跳至内容

谷歌团队的一篇最新论文或将揭开下一代AI大模型训练新范式。
这是一篇关于语言模型训练方式的论文,由谷歌Research、谷歌Search和谷歌DeepMind三大团队人员合力完成,他们提出了一种“DiLoCo的缩放定律”,可使语言模型训练具有可靠且稳健的扩展性。
论文第一作者、GoogleAI分布式机器学习研究员Zachary Charles表示:“这是分布式训练在越来越大的模型上发挥作用的关键一步,我们可以跨数据中心进行LLM训练,并且能够很好地扩展到越来越大的模型!”
未来的智能或将是分布式的,而DiLoCo可能起到关键“钥匙”作用。
网友评论称,该研究对去中心化训练总体上非常乐观,我们距离在遍布全球的GPU上训练超大型模型可能只差几篇论文了。
“Scaling Law” ( 缩放定律)在计算机科学、物理学、机器学习等多个领域都有应用。
在机器学习领域,特别是深度学习中,缩放定律主要探讨模型性能(如准确率、损失值等)与模型规模(参数数量)、数据集大小以及计算资源之间的关系。
AI圈公认的是,Scaling Law由OpenAI团队于2020年正式提出,并在其论文《神经语言模型的扩展定律》(Scaling Laws for Neural Language Models)中进行了阐述。
但很多人可能想不到,关于Scaling Law的发现最早还能追溯到百度。2017年12月,百度硅谷人工智能实验室团队曾发表了一篇名为《DEEP LEARNING SCALING IS PREDICTABLE, EMPIRICALLY》(《经验表明深度学习是可预测的》)的论文,就曾探讨了机器翻译、语言建模、图像处理和语音识别等四个领域中的Scaling现象。
