昨天刚开源Gemma3,然后今天夜里,鸽了N久的Gemini 2.0的原生多模态生图功能,也终于开放了。
在出门回来,玩了一下午后,我觉得终于可以给你们分享一下,这玩意的有趣之处了。
Gemini 2.0,就会瞬间保证所有的其他细节不变的情况下,把小姐姐变成长发。
不过这个得roll,我roll了3次才roll出来。
请你根据这张手绘线稿图,生成对应的一张真实房屋渲染图。
得益于Gemini 2.0的多模态能力,类似于之前的GPT4o,GPT4o是语音端到端,而Gemini 2.0,则是图片端到端。
而且,画出的图,审美也还凑合,虽然还远远达不到类似MJ、Flux那种质量,泛化能力也差点意思,但,能用了。
在多模态大模型上,能用的言出法随,是非常关键的一点。
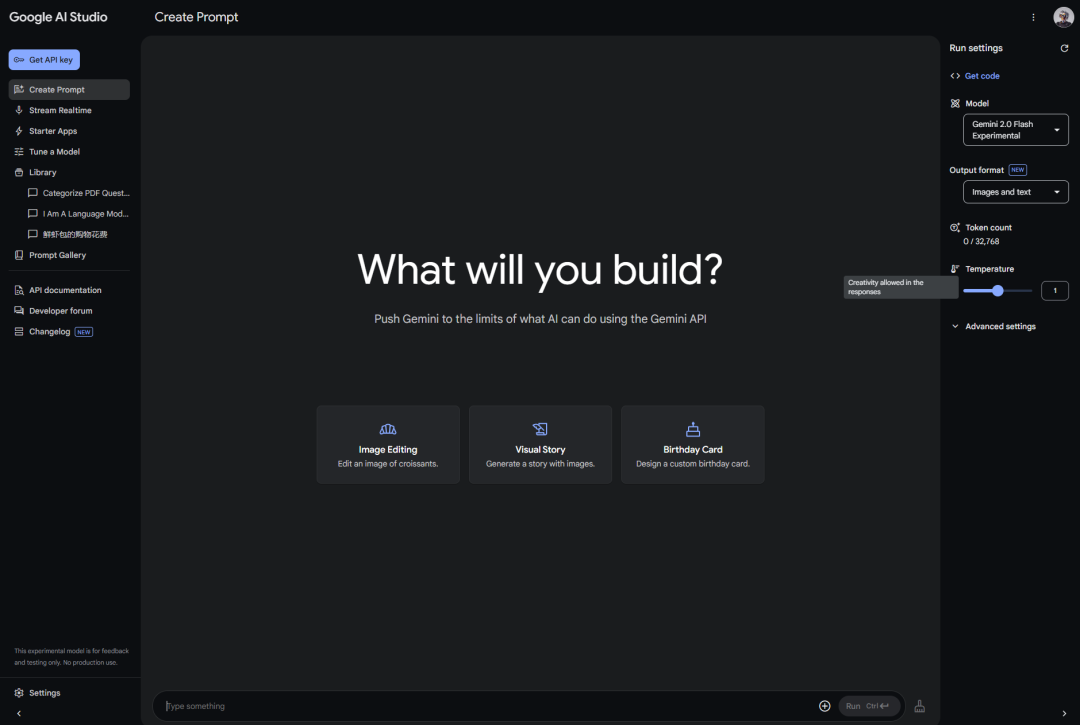
打开https://aistudio.google.com/
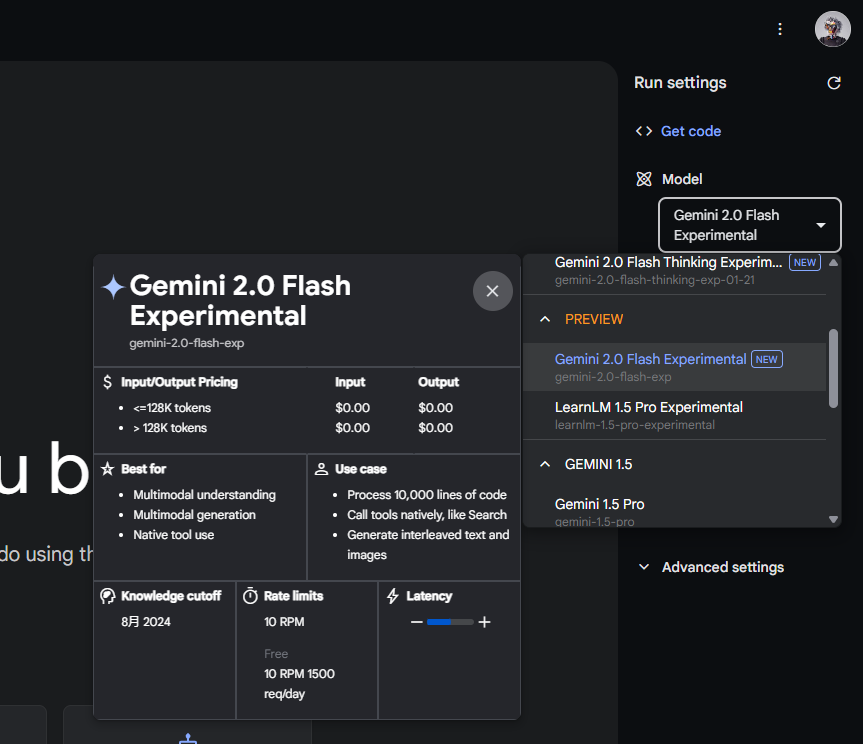
