

©PaperWeekly 原创 · 作者 | 韦锡宇
单位 | 北京大学计算语言所
研究方向 | 长上下文建模

研究简介
当前大语言模型(LLMs)在处理长上下文任务时面临核心挑战:如何在超长输入中有效检索和聚合分散信息。思维链(Chain of Thought CoT)是一种常见的激发模型思考的技术,能够通过引导模型逐步推理来提升其在复杂任务中的表现,在这篇文章中我们对思维链在长下文任务中的作用进行探究。
如下图所示,我们首先验证了 CoT 在长下文中的有效性,在 32k-128k 文本中,CoT 使模型推理准确率平均提升 3.5%,且增益随文本长度增加,表明 CoT 对长上下文任务具有显著促进作用。

更进一步的,在 Musique 数据集上,同样是推理时间成本增大(test-time scaling)的操作,我们发现 CoT 带来的收益远超多数投票(Majority Voting)的收益,并且 CoT 与理论上限(Oracle)之间仍然有将近 20% 的性能差异。
受上述观察启发,为了引导模型生成高质量 CoT,并用其提升模型长下文能力,我们提出了 LongRePS(Long-context Resoning Path Supervision, LongRePS)框架,一个面向长上下文场景的思维链过程监督方案。
LongRePS 框架包含一个自采样机制,用于从模型中生成多样化的推理路径,以及一个专门为长上下文场景设计的质量评估方案。实验结果表明,LongRePS 在多个长上下文基准测试中均取得了显著的性能提升。

论文标题:
Chain-of-Thought Matters: Improving Long-Context Language Models with Reasoning Path Supervision
论文链接:
https://arxiv.org/pdf/2502.20790
代码链接:
https://github.com/lemon-prog123/LongRePS

方法描述
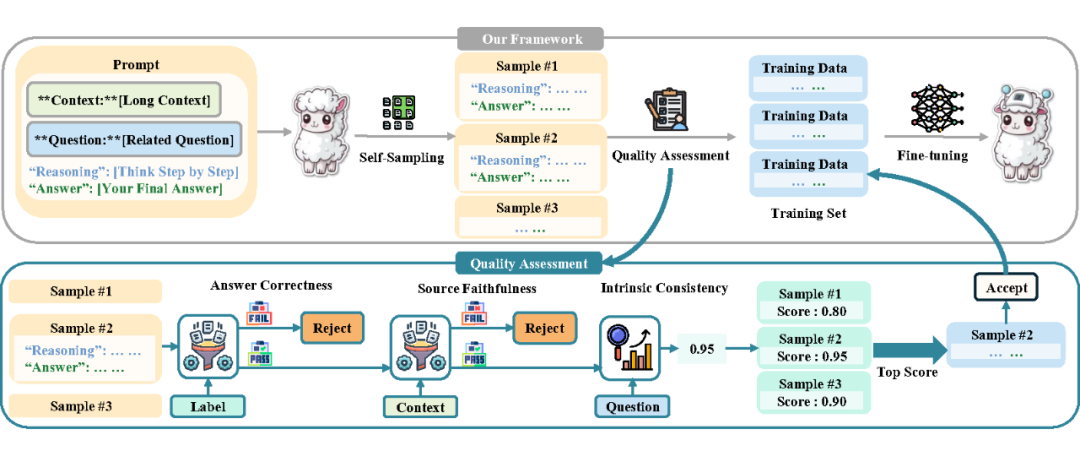
LongRePS 框架的核心在于如何生成和筛选高质量的推理路径。首先,我们通过自采样机制从模型中生成多样化的推理路径。
在采样过程中,模型被要求将回答分解为可验证的部分,并从长文本中提取相关信息,最终基于这些信息得出结论。为了确保推理路径的质量,我们设计了一个质量评估方案,该方案从答案正确性和过程可靠性两个维度对推理路径进行评估。
答案正确性(Answer Correctness AC): 要求推理路径最终得出的答案与标准答案一致,简单的来说,我们从模型的输出中分离出推理路径和问题回答,并将问题回答与标准答案比较,决定是否抛弃采样样本。
过程可靠性(Process Reliability): 则要求推理路径在逻辑上连贯、简洁且忠实于输入文本中的信息。在长上下文场景中,评估推理路径的可靠性尤其具有挑战性,因为它需要引用大量的输入文本。即使使用能够处理长输入的 llm,确保评估准确性仍然很困难,而且计算成本很高。为了解决这一难点,我们将过程可靠性分解为两个验证方面:
源文本忠实性(Source Faithfulness SF)保证了推理路径对源文本的忠实性,可以通过进行简单的字符串匹配来有效地测量。
内在一致性(Intrinsic Consistency IC)高质量的 CoT 应该表现出逻辑一致性(适当的问题分解、信息的逻辑使用和健全的推理链)、完整性(主要依赖于检索到的信息,而不是模型的内部知识),以及简洁性(避免不相关或过多的细节)。
考虑到评估这些维度的复杂性,我们采用 LLM 评分来度量。由于 LLM 只需要接受模型输出的推理路径作为打分依据,这一分解极大减少了评估方案的计算成本。

