


如何有效评估大型视觉语言模型(LVLMs)的事实问答能力?传统的端到端评估基准是否是最佳方案?如何有效标注具有挑战性的多模态事实问答基准?
VisualSimpleQA 提供了一套解决方案。
有效评估 LVLMs 在 fact-seeking QA 任务中的表现对于其可靠性研究至关重要。目前,主流评测基准多采用端到端评估,即直接对比标准答案和模型生成的多模态问题的答案。
然而,模型由多个模态模块组成,例如用于视觉特征提取的 ViT 和处理文本知识的 LLM。因此,模型产生的错误可能源于视觉识别不准确、文本知识不足,或二者共同作用。仅依赖端到端评估难以明确模型的弱点模块,因此,对模型的事实问答能力进行解耦评估尤为重要。
为此,团队提出了面向事实查询的多模态评测基准 VisualSimpleQA,包含 500 条人工标注的高质量评测样本,其主要优势包括:
-
简明的解耦评估框架:提供简单且易理解的方法,评估模型的语言模块和视觉模块,帮助分析亟待改进的弱点模块。
-
明确的样本难度标准:相较于现有基准,VisualSimpleQA 明确了一套量化样本难度的方法,并通过实验验证其有效性,这有利于指导标注人员合理控制样本难度,提高基准的挑战性。

论文题目:
VisualSimpleQA: A Benchmark for Decoupled Evaluation of Large Vision-Language Models in Fact-Seeking Question Answering
论文链接:
https://arxiv.org/pdf/2503.06492
数据集链接:
https://huggingface.co/datasets/WYLing/VisualSimpleQA

解耦评估框架
样本设计:解耦评估是 VisualSimpleQA 的核心之一,旨在评估 LVLMs 的特定模态模块。研究人员通过设计 VisualSimpleQA 的样本形式来支持解耦评估。
图 1 为一个 VisualSimpleQA 样本的示例,每个样本包含了一个多模态事实问答问题(multimodal question)、一个对应的纯文本问题(text-only question)以及标准答案(answer)。
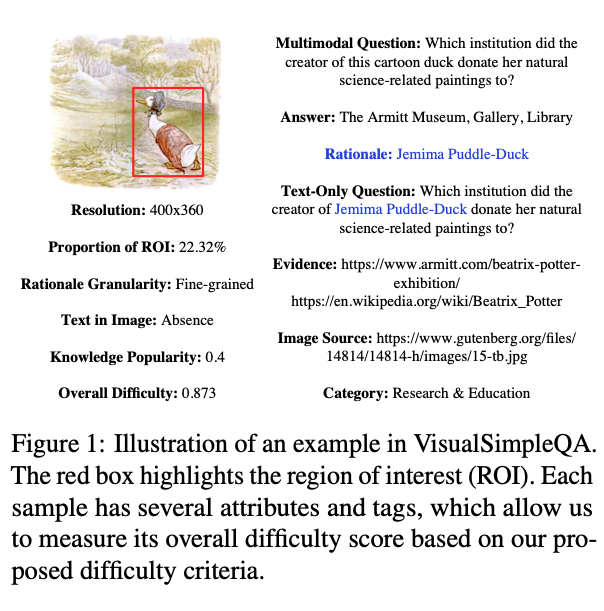
具体来说,标注者会对多模态问题标注一个回答依据(rationale),用于指示正确回答该问题所需从图像中识别的关键信息。例如,在图 1 所示的例子中,关键视觉信息是卡通角色 “Jemima Puddle-Duck”。通过将 rationale 融入多模态问题,可生成改写后的纯文本问题,回答该纯文本问题无需依赖任何视觉信息。
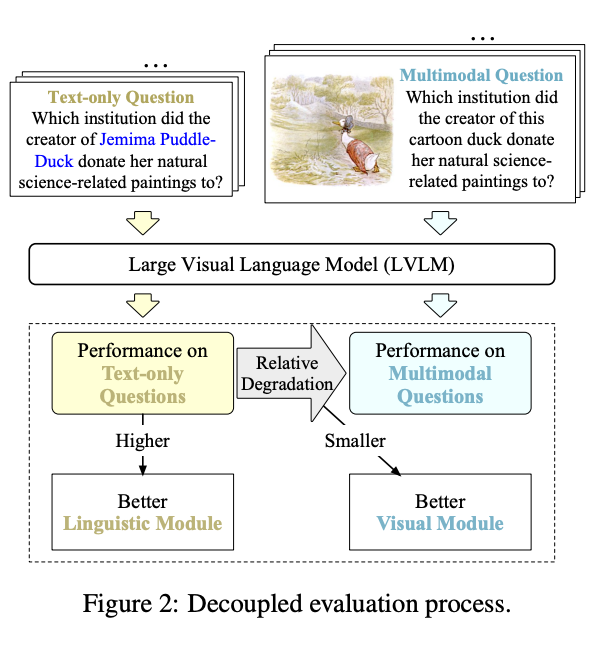
评估方法:如图 2 所示,语言模块的性能通过纯文本问答的表现来衡量,较好的表现表明语言模块具备更好的事实性问答能力。相比之下,视觉模块的性能通过计算从纯文本问答转移到多模态问答的性能下降幅度(relative degradation, RD)来衡量。

