







迪士尼机器人Blue作为黄仁勋主题演讲的惊喜嘉宾压轴出场,摇头晃脑向黄仁勋撒娇卖萌,还听从黄仁勋的指令,乖乖站到了他的旁边。


4月1-2日,智东西联合主办的2025中国生成式AI大会(北京站)将举行。35+位嘉宾/企业已确认,将围绕DeepSeek、大模型与推理模型、具身智能、AI智能体与GenAI应用带来分享和讨论。更多嘉宾陆续揭晓。欢迎报名~



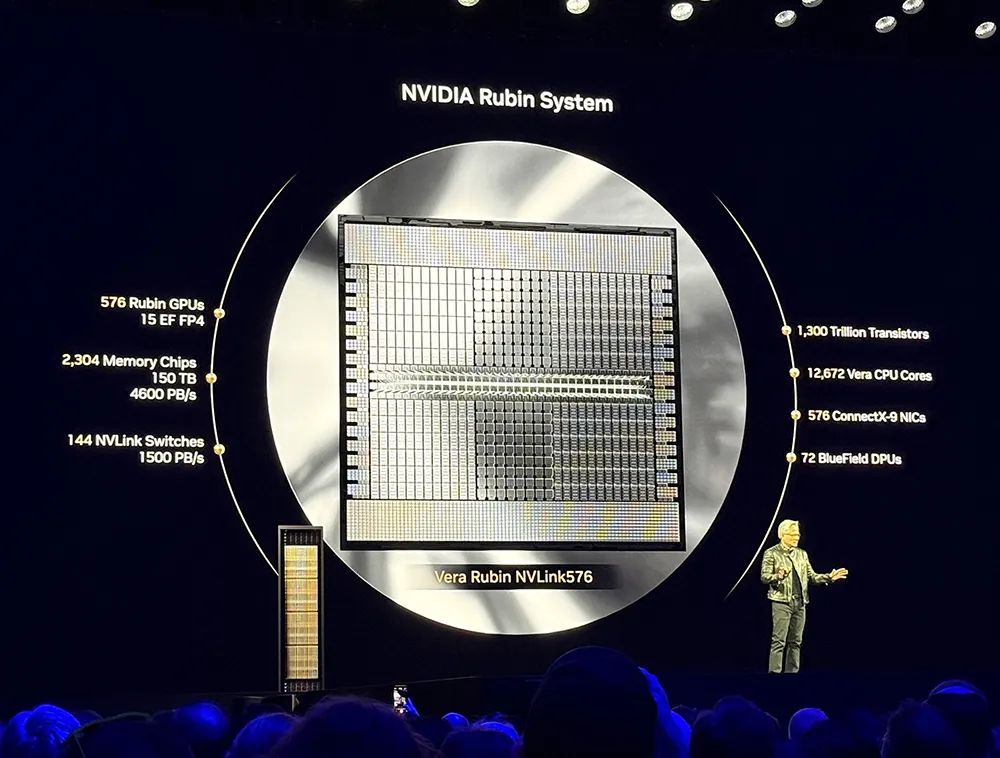
他公布了英伟达继Hopper、Blackwell之后的下一代GPU架构——Rubin。这一命名来自于发现暗物质的女性科学先驱薇拉·鲁宾(Vera Rubin)。

Rubin Ultra NVL576的FP4峰值推理算力高达15EFLOPS,FP8训练算力达到5EFLOPS,足足是GB300 NVL72的14倍,将于2027年下半年推出。

相较Hopper,基于Blackwell的AI工厂性能提高多达68倍,基于Rubin的AI工厂性能提高多达900倍。
![]()

下一代模型可能包含数万亿参数,可以使用张量并行基于工作负载进行任务分配。如取模型切片在多个GPU上运行、将Pipeline放在多个GPU上、将不同专家模型放在不同GPU上,这就是MoE模型。
流水线并行、张量并行、专家并行的结合,可以取决于模型、工作量和环境,然后改变计算机配置的方式,以便获得最大吞吐量,同时对低延迟、吞吐量进行优化。
黄仁勋称,NVL72的优势就在于每个GPU都可以完成上述任务,NVLink可将所有GPU变成单个大型GPU。


