


©PaperWeekly原创 · 作者 | 高世平
单位 | 中山大学硕士生
研究方向 | 语言模型偏好对齐

背景
在 AI 的世界里,大型语言模型(LLMs)凭借强大的参数量和计算能力,已经能够生成与人类偏好高度一致的回答,成为 ChatGPT 等明星产品的核心。然而,这些“大块头”模型对算力和内存的需求极高,难以在手机、边缘设备等资源受限场景中普及。
于是,小型语言模型(SLMs)成为了备受关注的替代方案——它们轻量、高效,却面临一个棘手的问题:在对齐人类偏好后,效果往往不佳,通用性能甚至会下降。这种现象被研究者称为“对齐税”(Alignment Tax),仿佛小模型在努力“理解”人类时,付出了额外的代价。
1.1 小模型对齐的难题:Hugging Face的坦言
Hugging Face 首席科学官(CSO)之一托马斯·沃尔夫(Thomas Wolf)在 2024 年 8 月发布著名的 SmolLM 小模型系列时,也直言不讳地指出小模型在对齐方面的不足。
他在 X 上表示:“另一个问题是模型对齐,即如何微调这些模型以遵循指令。我们已经为大型模型开发了一些非常有效的数据集和方法(如监督微调 SFT、直接偏好优化 DPO、近端策略优化 PPO 等),但如果你尝试‘即时 SmolLM 演示,你会发现对齐后的小模型在这方面仍存在不足”。来源:
https://x.com/Thom_Wolf/status/1825094850686906857
这一坦言揭示了目前 SLMs 的对齐仍存在很多挑战。
1.2 新突破:大模型带小模型“飞”
针对这一难题,一项由中山大学 & Meta AI 最新研究提出了一种创新解决方案,利用已经对齐好的大模型“手把手”教小模型,通过知识蒸馏(KD)让小模型直接继承大模型对于人类偏好的理解能力。