样本难度标准
设计思路:考虑到 LVLMs 的能力在不断提升,评测基准中包含挑战性的样本是非常必要。然而如何标注难样本呢?VisualSimpleQA 引入明确的标准来评价每个样本的难度。由于 LVLMs 结合了视觉和语言模块,样本难度标准涉及到视觉信息识别和文本知识辨识两个角度。
(1)视觉信息识别相关标准
-
分辨率(Resolution):图像分辨率越低,模型越不容易识别图像中的纹理等视觉特征,视觉识别难度越大。
-
ROI 占比(Proportion of ROI):多模态问题的正确回答依赖于精确的视觉定位,即识别感兴趣区域(Region of Interest,ROI)的能力。当 ROI 面积较小时,模型可能难以准确识别。
-
回答依据的粒度(Rationale Granularity):回答依据(rationale)是从 ROI 中提取的关键信息,其粒度可以是粗粒度(如识别“熊猫”这一物种)或细粒度(如识别特定卡通角色“皮卡丘”)。一般而言,细粒度的 rationale 识别难度更大。
-
图像中是否存在有用文字(Presence or Absence of Text in Image):部分图像包含文字,可以帮助模型明确 rationale。当前 LVLMs 在 OCR 任务上的表现有明显提升,正确识别图像中的文字能帮助回答问题。例如,如果图像中的 ROI 是动物园大门,上面写有 “Singapore Zoo”,OCR 识别出的文字可以成为回答依据,从而简化任务。
(2)文本知识辨识相关标准
-
知识流行度(Knowledge Popularity):语言模块的训练语料(如 CommonCrawl、The Stack 和 The Pile)多来源于互联网,其中包含大量常见的知识。模型对于这些高频知识的学习通常更充分,因此涉及流行知识的问题难度相对较低,而涉及冷门知识的问题则可能更加困难。
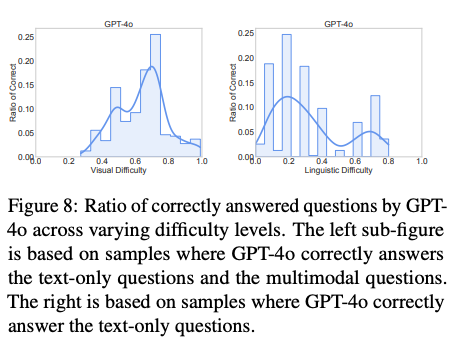
样本难度标准的验证:以 GPT-4o 为例,通过对比图 7 和图 8 展示的实验结果,可以验证模型失败的样本倾向于具有更高的视觉识别难度,同样地,这些样本也表现出更高的语言知识难度。类似的结果可在其他模型上观察到。