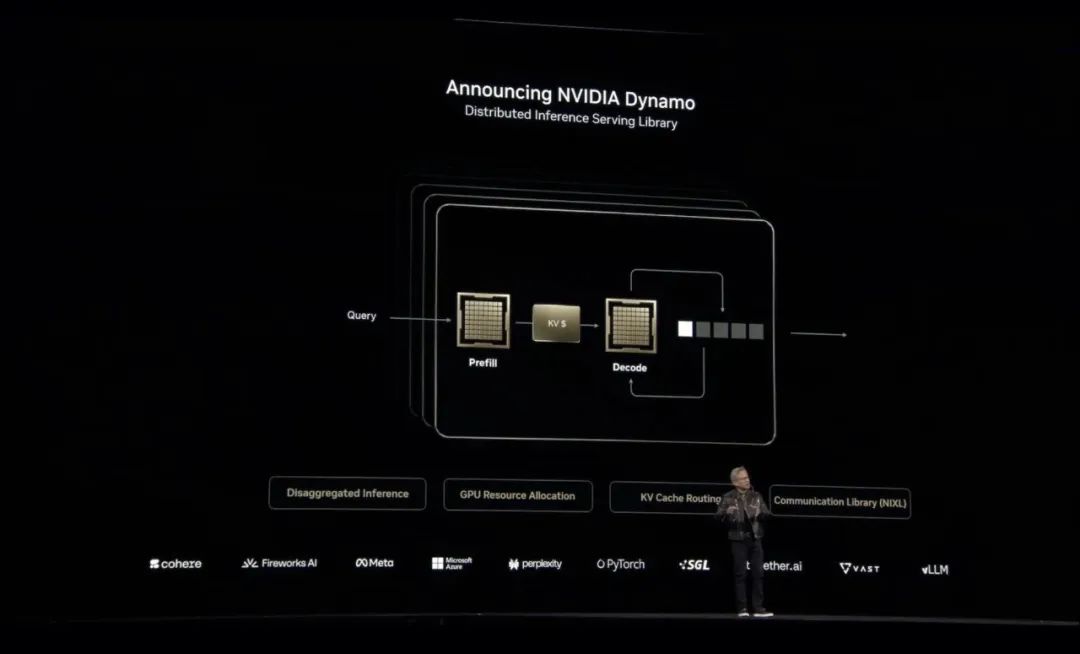
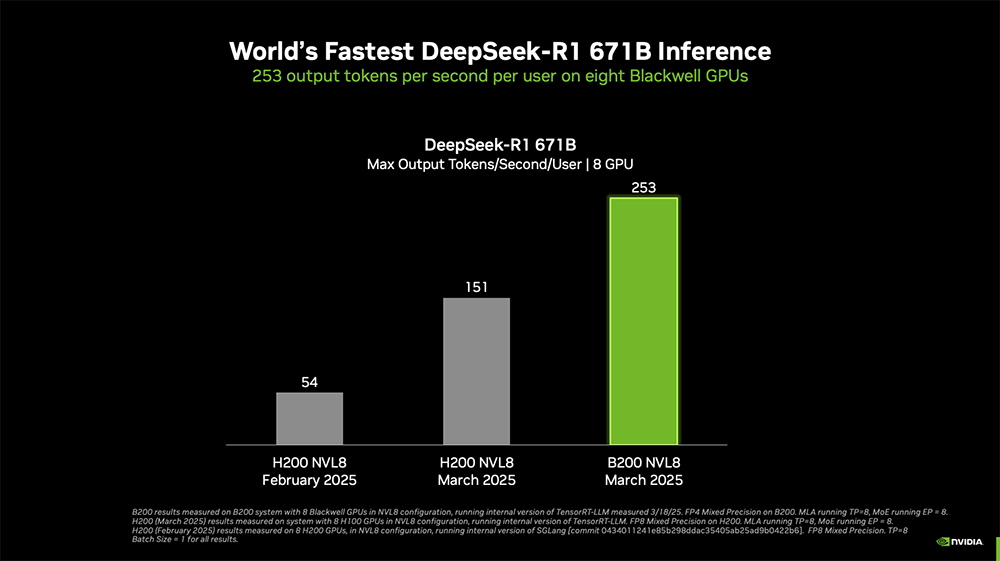
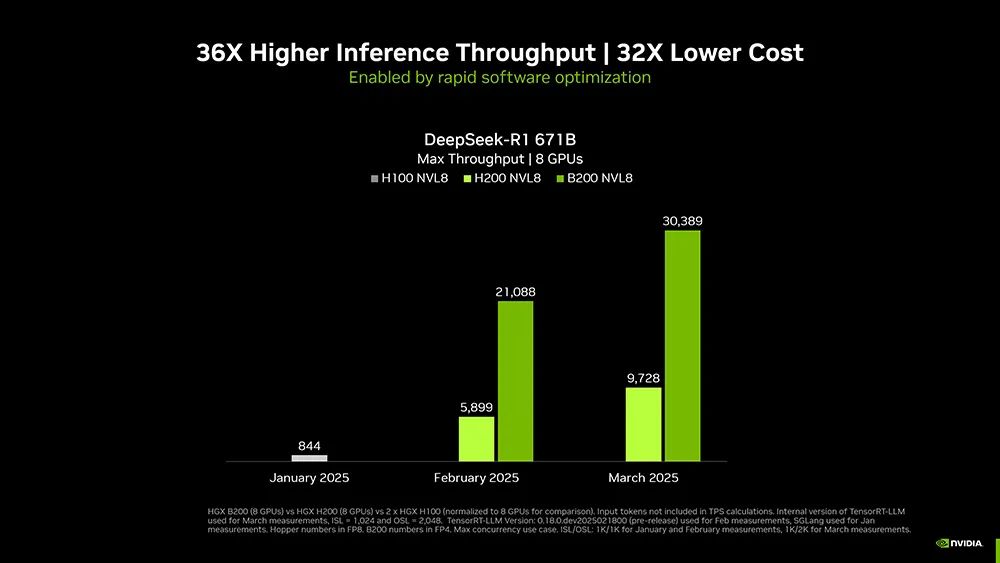
为了提高推理性能,英伟达采用Blackwell NVL8设计,之后又引入新的精度,用更少的资源量化模型。
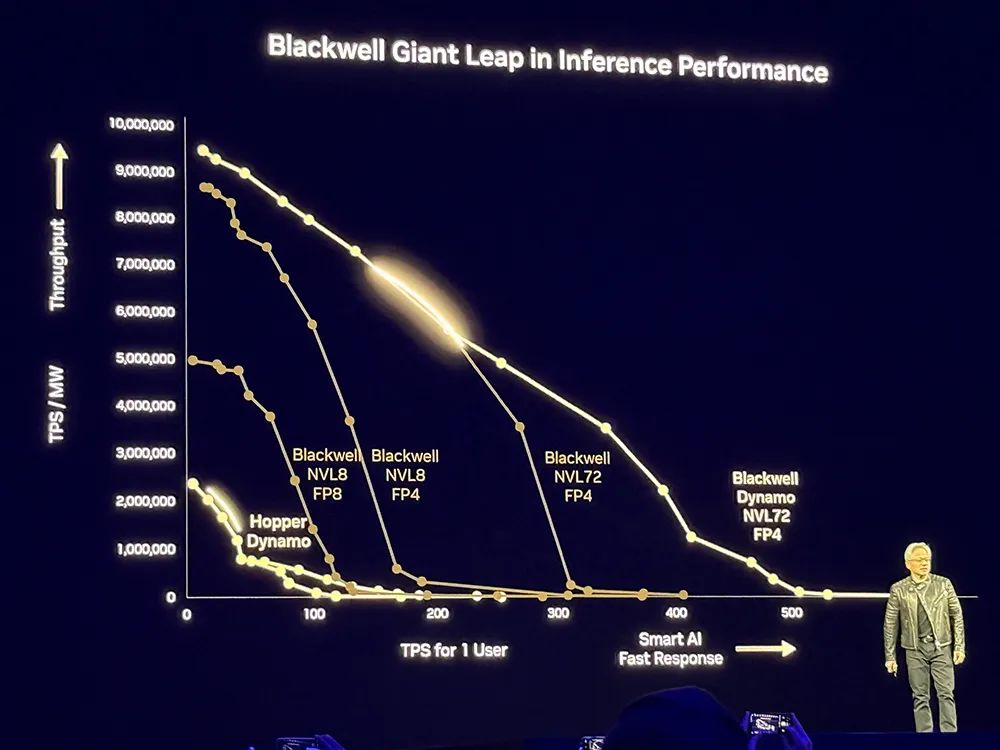
未来每个数据中心都会受到电力限制,数据中心的收入与之挂钩,因此英伟达用NVL72进行扩展,打造更节能的数据中心。

