

今天是2025年4月2日,星期三,北京,天气晴。
最近关于Agent的新闻不少,前有manus,后有智谱AutoGLM沉思,都引起了大家的关注。
这其实引出来一个观点,关于Agent研发重心。文章(https://mp.weixin.qq.com/s/2gF8eEDOF5oBKMBUxnXc9g)中,认为Agent发展要”模型进,工程退“,强调最终智能体应用会回归以模型为核心的结构,而非像Manus这样的工程化解决方案;也就是坚持”反共识”观点,坚持预训练大模型的重要性,认为它是大模型推理能力的天花板,即使当前行业关注度不高。
这个观点,是认同的,但其是从根上讲的,而不从快速变现角度上说的。如果是要快速变现,那么就在工程上做优化,做雕花。如果要从根上解决问题,那就老老实实地去优化大模型本身。
因此,我们来看一个工作,DeeResearch用在Github场景的实现,通过设置一个较长链路的解决方案,来辅助找到GitHub上最佳仓库的深度研究Agent。
另外就是,既然说到要做“模型进,工程退”,那么就需要知道如何做模型优化,因此,我们来看看一个实现的技术总结。
抓住根本问题,做根因,专题化,体系化,会有更多深度思考。大家一起加油。
一、DeeResearch用在Github场景的实现拆解
DeeResearch这类用在github场景,就变成了DeepGit,用于辅助找到GitHub上最佳仓库的深度研究Agent,https://github.com/zamalali/DeepGit,是个编排好的流程。
