



智东西3月16日报道,今日上午,百度文心大模型4.5和文心大模型X1两款大模型上新,已上线文心一言官网并免费开放,比之前百度官宣的4月1日全面免费提前了半个月。
体验地址:https://yiyan.baidu.com/
实践出真知,先来看下百度文心大模型X1的实战效果。





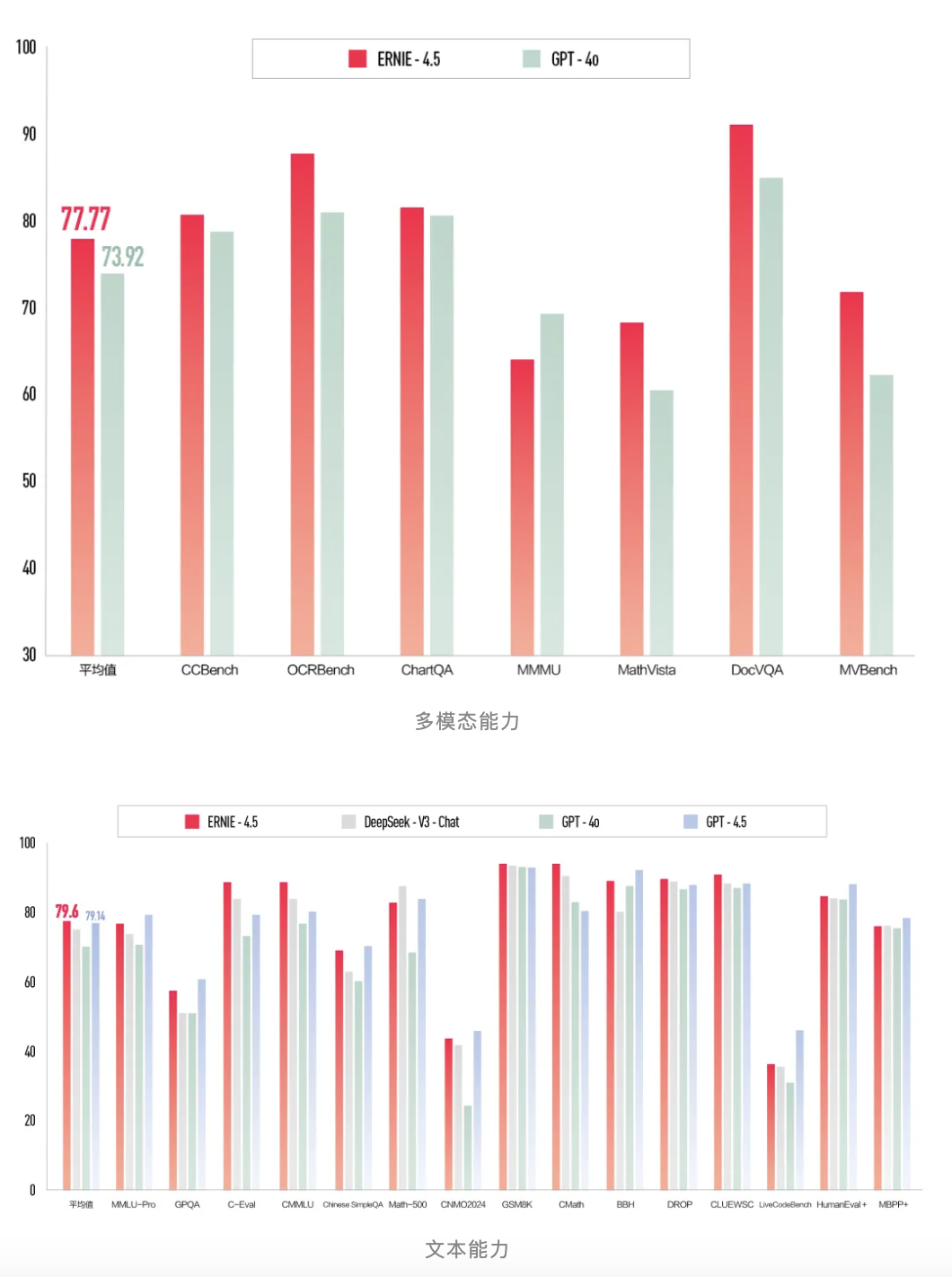
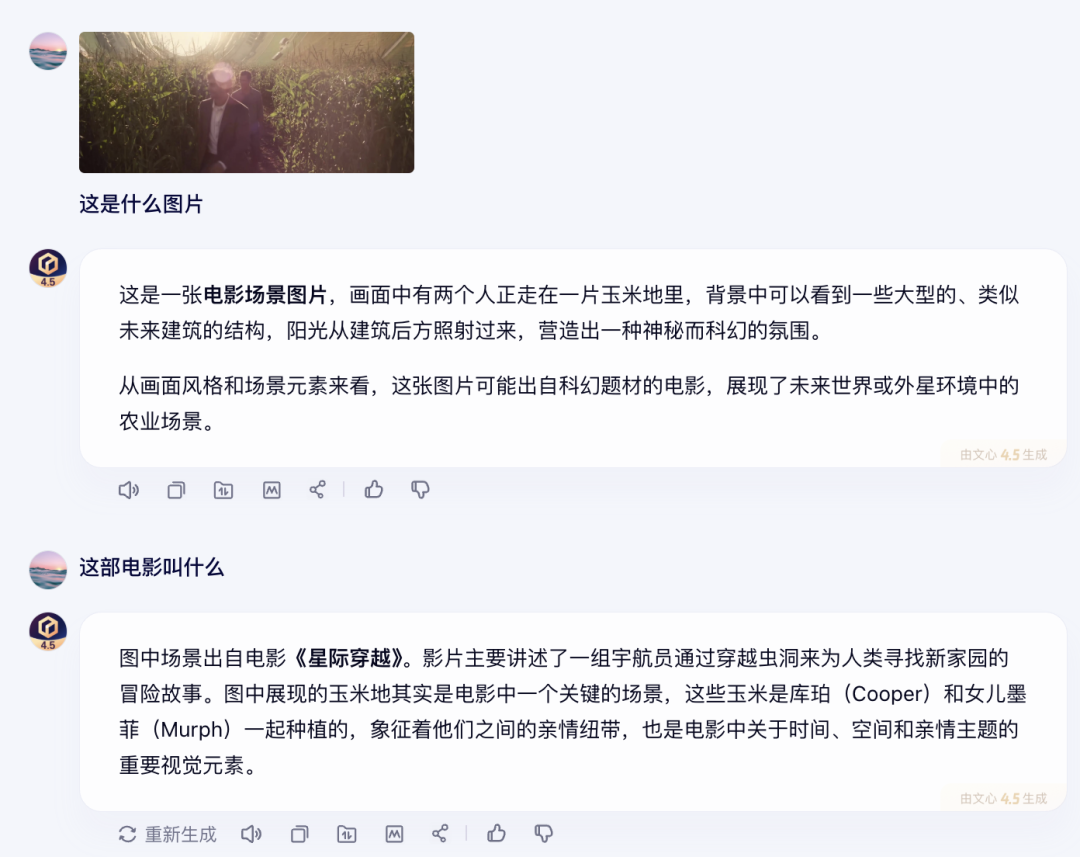
在图片理解能力,我上传了一张照片,图中两个人物并没有清晰正脸,所以所以需要模型从整个画面的构图、场景等来判断,文心4.5不仅清晰展现出了场景的具体特征,还给出了电影名称、相关人物以及场景在电影中的意义等。
我结合当下关注度较高的短视频爽剧,让文心4.5生成关于出身平凡主角隐藏惊人审视、顶级豪门云集、争夺商业帝国等元素的脚本。

