

今天是2025年3月18日,星期二,北京,天气晴。
我们今天来回到AI搜索和文档解析这块的工作。
一个是,AI搜索进展,哥伦比亚大学最新研究显示,AI搜索错误率高达60%,这个结论倒不奇怪,结论依赖于实验条件,我们把这个结论是怎么得出来的做个解释,这个对于评测是有价值的。
另一个是SmolDocling的小参数量训练及DocTags设计思路,多模态大模型这个方面,最近一段时间,先后出现了omlocr,mistralocr和smalldocling-256M的工作,这三者都是一类技术范式,不值得大吹特吹为最强OCR,实在是混淆视听。在一些评测榜单中的表现,很多也都是集中于英文文档,是拟合的结果,对于中文文档,表现并不会很好。
但是,各类多模态方案,其核心点,其实还是对文档图像模型的特征建模,或者训练数据构造上的差异,这个是跟任务强相关,所以,我们来看SmolDocling的独特之处,尤其是其对于表格的格式化表示思路,会更有意义。
抓住根本问题,做根因,专题化,体系化,会有更多深度思考。大家一起加油。
一、当前AI搜索可信度的简单评测结论
AI搜索进展,哥伦比亚大学最新研究显示,AI搜索错误率高达60%,对八款 AI 搜索展开研究,包括 ChatGPT Search、Perplexity、Perplexity Pro、Gemini、DeepSeek Search、Grok-2 Search、Grok-3 Search 和 Copilot。https://www.cjr.org/tow_center/we-compared-eight-ai-search-engines-theyre-all-bad-at-citing-news.php
里面都拿到了哪些有趣的结论?
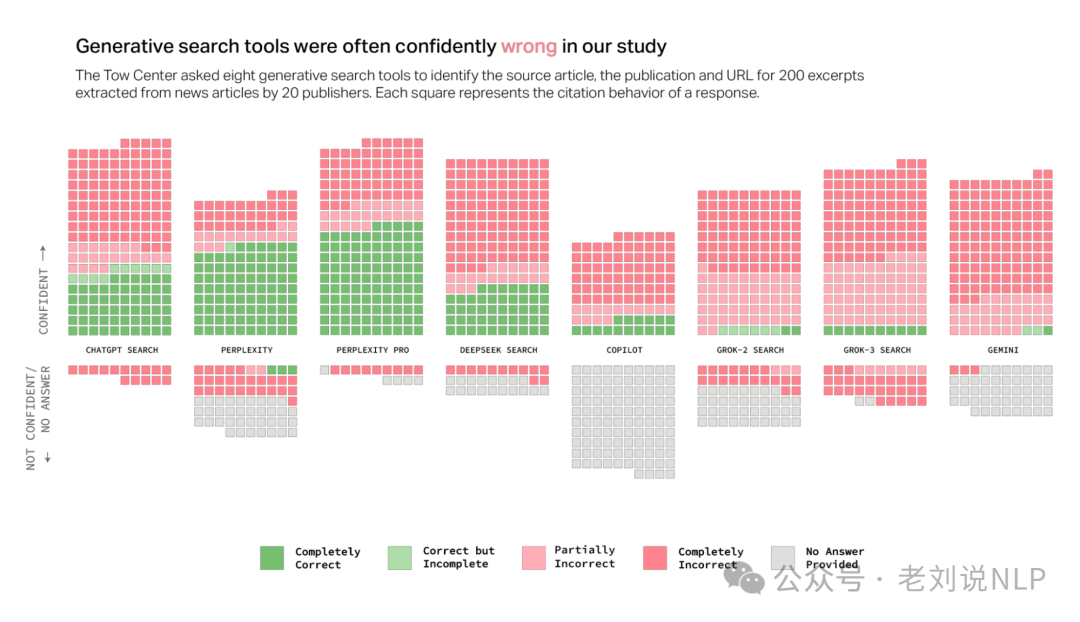
1)不准确的回答:大多数聊天机器人无法准确检索文章,错误率超过60%。例如,Perplexity错误回答了37%的问题,而Grok 3错误率高达94%。
2)过度自信的错误:聊天机器人在提供错误答案时通常表现出过度的自信,很少使用限定性词语或承认知识空白。
3)付费模型的问题:付费模型(如Perplexity Pro和Grok 3)虽然正确率较高,但错误率也更高,倾向于提供确定但错误的答案。
4)忽略robots.txt协议:许多聊天机器人绕过了出版商设置的robots.txt协议,访问被禁止的内容。
5)错误引用:聊天机器人经常引用错误的文章版本,甚至在没有授权的情况下引用被聚合或复制的内容。 6)伪造链接:聊天机器人提供的链接往往是伪造的或无效的,导致用户无法验证信息来源。
这个评测结论是怎么拿到的?