可以看下最终效果:
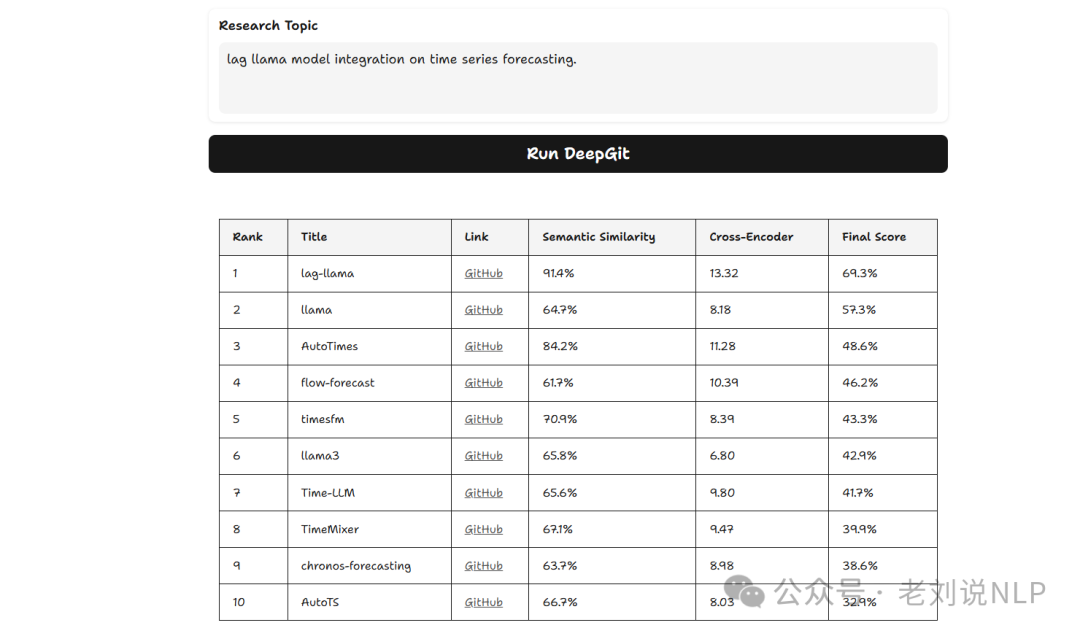
工作流程图下,当用户输入query时,
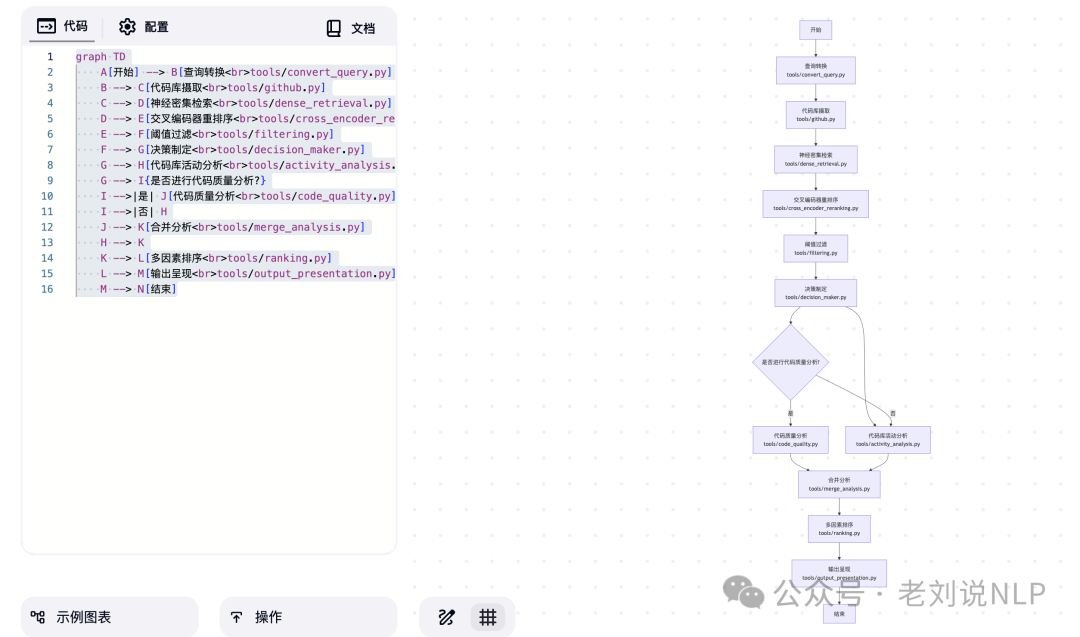
经历以下步骤:
1、查询转换(QueryConversion)
将用户的原始查询通过LLM转换为冒号分隔的搜索标签,输出转换后的查询标签。模块在tools/convert_query.py
2、代码库摄取(RepositoryIngestion),根据搜索标签从GitHub检索仓库。
使用GitHubAPI(异步调用,通过 httpx.AsyncClient)获取代码库的元数据和文档。具体执行时,先获取README和其他Markdown文件,然后将内容合并为每个代码库的combined_doc,最终输出代码库的元数据和文档内容,填充到填充 state.repositories。模块在tools/github.py,
3、神经密集检索(NeuralDenseRetrieval),计算用户查询与仓库文档之间的语义相似性。
使用SentenceTransformer对代码库文档进行编码,并通过FAISS计算与查询的语义相似度。具体执行时,先标准化嵌入向量,然后根据语义相似度返回候选代码库的排序列表。最后输出基于语义相似度的候选代码库列表(state.semantic_ranked)。模块在tools/dense_retrieval.py,
