


极市导读
把模型参数从 1.6B (20 blocks) 缩放到 4.8B (60 blocks),重用小模型的知识。不用从头开始训练模型 >>加入极市CV技术交流群,走在计算机视觉的最前沿
本文目录
1 SANA 1.5:线性扩散 Transformer 的 Training-time Compute 以及 Inference-time Compute 的高效扩展
(来自 NVIDIA, MIT 韩松团队,清华)
1 Sana 1.5 论文解读
1.1 Sana 1.5 研究背景
1.2 高效的 Model Growth 方法
1.3 Model Depth 剪枝方法
1.4 Inference-time Scaling 策略
1.5 实验设置
1.6 实验结果
太长不看版
SANA + 缩放参数高效训练 + 深度剪枝 + 推理时计算。
SANA 1.5 是 NVIDIA 的研究员,联合 MIT 韩松团队在 SANA 做 efficient scaling 的模型。在 SANA 的基础上引入了 3 个改进:
1) 高效的 Model Growth 方法: 一种把模型参数从 1.6B 缩放到 4.8B,且大幅降低计算资源的方案,结合了 memory-efficient 8-bit 优化器。
2) Model Depth 剪枝方法: 分析哪个层更重要,最小代价把模型压缩到任意尺寸。
3) Inference-time Scaling 策略: 一种重复的采样策略,用计算换模型能力,让小模型在推理时 match 大模型的能力。
这 3 个贡献的关联是:
Model Growth 方法让模型探索更大的优化空间,学出更好的特征。Model Depth 剪枝保留这些特征,实现高效部署。Inference-time Scaling 策略作为互补,当模型容量受到限制时,可以用推理时间换参数量来使得小模型实现与大模型相似或更好的结果。
它们证明了:深思熟虑的优化过程,胜于简单 Scaling 模型参数。高效的缩放可以通过更好的优化轨迹来实现,而不是简单地去增加模型的容量。
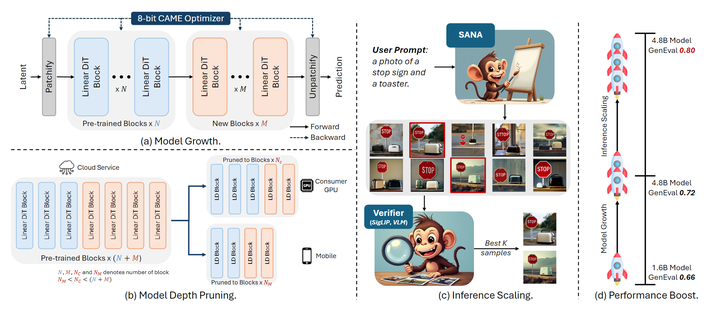
下图 1 说明了它们是如何协同工作,以在不同的 computational budgets 实现高效缩放的。
为了高效的训练和微调,SANA-1.5 使用 CAME-8bit 优化器。与 AdamW-32bit 相比,CAME-8bit 将内存使用量减少了约 8 倍,同时保持了训练的稳定性。这种优化对于单 GPU 微调场景特别有价值,使研究人员能够在 RTX 4090 等消费 GPU 上微调 SANA-4.8B。
SANA-1.5 在 GenEval 上达到了 0.72 的得分,通过 Inference-time Scaling 可以最终得到 0.8 的分数。
SANA-1.5 的贡献是使得模型按 compute budgets 缩放到不同的尺寸,同时维持高质量。
下面是对本文的详细介绍。
1 SANA 1.5:线性扩散 Transformer 的 Training-time Compute 以及 Inference-time Compute 的高效扩展
论文名称:SANA 1.5: Efficient Scaling of Training-Time and Inference-Time Compute in Linear Diffusion Transformer
论文地址:
http://arxiv.org/pdf/2501.18427
项目主页:
http://nvlabs.github.io/Sana/
Hugging Face 权重:
http://huggingface.co/collections/Efficient-Large-Model/sana-673efba2a57ed99843f11f9e
1.1 SANA 1.5 研究背景
T2I 扩散模型在过去几年中,模型大小明显呈上升趋势。尽管扩大模型大小在提高生成质量方面已被证明有效,但它具有巨大的计算成本。Playground v3 从PixArt 的 0.6B 参数增长到 24B,导致大多数从业者的训练和推理成本过高。
相比之下,SANA-1.0[1]引入了高效的 Linear Diffusion Transformer,在显著地降低计算需求的同时实现了有竞争力的性能。SANA-1.5 探索了2个问题:
-
Linear Diffusion Transformer 的可扩展性如何。
-
如何扩大 Linear Diffusion Transformer 并降低训练成本?
