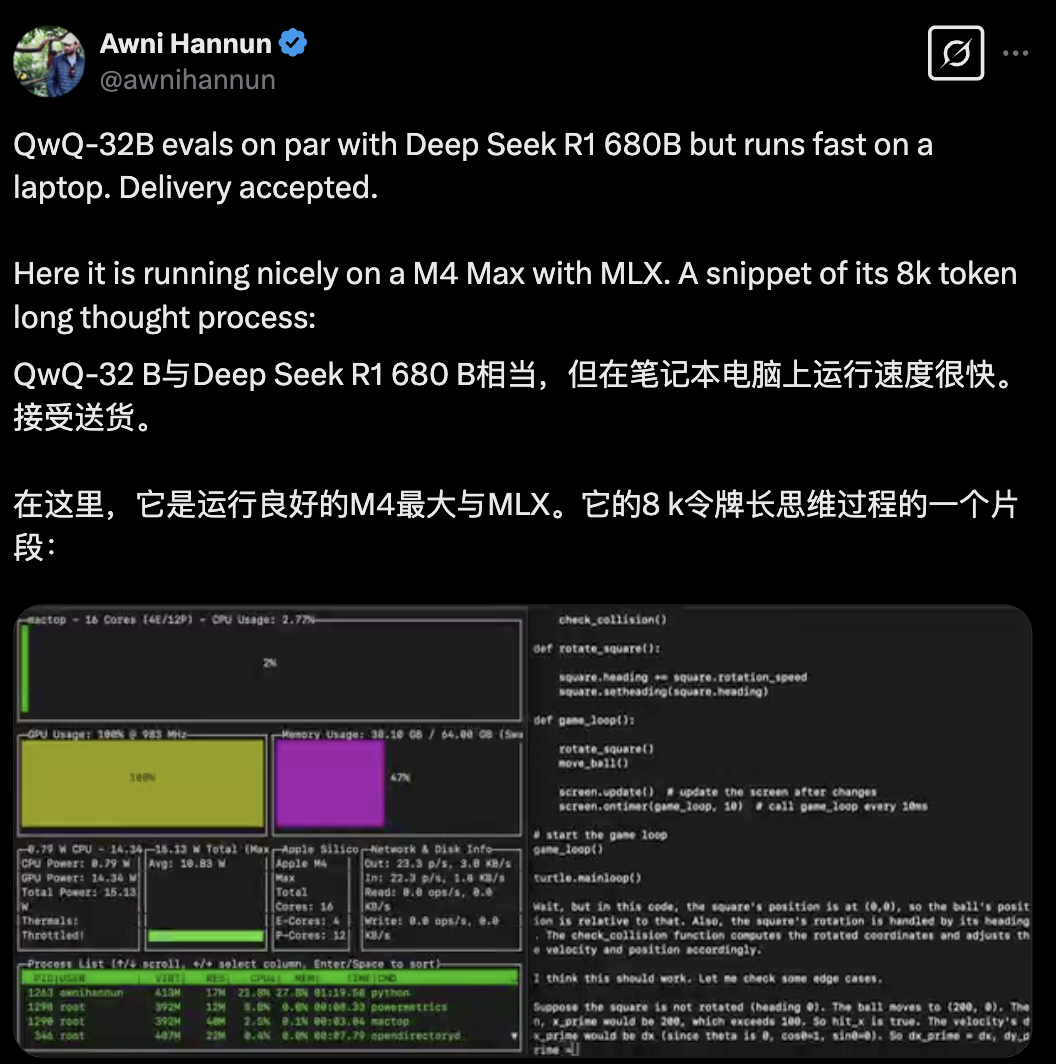
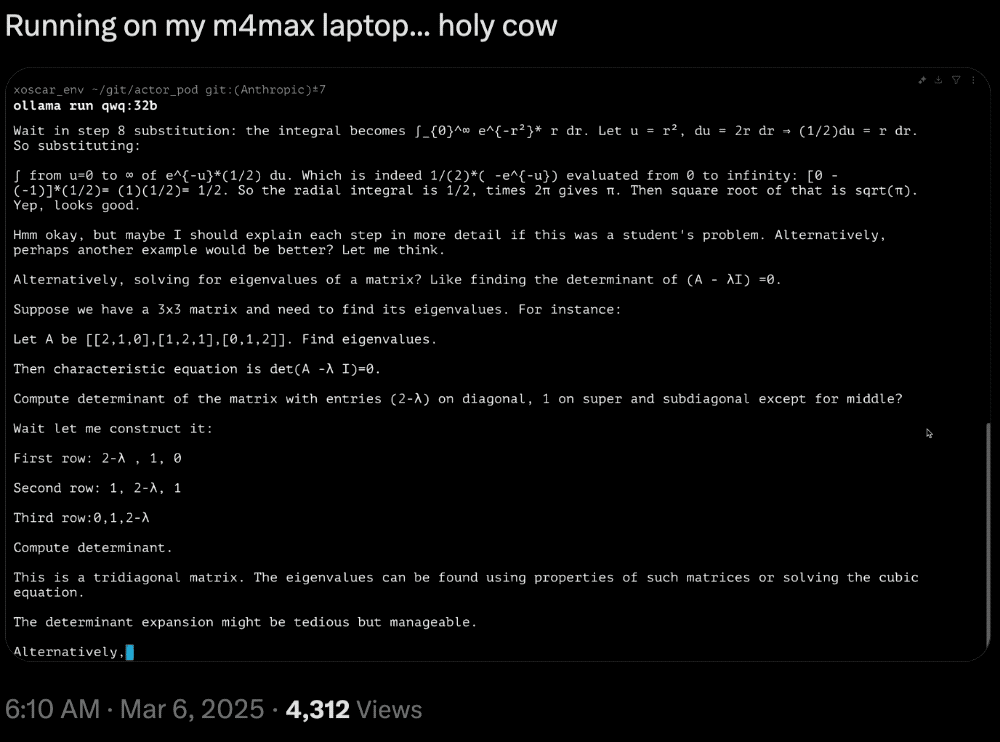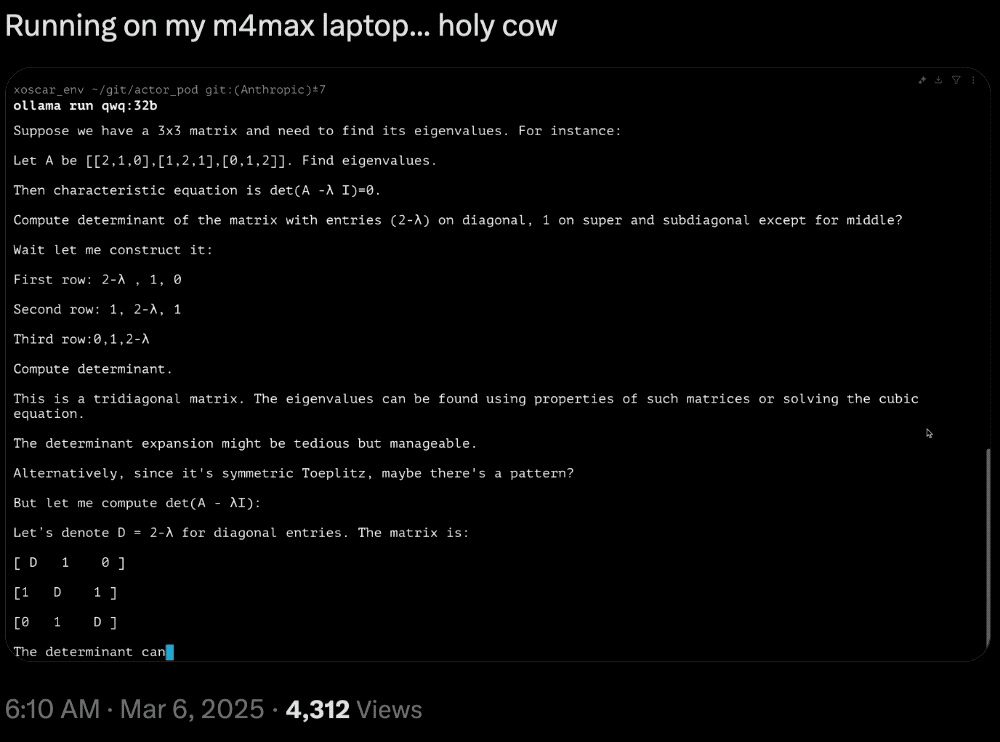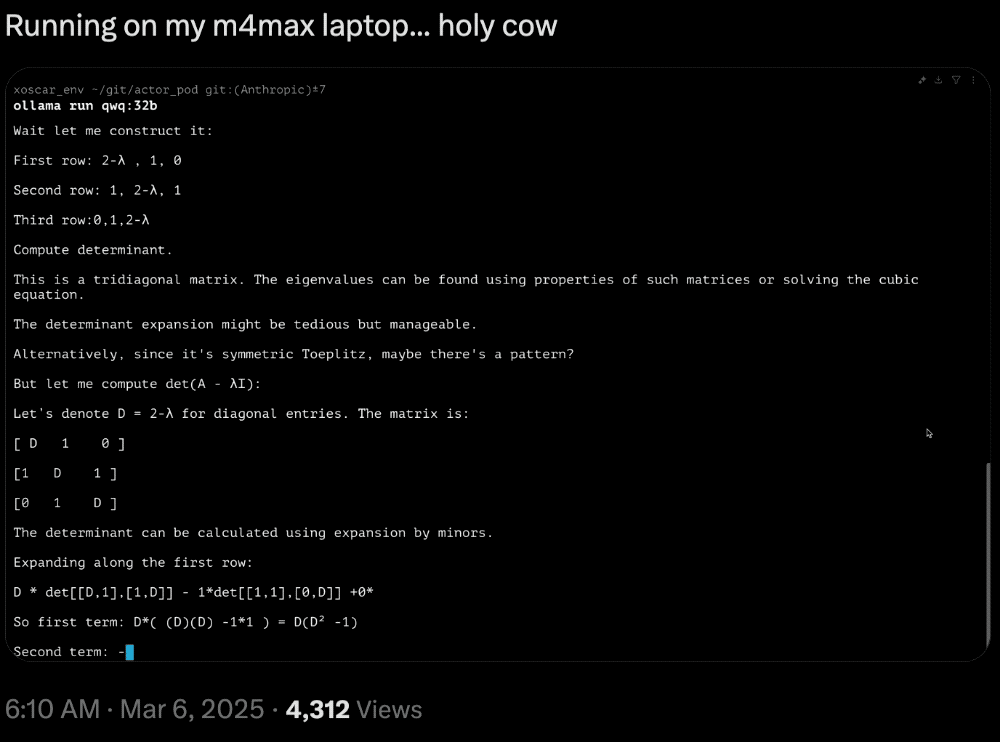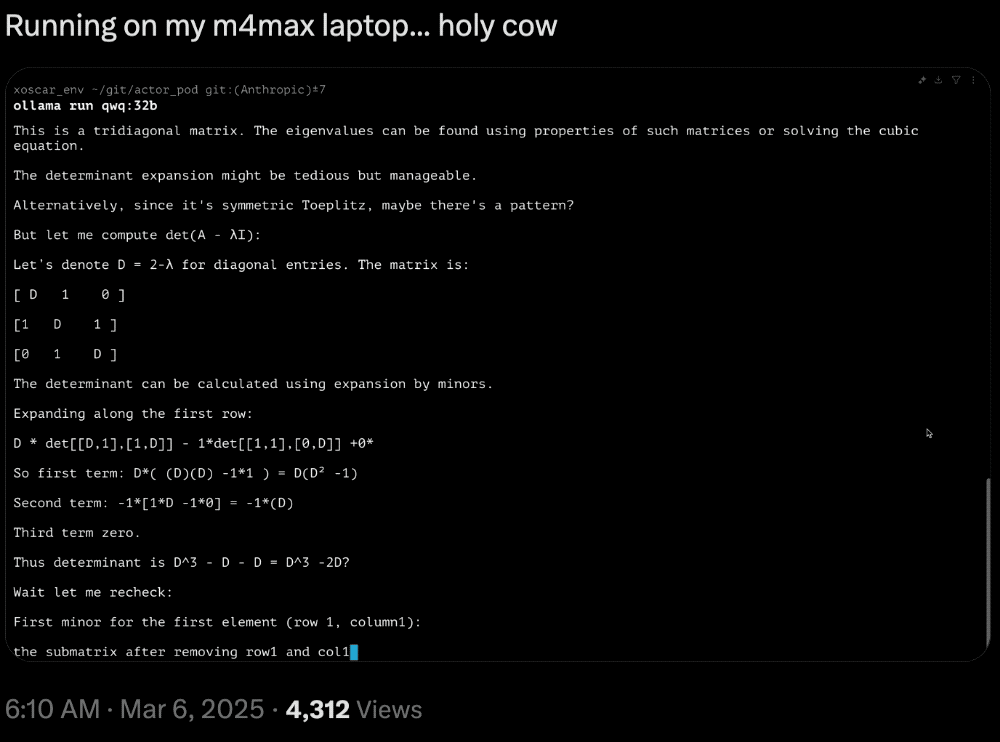
机器学习爱好者Vaibhav (VB) Srivastav强调了QwQ-32B的推理速度,称其“非常快”,可与顶级模型相媲美。
网友晒出了在M4 Max芯片的MacBook上运行的推理速度:
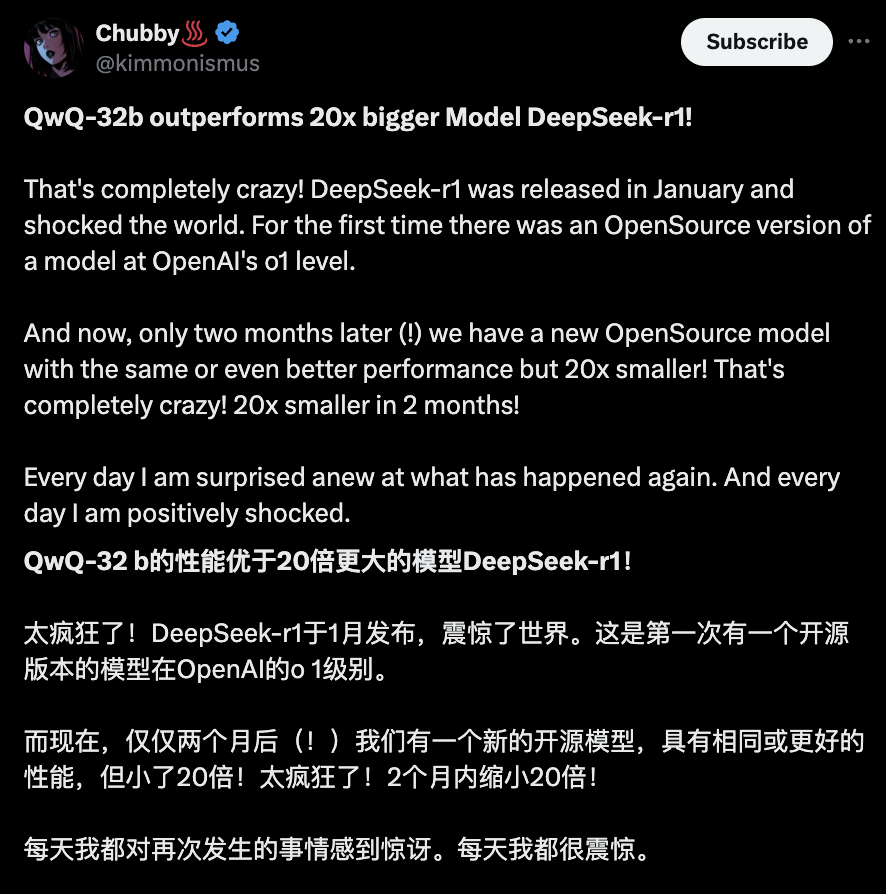
AI新闻发布者@Chubby称QwQ-32 B太疯狂了!