前OpenAI研究副总裁、美国人工智能独角兽公司Anthropic创始人Dario Amodei ,2014年11月至2015年10月期间曾在百度硅谷人工智能实验室工作,他曾提到那时在百度研究AI时,就已经发现了Scaling现象,但可惜的是百度没有将这一发现正式命名为 “Law”。
随着业界朝着参数越来越大的AI模型拓展,数据并行方法中固有的频繁同步需求会导致显著的训练速度减缓,这对进一步扩大模型规模构成了严峻挑战。
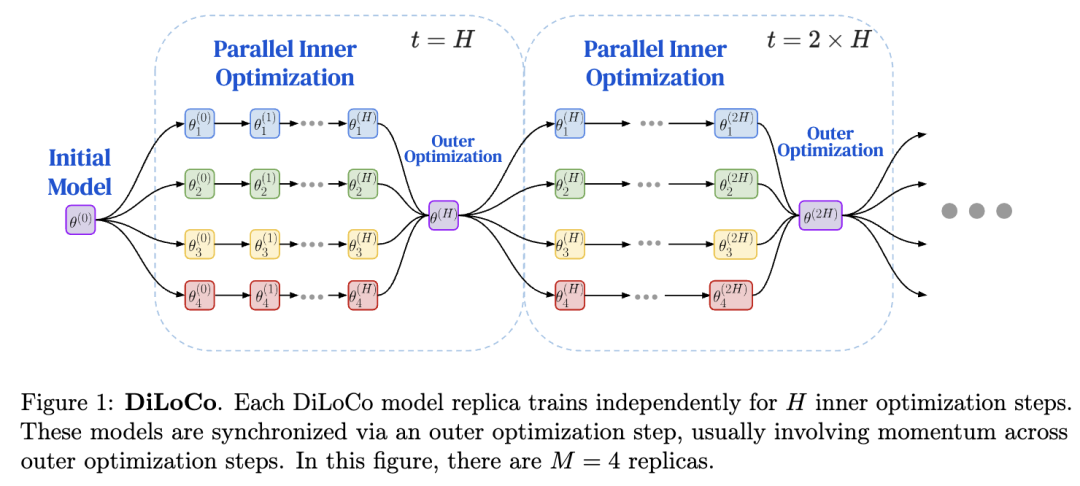
DiLoCo则是一种分布式低通信方法,该方法旨在不降低模型质量的前提下放宽同步要求。
在这篇新论文中,研究人员测试了在固定计算资源预算的情况下使用DiLoCo训练大语言模型(LLMs)时的缩放定律特性。
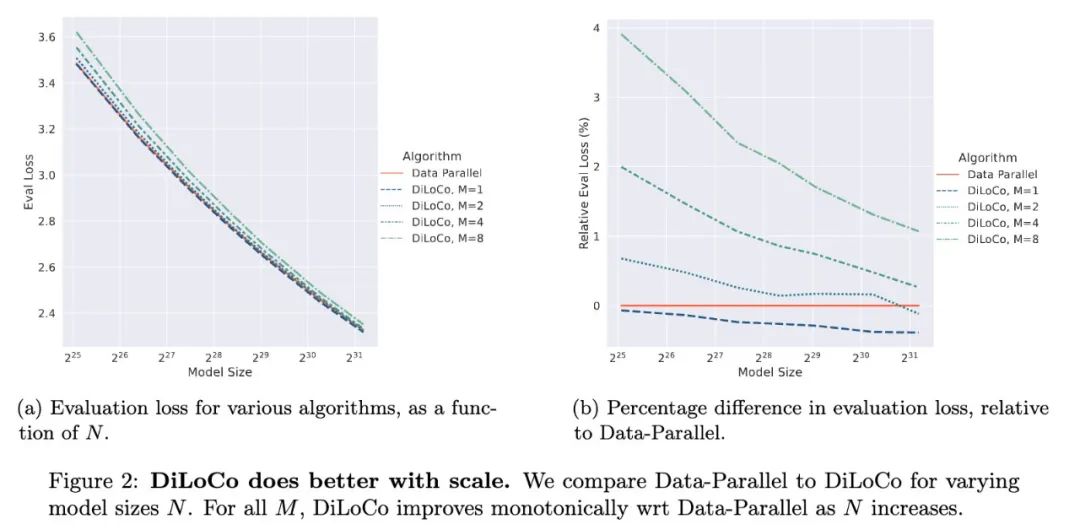
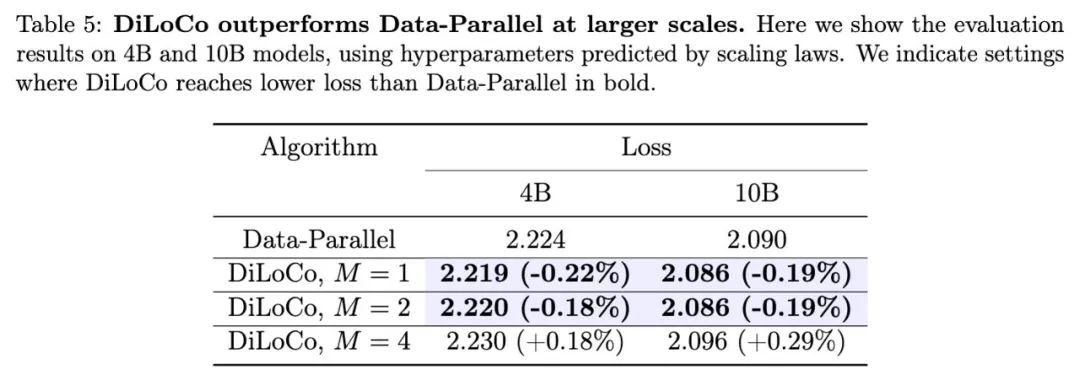
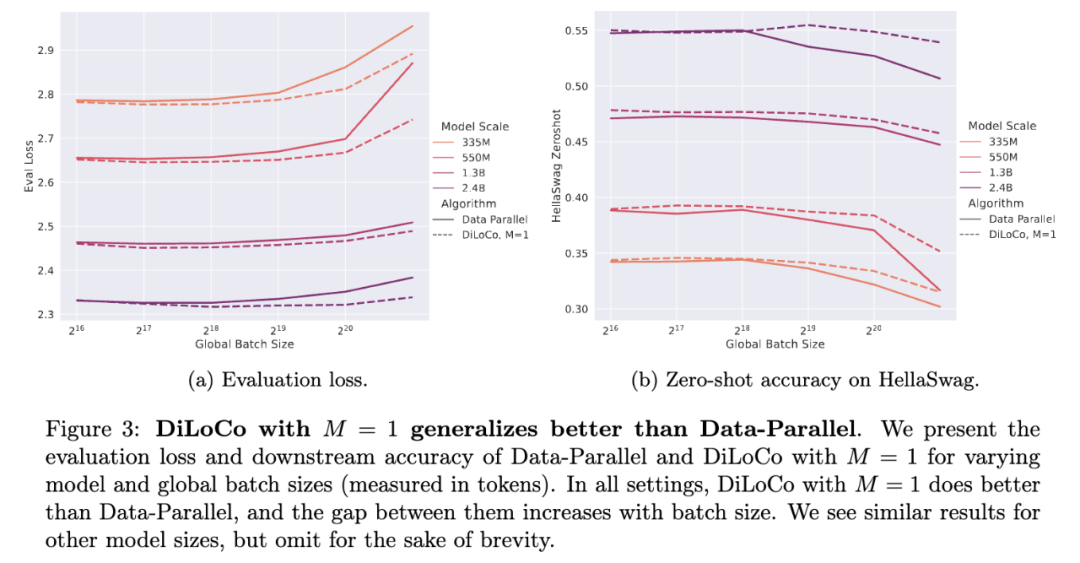
结果有点小惊喜,DiLoCo在模型规模变化时,其扩展性既具有可预测性又十分稳健,经过良好调优后,随着模型规模的增大,DiLoCo在扩展性方面优于数据并行训练方法,而且即使在模型规模较小的情况下,其性能也能超过数据并行训练方法。
1、DiLoCo的超参数在不同的模型规模下都具有稳健性且是可预测的;
2、随着模型规模的增大,DiLoCo相比数据并行训练有了进一步的提升;
3、DiLoCo所使用的带宽比数据并行训练少几个数量级;
4、DiLoCo能够承受比数据并行训练大得多的批量大小。
当下,训练大型语言模型(LLMs)的默认方法仍然是大批量分布式数据并行训练,然而,在较小规模下可以忽略不计的带宽和通信限制,在较大规模时却成了主导影响因素。
