

极市导读
本文提出了一种新的机器人操作范式,通过将互联网规模的基础模型生成的语言推理分割掩码融入端到端策略模型中,实现了样本高效的泛化能力,显著提升了机器人在新物体、新环境下的操作性能。此外,作者还设计了一个双流策略模型(TPM),通过局部-全局感知方式处理图像和掩码信息,进一步增强了模型的泛化能力和操作精度。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
本文介绍我们组(南京大学媒体计算研究组)在具身智能领域的系列工作之一 TPM,该工作和MSRA、人大等机构合作,论文最初版完成于23年6月,目前arxiv上已更新了最新版。
论文链接:
Transferring Foundation Models for Generalizable Robotic Manipulation
https://arxiv.org/abs/2306.05716v5
Pave the Way to Grasp Anything: Transferring Foundation Models for Universal Pick-Place Robots
https://arxiv.org/abs/2306.05716v1
Demo链接:
bilibili:
https://www.bilibili.com/video/BV178411Z7H2/
Youtube v2:
https://www.youtube.com/watch%3Fv%3DMAcUPFBfRIw
Youtube v1:
https://www.youtube.com/watch%3Fv%3D1m9wNzfp_4E%26t%3D1s
代码地址:
https://github.com/MCG-NJU/TPM
1. 研究愿景
构建能够在动态复杂环境中操控各种物体,并运用多种技能以满足人类指令需求的通用机器人,一直是具身智能领域的长期愿景。试想一下,你在家里不小心把牛奶洒在桌面上,并向机器人助手求助。它环顾四周,找到仅有的一块海绵并递给你。要实现这样的能力,整个机器人系统需要具备在开放环境下完成多模态感知-推理规划-决策-执行的能力,并构建它们之间的闭环控制回路。
2.研究背景与动机
长期以来,实现该愿景的主要挑战有两点。第一,目前robot manipulation的主流范式是基于真机遥操作数据和行为克隆训练policy。但由于真机数据采集成本及高且同质化严重,目前的policy相比于互联网模型数据效率低且泛化性很差,尤其是处理新的物体或环境时,例如首次开始大规模scaling up数据的RT-1[1]花了13个月采数据,仍无法泛化到新的物体概念。最近一年,随着用VLLM做初始基座,进一步scaling up数据并配合先进的的生成式policy来构建VLA,泛化性已经得到了明显提升。但我们看目前效果最好的π0[2]的fail cases,在做一些很简单的技能时仍可能失败。第二,人类的指令需求一般复杂抽象且常有歧义,尽管23年以来多模态大模型进展迅速,现有的VLLM已经能够比较好地完成具身推理和任务规划,但是生成的子任务依然只是告诉机器人“做什么”而缺乏“如何做”的行为信息。
针对第一点,和模仿学习得到的policy相比,互联网规模数据训练的基础模型有很强的泛化性,但是其没有与真实世界交互,物理知识匮乏,而模仿学习尽管数据效率低泛化性差,却恰恰能从人类的遥操作数据中学习到技能行为和相关的物理知识。在当时最先进的RT-1类工作基础上,我们希望将二者的优势结合起来。针对第二点,我们使用GPT-4来做指令推理和任务规划,相比于经典的使用自然语言做polciy conditioning的方式,我们使用语言推理的物体mask来做policy conditioning,相比于语言形式的sub-task,这隐式提供了互联网基础模型中强大的语义、几何和时序关联先验,细节见下节技术方案部分。
3.技术方案