SANA-1.5 回答了如何高效地缩放模型。
1.2 高效的 Model Growth 方法
一句话介绍: 把模型参数从 1.6B (20 blocks) 缩放到 4.8B (60 blocks),重用小模型的知识。不用从头开始训练模型 (这里和我们 LiT (LiT: Delving into a Simplified Linear Diffusion Transformer for Image Generation[2] 的初衷一致),SANA-1.5 的方法对一些 Block 使用小模型的权重初始化,允许大模型保留小模型的先验知识。与从头开始训练相比,这种方法将训练时间减少了 60%,如图 2 所示。
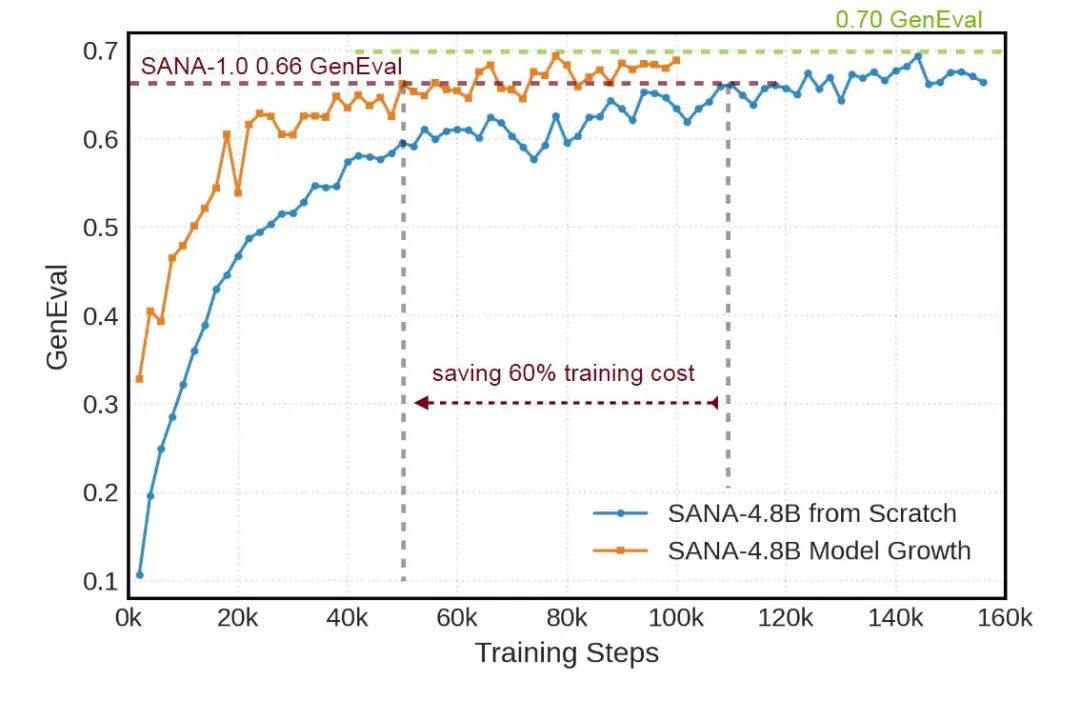
SANA-1.5 不像常见做法直接把模型 Scaling 参数上去,而是使用了一种比较高效的做法。首先扩展一个基模型,其中从 Transformer Blocks 增加到 Transformer Blocks(SANA-1.5 实验中为 ),同时保留其学习的知识。
参数初始化策略
这个过程中,作者探索了 3 种初始化策略,如下图 3 所示。
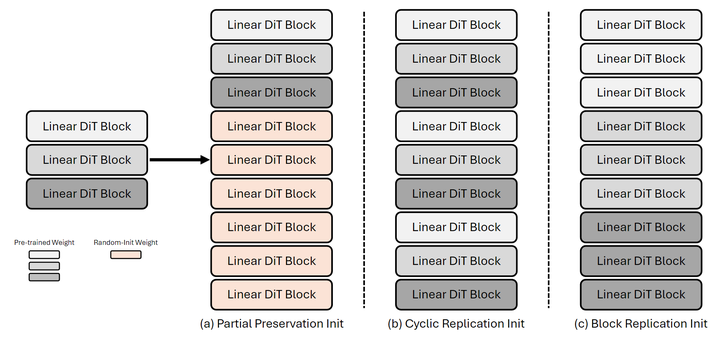
Partial Preservation Init:保留最初的 层参数,随机初始化额外加的 层参数。
Cyclic Replication Init:周期地重复预训练的层。
Block Replication Init:给定 expansion ratio ,对于预训练的第 层,后面 层都用其参数初始化。
稳定性增强
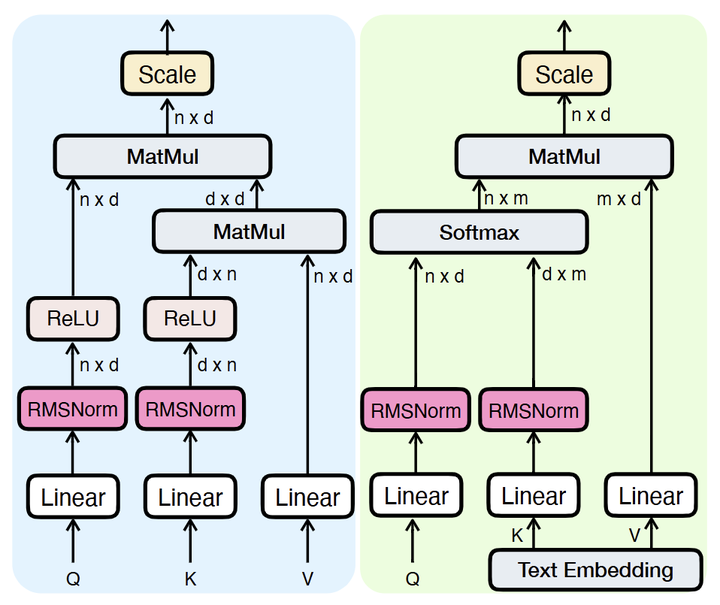
为了确保所有初始化策略的训练稳定性,在 Linear Attention 和 Cross-Attention 模块中都对 Query 和 Key 使用了 RMSNorm,如下图 4 所示。这种归一化技术至关重要,因为:1) 在早期训练时稳定注意力计算;2) 集成新的层时防止梯度不稳定;3) 在保证质量的同时实现快速适应。
Identity Mapping 初始化