然后,在右侧把模型,切换成Gemini 2.0 Flash Experimental。
同时记得output这块,一定是Images and text,千万别只选Text,那你就生成不了图了。
接下来,直接在对话框里,传你图片,加上文字描述就OK。
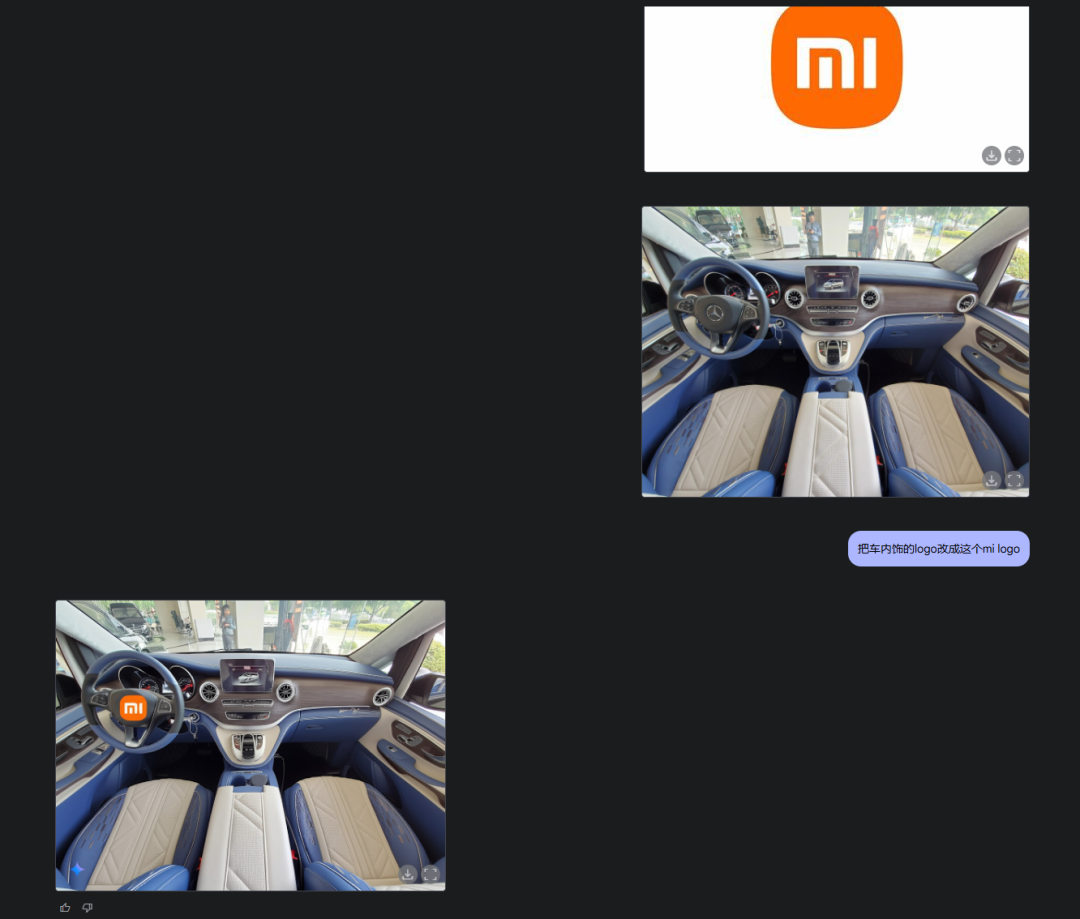
而且你不止可以传一张图,你也可以,传两张图,然后,融图。
虽然它换logo换的还有点贴片感,比较这个太难了,但是产品图,就会好很多了。
光影还是有一些不匹配,有一些贴图感,但不妨碍很准确。
甚至你还可以,不只是图+文字进去,你还可以,直接让它给你生成图文混排的教程。
甚至,你还可以,给一个平面图,直接做每个房间的渲染图。
两年多了,生成式AI在图像编辑领域的进步,真的也就像悄悄进行的大革命。
从最初需要苦学多年Photoshop和图像处理技术,到如今只需一句话就能实现你的所有创意。
我们不再受限于专业技能的掌握程度,就算是从来没用过PS的小白,也可以轻松地用嘴,将脑海中的创意转化为现实。
(文:开源星探)