4、交叉编码器重排序(Cross-EncoderRe-Ranking),通过将完整的Markdown文档与查询进行比较,进一步优化排名
通过比较用户查询与每个代码库的完整Markdown文档,对候选代码库进行重排序。具体实现上,对于短文档,直接对全文进行评分。对于长文档,将其分割成可配置大小的块(块大小和最大长度可配置),并对每个块进行评分。使用最高分数作为仓库的最终交叉编码器分数。最终输出重排序后的候选代码库列表。模块在tools/cross_encoder_reranking.py。
5、阈值过滤(ThresholdFiltering),过滤掉不符合质量阈值的仓库。
具体根据某些阈值(如最小星数、交叉编码器分数等)过滤不符合要求的代码库,最终输出过滤后的候选代码库列表。模块在tools/filtering.py,
6、决策制定(DecisionMaker),根据查询和代码库数量,决定是否运行代码质量分析
最终输出是否进行代码质量分析的决策。使用LLM 提示评估用户的查询和仓库数量,输出一个决策(1 表示运行分析,0 表示跳过)。模块在tools/decision_maker.py,
7、代码库活动分析(RepositoryActivityAnalysis),评估仓库的活跃度水平
根据拉取请求、提交记录和未解决问题等因素,计算代码库的活跃度分数。输出代码库的活跃度分数。模块在tools/activity_analysis.py
8、代码质量分析(CodeQualityAnalysis),如果需要,评估代码质量。
本地克隆仓库,运行flake8 计算风格错误数量,并基于每个文件的问题数量计算分数。模块在tools/code_quality.py
9、合并分析(MergeAnalysis),合并活跃度和代码质量分析的结果
根据仓库的完整名称合并候选仓库,将活动分析和代码质量分析的结果合并。最终输出综合分析结果。模块在tools/merge_analysis.py
10、多因素排序(Multi-FactorRanking),通过结合各种指标计算最终排名分数
对语义相似性、交叉编码器、活跃度、代码质量和星标数量的分数进行归一化,应用预定义的权重。最终生成一个按最终分数排序的state.final_ranked列表,输出最终排序的代码库列表。模块在tools/ranking.py
11、输出呈现(OutputPresentation), 格式化并显示最终排名的仓库
构建一个包含顶级排名仓库详细信息的字符串输出,在state.final_results中返回最终结果,模块在tools/output_presentation.py
所以,流程图连接关系顺下来就是:
查询转换→代码库摄取→神经密集检索→交叉编码器重排序→阈值过滤→决策制定→代码库活动分析→代码质量分析(条件执行)→合并分析→多因素排序→输出呈现→结束。