每个出版商随机选取十篇文章,然后手动从这些文章中选取直接摘录用于查询,在向每个评测模型提供选定的摘录之后,要求它使用以下查询来识别相应文章的标题、原始出版商、发布日期和网址:

特意挑选了一些摘录,如果粘贴到传统的谷歌搜索中,能够在前三条结果中找到原始来源,总共进行了1600次查询(20家出版商×10篇文章×8个聊天机器人)。根据三个属性手动评估回答:(1)检索到正确的文章,(2)正确的出版商,以及(3)正确的网址。
根据这些参数,每个回答都被标记为以下标签之一:正确:所有三个属性都正确;正确但不完整:一些属性正确,但答案缺少信息;部分错误:一些属性正确而其他属性错误;完全错误:所有三个属性都不正确和/或缺失;未提供:没有提供信息;爬虫被阻止:出版商在其robots.txt文件中禁止了爬虫。
所以说,上面那个结论,其实还是要跟具体的评测方式想绑定的,
二、SmolDocling的小参数量训练及DocTags设计思路
关于文档智能进展方面,我们在之前的文章《再看文档解析该如何做?pipeline派及end2end两派路线及代表工具》(https://mp.weixin.qq.com/s/2TJH3udlQNeUcSZIuNzeAg)中已经介绍了文档处理的两个基本路径。
多模态大模型这个方面,最近一段时间,先后出现了omlocr,mistralocr和smalldocling-256M的工作,这三者都是一类技术范式,不值得大吹特吹,在一些评测榜单中的表现,很多也都是集中于英文文档,是拟合的结果,对于中文文档,表现可能并不会很好。
但是,各类多模态方案,其核心点,其实还是对文档图像模型的特征建模,或者训练数据构造上的差异,这个是跟任务强绑定的,所以,这也就成为了一些看点。
我们今天来看:《SmolDocling: An ultra-compact vision-language model for end-to-end multi-modal document conversion》,https://huggingface.co/ds4sd/SmolDocling-256M-preview,https://arxiv.org/pdf/2503.11576,还是end2end那条路的方案,这次主打的点是小参数256M。
我们应该关注什么?具体看几个核心点。
