
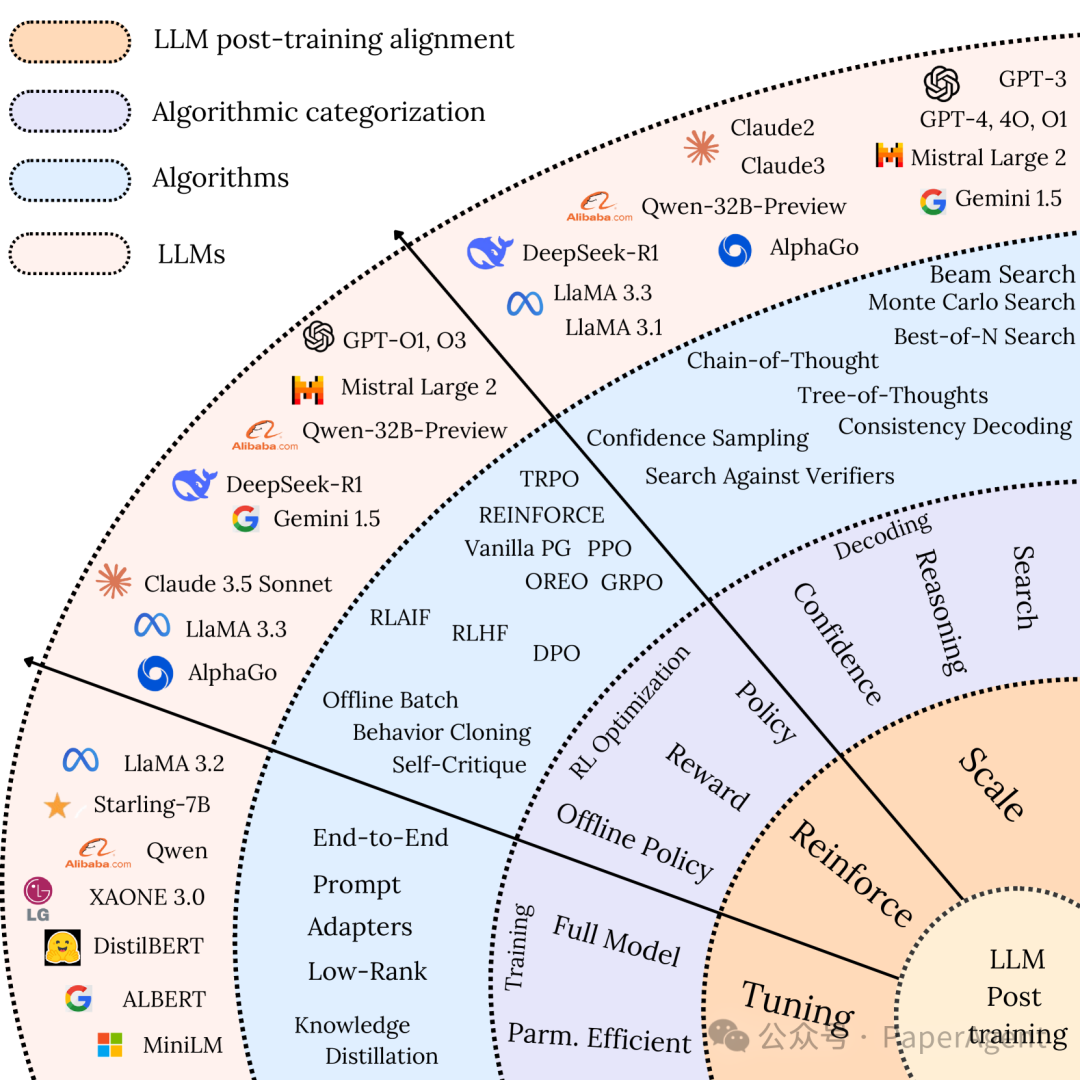
后训练方法的关键结论和趋势:
-
微调的局限性:微调可以提高LLMs在特定任务上的性能,但可能会导致过拟合和对新领域的泛化能力下降。
-
强化学习的有效性:强化学习能够通过动态反馈优化LLMs的行为,使其更符合人类偏好,但需要处理复杂的奖励结构和高维输出。
-
测试时扩展的潜力:测试时扩展通过在推理时调整计算资源,可以在不增加模型参数的情况下提高LLMs的性能,尤其在资源受限或任务复杂的情况下表现出色。