如头图所示,在第一阶段,我们使用GPT-4(具体部署时可使用开源的DeTGPT[3]等替换)来对人类需求指令进行推理规划,得到当前子任务需要交互的物体。接下来,我们基于GroundingDINO[4]和SAM[5]得到物体的mask,在执行过程中,由于物体和环境可能发生遮挡及运动,后续物体mask由MixFormer[6]跟踪得到。在这一阶段,我们发现在日常室内场景中分割和跟踪的效果很好,系统误差主要源于GroundingDINO的误检(一些视觉概念容易识别错误,我们给GPT-4的输出添加<颜色>prompt来提高成功率),因此分割检测我们推荐蒸馏的小模型如MobileSAM[7]和MixFormerv2[8]等来加速部署。
在第二阶段,一个轻量化的policy接受当前的实时视觉观测和任务相关物体的mask作为输入,输出机械臂的末端位置变化和夹爪开关状态。如头图所示,我们的policy在设计上使用了双流的架构,其中一个较深的分支提取RGB观测的特征,一个较浅的分支提取RGB+mask的特征,这确保了模型联合捕获整个场景的全局特征以及物体附近的局部特征,并使用CBAM[9]进行融合。我们在实验中发现显式引入额外RGB-only分支的双流设计在泛化到新背景的设定中提升(相较于同参数量的baseline)非常明显,我们推测是因为RGB-only分支可以有效地捕获场景全局信息进而增强深度感知的能力。这里,对于不同的原子技能我们分配不同的mask value来进行区分,例如pick分配0,place分配1,…….,fold分配128等。
总结起来,我们的方法有效地统一了互联网基础模型泛化性强和模仿学习有效捕获人类示教数据中多模技能分布的优势,将互联网基础模型中蕴含的语义、几何与时序关联先验注入到端到端训练的策略模型中,有效地提升了机器人操控系统的泛化能力和样本效率。
4.与其他技术方案的比较
自RT-2[10]以来,最近一年多将多模态基础模型和机器人学习结合已成为逐渐收敛的思路。目前最主流的范式大概有以下两类:
-
多模态基础模型做感知规划+传统model-based planning/control: 代表性工作有Voxposer[11],Copa[12]和ReKep[13]等。这类方法具备强大的新任务零样本泛化能力,但由于通常需要深度校准、task-specific的prompt和没有进行训练,可扩展性可能有些受限。 -
多模态基础模型做policy的基座初始化+模仿学习微调: 这类工作目前最为火爆,代表性的有RT-2,OpenVLA[14], RDT-1B[15]和π0等。这类工作同样同时结合了基础模型以及模仿学习的优势,泛化性取得了巨大的提升。但是这种统一的一体化大模型做policy,可解释性较弱,同时通常需要较大的训练和数据采集开销,更重要的是带来巨大的推理开销,这对于要求实时高频控制的任务来说可能有些挑战。 -
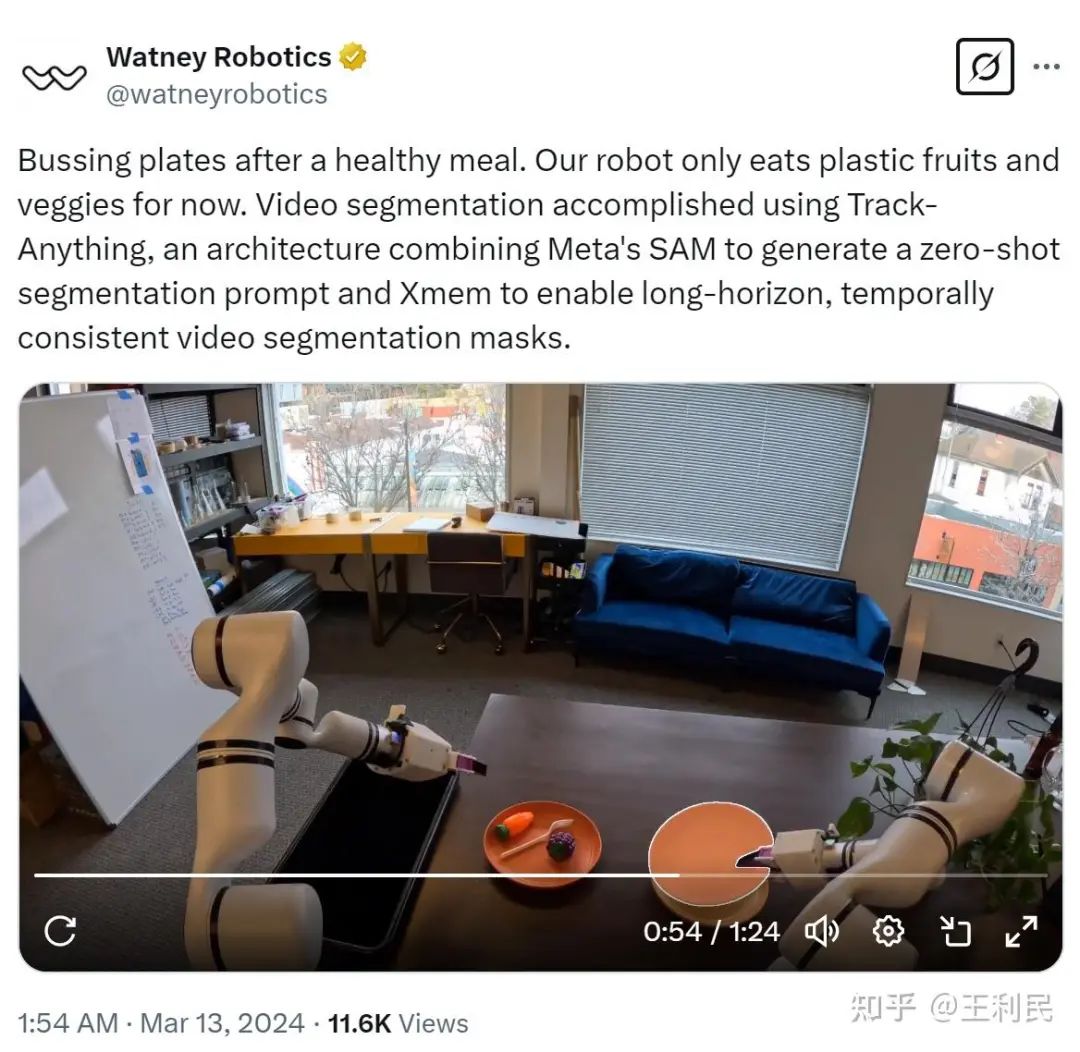
相比于第二类范式,TPM大大降低了训练和推理开销(每次执行动作只需要推理轻量化的跟踪分割模型和policy),同时也取得了出色的泛化性和数据效率,并保留了原基础模型固有的能力。我们发现,近期许多工作同样采用层次化设计的思想,将多模态基础模型和policy进行适当地解耦,例如RoboDual[16],以及2月底几乎同时发布的Figure AI的Helix[17]和Physical Intelligence的Hi Robot[18]。早在去年3月,Watney Robotics发布了他们使用双臂机器人收拾餐桌的demo,我们高兴地发现他们采用了和TPM高度相似的范式:使用基础模型推理得到的mask取代语言来condition policy。同时与我们的结论类似,他们也发现与一体化大模型的范式相比,这种multi-model的设计具有更好的样本效率及推理速度。

5.实验结果
我们基于Franka机械臂并采集了1000条数据来验证我们TPM范式和policy架构设计的有效性以及对新物体概念、背景和复杂干扰物的泛化能力。同时由于无需精确的深度校准和显式地跟踪模块,TPM可以很好地应对透明物体以及动态物体。此外,我们也验证了TPM的可扩展性,包括开关抽屉、叠布、放置到容器内等技能和部署在低成本的双臂机器人中。关于更多的实验设定和结果比较细节,欢迎大家check我们的paper。



6.总结与展望