在新加的层中将特定组件的权重初始化为零:Self-attention 的输出投影,Cross-attention 的输出投影,MLP Block 最后的 point-wise 卷积。零初始化确保新的 Transformer Block 最初为恒等函数,有 2 个关键的优势:1) 在训练开始时精确保存预训练模型的行为;2) 提供稳定的优化路径,从一个已知的好的解。
在图 2 的这些策略中,作者采用了 Partial Preservation Init。因为它简单和稳定。预训练的 层保持其特征提取能力。其他新加入的 层,从 Identity Mapping 开始,逐渐学会 refine 这些表征。
与其他 2 种方案相比,Partial Preservation Init 提供了最稳定的训练动态。作者在预训练模型中删除了最后 2 个 Block 以增强新添加的 Block 的学习。
显存高效的 CAME-8bit 优化器
在 CAME 和 AdamW-8bit 基础上,本文提出了 CAME-8bit 进行高效大规模模型训练。CAME 通过二阶矩的矩阵分解将显存使用量减少了一半,使得它对于大型线性层和卷积层特别高效。作者进一步用一阶矩的 block-wise 8-bit 量化来扩展 CAME,同时对于关键的统计量维持 32-bit 精度,维持优化稳定性。
这种混合的方法将优化器的显存占用减少到 AdamW 的大约 1/8,在不影响收敛特性的情况下在消费级 GPU 上实现十亿规模的模型训练。
混合精度设计
为了维持优化器的稳定性,作者将二阶统计量保持为 32-bit,因为这对于梯度缩放至关重要。对于一个输入和输出维度分别为 和 的线性层而言,二阶变量的存储从 减少到 。使得其精度对于整体的内存消耗不那么关键。这种混合方法在保持 CAME 收敛特性的同时减少了显存使用。显存的减少可以表述为:

其中, 是量化的层, 是第 层的参数, 24 是每个参数节约的最大 byte 数。实践中,由于以下几个因素,实际节省的显存略微略低:
-
一些很小的层 (<16K 参数) 保持 32-bit 的精度。 -
二阶统计数据保持在 32-bit。 -
量化参数的额外开销。
在推理过程中,采用了 2 种互补的高效部署方法:
-
Model Depth 剪枝方法,识别和保留重要的 Transformer Block,剪掉不重要的。使得模型根据不同的计算预算或者不同大小的模型,通过高效的微调恢复模型性能。
-
Inference-time Scaling 策略:通过重复采样和 VLM 引导的选择,用计算换模型容量。同时,CAME-8bit 优化器使得在单个消费 GPU 上微调十亿级的模型成为可能。