LLMs的后训练方法分为三大类:微调(fine-tuning)、强化学习(reinforcement learning)和测试时扩展(test-time scaling)。
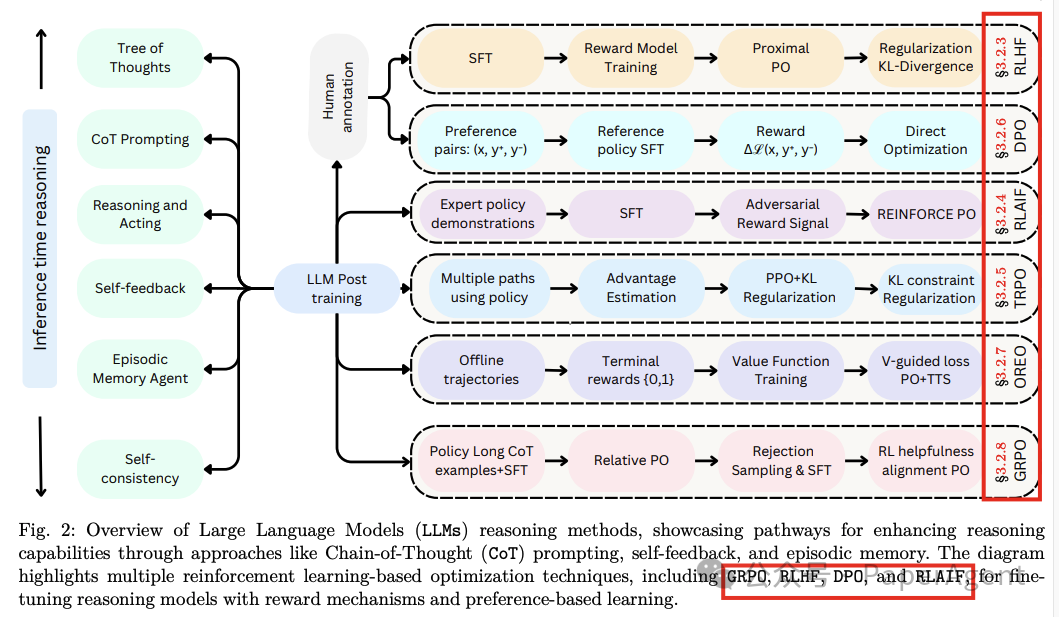
强化学习(Reinforcement Learning)
-
定义:强化学习通过动态反馈和优化序列决策来增强LLMs的适应性。
-
挑战:与传统强化学习不同,LLMs的强化学习面临着高维动作空间、主观和延迟的奖励信号,以及需要平衡多个目标的复杂性。
-
