


导读
随着人工智能的迅猛发展,统一理解与生成的大模型技术已广泛应用于多个领域,为解决复杂问题提供了全新的视角与工具。在众多应用场景中,医学领域对人工智能的需求尤为迫切,将先进的 AI 技术与医学深度结合,能够显著提高诊断准确性与医疗效率,为患者提供更优质的医疗服务。
为满足这一重要需求,浙江大学与阿里巴巴等多家顶尖机构合作推出了 HealthGPT —— 一款专为医学设计的视觉语言模型(Med-LVLM)。HealthGPT 自发布以来已在医疗 AI 领域备受关注。

项目链接:
https://llsuzy.github.io/HealthGPT.github.io/
论文链接:
https://arxiv.org/abs/2502.09838
代码链接:
https://github.com/DCDmllm/HealthGPT

项目概述
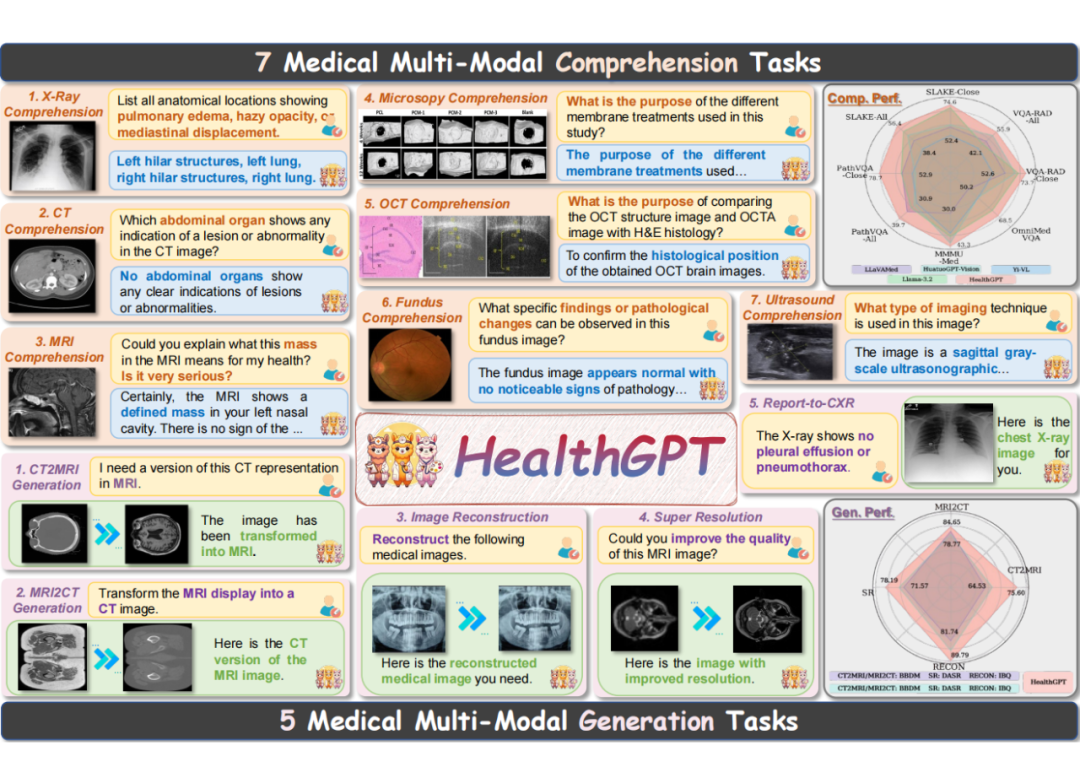
当前,将大模型统一理解生成技术成功应用到医学领域面临两大挑战:
-
医疗数据规模与质量不足:医疗数据不仅规模有限且专业性极高,难以达到传统大模型数十亿级别的预训练要求,开发统一的医学视觉模型难度较大。
-
视觉理解与生成的模式冲突:理解任务倾向于提取抽象信息,而生成任务则需保留大量细节,两类任务之间存在固有的矛盾,传统联合训练方式难以兼顾。
为了解决以上问题,HealthGPT 提出一种统一框架,致力于打破医学视觉理解任务和生成任务之间的隔阂,实现两者的深度融合。

核心技术方案