1.3 Model Depth 剪枝方法
一句话介绍: 按 Block 剪枝。剪掉不重要的 Block,并通过微调快速恢复模型质量 (比如单 GPU 微调 5 分钟)。这种先增加模型尺寸,再剪枝的做法在保持竞争质量的同时,高效地将 60 Block 的模型压缩为各种配置 (40/30/20 Block),便于为不同的 compute budgets 做灵活部署。
为解决大模型中效果和效率的 trade-off,引入的度剪枝方法,来压缩大模型,得到不同配置的较小模型,同时维持高质量。Model Depth 剪枝通过输入输出相似性模式分析 Block 的重要性:
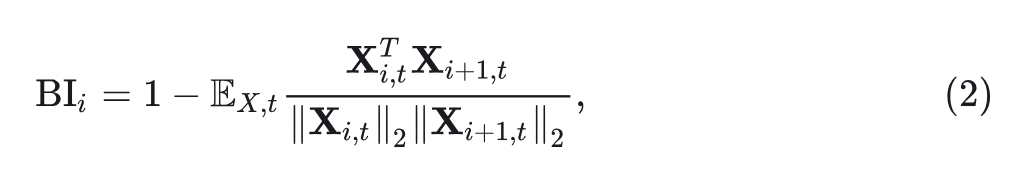
其中, 代表第 个 Block 的输入。
作者对 diffusion timesteps 和校准数据集之间的 Block 重要性做平均,结果如下图 5 所示。头部和尾部的 Block 重要性较高,作者推测头部 Block 将 latent distribution 更改为 diffusion distribution,尾部 Block 将其转回。
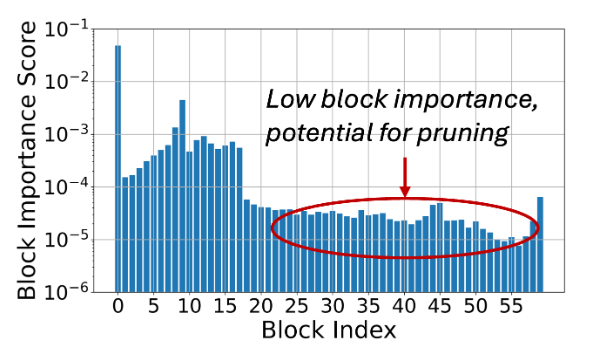
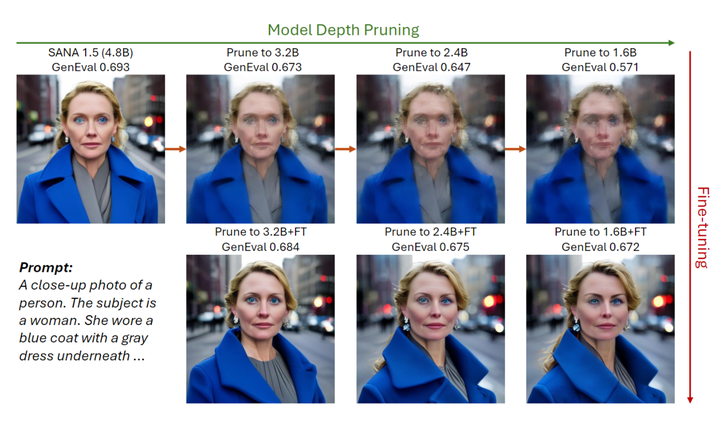
中间 Block 通常在输入和输出特征之间具有更高的相似性,证明了生成结果的逐步细化。根据 Block 的重要性 Prune Transformer Block。如图 6 所示,剪枝 Block 会逐渐损害高频细节。因此,在剪枝 Block 后,进一步微调模型以补偿信息丢失。
仅微调 100 步,剪枝 Block 后的 1.6B 模型可以达到与完整 4.8B 模型相当的质量,并且优于 SANA-1.0 1.6B 模型,如图 6 所示。

1.4 Inference-time Scaling 策略
一句话介绍: 推理时间缩放策略,使较小的模型通过在推理时做更多计算,而非参数缩放来匹配更大的模型的质量。将 GenEval 得分从 0.72 提高到 0.80,这个现象表明计算可以有效地被用来换取模型能力,让小模型在推理时 match 大模型的能力,挑战了 “实现更好的质量必须通过更大的模型” 的传统观点。
