
-
去年4月,为解决传统RAG在全局性的查询总结任务上表现不佳,微软多部门联合提出Project GraphRAG(大模型驱动的KG);
-
去年7月,微软正式开源GraphRAG项目,引起极大关注,至今23.2k star,但落地时却面临巨大成本痛点(具体:LLM用于实体关系抽取+描述,社区总结); -
去年11月,为了上述痛点,微软发布了LazyGraphRAG,将数据索引成本降低1000倍,只有GraphRAG的0.1%(使用 NLP 名词短语提取来识别概念及其共现,再利用图形统计来优化概念图并提取分层社区结构); -
时隔3月,微软GraphRAG项目迎来2.0.0版本,正式开源LazyGraphRAG,即NLP graph extraction功能。

-
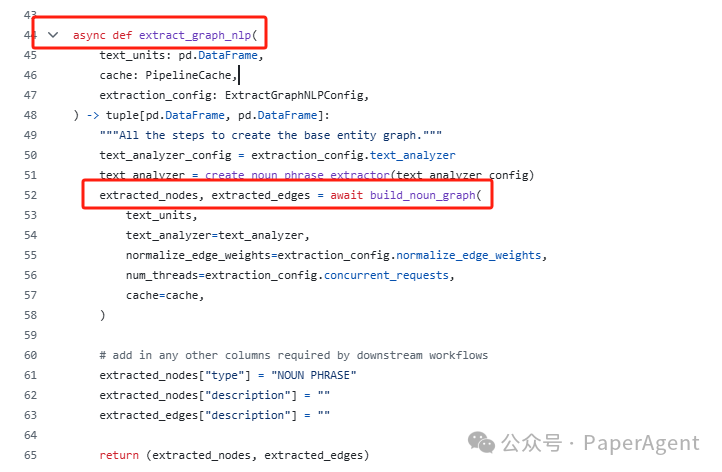
NLP图谱抽取 graphrag/index/workflows/extract_graph_nlp.py
-
建立名词短语图

-
使用text_analyzer.extract方法从每个文本单元中提取名词短语 -
去重

-
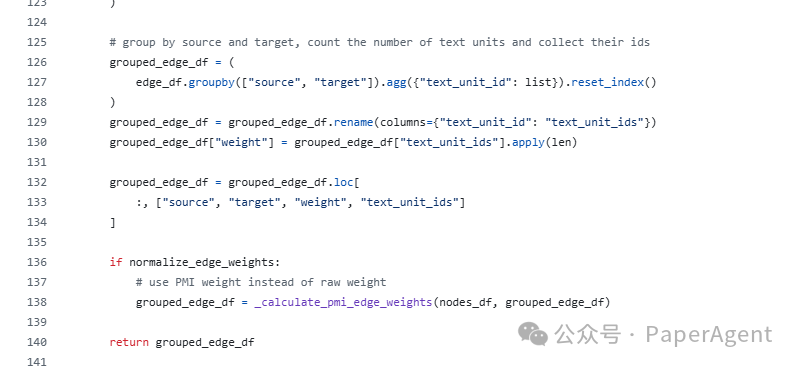
将节点数据框中的text_unit_ids展开,得到每个文本单元中出现的名词短语列表 -
对每个文本单元中的名词短语列表,生成所有可能的边(即名词短语对)

-
按source和target分组,统计边的权重(即边出现的文本单元数量) -
使用点互信息(PMI)对边的权重进行归一化

-
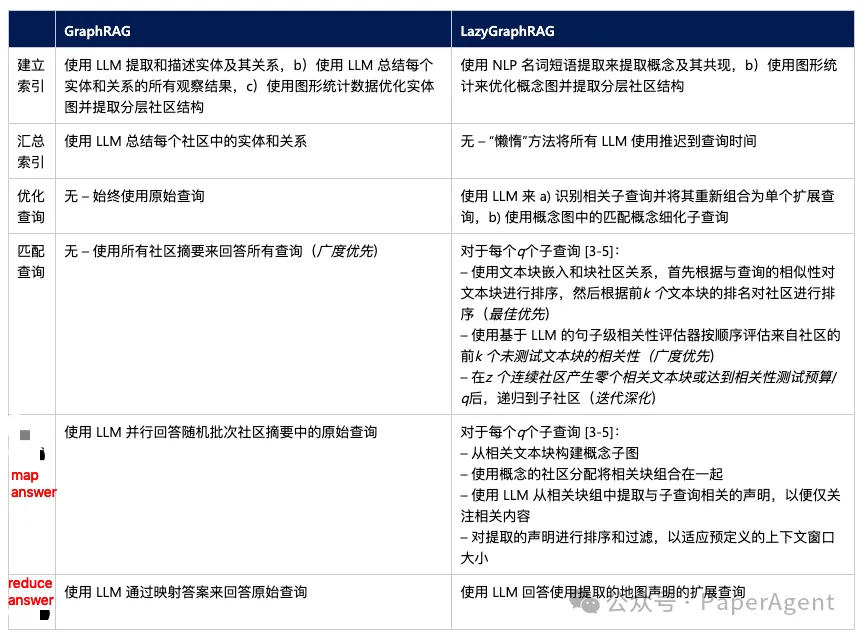
使用 NLP 名词短语提取来提取概念及其共现
-
使用图形统计来优化概念图并提取分层社区结构

https://github.com/microsoft/graphrag/blob/main/CHANGELOG.md
(文:PaperAgent)