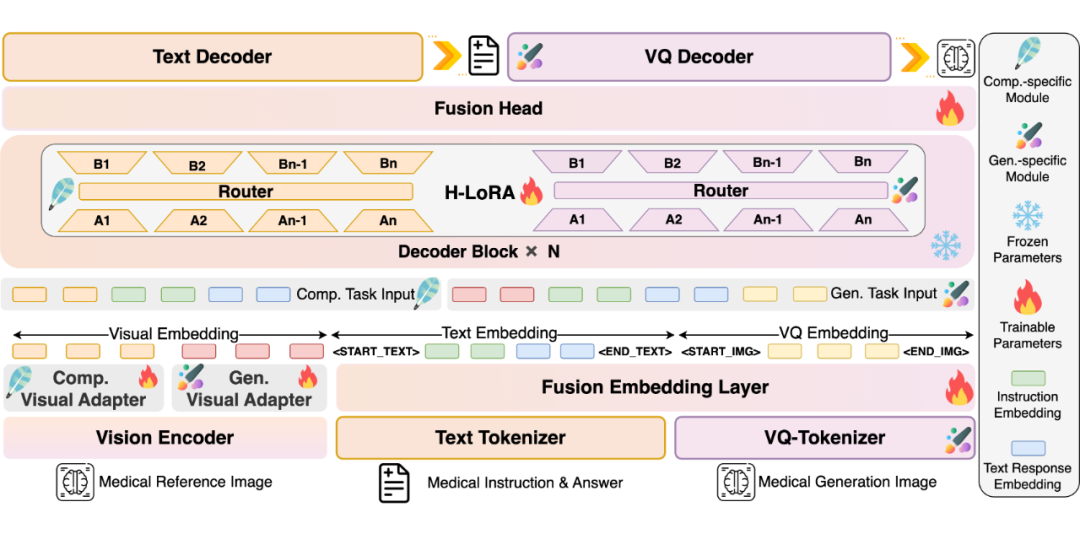
为有效解决理解与生成任务之间的矛盾,避免大规模数据依赖,HealthGPT 创新性地提出了四大核心方案:
1. 异构低秩适应(H-LoRA)
-
任务解耦:将理解任务和生成任务的训练过程分离,使模型能够储存两种任务的异构知识在独立的“插件”中,避免了因任务冲突而导致的联合优化问题。
-
LoRA 专家机制:采用专家混合(MoE)机制,动态调用专家知识,防止灾难性遗忘。
-
矩阵合并优化:利用创新的矩阵块乘法优化,防止潜在的缩放因子退化,训练效率提升明显。
2. 层次视觉感知(HVP)
将视觉 Transformer(ViT)的浅层与深层特征分离,分别用于理解(深层抽象)和生成(浅层细节)任务,有效降低任务干扰,加快模型收敛。
3. 三阶段学习策略(TLS)
-
阶段一:多模态对齐:针对理解任务和生成任务的异构性,分别训练 H-LoRA 插件,使 LLMs 具备视觉-语言对齐和视觉到视觉重建的能力。
-
阶段二:异构插件适应:融合不同 H-LoRA 子模块会出现偏差和尺度不一致等问题,因此在这一阶段对词嵌入层和输出头进行微调,以确保多个 H-LoRA 插件能够与 LLMs 无缝对接,构建统一的视觉语言基础模型。
-
阶段三:视觉指令微调:引入额外的指令数据增强模型对下游任务的适应性。此时,词嵌入层和输出头已经经过微调,只需训练 H-LoRA 模块和视觉适配器,从而显著提高模型的任务灵活性。