该研究的核心在于,通过大模型的分布粒度的指导和 O(1) 的样本复杂度,小模型不仅能学会“什么是好的回答”,还能明白“什么是不好的”,从而大幅提升对齐效果。
目前这项工被国际机器学习顶级会议 ICLR 2025 接受,成功入选 Spotlight。

论文标题:
Advantage-Guided Distillation for Preference Alignment in Small Language Models
论文地址:
https://openreview.net/pdf?id=xsx3Fpo3UD
论文仓库:
https://github.com/SLIT-AI/ADPA


方法介绍
研究团队提出了两种创新方法,以下是详细介绍:
2.1 双重约束知识蒸馏(DCKD)
DCKD 利用偏好数据,从对齐好的大模型(教师模型)向未对齐的小模型(学生模型)传递知识。
为了让小模型同时捕捉正向(喜欢的回答 )和反向(不喜欢的回答 )信号,DCKD 在传统知识蒸馏的基础上增加了一个额外的 KL 散度约束。公式如下:
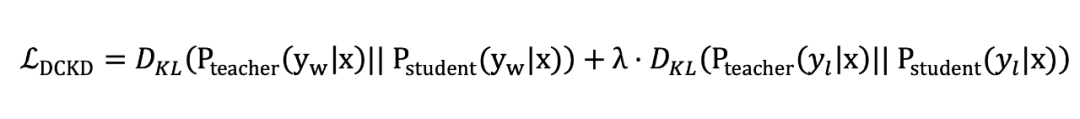
其中, 和 分别是教师模型和大模型在输入 下生成正向输出 (wining response)和反向输出 (losing response)的概率分布, 是超参数,用于平衡正向和反向信号的权重。
这种设计让学生模型不仅要模仿教师模型对正确答案的预测,还要理解教师模型对错误答案的判断。这样,学生就能更全面地掌握教师的决策逻辑,通过“双重约束”(正向和反向信号)提升对偏好的理解能力。