通过充分的训练,SANA-1.5 在 Model Growwth 之后获得了更强的生成能力。受 LLM 中推理时间缩放成功的启发,作者做了 Inference-time Scaling 来推动生成上限。
Scaling 扩散模型到底面向 Denoising Steps 还是 Scaling Samplings
对于 SANA 和许多其他扩散模型,扩大推理时间计算的自然选择是增加 Denoising Steps 的数量。
然而,2 个原因,使更多的 Denoising Steps 对于缩放并不理想。
-
额外的 Denoising Steps 不能自我纠正错误。图 7(a) 用样本说明了这一点,其中,早期阶段错位的对象在后续步骤中保持不变。 -
生成的质量很快达到平台期。如图 7 所示,SANA 在仅 20 步的情况下就已经产生了视觉上令人愉悦的结果,即使增加了 2.5 倍的步骤,也没有显著的视觉改进。
相比之下,Scaling Sampling Candidates 数量是一个更有前途的方向。如图 7(b) 所示,当多次尝试时,小模型 SANA (1.6B) 也可以为困难的测试提示生成正确的结果,就像一个粗心的学生有时会在执行过程中出错。但是,当有足够的机会尝试时,其仍可以提供令人满意的答案。
因此,作者选择生成更多的图像并引入 “教师模型” 来对结果进行评分。
Visual Language Model (VLM) 对生成结果作评判
为了找到与给定提示最佳匹配的图像,需要一个模型来理解文本和图像。虽然像 CLIP 和 SigLIP 这样的流行模型提供了多模态能力,但上下文窗口太小 (CLIP 77 tokens,SigLIP 66 tokens),限制了它们的有效性。
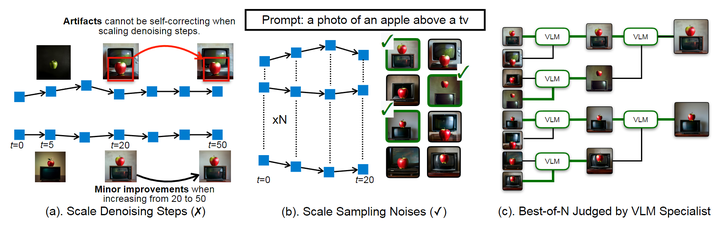
作者先尝试了一些商业化 multi-modal APIs,比如 GPT-4o 和 Gemini-1.5-pro,发现 2 个比较大的问题。其一,在针对提示评估单图像时,2 个 API 缺乏评分一致性。其二,当任务从多个选项中选择最佳匹配图像时,无论图像排序或混洗如何,2 种模型都对第 1 个呈现选项表现出强烈的偏差。
为了解决这些问题,作者选择了 NVILA-2B,并开发了专门的数据集来微调它以评估图像。微调模型可以在提供详细的解释性推理的同时评估图像与其提示的匹配程度。通过微调的 VLM 比较和判断生成的图像,作者最终确定前N个候选,如图 8(c) 所示。这确保了稳健的选择结果并有效地过滤掉提示不匹配的图像。