VL-Health 医疗数据集:精心设计了综合医学数据集 VL-Health,用于训练统一的医疗 LVLMs。该数据集涵盖了七种理解任务和五种生成任务,通过在多模态任务上的定量分析和验证,表明 HealthGPT 能够在数据受限的情况下统一医疗多模态能力,并在多个指标上实现与现有最先进的模型相当或更好的性能。

性能表现与实验分析
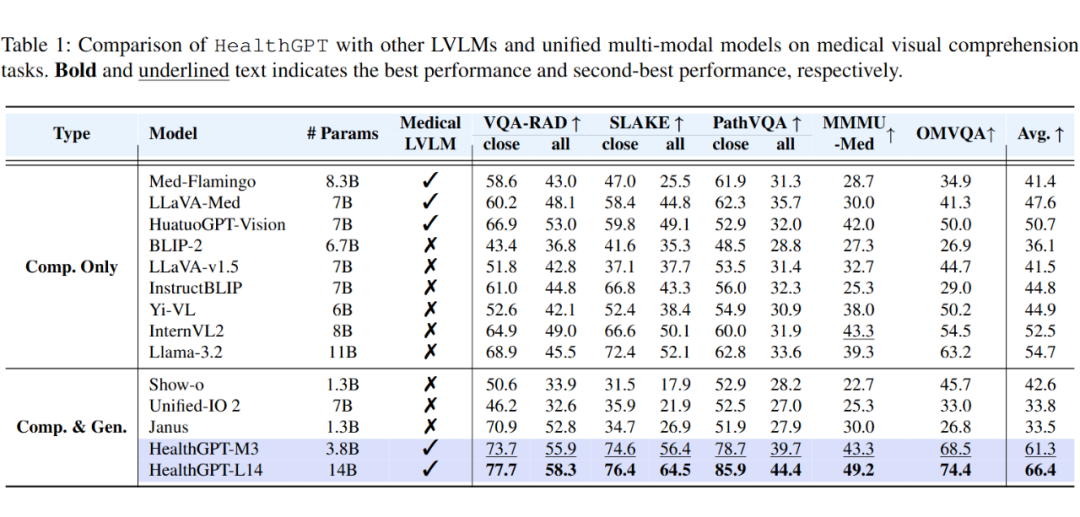
4.1 医学视觉理解任务
实验采用了多个维度的视觉理解任务评估,针对仅理解模型和统一模型进行了测试:
-
仅理解模型:HealthGPT-M3 以 3.8B 的参数优于前沿医学专用模型(如 HuatuoGPT-Vision)和强大预训练通用模型(如 Llama-3.2),而更大参数规模的 HealthGPT-L14 进一步提升了性能表现。
-
统一模型:尽管经过了数十亿数据训练,统一模型仍无法在医学场景保持足够的泛化能力,普遍弱于理解模型,而 HealthGPT 具备生成能力,仍保留了强大的医学知识。
4.2 医学视觉生成任务
在医学场景常见的超分辨率和模态转换任务中,HealthGPT 表现突出。
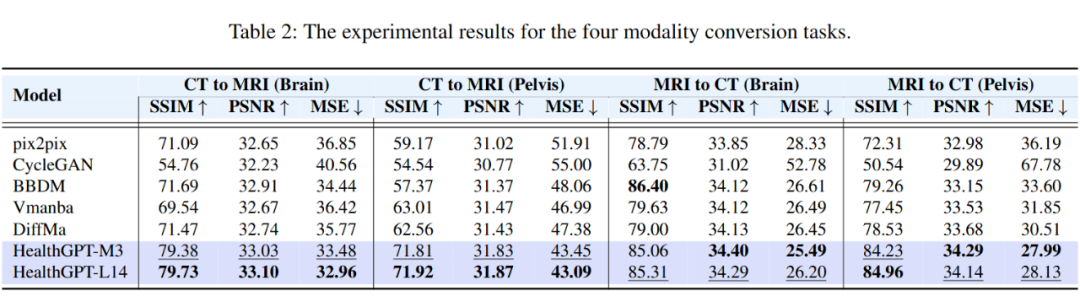
4.2.1 模态转换
HealthGPT 统一训练不同部位 CT 和 MRI 的模态转换,较其他模型(针对单一任务训练)展现出了足够的潜力。
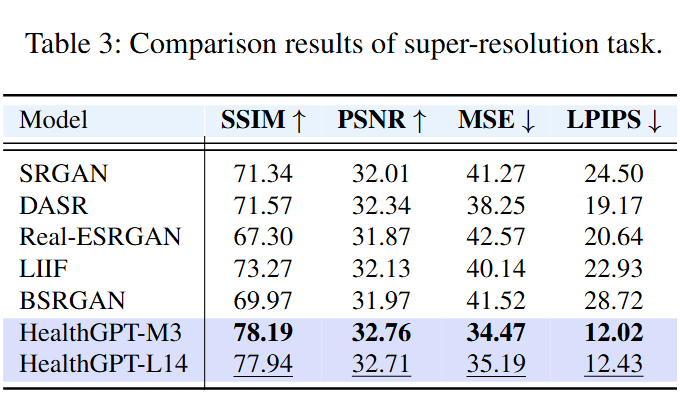
4.2.2 超分辨率