2.2 优势引导蒸馏(ADPA)
ADPA是这项研究的亮点,作为“主菜”,它通过引入“优势函数”(Advantage Function)进一步优化训练过程,显著提升小模型的对齐能力。具体来说,优势函数的计算基于经过直接偏好优化(DPO)训练的大模型(对齐模型)和一个未训练的参考模型(未对齐模型)。
优势函数的计算:ADPA 中的优势函数 通过比较对齐后的教师模型(DPO Teacher,)和参考教师模型(reference Teacher,)在同一输入下的输出概率分布之差来计算,告诉学生在特定情况下哪些行为更符合人类偏好。
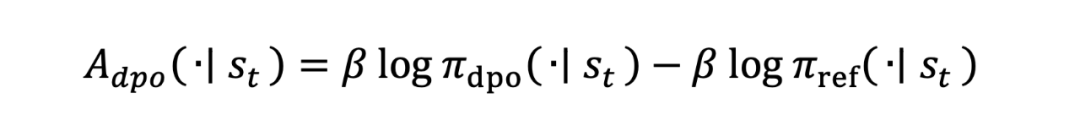
原论文附录 A 中给出了其完整的证明过程。这种设计利用了大模型对齐后的分布优势,捕捉偏好与非偏好的相对差异,作为小模型优化的指导信号。优势函数的在强化学习中用于衡量特定动作(或输出)相对于平均行为的优劣。
基于最大化优势函数期望的目标,ADPA 的损失函数被定义如下:
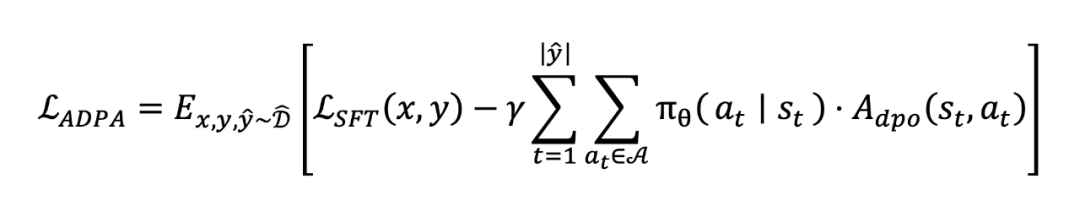
其中,,其中 是学生模型针对提示 生成的响应, 是提示 的真实响应。 表示监督微调损失,用于保留基本能力并避免过度优化,超参数 用于平衡监督微调项和优势引导蒸馏项(这里借鉴了 RPO 中使用 SFT 项避免过度优化的思路)。
通过这种明确的奖励引导,学生模型能直接学习到偏好相关的动作,而不仅是模仿输出分布,从而更高效地实现偏好对齐。
2.3 ADPA+——先DCKD,后ADPA