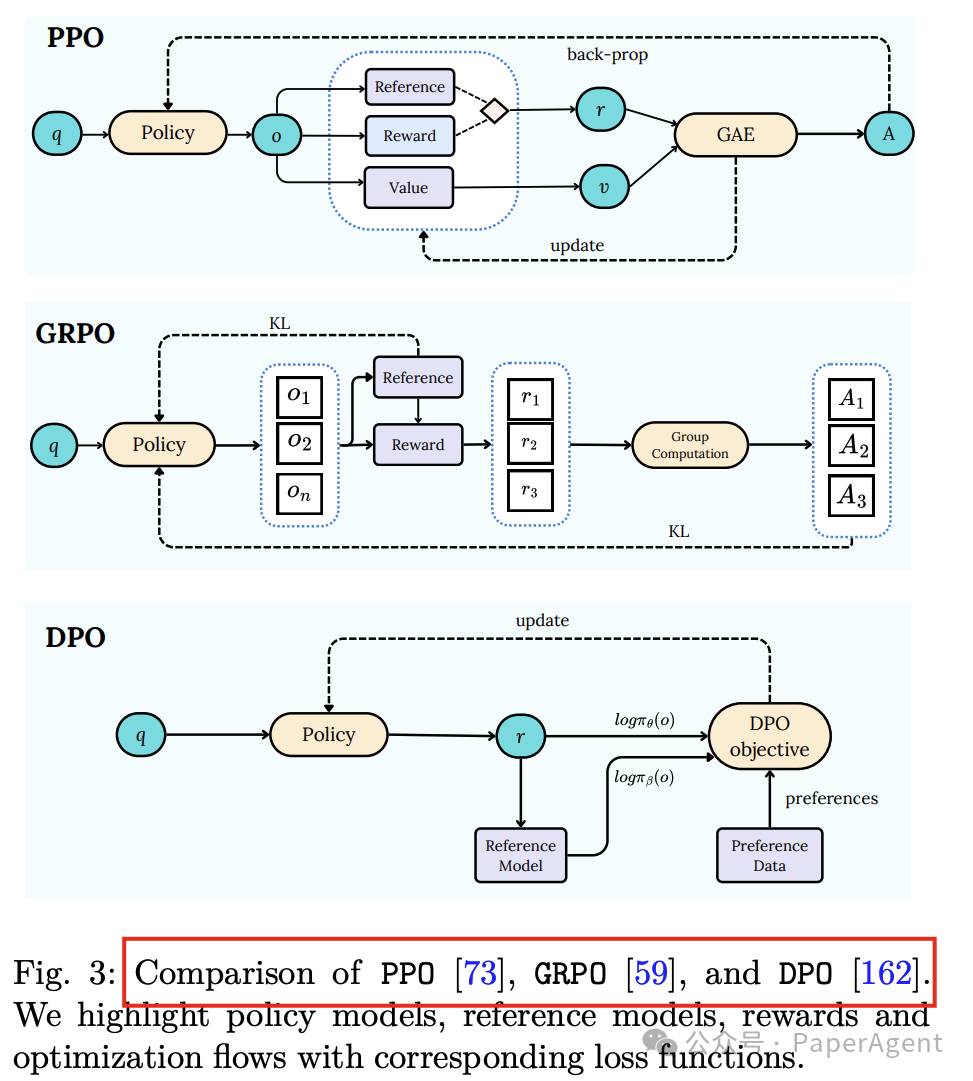
方法:讨论了多种强化学习方法,包括直接策略优化(DPO)、群体相对策略优化(GRPO)和近端策略优化(PPO)等,这些方法通过不同的策略来优化LLMs的行为,使其更符合人类偏好。
-
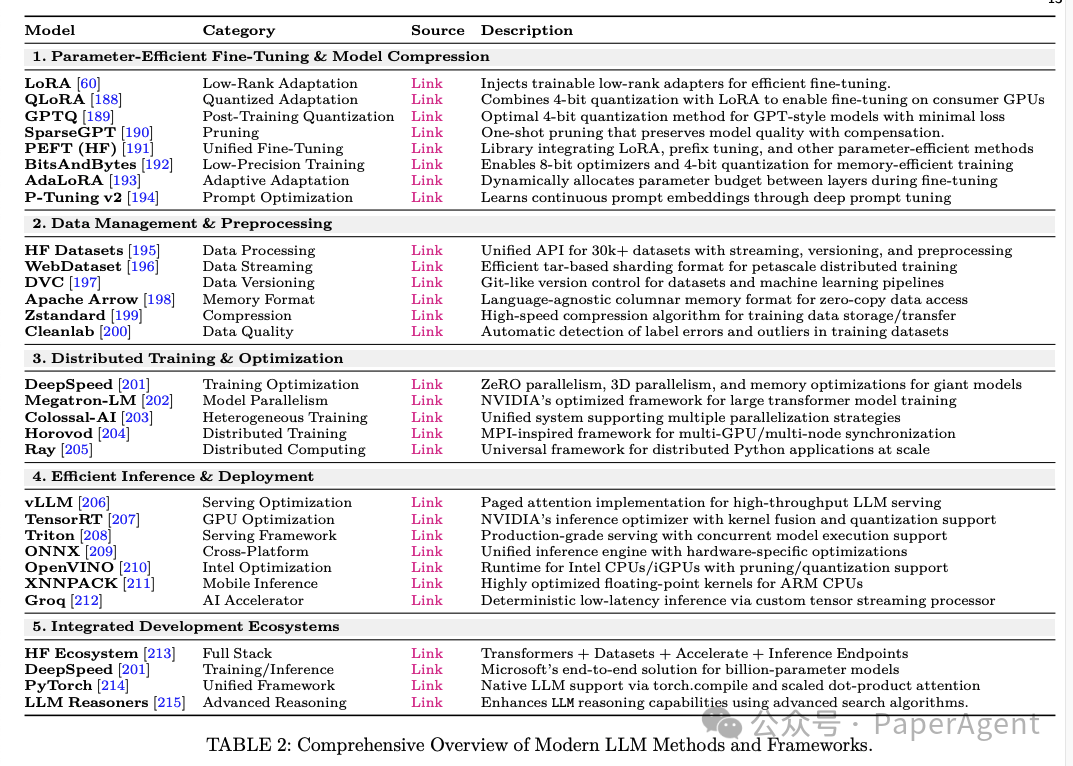
定义:微调是通过在特定任务或领域的数据集上更新预训练模型的参数,使其适应特定任务或领域。
-
挑战:微调可能会导致过拟合、高计算成本和对数据偏差的敏感性。
-