基于Dynamo,相比Hopper,Blackwell性能提升25倍,可以基于均匀可互换的可编程架构。在推理模型中,Blackwell性能是Hopper的40倍。
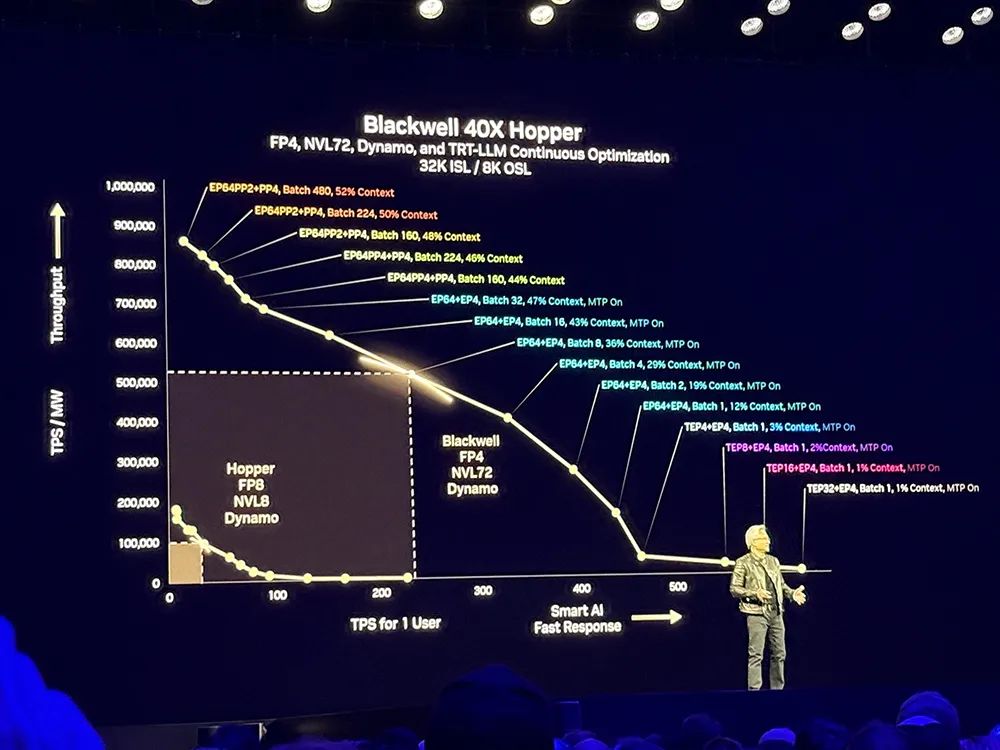
黄仁勋说:“这就是我以前为什么说,当Blackwell批量发货时,你不要把Hopper送人。”他调侃自己是“首席收入官”。