研究还提出了 ADPA+,它对 DCKD 训练后的学生模型进行 ADPA 训练。ADPA+ 首先使用 DCKD 进行初步知识蒸馏,让小模型初步模仿大模型的行为,然后通过 ADPA 利用优势函数进一步细化对齐效果。
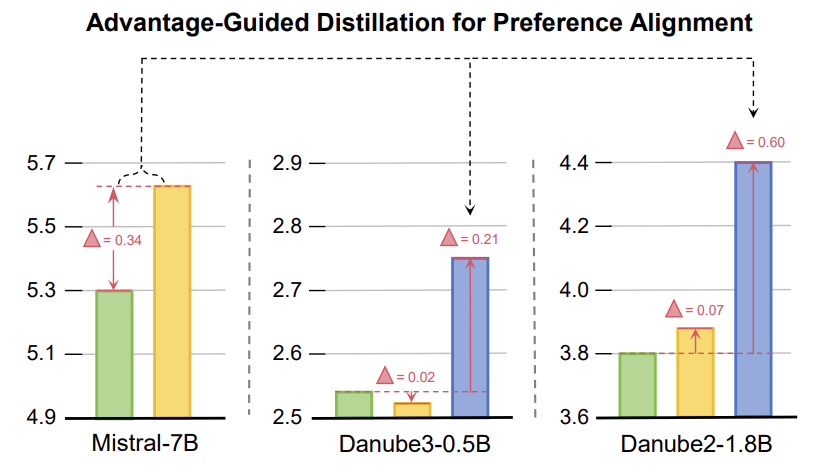
实验表明,ADPA+ 在性能上远超单独使用 DCKD 或 ADPA,尤其在小模型(如 Danube3-500M)上表现更优。
DCKD 先通过分布对齐让学生模型大致掌握教师的偏好知识,打下基础;然后 ADPA 利用优势函数提供更精确的指导,优化学生的偏好对齐能力。ADPA+ 的流程如下:


实验
测评方法上,论文主要使用了 MT-Bench、AlpacaEval,和OpenLLM Leaderboard(OLL)。由于小模型的能力还不足以与 GPT-4 相媲美,比较胜率会引入较大的噪声,导致不同方法之间难以比较,所以论文中在测试 AlpacaEval 时,使用 ADPA 训练的小模型作为基线。
文中使用的教师–学生模型组合有:Llama3.1-8B->Llama3.2-1B、Mistral7B->Danube3-500M, Danube2-1.8B、Llama2-13B->Llama2-7B;文中使用的指令微调数据集为 Deita-10K,使用的偏好数据集为:DPO-MIX-7K 和 HelpSteer2。
实验结果如下:
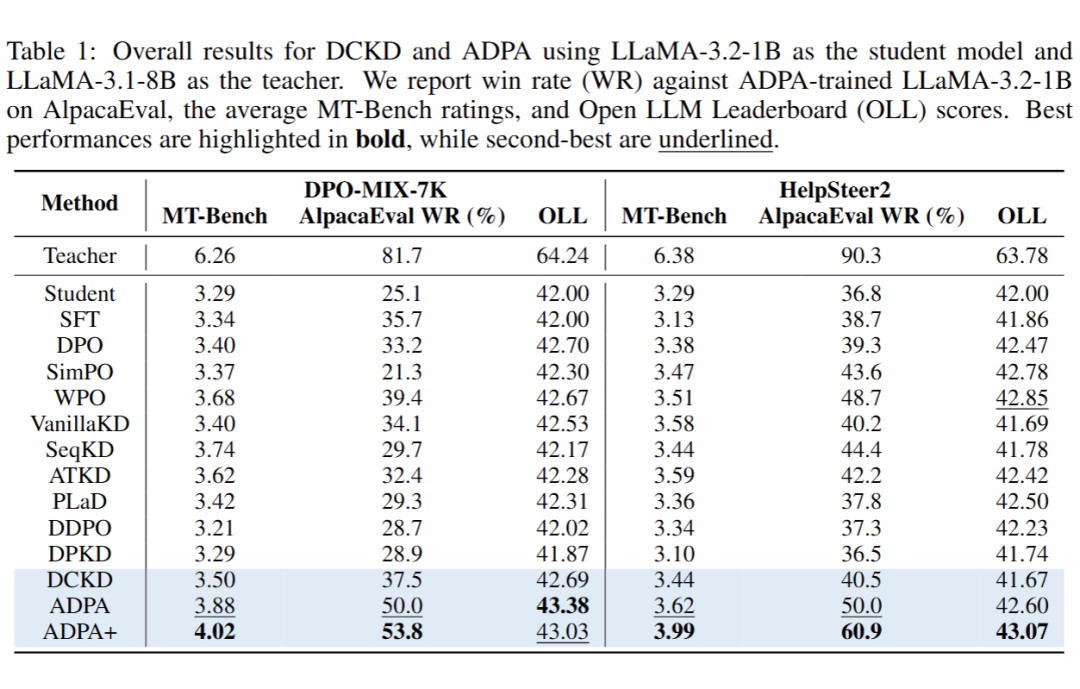
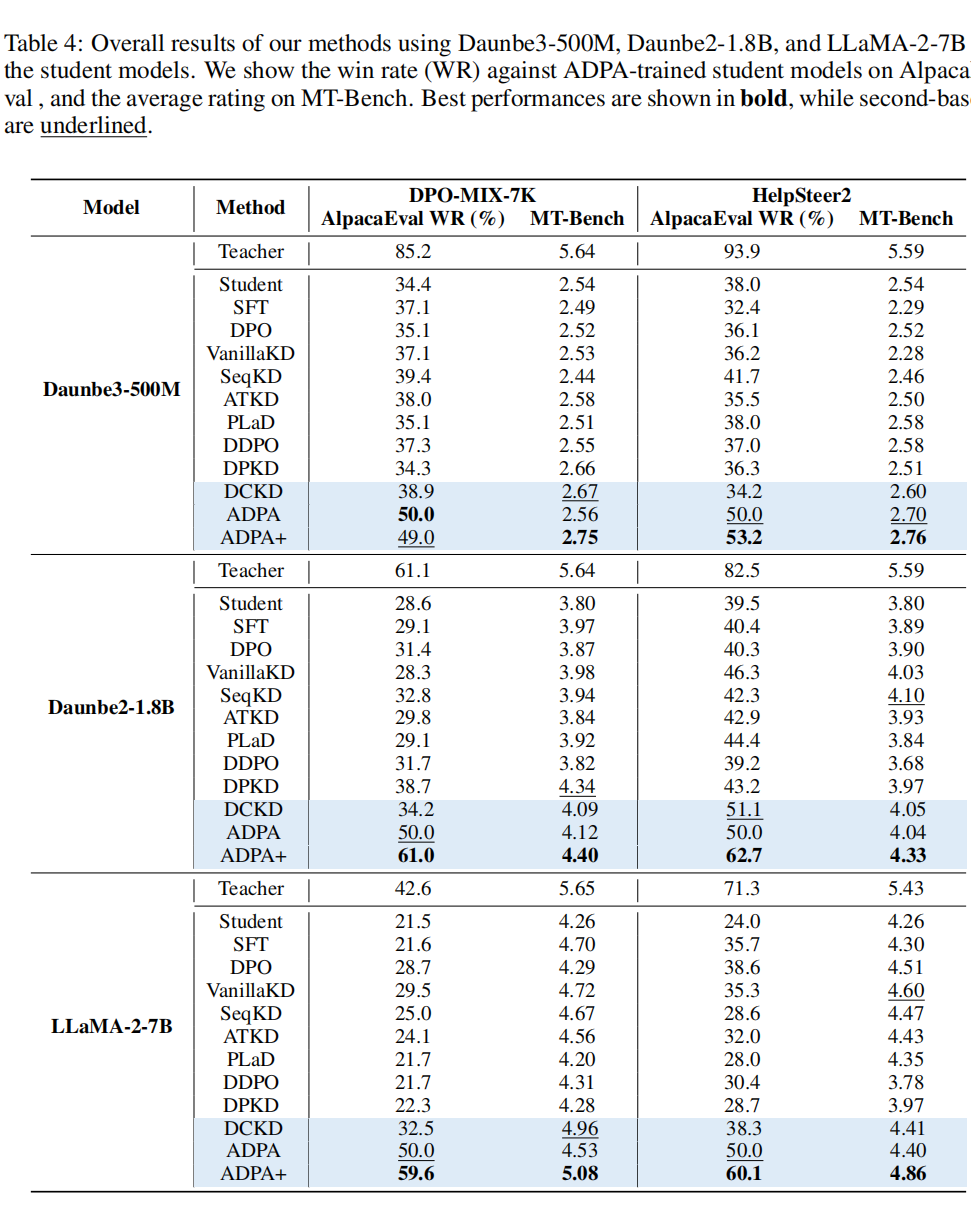
实验结果表明,DCKD 和 ADPA 显著优于基线方法(如 DPO、SimPO、VanillaKD 等)。