模型架构上,基于Hugging Face的SmolVLM-256M,使用SigLIP作为视觉骨干网络,并采用轻量级的SmolLM-2家族作为语言骨干网络。通过像素shuffle方法压缩视觉特征,并引入特殊标记以提高标记效率。这个没有新意。
训练数据构造上,引入了一种新的文档标记格式DocTags,用于标准化文档转换,这个是核心意义。DocTags定义了一个明确的标签和规则集,以分离文本内容和文档结构,从而提高图像到序列模型的性能,如下图就是个具象化的例子。
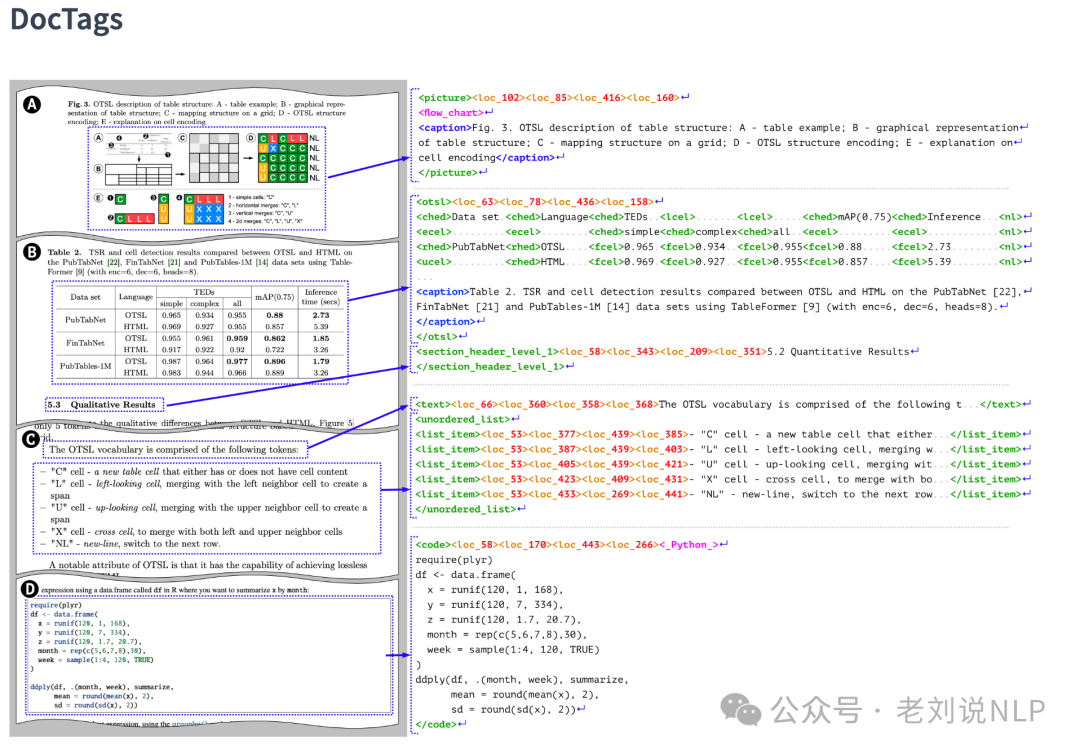
对应的语法如下:

再次强调,这是整篇论文的核心,就是标签的设计:
使用类似于XML的符号表示标签。一些标签有开始和结束部分,并围绕文本内容(或其他标签),例如:<text>你好,世界</text>。其他标签是独立的,没有结束标签;它们标记特殊的指令,例如:<page_break>。
完整的DocTags片段可以代表一页或多页,包裹在<doctag>...</doctag>中。 当内容代表多页时,我们使用<page_break>标签作为分隔符。
在<doctag>范围内,放置了高层级的标签,这些标签围绕文档某些块的文本内容并标识该块的类型。这些标签包括:<text>、<caption>、<footnote>、<formula>、<title>、<page_footer>、<page_header>、<picture>、<section_header>、<document_index>、<code>、<otsl>、<list_item>、<ordered_list>、<unordered_list>。每个元素都可以嵌套额外的独立位置标签,以编码其在页面上的位置作为一个边界框,在DocTags中表示为<loc_x1><loc_y1><loc_x2><loc_y2>。每个坐标对属于一个固定的网格。在我们的案例中,使用的整数值范围是从0到500,这与页面的宽度和高度成比例地映射。
其中:
1、<otsl>元素包含表格表示,带有以下OTSL标签,这些标签是独立的,用于描述表格结构:<fcel>、<ecel>、<lcel>、<ucel>、<xcel>、<nl>。
这些标签设计跟一般的表格html表示还不一样,可以参考《Optimized Table Tokenization for Table Structure Recognition》(https://arxiv.org/pdf/2305.03393),这个工作也是一个方向,觉得HTML表示表格很冗余,然后通过优化表格标记化来提高表格结构识别的准确性,提出一种新的优化表格结构语言(OTSL),以减少标记数量并缩短序列长度。