该软件完全开源并支持PyTorch、SGLang、NVIDIA TensorRT-LLM和vLLM,使企业、初创公司和研究人员能够开发和优化在分离推理时部署AI模型的方法。
大模型公司Cohere计划使用NVIDIA Dynamo为其Command系列模型中的AI智能体功能提供支持。
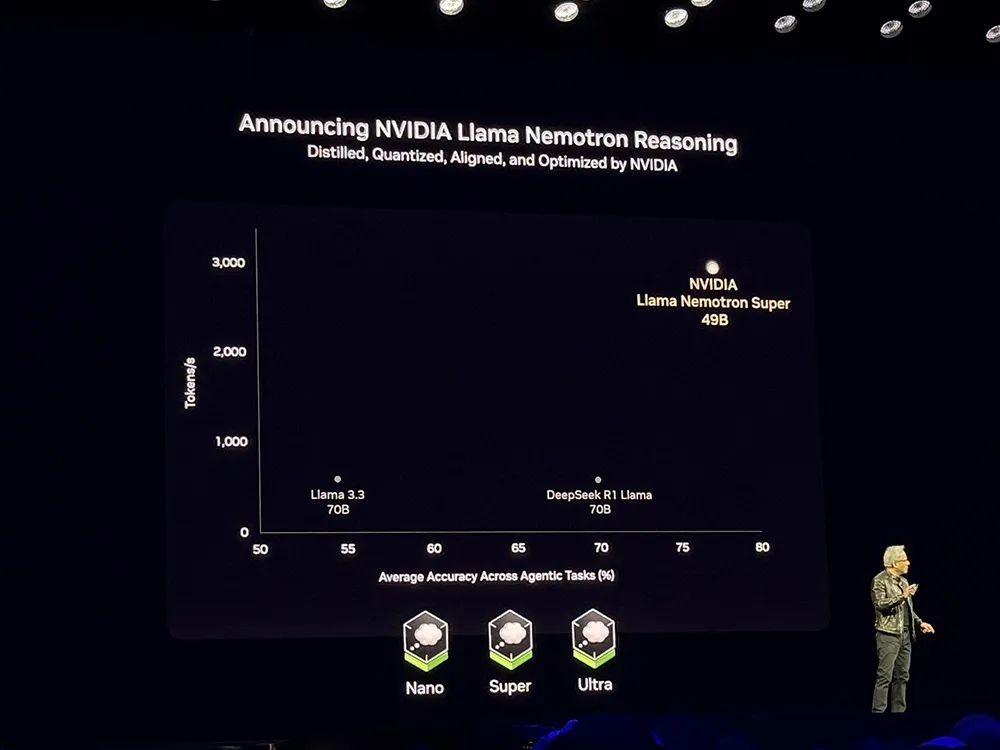




黄仁勋说CUDA-X是GTC的全部意义所在。他展示了一张自己最喜欢的幻灯片,包含了英伟达构建的关于物理、生物、医学的AI框架,包括加速计算库cuPyNumeric、计算光刻库cuLitho,软件平台cuOPT、医学成像库Monaiearth-2、加速量子计算的cuQuantum、稀疏直接求解器库cuDSS、开发者框架WARP等。

“我们已经达到加速计算的临界点,CUDA让这一切成为可能。”黄仁勋谈道。
据他分享,英伟达正在全面生产Blackwell,有十几家企业已生产和部署Blackwell系统。









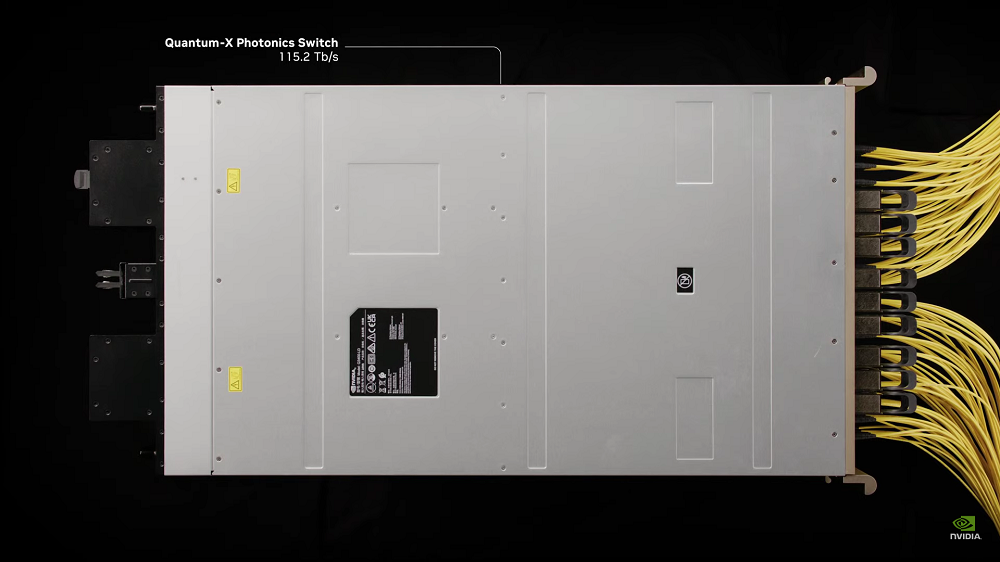
NVIDIA硅光网络交换机会被用于NVIDIA Spectrum-X Photonics以太网平台和Quantum-X Photonics InfiniBand平台。