这个agent其实更像是一个taskflow,但这流程设计的很不错。
二、Agent性能优化技术总结
关于Agent性能优化技术的总结,我们可以看《A Survey on the Optimization of Large Language Model-based Agents》(https://arxiv.org/pdf/2503.12434,https://github.com/YoungDubbyDu/LLM-Agent-Optimization),对基于LLMs的Agent优化方法的全面综述,系统地分类了参数驱动和无参数优化策略。
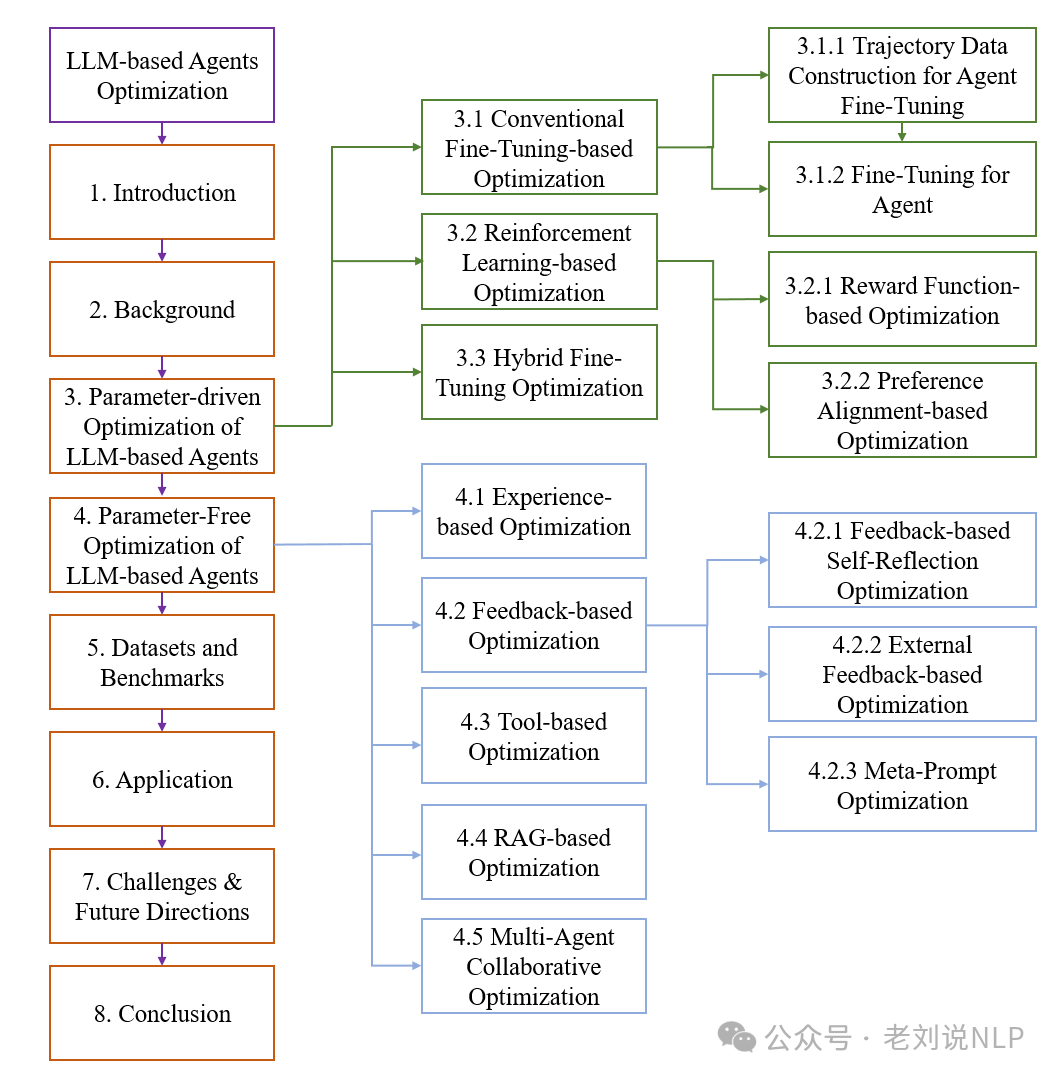
我觉得,这些是很好的索引。看三个点。
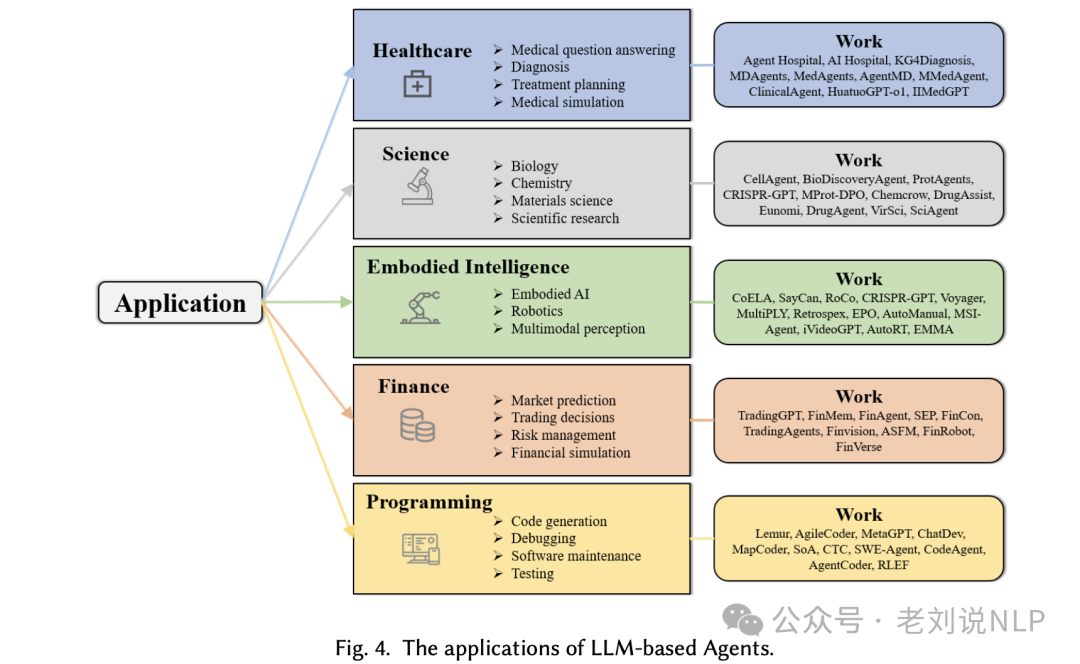
一个是当前agent的应用都有哪些。
一个是参数驱动优化的策略,包括:
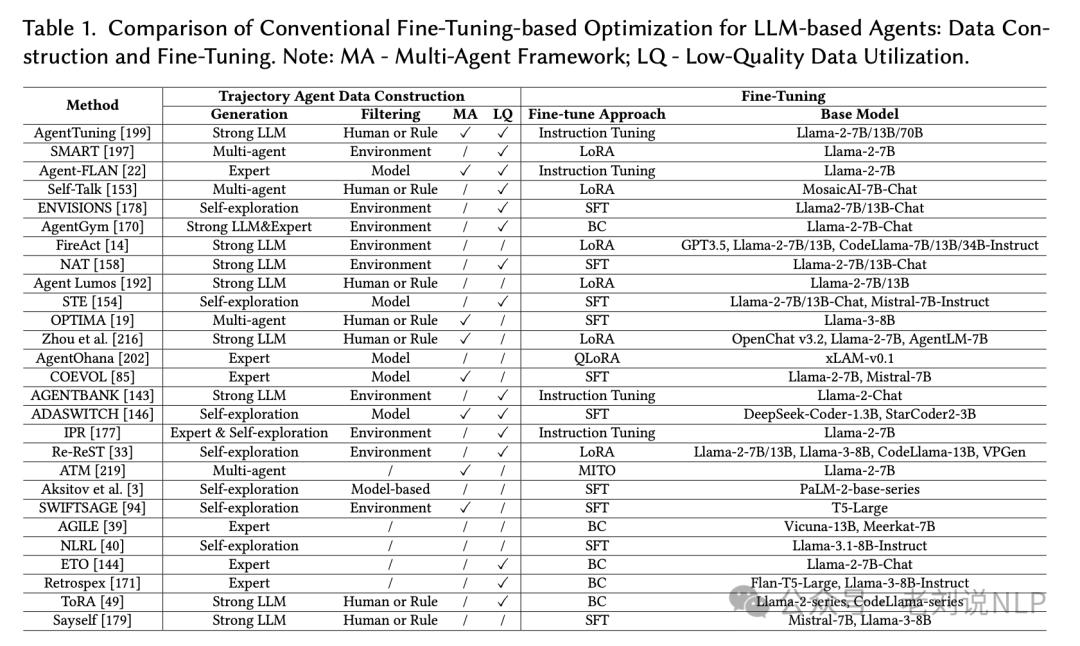
微调优化,通过微调预训练的LLMs参数来提高智能体的性能。微调过程包括构建高质量的轨迹数据和微调策略。
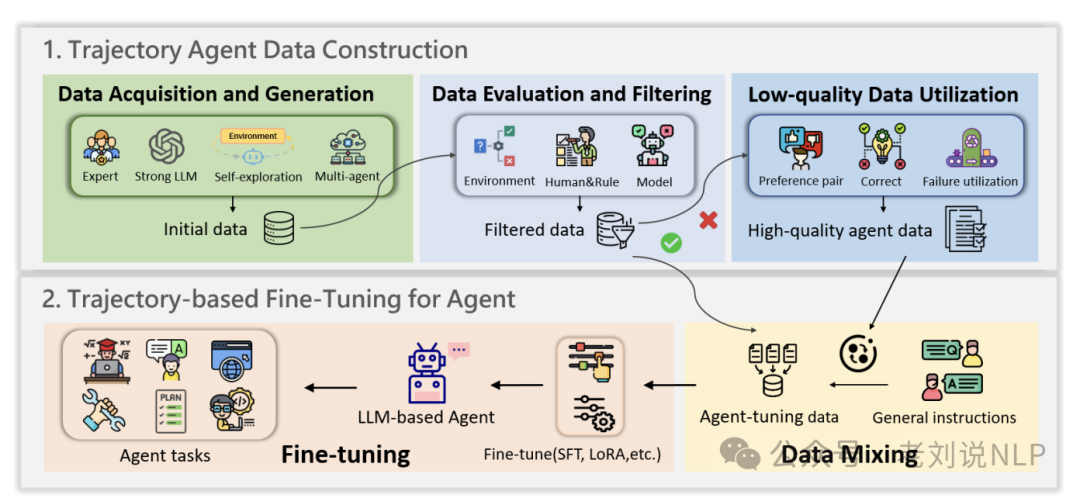 这个使用的作为频繁,重点是轨迹数据构建。具体的,首先生成高质量的轨迹数据,这些数据可以是专家标注的、由强LLM生成的、通过自探索环境交互生成的或多智能体协作生成的。