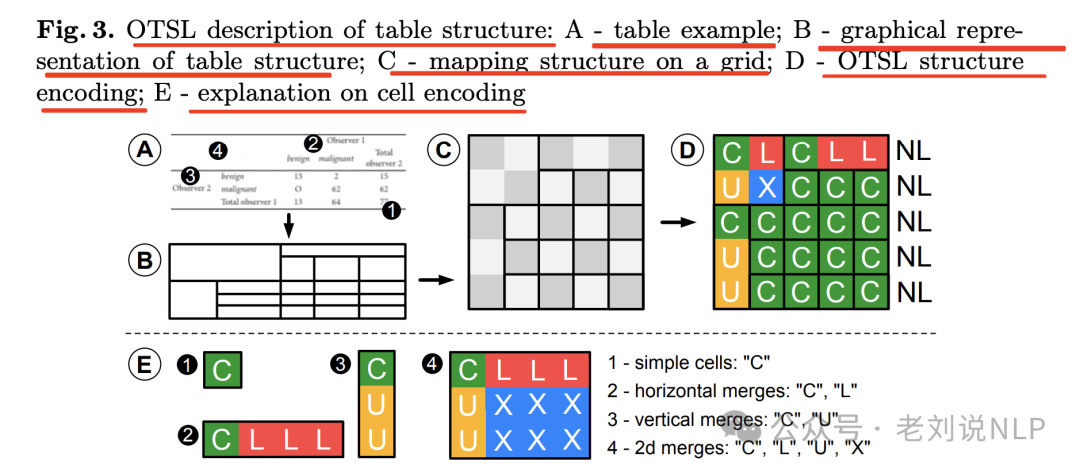
例如,如下图所示,HTML与OTSL表格结构表示方式的比较:(A)具有复杂行列标题的表格示例,包括一个二维空白跨度;(B)使用矩形布局的表格结构的简化图形表示;(C)HTML表示;(D)OTSL表示。

此示例展示了OTSL的许多关键特性,即其词汇量减少(本例中为12对比5)、序列长度缩短(55对比30)以及内部结构增强(HTML中每行的可变标记序列长度对比OTSL中的固定行数)。
实际上,表格的形式化定义有很多种,比如HTML、Latex或Markdown等等,也不是只有这一种。
那么,既然是一种表示方法,那么就具体看这个形式化定义,其定义了五个标记来描述基于原子二维网格的表格结构,标记包括:
“C”表示单元格(cell);
“L”表示左看单元格(left-looking cell);
“U”表示上看单元格(up-looking cell);
“X”表示交叉单元格(cross cell);
“NL” 表示换行(new-line)。
此外,语法外还有使用规则,遵循一系列语法规则,确保表格结构的严格矩形表示,并且每个新行以”NL”标记开始,包括:
左看单元格规则:”L”单元格的左邻居必须是另一个”L”单元格或”C”单元格;
上看单元格规则:”U”单元格的右邻居必须是另一个”U”单元格或”C”单元格;
交叉单元格规则:”X”单元格的左邻居必须是另一个”X”单元格或”U”单元格,上邻居必须是另一个”X”单元格或”L”单元格;
第一行规则:第一行只允许”L”单元格和”C”单元格;
第一列规则:第一列只允许”U”单元格和”C”单元格;
矩形规则:表格表示总是矩形的,所有行必须有相同数量的标记,以”NL”标记结束。
因此,根据这个规则,进一步将OTSL概念中的单元格区分为<fcel>-完整单元格或包含内容的单元格,以及<ecel> -空单元格,也用额外的标签<ched>、<rhed>、<srow>增强表格结构信息,这些标签替换<fcel>来描述属于表格列和行头的单元格,以及相应地描述表格节。
2、<list_item>元素放置在<ordered_list>或<unordered_list>内,定义它是否为枚举(有序)列表。