参数高效技术:为了应对这些挑战,提出了参数高效的技术,如 LoRA 和 adapters,这些技术通过更新显式参数来学习任务特定的适应性,显著减少了计算开销。
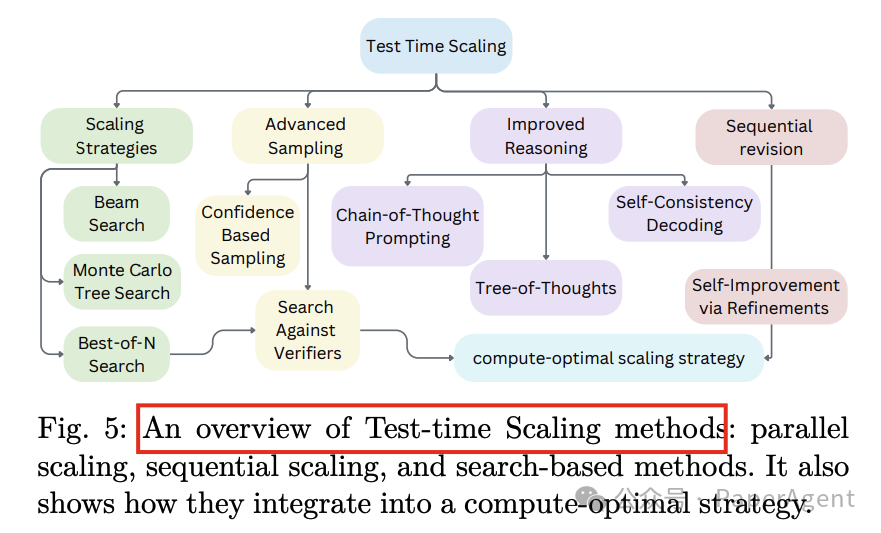
测试时扩展(Test-time Scaling)
-
定义:测试时扩展通过在推理时动态调整计算资源来优化LLMs的性能。
-
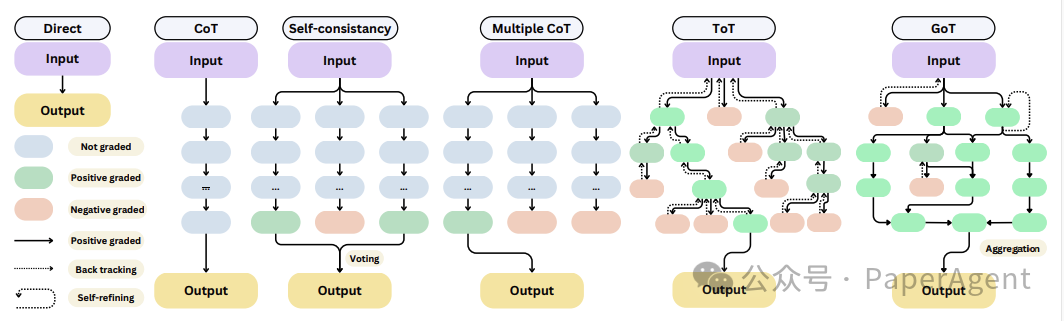
方法:包括链式思考(Chain-of-Thought)、树状思考(Tree-of-Thoughts)、蒙特卡