尽管展示了优异的数据效率、推理成本和泛化能力,TPM这套范式仍存在许多缺点。第一,我们使用物体的mask替代语言去condition policy,尽管提供了更多的的先验和信息,但是对于不同的原子技能需要分配不同的mask value,这相对比较手工,同时视觉和文本有着比较好的对齐先验,这导致TPM在可扩展性上不如一体化的多模态基础模型policy。此外,对于不同的技能或任务,我们通常需要给基础模型设计和尝试相应的prompt,例如对于叠衣服这个任务,我们需要提示它寻找两个合适的夹取区域用于后续检测分割。第二,相对于一体化的多模态基础模型policy,TPM的范式引入了多模块化的机器人栈,系统中每个模块的误差都会被累计传递。总的来说,对于机械臂执行起来相对比较成熟的技能(尤其是object-centric的manipulation任务),TPM兼具了数据效率、推理成本和泛化能力,比较实用。对于系统误差问题,在未来可以进一步对每个模块进行单独scaling和优化,同时也可以像UniAD[19]那样进行联合地端到端训练。
参考文献
[1] Rt-1: Robotics transformer for real-world control at scale
[2] π0: A Vision-Language-Action Flow Model for General Robot Control
[3] Detgpt: Detect what you need via reasoning
[4] Grounding dino: Marrying dino with grounded pre-training for open-set object detection
[5] segment anything
[6] Mixformer: End-to-end tracking with iterative mixed attention
[7] Faster segment anything: Towards lightweight sam for mobile applications
[8] Mixformerv2: Efficient fully transformer tracking
[9] Cbam: Convolutional block attention module
[10] Rt-2: Vision-language-action models transfer web knowledge to robotic control
[11] Voxposer: Composable 3d value maps for robotic manipulation with language models
[12] CoPa: General Robotic Manipulation through Spatial Constraints of Parts with Foundation Models
[13] Rekep: Spatio-temporal reasoning of relational keypoint constraints for robotic manipulation
[14] Openvla: An open-source vision-language-action model
[15] Rdt-1b: a diffusion foundation model for bimanual manipulation
[16] Towards Synergistic, Generalized, and Efficient Dual-System for Robotic Manipulation
[17] Helix: A Vision-Language-Action Model for Generalist Humanoid Control
[18] Hi Robot: Open-Ended Instruction Following with Hierarchical Vision-Language-Action Models
[19] Planning-oriented Autonomous Driving

(文:极市干货)