3、如果适当的图片或表格有自己的标题,<picture>和<otsl>元素本身可以封装<caption>标签。这样,可以将额外的描述性信息连接到文档中的插图和表格上。
4、<code>元素包含代码片段作为内容,因此尊重制表和换行。代码元素还包含特殊独立分类标签-<_programming-language_>,其中programminglanguage是合适的编程语言名称,支持的编程语言名称值(总共57个)包括:Ada、Awk、Bash、bc、C、C#、C++、CMake、COBOL等。
5、在<picture>元素内,包含了带有额外独立标签<image_class>的图片分类,将来自数据集的图像分类为以下类别:自然图像、饼图、条形图、折线图、流程图、散点图、热图、遥感、化学分子结构、化学马库什结构、图标、标志、签名、印章、二维码、条形码、截图、地图、地层图、CAD绘图、电气图。
训练方法上,使用课程学习方法逐步对齐模型以进行文档转换。首先将DocTags作为标记集成到tokenizer中,然后冻结视觉编码器并仅训练剩余的网络以适应新的输出格式。最后,解冻视觉编码器并在预训练数据集上进行训练,并使用所有任务特定的转换数据集进行微调。这个也没有亮点。
然后,基于这个标记语法,开始做数据构造,如下。
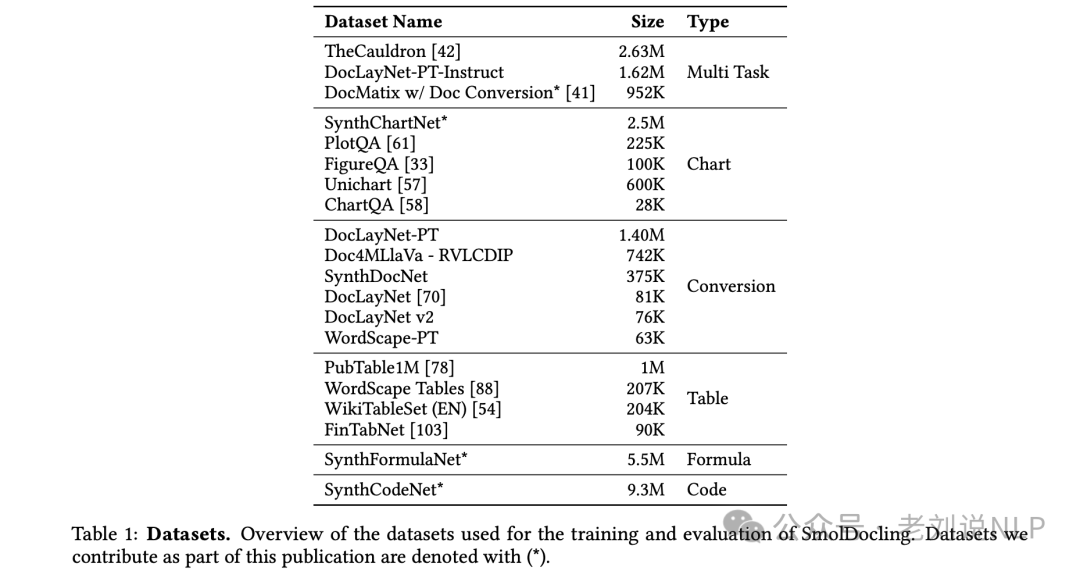
可以看到,数据其实还是用全是英文数据,并且很大,所以,这是强拟合操作,所以,很预见的是,中文文档效果并不会很好。
接着,就是在做微调阶段,核心在于instruction的设计:

最后,看看功能侧的效果,提供的功能倒是挺多的。

总结
本文主要介绍了当前AI搜索引用可信度的简单评测结论、SmolDocling的小参数量训练及DocTags设计思路两个话题,尤其是其中的建模细节,是我们应该看的,实际效果如何,我们需要自己去测试。
踏踏实实的,长期进步。
参考文献
1、https://www.cjr.org/tow_center/we-compared-eight-ai-search-engines-theyre-all-bad-at-citing-news.php
2、https://arxiv.org/pdf/2305.03393
3、https://arxiv.org/pdf/2503.11576
(文:老刘说NLP)
Smoldocling 替你试过了,PDF,表格,图表都能扫描的出来。。还是不错的。。。。