实验分析
3.1 训练过程
我们使用 LLaMA-3.1-8B 和 Qwen-2.5-7B 作为基模型,采用两阶段训练方案:先使用 300 条数据对基座模型进行指令跟随预热,在预热后模型上进行自采样,生成 3000 条推理路径,再基于筛选后的 2,100 条优质路径对预热后模型进行监督微调。所有训练流程都在 8 张 A100 上完成,训练数据来自 MuSiQue 数据集。
Baseline:
-
基础预训练模型(Base Model) -
结果监督模型(Model with Outcome Supervision):在预热后模型上用相同的数据进行结果监督微调。
3.2 实验结果
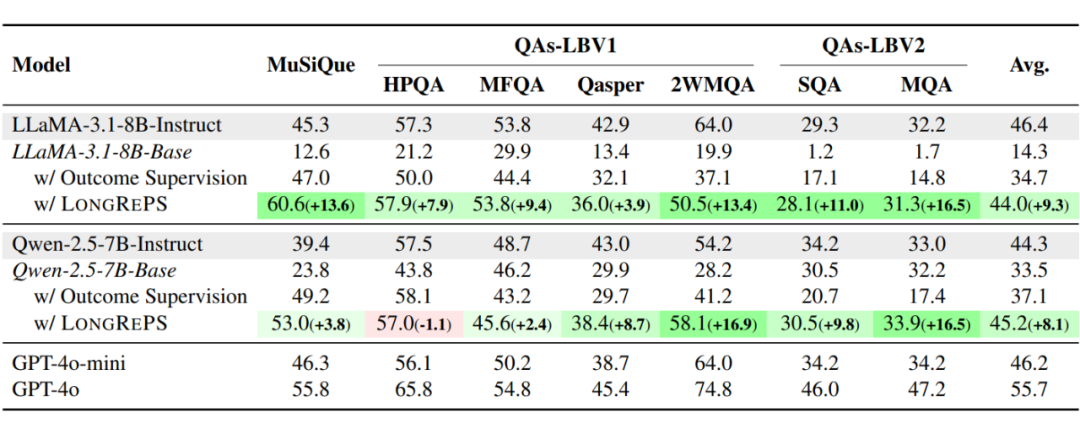
我们采用 F1-Score 作为性能评价指标,并选取了来自 LongBenchV1 和 LongBenchV2 的不同 QA 任务进行测试,括号内的数字显示了使用 LongRePS 后模型性能相比于结果监督的变化(绿色表示改善,红色表示退化)。
过程监督优于结果监督:相较于结果监督的传统方法,使用过程监督的模型域内数据集上表现更佳,这一现象在 LLaMA 上尤其明显,使用 LongRePS 为 LLaMA 带来了 13.6 分的显著性能提升,这表明,过程监督能够更有效地引导模型在复杂任务中生成高质量的推理路径。
更强的泛化性:LongRePS 框架不仅在域内任务上表现出色,还在多个长上下文基准测试中展现了更优越的泛化能力。在 LongBenchV1 和 LongBenchV2 的多个任务上,LLaMA 和 Qwen 模型分别取得了平均 9.3 和 8.1 分的提升,达到与 GPT-4o-mini 相近的性能表现。说明通过过程监督生成的推理路径能够帮助模型更好地适应多样化的长上下文场景,进一步提升其泛化性能。
质量评估方案的有效性:
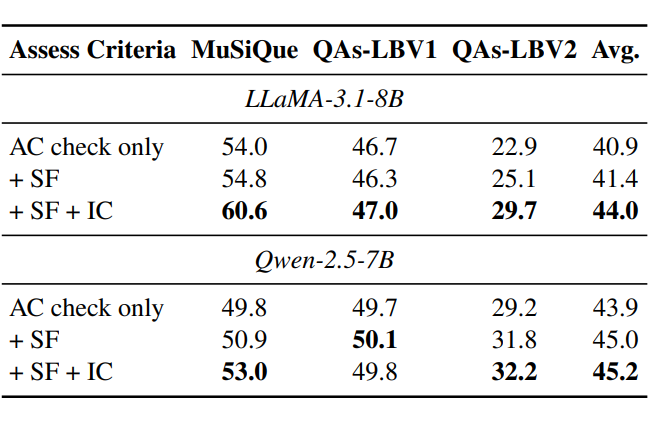
我们进一步检验我们的评估方案在选择高质量的 CoTs 作为训练数据方面的有效性。我们着重于检查过程可靠性的标准:源忠实性和内在一致性。结果表明,合并每个评估标准会带来正向的性能收益,当三个评估标准一起工作时,可以实现最高的性能。