英伟达与迪士尼研究院、谷歌DeepMind将合作开发开源物理引擎Newton。

黄仁勋谈道,物理AI和机器人技术发展得很快,但也面临着和大模型同样的挑战,就是如何获得数据、如何扩展让机器人更聪明。
基于此,英伟达为Omniverse添加了两项技术。
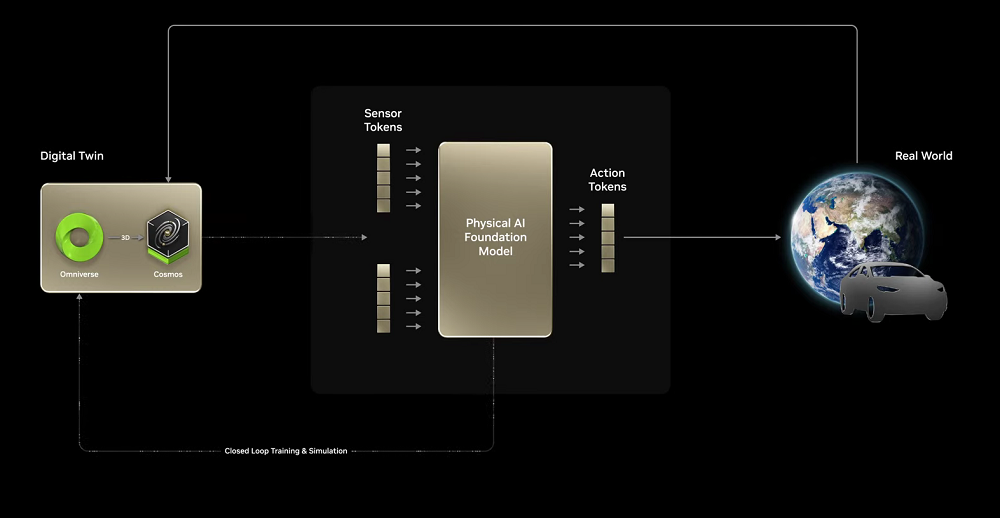
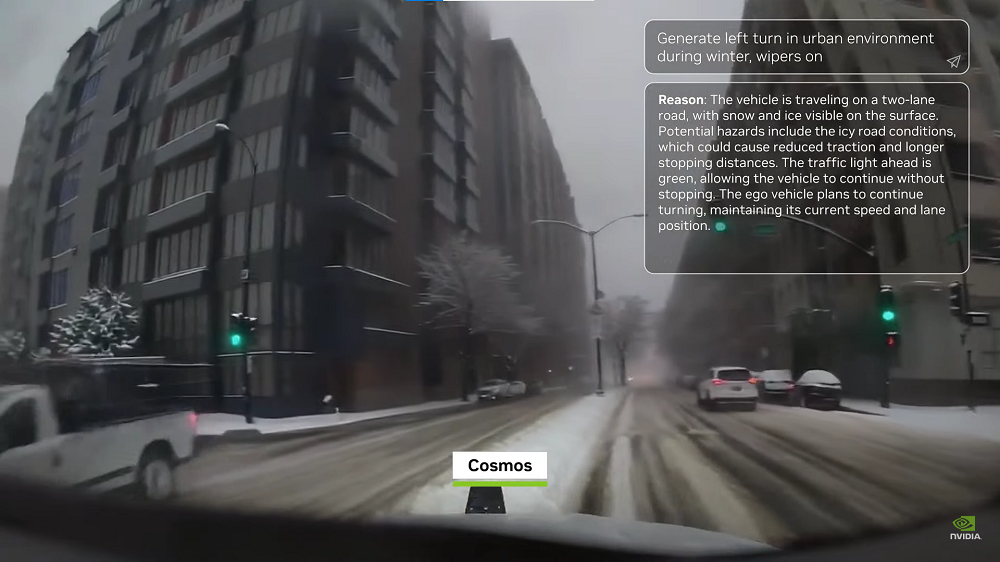
一是扩展AI的生成能力和理解物理世界的生成模型,也就是Cosmos。Cosmos可以生成无限数量的环境数据。

二是,机器人的可验证回报是物理定律,因此需要设计用于模拟真实世界中的物理现象的物理引擎。这一物理引擎需要被设计用于训练触觉反馈、精细运动技能和执行器控制。也就是上面迪士尼机器人Blue已经搭载的物理引擎。
在机器人开发中,英伟达Omniverse可以生成大量不同的合成数据,开发人员根据不同领域聚合现实世界的传感器和演示数据,将原始捕获的数据乘以大量照片级的多样化数据,然后使用Isaac Lab增强数据集对机器人策略进行后训练,让其通过模型放行为学习新技能。
实地测试中,开发人员使用Omniverse动态模拟真实环境进行测试。现实世界的操作需要多个机器人协同工作,Mega和Omniverse允许开发人员大规模测试。