然后,对生成的轨迹数据进行评估和过滤,确保数据的质量和适用性。评估方法可以基于环境反馈、人类规则或模型评估,最后使用过滤后的轨迹数据对LLMs进行微调,通常采用标准SFT、参数高效微调(如LoRA)或定制策略。如代表性的工作:
这个使用的作为频繁,重点是轨迹数据构建。具体的,首先生成高质量的轨迹数据,这些数据可以是专家标注的、由强LLM生成的、通过自探索环境交互生成的或多智能体协作生成的。然后,对生成的轨迹数据进行评估和过滤,确保数据的质量和适用性。评估方法可以基于环境反馈、人类规则或模型评估,最后使用过滤后的轨迹数据对LLMs进行微调,通常采用标准SFT、参数高效微调(如LoRA)或定制策略。如代表性的工作:
强化学习优化,利用强化学习技术,通过与环境或人类反馈对齐来优化智能体行为。主要包括奖励函数优化和偏好对齐优化。
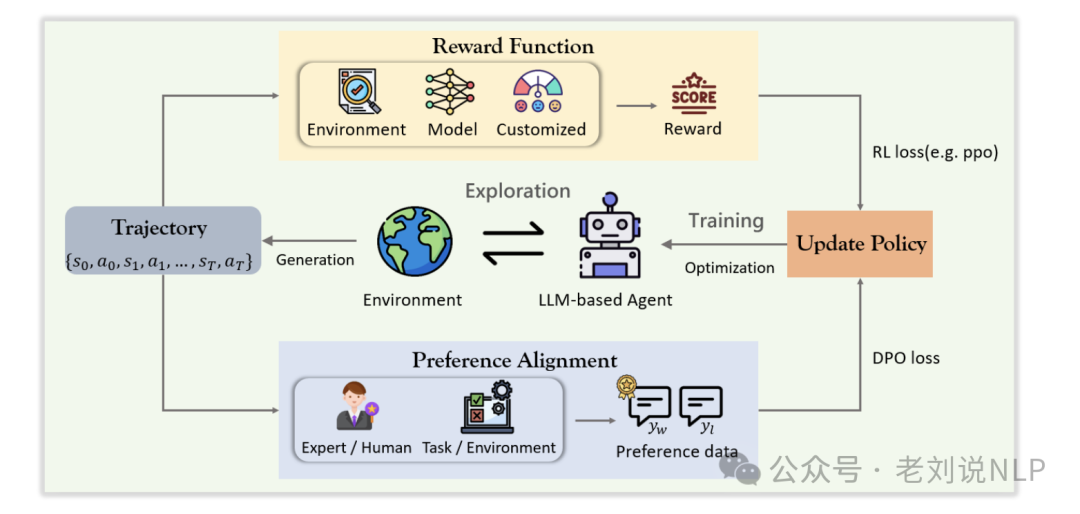
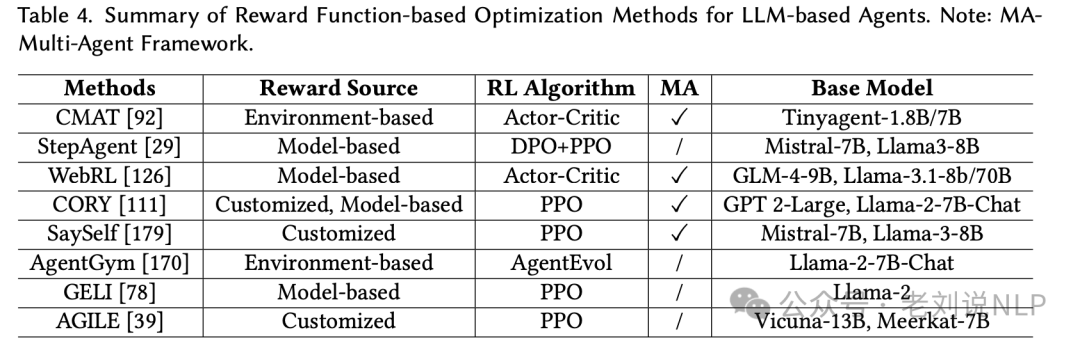
奖励函数优化,使用传统的强化学习算法(如PPO、Actor-Critic)来迭代优化智能体的策略。奖励可以来自环境反馈、模型生成的信号或自定义奖励函数。
偏好对齐优化,通过直接优化偏好数据来对齐模型输出与人类偏好,避免传统奖励建模的需求。偏好数据通过成对比较或其他排名机制构建。
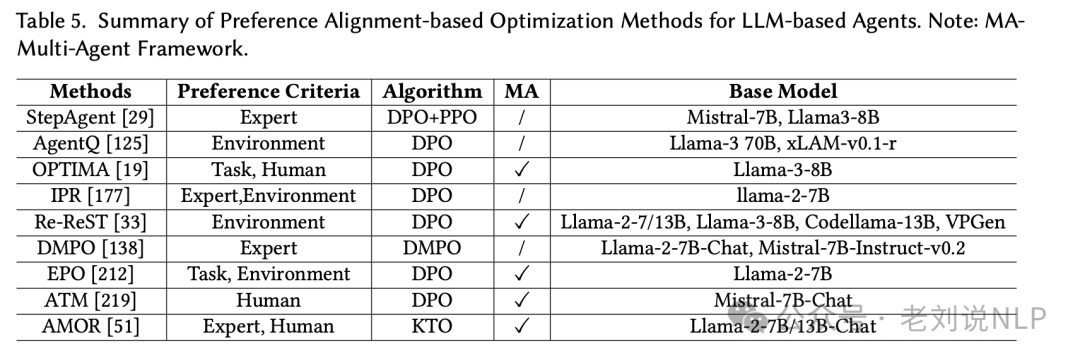