有网友尝试了QwQ-32B的编码能力,并称赞其是o1-mini级别的可本地部署模型。他的提示词是”Create an amazing animation using p5js(“使用p5.js创建一个精彩的动画”)。效果如下:

不过也有网友指出,巨大的尺寸差异意味着用户需要大约5%的高带宽内存来进行推理。

研究人员在冷启动的基础上开展了大规模强化学习。在初始阶段,他们特别针对数学和编程任务进行了强化学习训练。
与依赖传统的奖励模型(reward model)不同,他们通过校验生成答案的正确性来为数学问题提供反馈,并通过代码执行服务器评估生成的代码是否成功通过测试用例来提供代码的反馈。随着训练轮次的推进,这两个领域中的性能均表现出持续的提升。
QwQ-32B的强化学习过程分两个阶段执行:
数学和编码重点:使用用于数学推理的准确性验证器和用于编码任务的代码执行服务器来训练该模型。这种方法确保生成的答案在被强化之前被验证正确性。
通用能力增强:在第二阶段,模型使用通用奖励模型和基于规则的验证器接受奖励训练。这个阶段改进了指令遵循、人类对齐和代理推理,而不影响其数学和编码能力。
QwQ-32B遵循因果语言模型架构,并包括几个优化:
1、64个Transformer层,具有RoPE、SwiGLU、RMS Norm和Attention QKV偏置;
2、分组查询注意力(GQA),40个attention heads用于查询,8个attention heads用于键值对(key-value pairs);
3、扩展了131072个Tokens的上下文长度,允许更好地处理长序列输入;
4、多阶段训练,包括预训练,监督微调和RL。
凭借其强化学习驱动的推理能力,该模型可以提供更准确、结构化和上下文感知的见解,使其可用于自动化数据分析、战略规划、软件开发和智能自动化等用例具有价值。
为了获得最佳性能,通义千问团队建议使用以下设置:
此外,该模型支持使用vLLM(一种高吞吐量推理框架)进行部署。然而,vLLM的当前实现仅支持静态YaRN缩放,即无论输入长度如何,都保持固定的缩放因子。
基于QwQ-32B,研究人员将强化学习定位为下一代AI模型的关键驱动力,证明可以产生高性能和有效的推理系统。
其博客中还提到,通义千问团队计划:进一步探索扩展RL以提高模型智能;将Agent与RL集成用于长时间推理;继续开发为RL优化的基础模型;通过更先进的训练技术向通用人工智能发展。
这是通义千问团队通过大规模强化学习以增强推理能力方面的第一步,其扩展了强化学习的巨大潜力,同时还展现出预训练语言模型中尚未开发的可能性。
(文:智东西)