标注流程
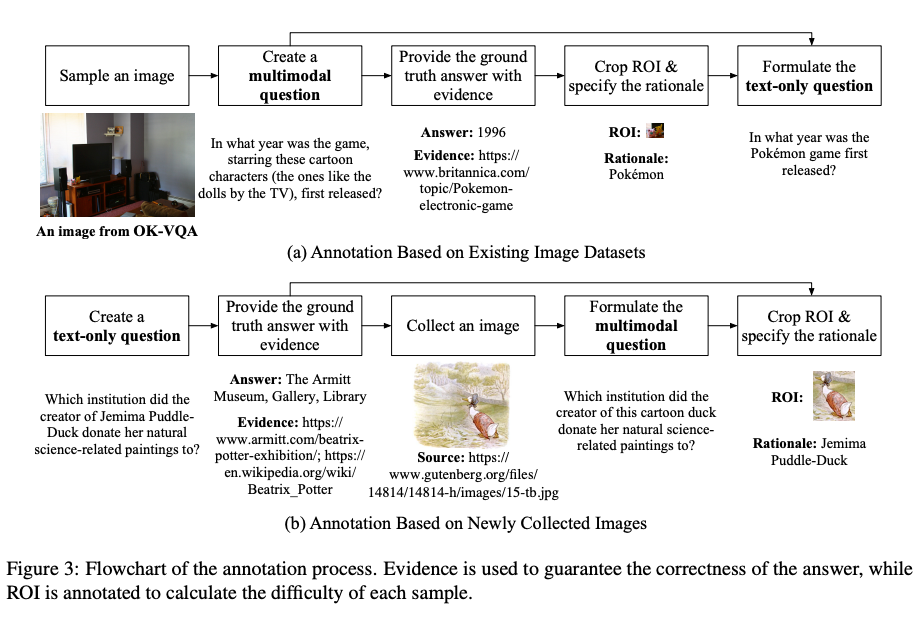
流程概述:VisualSimpleQA 由多名具备至少一年大模型经验的科研人员标注与验证。根据图像来源的不同,设计了两种标注流程(如图 3 所示),以便于标注人员工作。
对于现有图像数据集,标注者随机选取图像,并依据难度标准构造样本。考虑到现有的多模态数据集可能会被用于 LVLM 的训练,导致引入评测偏差,标注人员特别从互联网采集了 200 张新图像(占比 40%),以缓解可能的数据泄漏对评测的影响。
质量控制:参考 SimpleQA 的做法,标注者构建具有无争议且简短答案的问题,以便于更客观和准确的自动评估,同时,需要涉及不同类型的主题,保证多样性,同时为每个样本提供证据,证据以官方或正规网页 url 的形式提供,在网页中我们能验证标准答案。
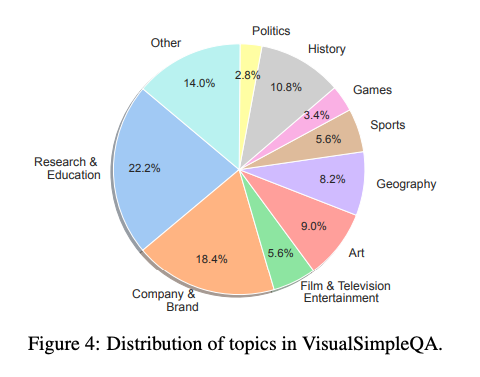
每个样本被检查了两次,低质量样本被删除或修改,最终形成 500 个可用样本,样本的主题分布如图 4 所示。
VisualSimpleQA-hard:基于所设计的难度标注,可以从 500 条标注样本中提取 129 条更具挑战性的样本,组成子集 VisualSimpleQA-hard。

模型评估
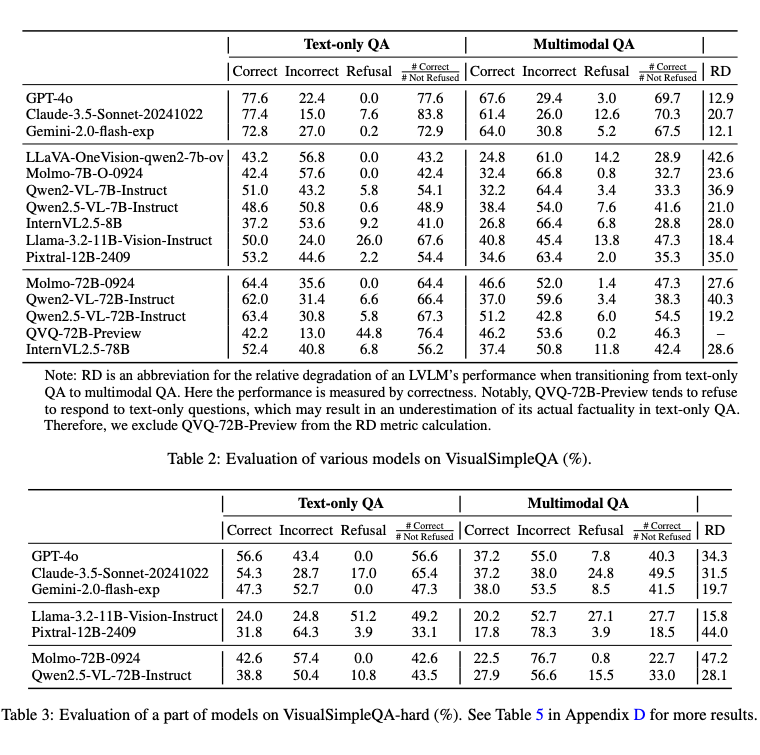
主要结论:在 15 个典型的开闭源 LVLMs 上测试了多模态问题和纯文本问题。结果显示,VisualSimpleQA 是一个具有挑战性的基准,能够区分不同模型的事实性表现。
即使是先进的模型如 GPT-4o,在 VisualSimpleQA 的多模态问答中仅达到 60%+ 的正确率,在 VisualSimpleQA-hard 中仅达到 30%+ 正确率,且不同模型在基准上的表现差异明显,证明了该基准在评估多模态事实问答能力上的有效性。RD 指标结果表明,当前前沿 LVLMs 的视觉模块仍有明显提升空间。

结语
VisualSimpleQA 的提出为评估 LVLMs 的事实问答能力提供了新的思路。明确定义的样本难度标准不仅提升了标注效率,还能帮助进行更细致的结果分析。评估结果表明,主流 LVLMs 在视觉和语言模块均存在显著的改进机会以提高模型事实性。
目前,VisualSimpleQA 已开源至 Hugging Face,期望能为 LVLMs 的事实性研究提供支持,推动该领域的进一步发展。
(文:PaperWeekly)