黄仁勋回顾说,在开始研究GeForce 25年后,GeForce已经在全球范围内售罄。GeForce将支持AI的CUDA带向世界,现在AI彻底改变了计算机图形学。
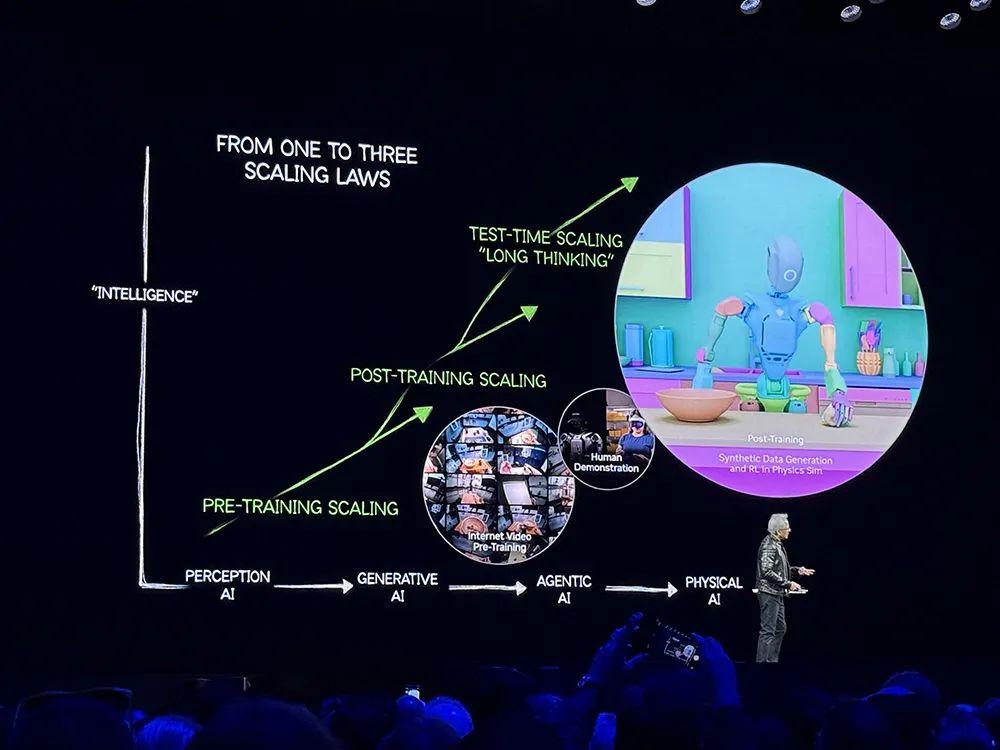
AI在10年间已经取得了巨大进步。2023年的重大突破是AI智能体(AI Agents),AI智能体可以对如何回答或者解决问题进行推理、在任务中进行规划、理解多模态信息、从网站中的视频中学习等,然后通过这些学到的学习来执行任务。
下一波浪潮是物理AI,可以理解摩擦、惯性和因果关系,使机器人技术成为可能,开辟出新的市场机会。
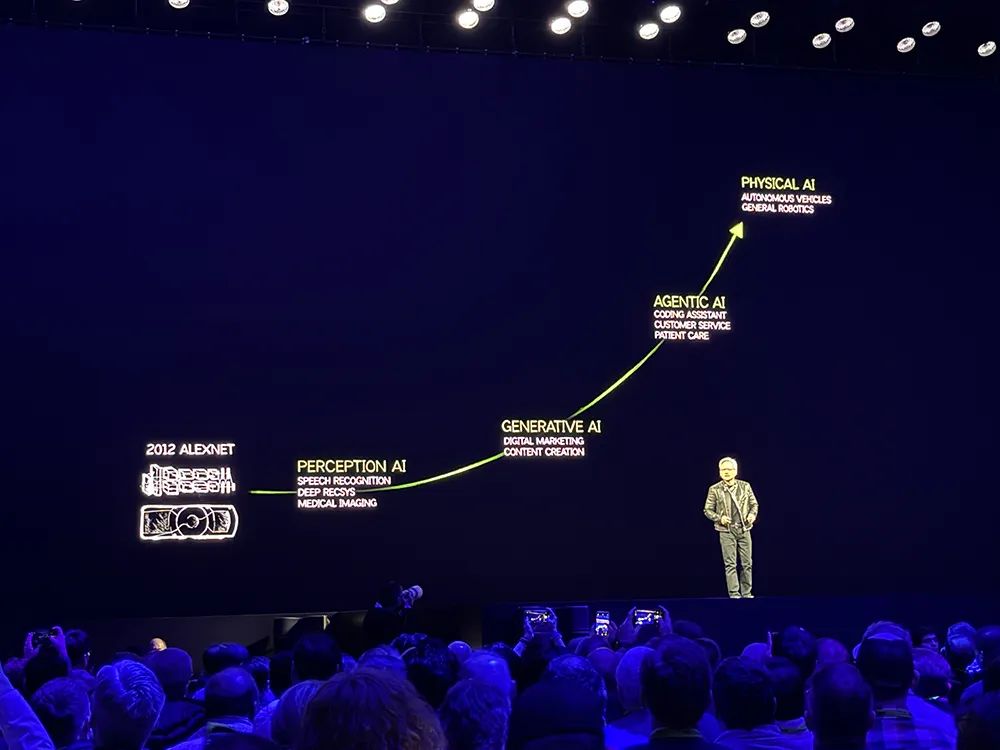
关于AI智能体和物理AI有几个核心问题:一是如何解决数据问题,AI需要数据驱动,需要数据来学习、获得知识;二是如何解决训练问题,AI需要以超人的速度、以人类无法达到的规模进行学习;三是如何扩展实现Scaling Law,如何找到一种算法让AI更聪明。