相较于缺乏医学先验知识的超分模型,HealthGPT 充分还原了医学影像在 4× 任务下的局部细节,获取了最好的性能。
4.3 消融实验
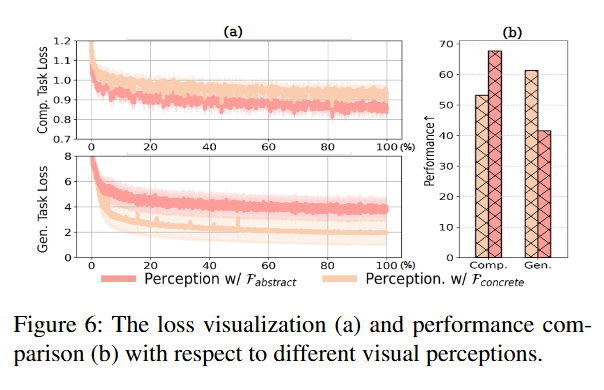
4.3.1 层次视觉感知
为深入探索层次视觉感知模块,实验通过为理解任务和生成任务分配不同粒度的视觉特征,验证了层次视觉感知的必要性:为理解/生成任务指派 ViT 深层/浅层特征更能充分利用输入图片的视觉特性,从而提升整体性能。
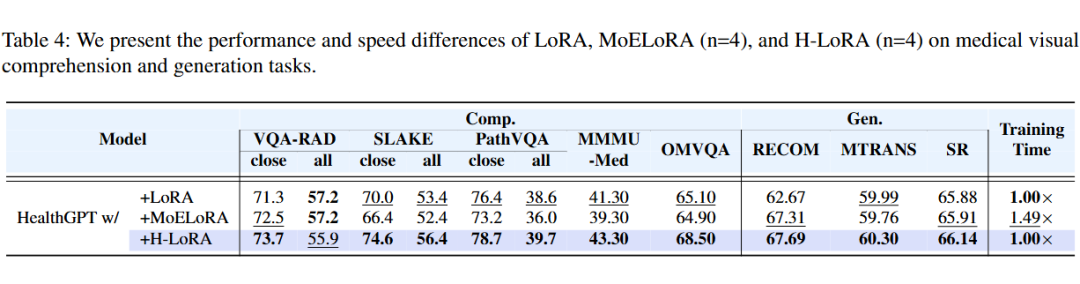
4.3.2 异构低秩适应
相比传统的 MoELoRA 方案将多个 LoRA 模块简单堆叠为专家,HealthGPT 提出的 H-LoRA 有效地优化了专家模块的结构,在效率和收敛速度上取得了进一步提升。
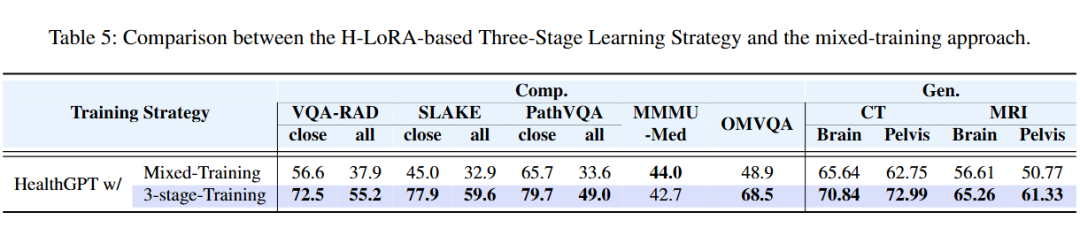
4.3.3 三阶段学习策略
HealthGPT 提出的三阶段学习策略有效缓解了视觉理解与生成任务之间的模式冲突,实验结果表明,相较于传统的混合训练方法,该策略实现了明显的性能提升。

关键结论
HealthGPT 通过其创新的 H-LoRA 技术、层次化视觉感知方法和三阶段学习策略,在医疗视觉理解和生成任务中展现出了卓越的性能和可扩展性。它不仅在多个医疗视觉任务中优于现有的模型,还表现出良好的可扩展性和适应性。
此外,HealthGPT 在处理复杂的医疗任务时,能够有效地缓解理解与生成任务之间的冲突,为医疗领域的多模态应用提供了新的可能性。
(文:PaperWeekly)