1.5 实验设置
最终模型 SANA-4.8B 扩展到 60 层,保持与 SANA-1.6B 相同的通道维度 (每层 2240) 和 FFN 维度 (5600)。架构、训练数据和其他超参数与 SANA-1.6B 保持一致。
SANA-1.5 首先在大规模数据集上进行预训练,然后在高质量的数据集上执行 SFT。
评估指标包括 FID、CLIP Score、GenEval 和 DPG Bench,将其与 SOTA 方法进行比较。在 MJHQ-30K 数据集上评估 FID 和 CLIP score,该数据集包含来自 Midjourney 的 30K 张图像。GenEval 和 DPG-Bench 都专注于测量文本图像对齐,分别有 533 和 1,065 个 test prompts。特别强调 GenEval,因为它更好地反映了文本图像对齐,并显示出比其他指标更多的改进空间。
1.6 实验结果
作者将 SANA-4.8B 与最先进的 T2I 方法进行了比较,结果如图 9 所示。从 SANA-1.6B 到 4.8B 的扩展带来了实质性的改进:GenEval 的绝对增益为 0.06 (从 0.66 到 0.72),FID 降低了 0.34 (从 5.76 减少到 5.42),DPG 分数提高了 0.2 (从 84.8 到 85.0)。
SANA-4.8B 模型取得了比 Playground v3 (24B) 和 FLUX (12B) 等更大的模型相当或更好的结果。SANA-4.8B 的 GenEval 分数为 0.72,接近 Playground v3 的 0.76,但延迟比 FLUX-dev (23.0s) 低 5.5 倍。
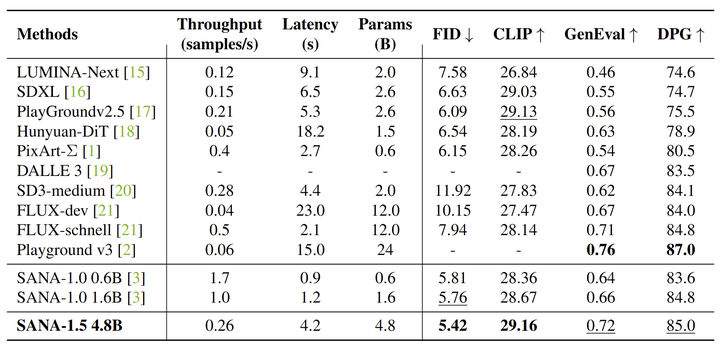
作者在图 7 中比较了 SANA-1.5 和 SANA-1.0 模型的不同大小。为了与 SANA-1.0 1.6B 进行公平比较,此处的 SANA-1.5 4.8B 模型在没有从高质量数据进行监督微调的情况下训练。所有结果都是在大小为 512×512 的图像上评估的。在较小的计算成本下,Model Pruning 后的模型进行微调的性能优于从头训练的模型。
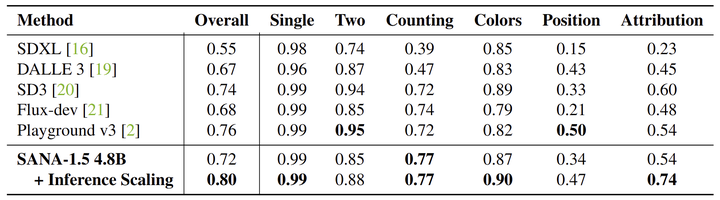