采样规模的影响:
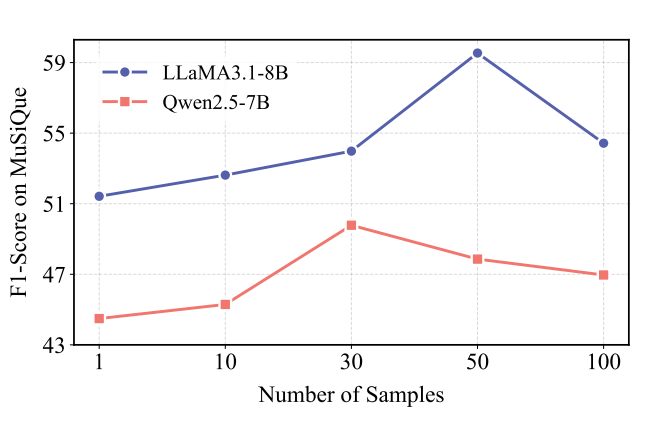
我们分析了每个训练样例中抽样的候选 CoTs 数量如何影响模型性能。我们观察到模型性能随着样本量的增加先增加后降低,不同模型到达峰值的采样数量也有所差异。我们推测,这种现象可能是由于在更大的 CoT 候选库也增大了保持一致的质量评估的难度。
推理路径来源的影响:
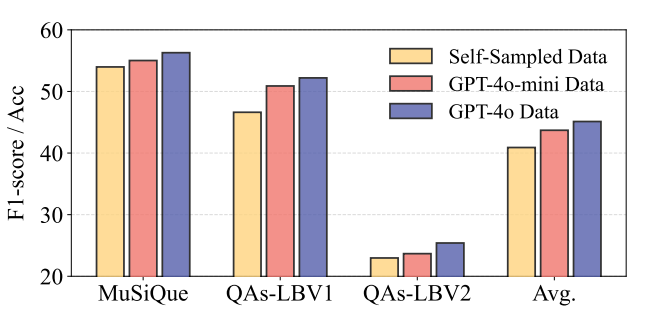
最后,除了从基本模型中自采样推理路径之外,我们还研究了直接从更有能力的模型(GPT-4o-mini 和 GPT-4o)中采样推理路径对模型性能造成的影响。可以看出,从更强的模型中直接采样,提高推理路径质量,也能有效地增强模型在长文本场景下的能力。

总结与展望
本文提出了一种过程监督框架(LongRePS)来提升 LLM 在长下文任务场景下的性能,通过三阶段的质量检测方案,LongRePS 可以通过模型自采样生成训练数据并显著提升模型性能。
实验结果表明,LongRePS 不仅在特定任务上表现出色,还展现了强大的泛化能力。我们相信,LongRePS 将减少长上下文训练对人工标注数据的依赖,为长上下文语言模型的研究提供新的思路,并推动该领域的进一步发展。
LongRePS 完成于 2025 年 2 月,结合近年来长上下文相关研究的进展,我们认为 LongRePS 在以下几个方面值得进一步探索:
-
更大规模的模型 & 更长的上下文:受限于 GPU 资源的限制,LongRePS 还没有在更大规模的模型和更长的上下文上进行训练微调,我们相信在思考能力更强的大规模模型和更贴近长上下文场景的训练数据的基础上,LongRePS 将会带来更好的性能改善。
-
更多领域任务的参与:LongRePS 目前的训练数据还只局限于长文本 QA 任务,在训练数据中加入不同领域任务的高质量推理路径,模型的泛化性将会发生什么程度变化,值得关注。
(文:PaperWeekly)