这大大加快了目前所需的计算量。背后有两个原因:
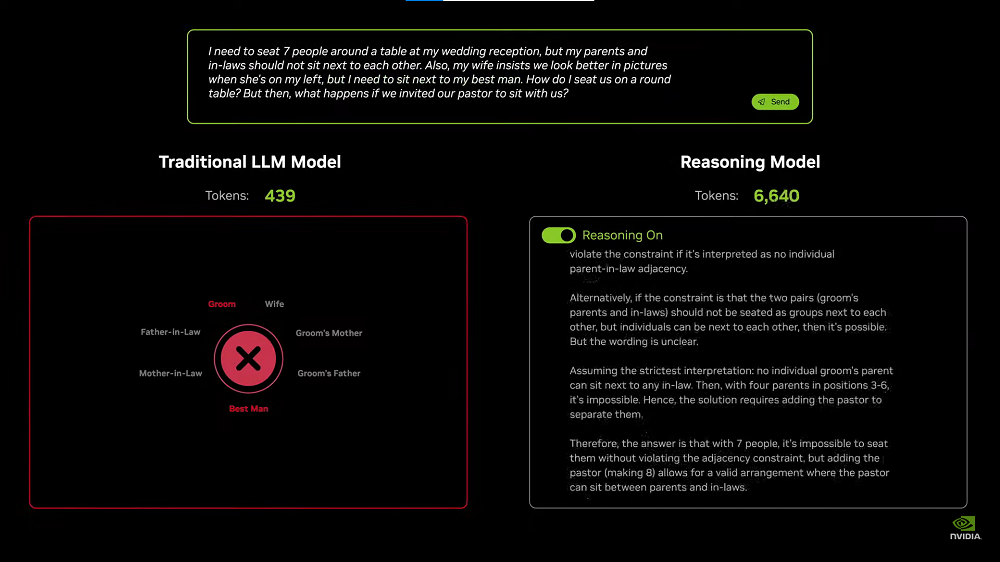
首先从AI可以做什么开始,AI可以逐步分解问题、以不同方式解决同样问题、为答案进行一致性检查等。
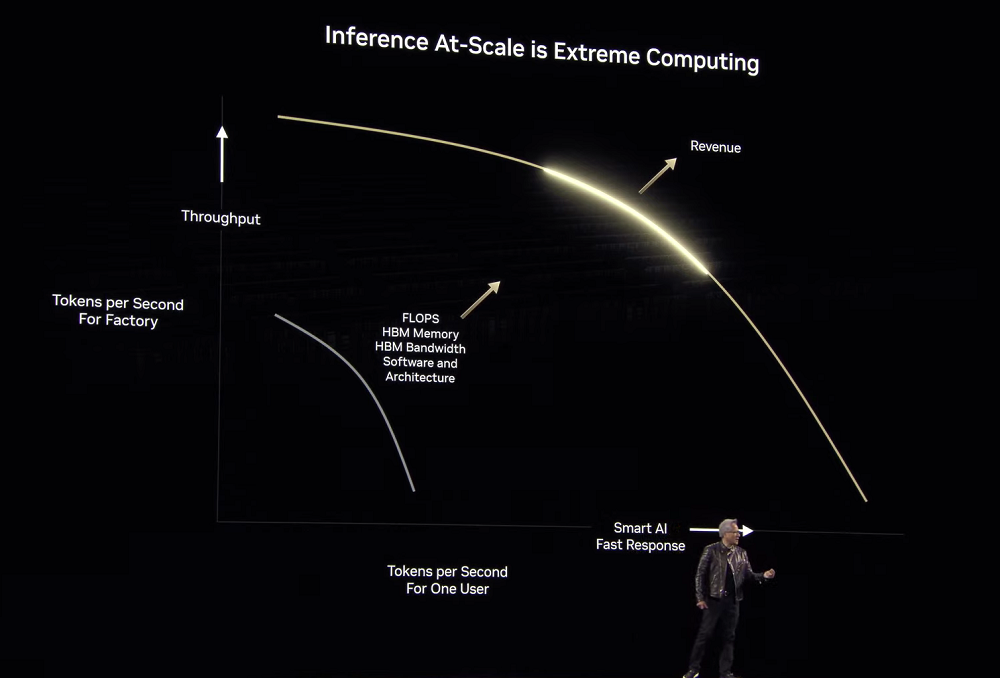
当AI基于思维链进行一步步推理、进行不同的路径规划时,其不是生成一个token或一个单词,而是生成一个表示推理步骤的单词序列,因此生成的token数量会更多,甚至增加100倍以上。
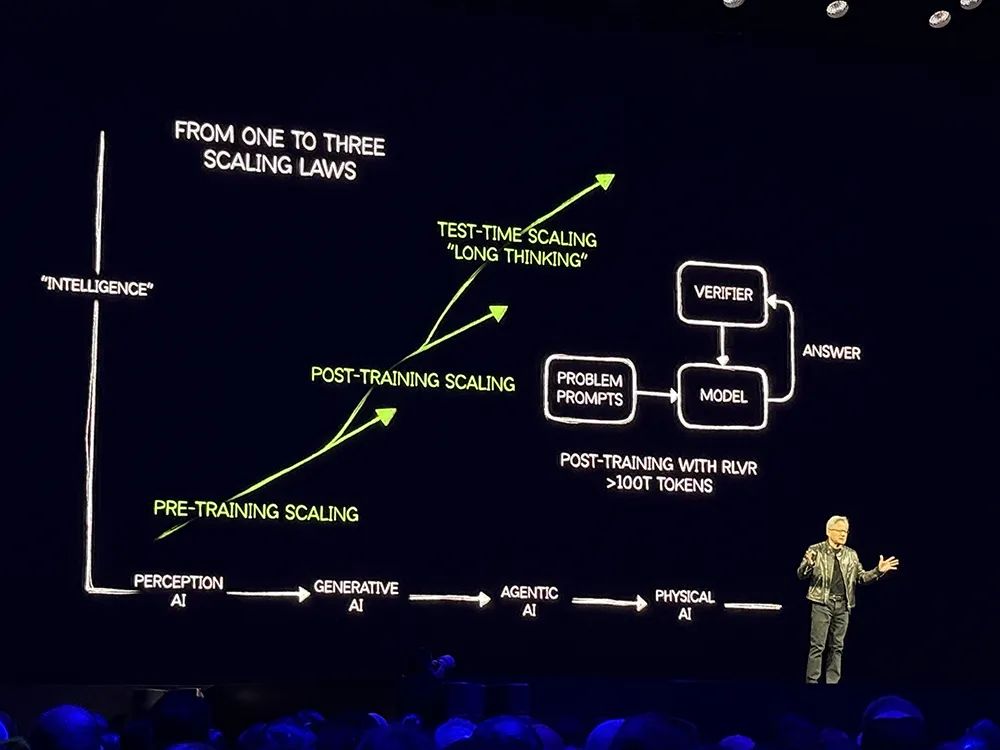
黄仁勋解释说,模型更复杂,生成的token多10倍,为了保证模型的响应性和交互性,因此计算速度必须提高10倍。
其次是关于如何教AI。教会AI如何推理的两个基本问题是数据从哪里来、如何不受限制学习,答案就是强化学习。