以 LLaMA-3.2-1B 为例,在 DPO-MIX-7K 上,DCKD 和 ADPA 分别比 DPO 提升了 0.10 和 0.48 的 MT-Bench 评分,而 ADPA+(DCKD与 ADPA 结合)进一步提升至 4.02,胜率在 AlpacaEval 中达 53.8%。在 Open LLM Leaderboard 上,ADPA+ 也展现出最佳平均性能(如 43.07 on HelpSteer2)。

ADPA 为何有效?消融实验的启示
4.1 消融实验
ADPA 的优势函数中引入了参考教师,论文中对此进行了消融实验,尝试在优势函数中去掉 ,仅保留 ,损失函数改变为:,相当于反向的交叉熵损失函数。
此外,论文中还尝试了更多的消融实验,如 DCKD 中取消教师的 DPO 训练阶段(仅使用 SFT 后的教师),或者取消反向信号(不喜欢的回答 )上的蒸馏。消融实验的结果如下:
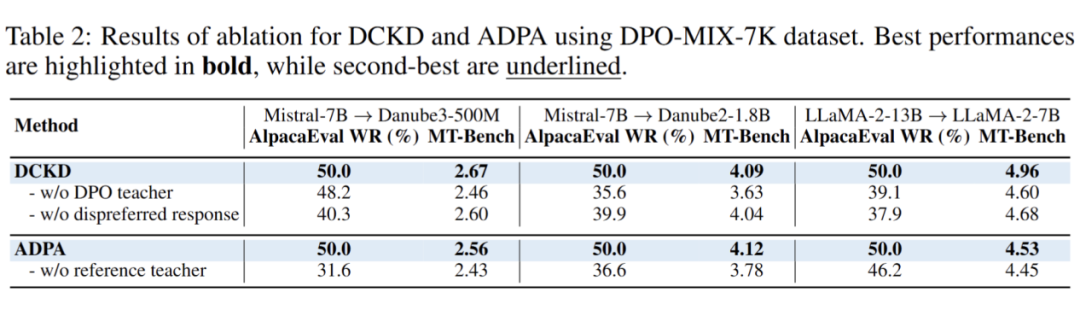
可见 ADPA 中优势函数的 reference 教师,以及 DCKD 中对教师进行 DPO 训练和加入反向信号的蒸馏都会提升学生模型的对其效果。
4.2 细粒度奖励的好处——O(1)级别的样本复杂度:
ADPA 能提供分布级别的对齐信号,这一点有何优势?文中从样本复杂度上进行了理论分析,并对不同粒度的奖励信号进行了对比实验。
文中先定义了奖励信号的样本复杂度为:在这种奖励信号的指导下,找出状态 下的最优动作 所需要的样本数量级。然后分别对本文提出来的分布级优势、token 级奖励和 sequence 级奖励的样本复杂度进行分析:
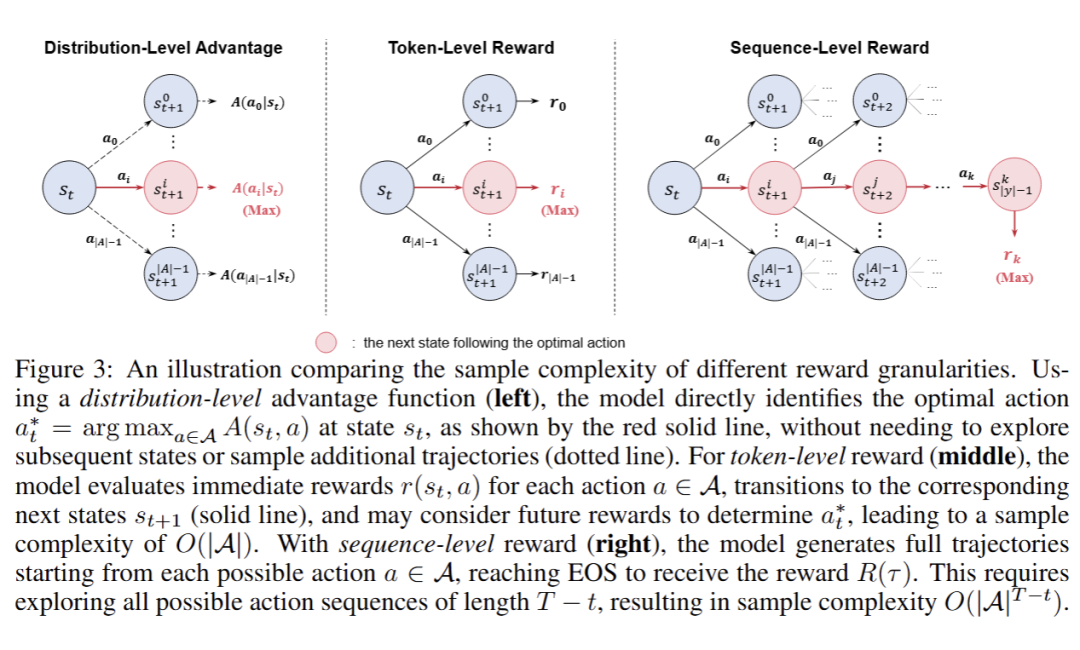