一些大型科研机构和科技公司,为了充分利用多数据中心的资源优势、实现数据的分布式处理和提高模型的泛化能力,都在积极探索和尝试跨数据中心的LLM训练技术,可以说,DiLoCo的缩放定律不仅减少了通信量,还使得数据并行分布式训练(DDP)能够扩展到更多的计算资源上,有望破解当下的大规模AI训练瓶颈。
论文第一作者Zachary Charles在社交媒体分享了一些团队的重要发现。
关键发现 1:规模效应。相对于数据并行,DiLoCo在规模方面表现更佳,即使研究人员开始对更大的模型进行推断,使用缩放定律来预测最佳超参数,DiLoCo仍然表现得非常好。
关键发现 2:具有单一模型副本的DiLoCo比数据并行训练也更好!这是Lookahead优化器的增强版本,它不会减少通信,但具有更好的泛化能力,并且对于较大的批量大小表现更好。
关键发现 3:DiLoCo增加了最佳批次大小,这意味着研究人员可以水平扩展,从而进一步缩短端到端的挂钟训练时间!(挂钟时间是指从训练开始到结束整个过程所花费的时间)。
事实上,使用理想化的挂钟时间模型,研究人员发现这种现象使得DiLoCo即使在使用高带宽网络进行训练时也比数据并行更快,而当使用低带宽网络时,性能差距就明显体现出来了。
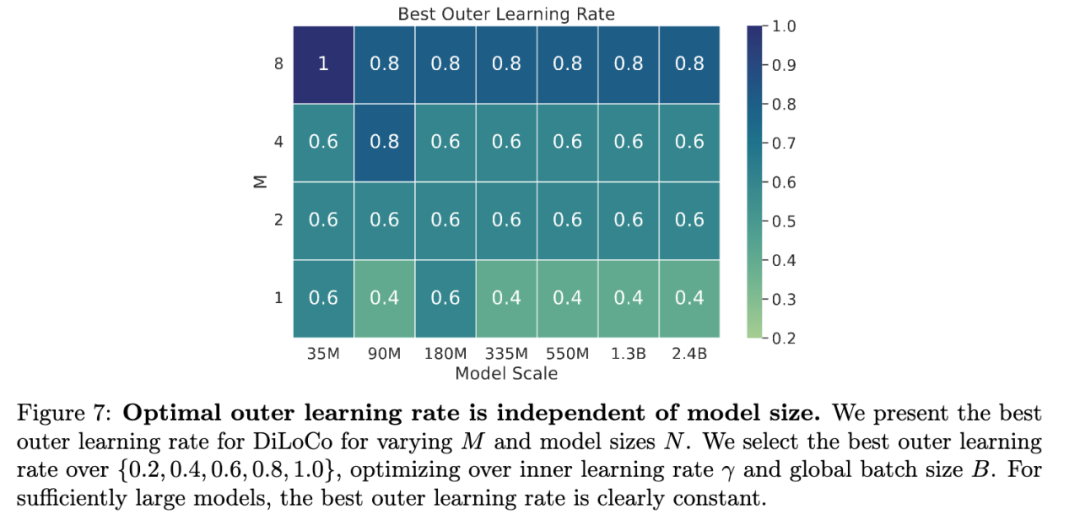
关键发现4:DiLoCo的外部学习率(使同步操作保持性能的关键)与模型大小保持不变,这意味着研究人员可以在小规模上调整DiLoCo特定的超参数,并在大规模上使用它们。
Zachary Charles表示,DiLoCo也有助于过度训练(超量训练),过度训练可能成本相当高,但DiLoCo增大的批量大小以及减少的通信量意味着,在与数据并行训练进行1倍过度训练相同的时间内,使用DiLoCo通常能够进行4倍的过度训练。