混合优化,结合SFT和RL,创建更灵活和有效的框架。通常先进行SFT预热,然后应用RL策略进行任务特定目标或动态环境的优化。
一个是无参数优化的策略,包括:
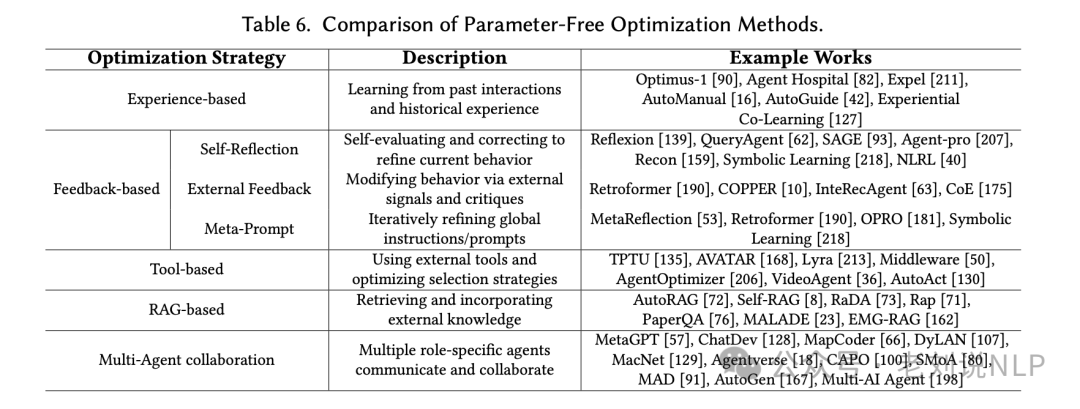
基于经验的优化,利用历史数据、轨迹或积累的知识来改进智能体。通过存储和分析成功和失败案例,智能体可以提炼策略、增强长期决策和适应演变的任务;
基于反馈的优化,通过外部信号和批评来修改行为,自我评估和校正以精炼当前行为。包括自我反思优化和外部反馈优化;
元提示优化,通过迭代调整全局指令或元提示来增强LLMs的泛化能力。通过分析失败试验创建优化的提示,并迭代地将其纳入以提高任务性能;
基于工具的优化,利用外部工具来执行需要外部计算、动态信息检索或专门功能的任务。
检索增强生成(RAG)优化,通过将检索与生成过程相结合,克服固定预训练知识的限制,提高在演变环境中的适应性。
多智能体协作优化,通过角色特定的智能体通信和协作来提高决策和性能。
关于该论文中所提工作的进一步索引,可以在https://github.com/YoungDubbyDu/LLM-Agent-Optimization中找到。
参考文献
1、https://github.com/zamalali/DeepGit
2、https://arxiv.org/pdf/2503.12434
(文:老刘说NLP)