分布级优势(distribution-level advantage),即:
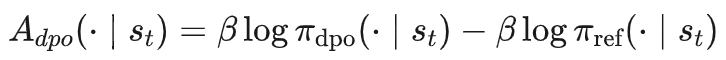
这种奖励机制通过教师模型和参考模型的策略分布直接计算优势函数 ,只需利用当前状态 下教师模型 和参考教师 的策略分布,无需对未来状态或动作进行采样。
这种方法不依赖于额外的环境交互或模拟,因此每次计算仅涉及当前状态和动作,样本需求是常数级别的,即 O(1)。
token级奖励(distribution-level advantage),即:
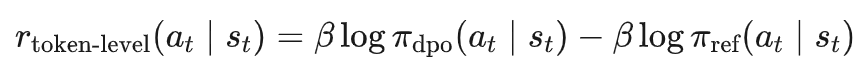
这种奖励机制模型需要评估当前状态 下所有可能的动作 的奖励,其中 是动作空间的大小(例如词汇表大小)。
为了准确计算每个动作的奖励,模型需要对词表中每个动作都采样一次,这意味着需要 次计算或采样。因此,样本复杂度为 。
序列级奖励(sequence-level reward),即:
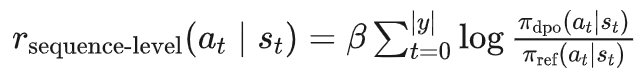
在序列级奖励中,当前动作 的价值依赖于从当前时间步 到序列结束 的所有未来奖励。
为了评估这一影响,模型需要考虑从 开始的所有可能序列。每个时间步有 个可能的动作,剩余 步的序列总数为 。这意味着需要模拟或计算指数级的序列数量来估计当前动作的价值。因此,样本复杂度为 。
论文中也对不同的奖励级别进行了实验,其中分布级优势使用 ADPA 进行优化,而 token 级和 sequence 级奖励使用 PPO 进行优化,并以 ADPA 作为基线,在 AlpacaEval 上(GPT-4Turbo 作为 judger)进行了测评,结果如下:
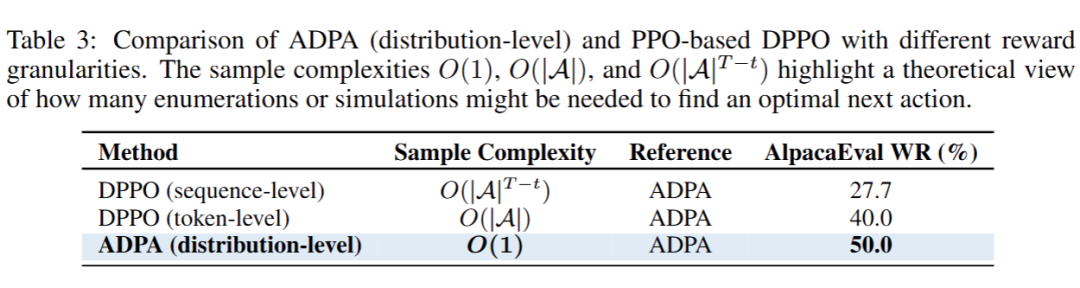
可见,虽然 ADPA 的细粒度奖励和更低的样本复杂度使得小模型更加受益。
4.3 其他基于 Q 函数的蒸馏方法
传统策略蒸馏工作中,Q 函数或优势函数常通过 softmax 或 argmax 操作后,结合 KL 散度或交叉熵损失进行蒸馏,而 ADPA 是以最大化优势期望作为目标。
为了对比这几种基于优势的蒸馏方法,论文使用 ADPA 作为基线,在 AlpacaEval 的指令上进行胜率比较。由于优势函数可视为 Q 函数的偏移,softmax 和 argmax 结果相同,故分别以 KL 散度和交叉熵为目标进行蒸馏。
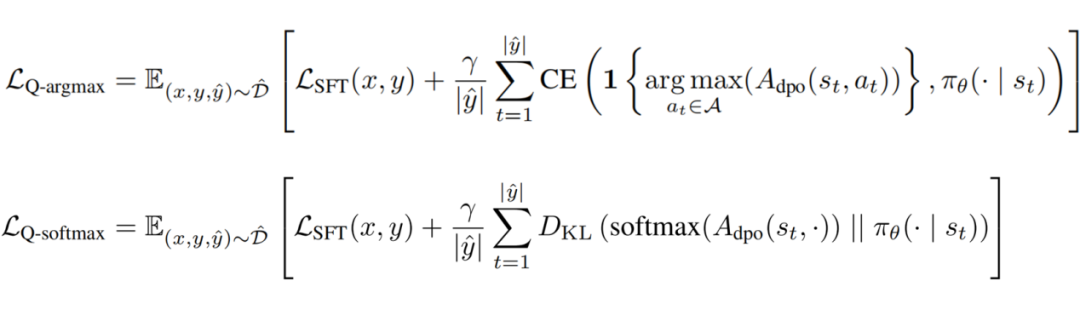
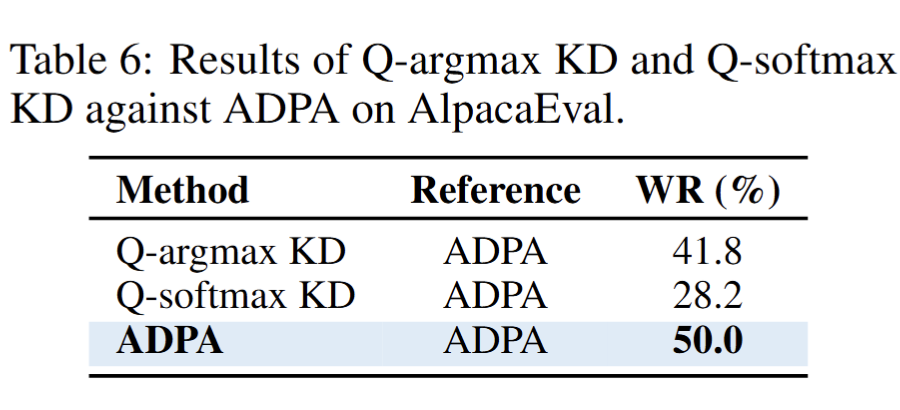
以 ADPA(胜率 50.0%)为基准,Q-argmax KD 胜率 41.8%,Q-softmax KD 的胜率为 28.2%。这提示在蒸馏过程中,保留优势函数的原始分布特征可能对性能提升更为关键。

结语
从大模型“一枝独秀”到小模型“迎头赶上”,AI 对齐技术正在迎来新的转折点。这项被 ICLR 2025 接受并入选 Spotlight 的研究意义重大,不仅在于技术突破,更在于它让我们看到:即使是“小个子”模型,也能通过“借力”大模型和优化方法(如 ADPA+),变得更聪明、更贴近人类需求。
结合 Hugging Face 的 SmolLM 实践和这项创新,我们或许正站在轻量 AI 普及的门槛上。你觉得未来小模型会有多大的潜力?欢迎留言讨论!
(文:PaperWeekly)