NanoDO代码库是一个由Google DeepMind团队开发,采用JAX框架构建的极简Transformer解码器语言模型。谷歌研究人员将本次研究成果与NanoDO代码库(https://github.com/google-deepmind/nanodo)相结合,从而能够在JAX框架下非常轻松地对大型语言模型应用DiLoCo方法。
第一,可以从已应用于数据并行训练缩放定律分析的多个方面来扩充DiLoCo的缩放定律分析;
第二,缩放定律可进一步调整,将对DiLoCo及相关方法的改进纳入其中,这些改进包括异步更新、流式DiLoCo以及与训练方法协同设计的模块化架构;
第三,显然需要开发相关系统和软件,以便大规模部署DiLoCo这类方法,并在实际超大规模场景中实现其通信效率优势。
谷歌团队近期在AI底层技术和开源方面实现了很多进展,一直在探索算力和模型性能之间平衡的极限。
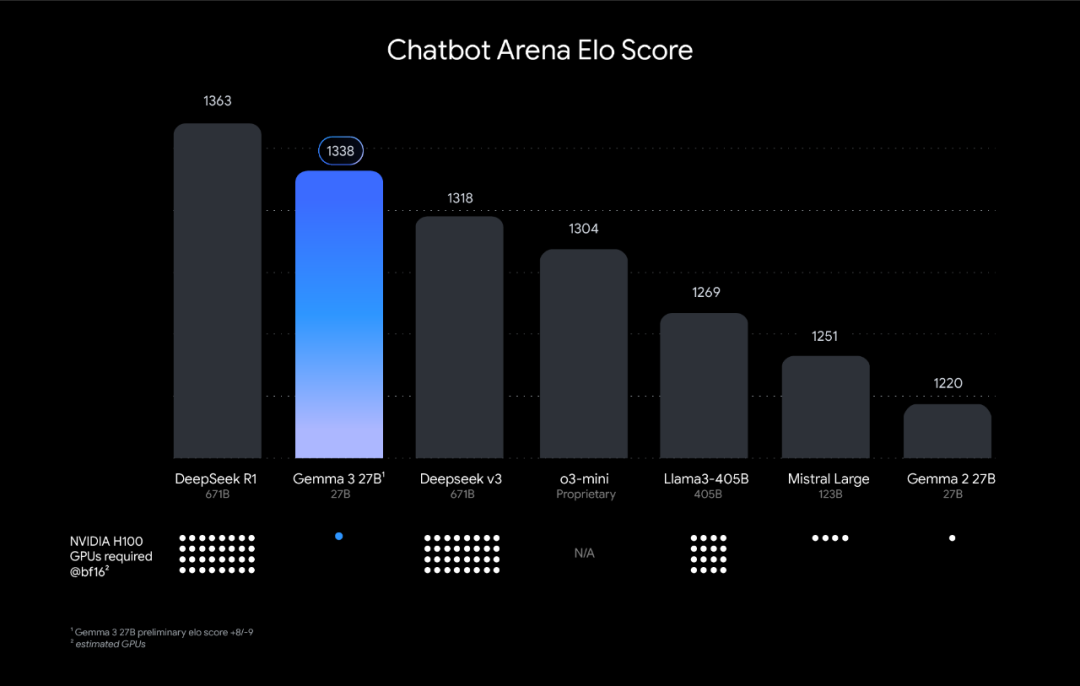
在DiLoCo缩放定律发布前几天,谷歌开源了一个Gemma 3模型,是一个可在单个GPU或TPU上运行的目前功能最强的AI模型,其最大的27B模型仅需一个H100 GPU就能运行,而其他模型想要实现类似性能则需要至少10倍的算力。
谷歌的动作也反映了当下AI模型发展的最新趋势,一种是被设计为轻量级、高性能模型,能够轻松在手机、笔记本电脑到工作站等便携设备上直接快速运行,帮助开发者在人们需要的任何地方创建人工智能应用程序。
另一种路径就是AI巨头们下一步押注的超级大模型,例如业界推测GPT-5或将达到10万亿参数规模,如何通过技术优化提升超大规模训练效率、降低训练成本十分关键。
从去年开始,业内也偶尔传出scaling law已失效、预训练即将结束的论断,但目前看来,scaling law并未失效,而是需要更多创新了,尤其是在模型参数规模、训练数据量和计算资源不断加大的情况下,相关的降本增效技术突破或给AI发展带来新的转折点。
(文:头部科技)