人类历史上已经明确了二次方程的解法、数独、勾股定理等诸多知识,基于数百个这样的案例可以生成数百万个例子让AI去解决,然后使用强化学习来奖励。这个过程中,AI需要处理数百万个不同问题、进行数百次尝试,而每一次尝试都会生成数万个token,这些都加到一起,就会达到数万亿token。
这两件事带来了巨大的计算挑战。
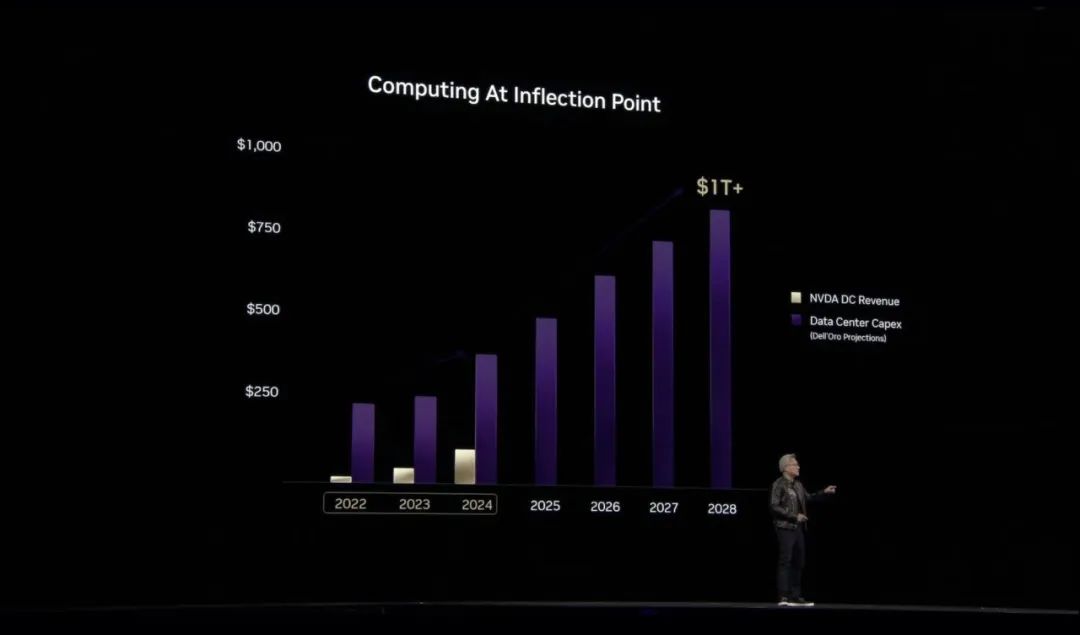
AI变得更聪明,使得训练这些模型所需的计算量大幅增长。黄仁勋预计2030年末,数据中心建设支出将达到1万亿美元。
这背后的第一个动态变化是,通用计算已经用完,业界需要新的计算方式,世界将经历手动编码软件到机器学习软件的平台转变。
第二个变化是,人们越来越认识到软件的未来需要大量投资。这是因为计算机已经成为token的生成器,基于生成式的计算构建AI工厂,然后在AI工厂里生成tokens并重组为音乐、文字、视频、化学品等各种类型的信息。
目前,拐点正在全球数据中心的建设中发生。
(文:智东西)