两大模型的表现升级背后,是百度在核心技术方面的突破与深耕。
从技术层面看,更全面的深度思考模型文心X1背后有三大核心技术,递进式强化学习训练方法、基于思维链和行动链的端到端训练、多元统一的奖励系统。
基于应用递进式强化学习方法,可以在创作、搜索、工具调用、推理等场景全面提升模型的综合应用能力。思维链和行动链的端到端训练可以针对深度搜索、工具调用等场景,根据结果反馈进行端到端的模型训练,显著提升训练效果。
文心X1的训练还建立了统一的奖励系统,融合多种类型的奖励机制,为模型训练提供更加鲁棒的反馈。
此外,为了进一步提高模型学习效率,降低幻觉。一方面,文心4.5通过基于知识点的大规模数据构建技术,在知识分级采样、数据压缩与融合、稀缺知识点定向合成技术加持下,构建高知识密度预训练数据;另一方面,基于自反馈的Post-training技术,大模型可以融合多种评价方式的自反馈迭代式后训练技术,提升预训练模型对齐人类意图能力。
将时间的标尺拉长,百度文心大模型的发展历程清晰映照出国产大模型茁壮成长的坚实轨迹 。
2023年3月16日,文心一言正式发布并开启邀请测试,首日超6.5万家企业申请调用。
同年10月,文心大模型4.0发布,彼时达到了与GPT-4性能相当的水平。从去年6月至今,文心大模型4.0 Turbo、性能强劲的轻量模型ERNIE Speed Pro和ERNIE Lite Pro到当下的文心大模型4.5、文心大模型X1。
如今,百度文心大模型家族持续壮大,成员数量稳步递增,模型类型愈发多元。
到2024年,文心大模型的日均调用量达到16.5亿,而2023年同期这一数字仅为5000万次,增长达到33倍。
作为国产大模型的头部玩家,百度已经基于大模型构建起了全栈技术布局,以支撑其上述业务体系的发展。
在当下,大模型的蓬勃发展正深刻改写AI时代的演进轨迹。从技术架构来看,其技术栈大致可划分为四个关键层级,自下而上依次为芯片层、框架层、模型层以及应用层,而百度也成为当下全球范围内鲜少的在这四层都有所布局的公司之一。
也就是在芯片层,百度智能云已经成功点亮自研万卡集群昆仑芯三代万卡集群,框架层飞桨文心开发者数量已经达到1808万名,应用层百度已经基于大模型重构了百度搜索、百度文库等多个国民级应用。
从更为具体的数据层面来看,百度近十年来的累计研发投入已经超过1800亿元。
截至2023年12月,百度全球AI专利申请超过2.5万件,国内AI专利申请量近1.9万件,中国人工智能专利申请量突破8000件,国内人工智能专利授权率行业领先。
可以看出,百度在AI领域的研发与积累已经转化为自身大模型研发的养料以及国内大模型产业发展的加速引擎,助推国内大模型产业发展在全球的竞争态势中飞速前进。
(文:智东西)