洛树搜索(MCTS)等,这些方法通过分解复杂问题或迭代探索可能的输出来提高LLMs的推理能力。
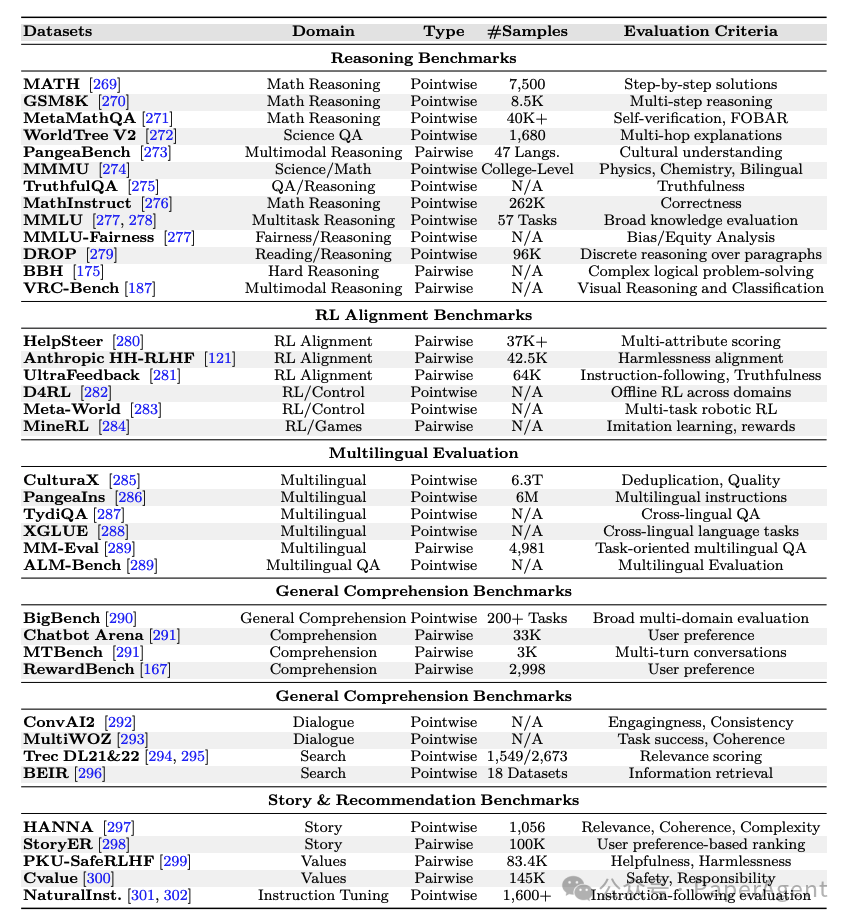
https://arxiv.org/pdf/2502.21321LLM Post-Training: A Deep Dive into Reasoning Large Language Modelshttps://github.com/mbzuai-oryx/Awesome-LLM-Post-training
(文:PaperAgent)