作者继续结合 SANA-1.5 4.8B 模型以及 Inference Scaling,并将其与 GenEval Benchmark 上的其他 T2I 生成模型进行比较,如下图 10 所示。通过从 2048 个生成的图像中选择样本,inference-scaled 模型在整体精度上优于朴素单图像生成 8%,在 “Colors”, “Position”, 和 “Attribution” 子任务方面均有显著的改进。此外,配备 Inference Scaling 之后,SANA-4.8B 模型在整体准确度上比 Playground v3 (24B) 高出 4%。这些结果表明,即使在模型容量有限的情况下,推理增强也可以提高模型生成质量和精度。
推理中的 Inference Scaling Law
图 11 展示了增加 inference-time computation 带来的优势。
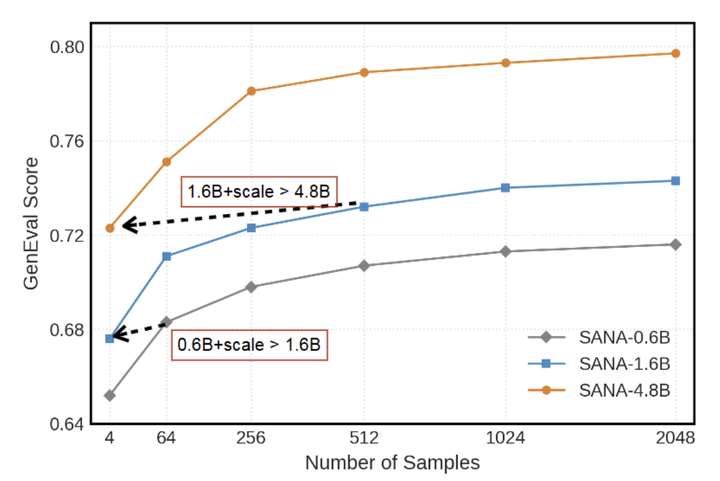
SANA 在 GenEval 上的精度随采样的增加不断提高。其次,推理时间缩放使较小的 SANA 模型能够匹配甚至超过较大模型的准确性 (1.6B + 缩放优于 4.8B)。这些结果揭示了 scaling up inference 的潜力。
唯一的限制是计算成本增加:采样 个图像,SANA 生成需要 GFLOPs,NVILA判断和比较需要 GFLOPs 。如何提升效率,可以留给未来的工作。
高质量数据微调
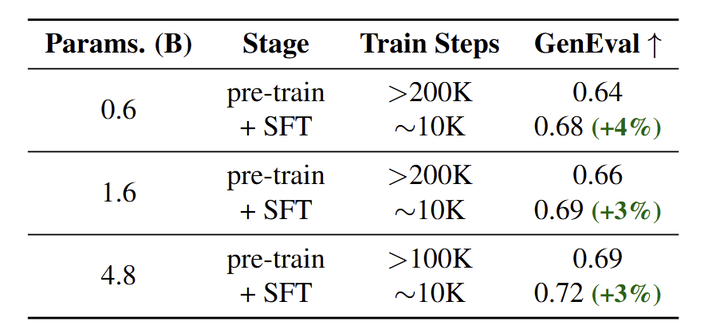
虽然对大规模数据集的广泛预训练导致质量饱和,但对精选数据集 (来自 50M 预训练数据的 3M 个样本) 进行微调,显著地提高了不同模型大小的能力。具体而言,通过对 CLIP score > 25 的图文对进行微调,与预训练模型相比,SANA-4.8B 模型在 GenEval score 上实现了 3% 的改进,如图 12 所示。
参考
-
Sana: Efficient high-resolution image synthesis with linear diffusion transformers -
LiT: Delving into a Simplified Linear Diffusion Transformer for Image Generation

(文:极市干货)